-
-

Logo
-

Getting Files
-

Getting resume details
-

Uploading resume
-

Deleting files
-

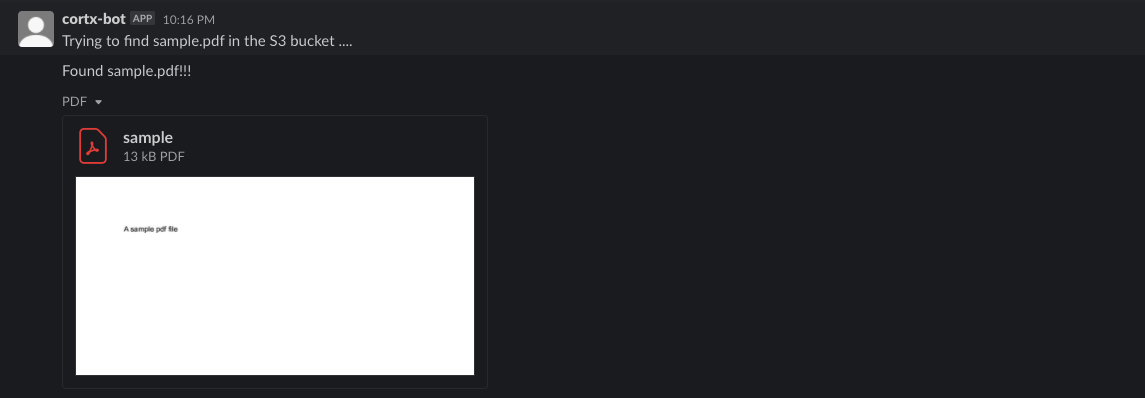
Searching files




Inspiration
When the hackathon was announced we were looking to build something useful that integrates Cortx S3 with a widely used tool to make a useful integration. With 10+ million daily active users we decided Slack would be the perfect fit. You can find files, download them or delete them permanently without leaving Slack or writing a single line of code. Most of the time we don't know the exact name of the file we are looking for so we decided to integrate a search dialog to find files in the S3 bucket. Managing employee records can also be a hassle, so we made a data pipeline to streamline the employee or intern onboarding process. The new team members just have to upload their resume and their data is added to the company database using AWS and advanced NLP (Natural Language Processing) and OCR (Optical Character Recognition) techniques. This enables efficient management of employee documents. With the data pipeline we have built we can make sense of any kind of unstructured data not just resumes we can extend it to medical records, performance reports and what not.
What it does
File Syncing and Data Backup
Cortx S3 Slack Bot enables users to access files in your S3 bucket directly from Slack using Slash commands. By using simple commands like /cortx-s3-get filename and /cortx-s3-delete filename we can find or delete files. Whenever a new file is shared on any public channel it is automatically added to the Cortx S3 test bucket, ensuring that all your slack files are safe in case a teammate accidently deletes a file that you need.
File Searching
Most of the time we don't know the exact name of the file we are looking for. We also need to check if the file is actually present in the S3 bucket. Pooling the bucket over and over again to find a file or check for its existence is a computationally expensive and slow operation. To enable faster indexing of all the files on the S3 bucket, there is a layer of Elasticsearch between the Slack Bot and the S3 bucket. A user can find any file using the /cortx-s3-search command which opens a file search dialog. Elasticsearch's autocomplete functionality helps in navigating or guiding the user by prompting them with likely completions and alternatives to the filenames as they are typing it.
Employee/Intern Onboarding
Whenever a new employee/intern joins the #cortx-s3-test channel he/she is greeted by our Cortx bot and is asked to upload his/her resume. After uploading their resume, they notify the slack bot with the /cortx-s3-upload-resume resume.pdf command. The bot processes the file extracts Personally Identifiable Information (PII) like name, email and phone number from the document updates of the csv file.
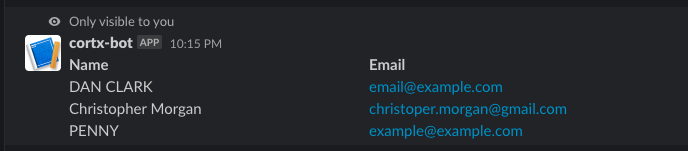
The administrators can get all the details of the employees within slack using /cortx-s3-resume-data slash command.
How we built it
This integration has 5 components
- Slack Bot
- Cortx S3 Server
- Elasticsearch
- AWS Comprehend
- AWS Textract
The Project is set up to work in a python3 virtual environment. The Slack app is built using Bolt for Python framework. For connecting to the CortxS3 Server, AWS Comprehend and AWS Textract we use their respective boto3 clients. We connect to Elasticsearch using the Python Elasticsearch Client.
The Slack app listens to all sorts of events happening around your workspace — messages being posted, files being shared, users joining the team, and more. To listen for events, the slack app uses the Events API. To enable custom interactivity like the search modal we use the Blocks Kit.
Slash commands perform a very simple task: they take whatever text you enter after the command itself (along with some other predefined values), send it to a URL, then accept whatever the script returns and posts it as a Slackbot message to the person who issued the command or in a public channel. Here are the 5 slash commands we use to interact with the Cortx S3 bucket.
File Sync
Whenever a new file is shared in any public slack channel the file_share event is sent to the Slack app. The file is first indexed into Elasticsearch and then added to the Cortx S3 bucket with a key as file name.
Slash Commands
- /cortx-s3-get
- /cortx-s3-search
- /cortx-s3-delete
- /cortx-s3-upload-resume
- /cortx-s3-resume-data

/corx-s3-get filename
After fetching the filename from the command['text'] parameter we check if a the file exists using the es.exists(es = Elasticsearch client) function. If the file is found, we return the file back to the user as a direct message.
/corx-s3-search
This command opens up a modal inside of slack with a search bar, the user is suggested the file names depending on whatever text is written in.
/corx-s3-delete filename
After fetching the filename from the command['text'] parameter we check if a the file exists using the es.exists(es = Elasticsearch client) function. If the file is found, we confirm if the user wants to permanently delete the file from the S3 bucket. If the user clicks yes, the file is permanently deleted.

/corx-s3-upload-resume resume.pdf
When the command is invoked, we get the name of the file from the command[text] parameter. The slack app searches for the file on the S3 bucket and downloads it for local processing. The text is extracted from the .jpeg or .pdf resume file using AWS textract using OCR (Optical Character Recognition). The text is passed onto AWS Comprehend which identifies Personally Identifiable Information (PII) of the employee like name, email and phone number from the document. This data is appended in the resume-data.csv file.
/corx-s3-resume-data
Upon invocation we get the names and email addresses of the employees inside a table in slack populated with the data from resume-data.csv file.
Challenges we ran into
- Firstly, setting up a VM to run cortx-va-1.0.3.ova was a challenge. I finally switched over to a Cloudshare environment as it was much easier to use
- Setting up slack and using Bolt framework to build slack apps. Learning a new framework was difficult but once you get a hang of it was quite easy.
- In order for the search functionality to work, Elasticsearch had to be properly set up.
- Coming up with a meaningful integration
- Setting up AWS to use AWS comprehend and AWS Textract for Text extraction and processing
Accomplishments that we're proud of
We were able to build a decent enough integration that uses 5 widely popular technologies namely Cortx S3, Slack, Elasticsearch & AWS Comprehend and AWS Textract. This integration makes it easy for remote teams to collaborate and work efficiently.
What we learned
- Setting up a VM machine to run Cortx S3
- Elasticsearch and ngrams
- Building Slack apps using bolt framework
- Slash commands to enhance the workspace experience
- Using Slack's Block Builder to build custom native interfaces
- Using AWS
- AWS Comprehend
- AWS Textract
- Getting familiar with environment variables and virtual environments in python
What's next for Cortx S3 Slack Bot
The Slack Bot currently works only on a development environment, we plan to distribute it on the Slack App Directory. We have currently used AWS Textract & AWS Comprehend only to detect personally identifiable information (PII) as just a proof of concept, in future we plan to use AWS Comprehend Medical to derive insights from a large trove of unstructured medical data.
Built With
- amazon-web-services
- cortx
- cortx-s3
- elasticsearch
- python
- slack




Log in or sign up for Devpost to join the conversation.