










Inspiration
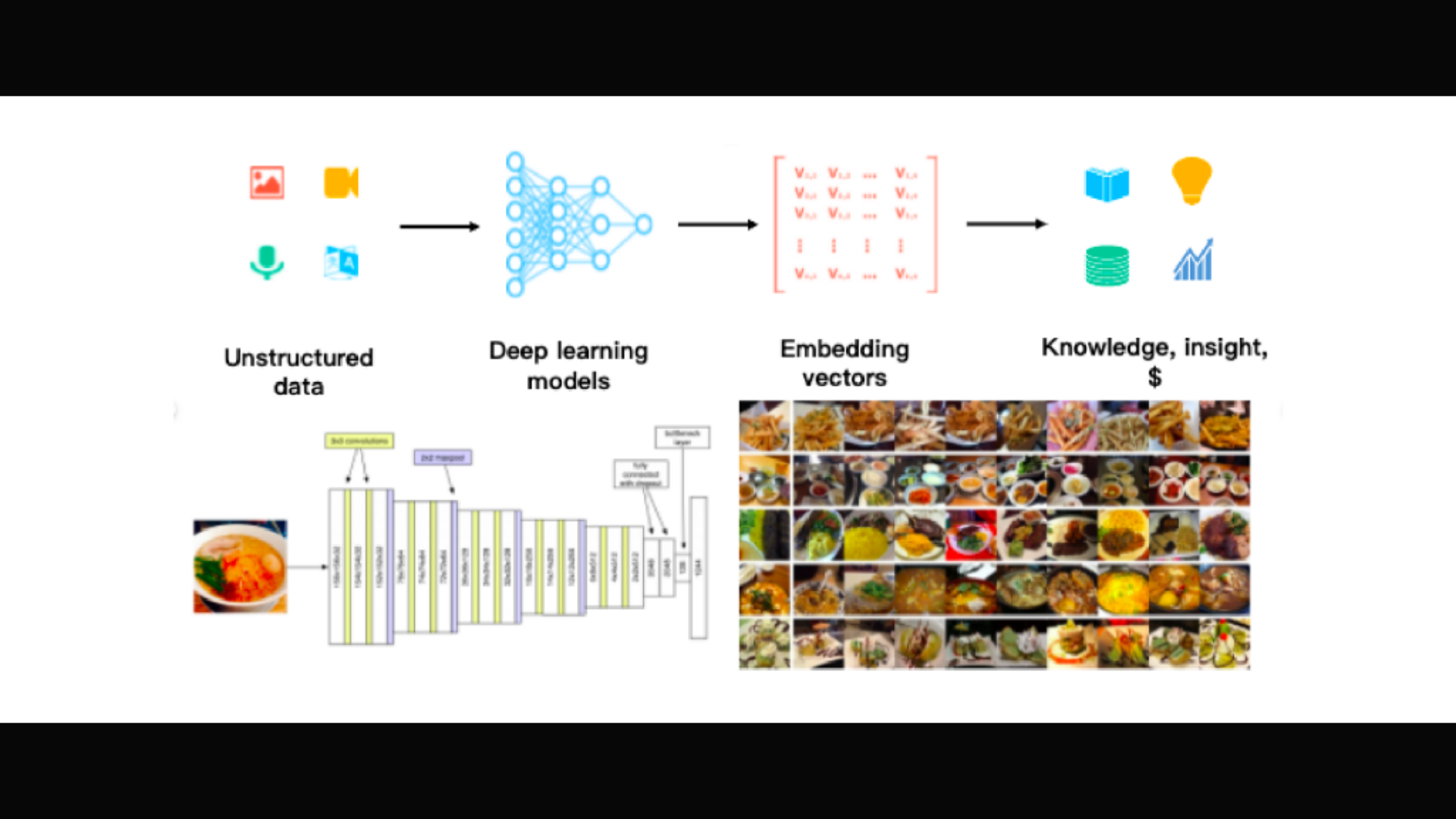
Neural search, which combines machine learning and object storage technologies, could one day enable people to access the entire world’s information. They would be able to search through any data that is available online but not stored in a standard database format like text or images. This includes newspaper articles from 80 years ago or genetic sequence records – anything! Since so much of the world’s knowledge exists outside of normal databases already today, neural applications will likely play an important role in research as well as everyday tasks soon enough.

What it does
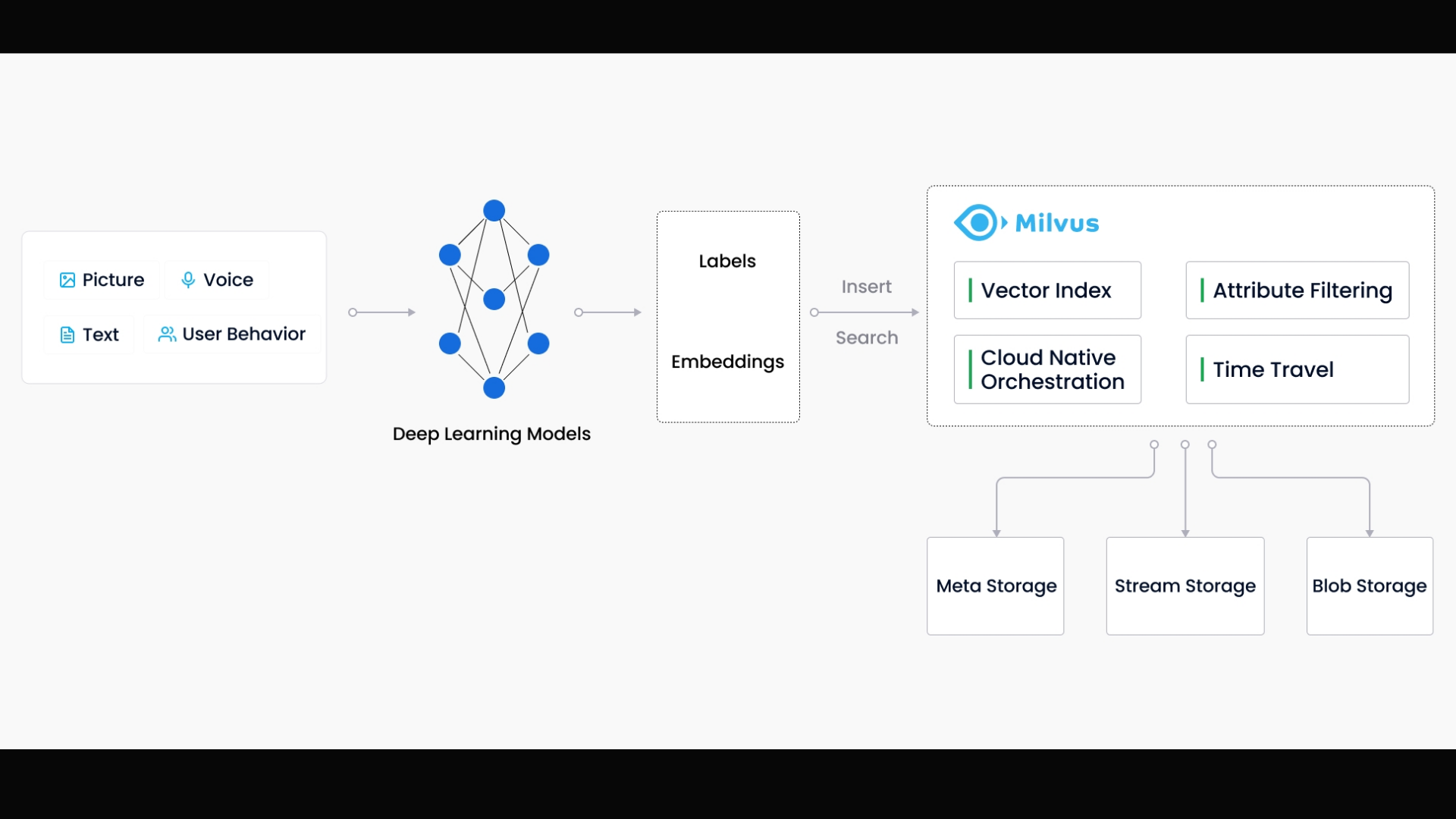
Milvus was created in 2019 with a singular goal: to store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models. Various companies use Milvus.io for getting insights into their industrial and business data.

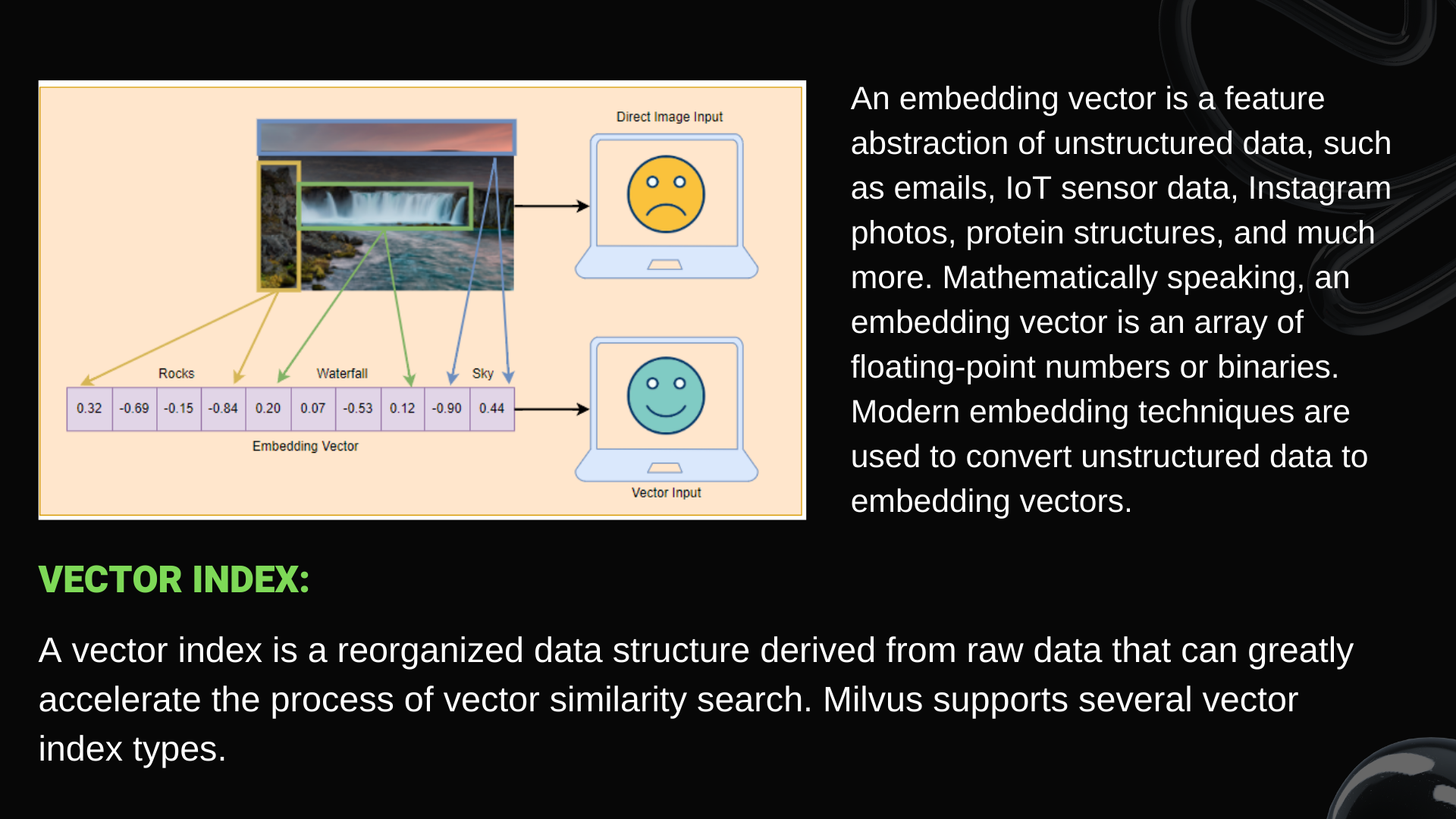
As a database specifically designed to handle queries over input vectors, it is capable of indexing vectors on a trillion scale. Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom up to handle embedding vectors converted from unstructured data. Unstructured data, including images, video, audio, and natural language, is information that doesn't follow a predefined model or manner of organization. This data type accounts for ~80% of the world's data and can be converted into vectors using various artificial intelligence (AI) and machine learning (ML) models.
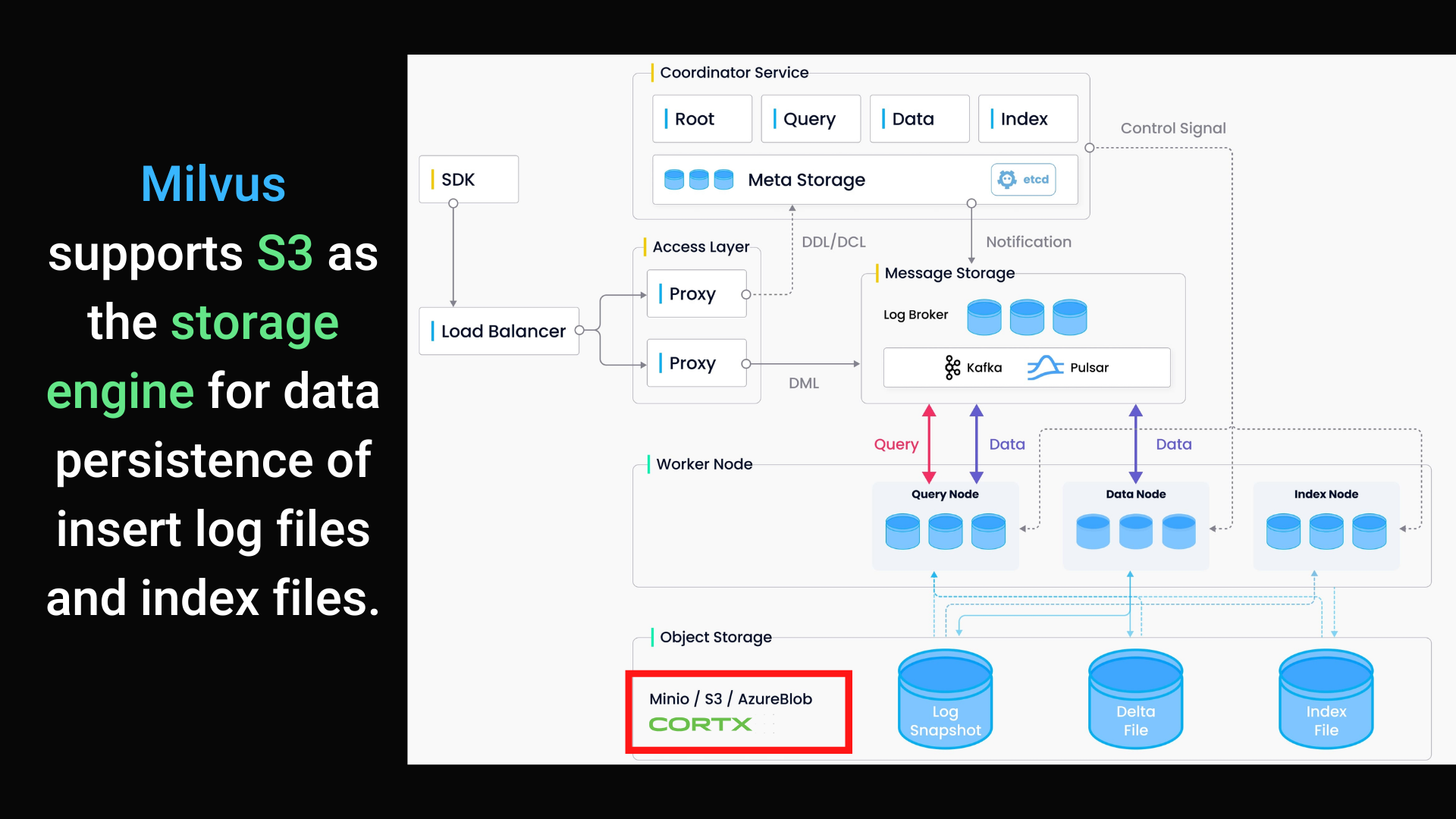
Cortx Object storage stores snapshot files of logs, index files for scalar and vector data, and intermediate query results, and is responsible for data persistence of large files in the cluster, such as index and binary log files.

Cortx as the Milvus Object Storage
Here we will learn about the implementation of data insertion, index building, and data query in Milvus with Cortx as Object Storage Backend.

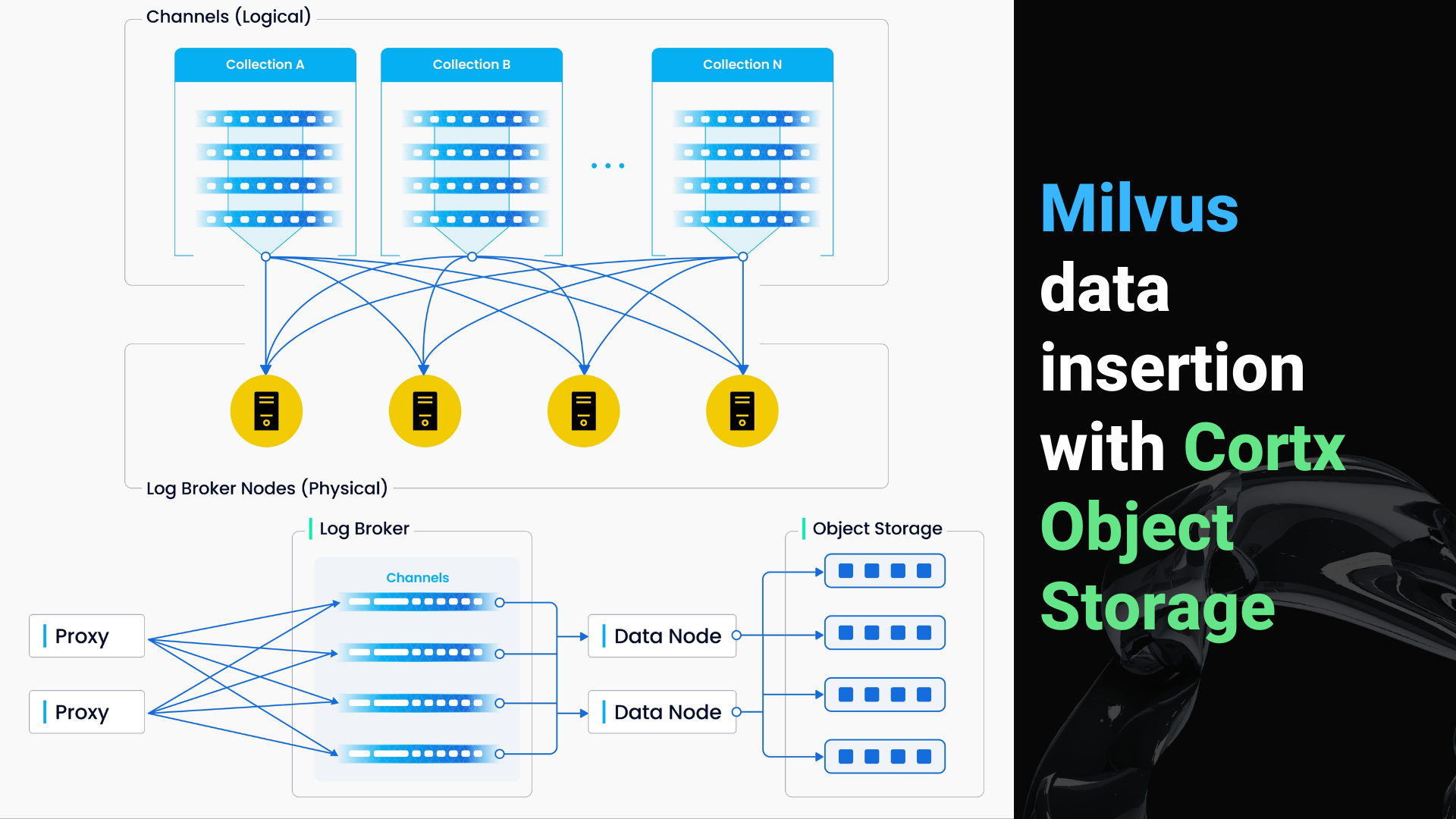
The above diagram encapsulates four components involved in the process of writing log sequence: proxy, log broker, data node, and object storage. The process involves four tasks: validation of DML requests, publication-subscription of log sequence, conversion from streaming log to log snapshots, and persistence of log snapshots. The four tasks are decoupled from each other to make sure each task is handled by its corresponding node type.

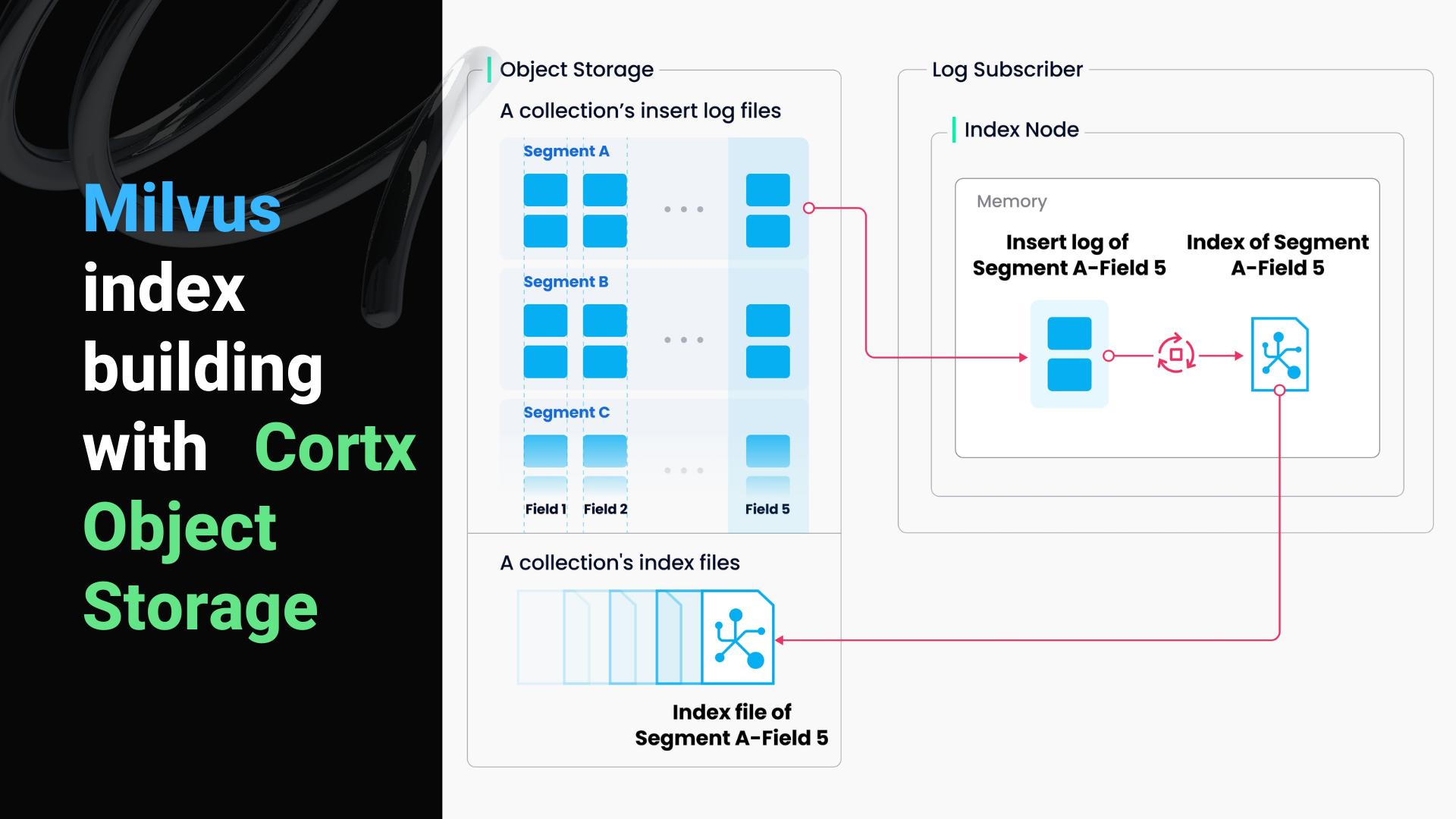
Index building mainly involves vector and matrix operations and hence is computation- and memory-intensive. As shown above, Milvus supports building index for each vector field, scalar field and primary field. Both the input and output of index building engage with object storage: The index node loads the log snapshots to index from a segment (which is in object storage) to memory, deserializes the corresponding data and metadata to build index, serializes the index when index building completes, and writes it back to object storage.

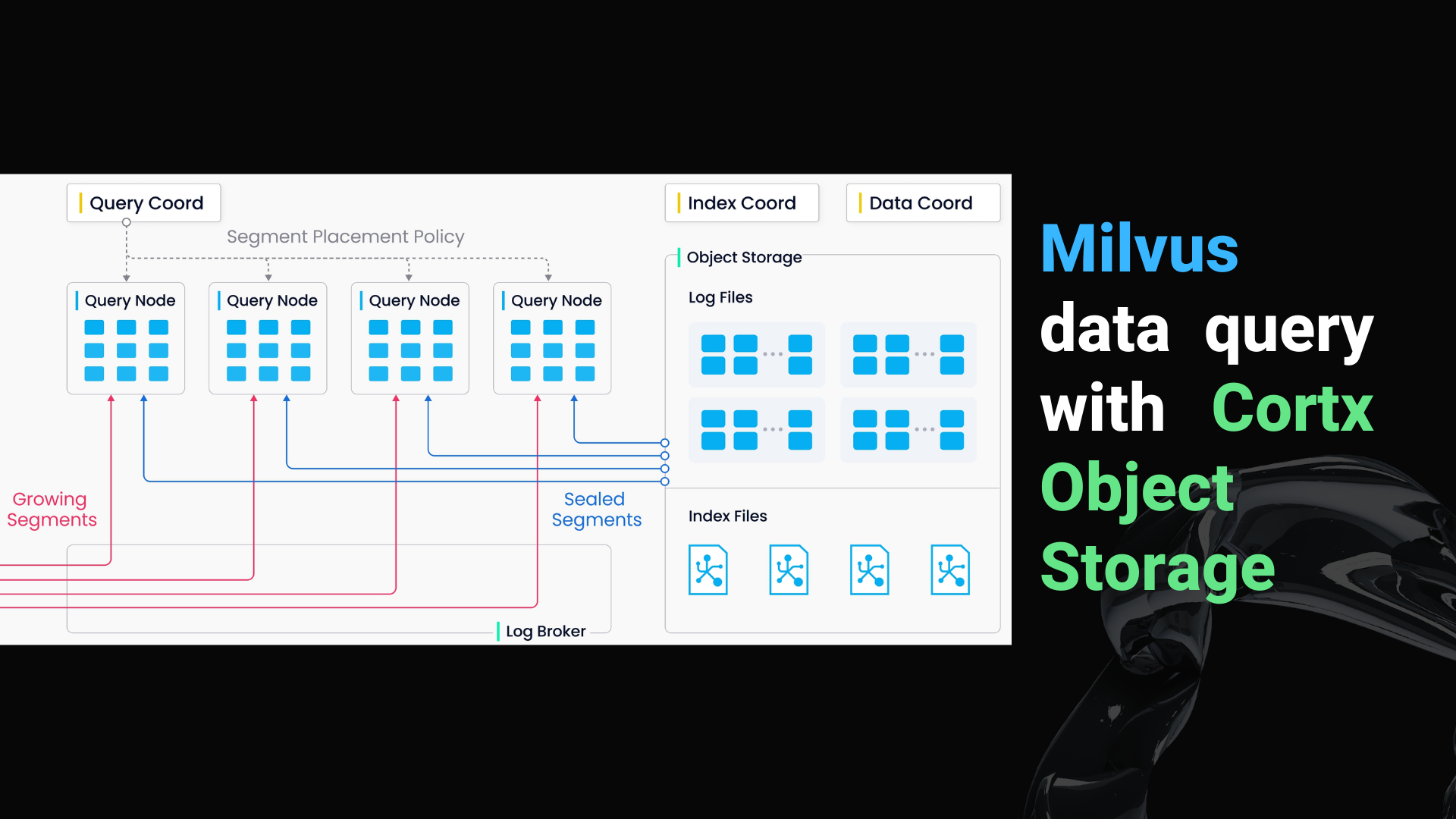
As shown above, Data query refers to the process of searching a specified collection for k number of vectors nearest to a target vector or for all vectors within a specified distance range to the vector. From the Index Building step, we learned that a collection in Milvus is split into multiple segments, and the query nodes load indexes by segment. When a search request arrives, it is broadcast to all query nodes for a concurrent search. Each node then prunes the local segments, searches for vectors meeting the criteria, and reduces and returns the search results.
So we see that Milvus uses logs as the data, mechanism throughout all processes for inter-data exchange between all Milvus components.
How we built it
The building part is constructed in two different steps. The first step is to set up Cortx Data Storage on VMWare:
- Follow this instruction to setup OVA on VMWare https://github.com/Seagate/cortx/blob/main/doc/ova/2.0.0/PI-6/CORTX_on_Open_Virtual_Appliance_PI-6.rst
- Load the OVA on VMWare https://github.com/Seagate/cortx/blob/main/doc/Importing_OVA_File.rst
- Set up S3 operations from the instructions https://github.com/Seagate/cortx/blob/main/doc/ova/2.0.0/PI-6/S3_IO_Operations.md
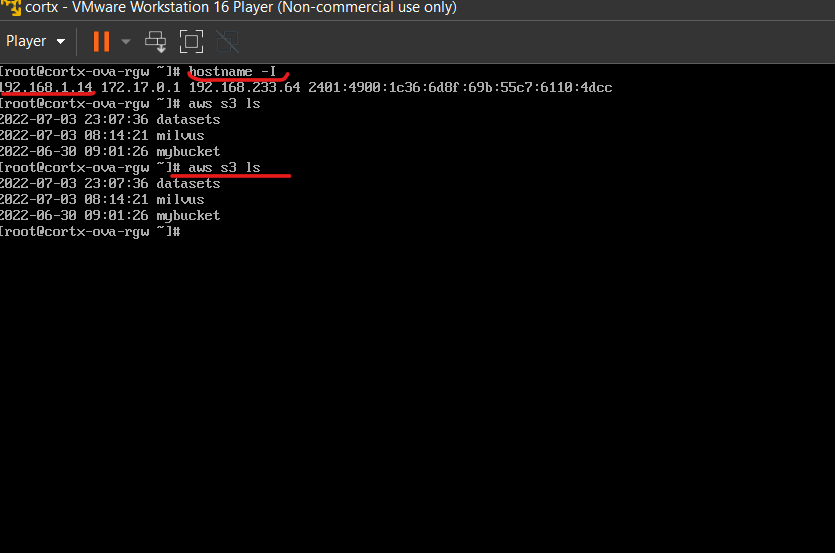
- If you are successful, you should be able to test aws commands on VMware and check your IP address which will be used as the Endpoint URL.
# hostname -I
# aws s3 cli

- Your endpoint URL for S3 APIs is http://YOURIP:31949 Test it with awscli from other systems.

Milvus Installation
Once your cortx VM is running successfully, you can proceed to Milvus standalone installation. Before that, you need docker, kubectl, helm to be installed on your system
Install docker for Ubuntu 20.04, from the guide here, https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-20-04
Install minikube for your system from guide here https://minikube.sigs.k8s.io/docs/start/
Install kubectl and helm
$ sudo apt install kubectl
$ sudo apt install helm
Start minikube
minikube start
Once your minikube had configured and started successfully, Add Milvus Helm repository.
$ helm repo add milvus https://milvus-io.github.io/milvus-helm/Update charts locally.
$ helm repo updateStart Milvus :- there are other ways to install as well check the official guide here, https://milvus.io/docs/v2.0.x/install_standalone-docker.md
$ helm install cortx milvus/milvus --set cluster.enabled=false --set externalS3.enabled=true --set externalS3.host='192.168.1.14' --set externalS3.port=31949 --set externalS3.accessKey=sgiamadmin --set externalS3.secretKey=ldapadmin --set externalS3.bucketName=mybucket --set externalS3.useSSL=false --set minio.enabled=false --set pulsar.enabled=false --set attu.enabled=true --set attu.ingress.enabled=false
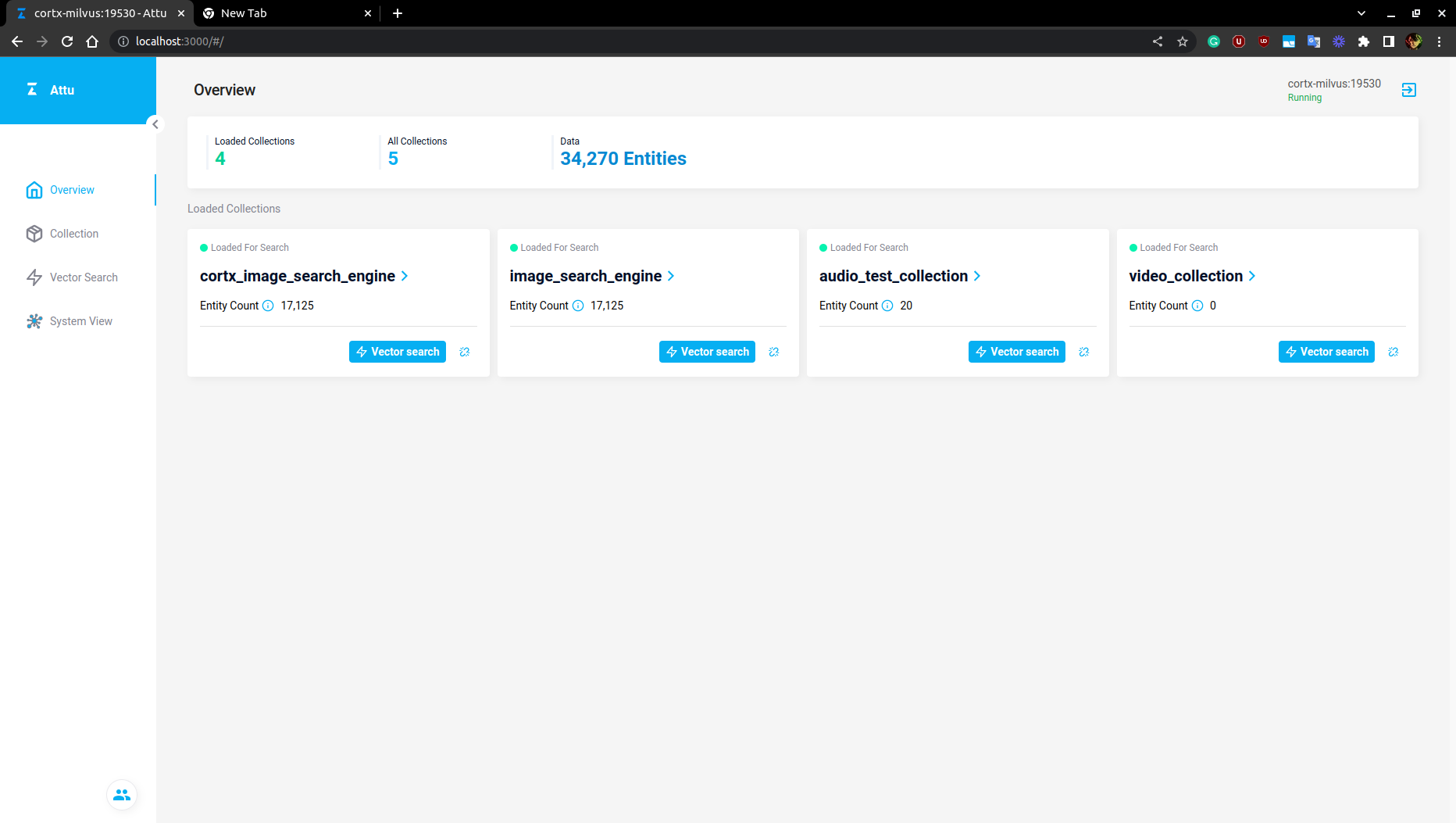
Check the status of the running pods.
kubectl get podsIt should show 1/1 in all services READY status. Check the above images.Forward the Milvus port to connect with Milvus Python APIs for our Neural search applications.
$ kubectl port-forward service/cortx-milvus 19530Forward the Milvus ATTU port which is to be used to monitor Milvus clusters, collections and entities.
$ kubectl port-forward service/cortx-milvus-attu 3000

Building Neural Search Application
We are going to test Image Reverse Search and Audio search for a command dataset using the Milvus tool (Although you can build as complicated as DNA, molecular and Q/A search applications as well). The source code repo contains a requirements.txt file for each sample application, make sure to install it.
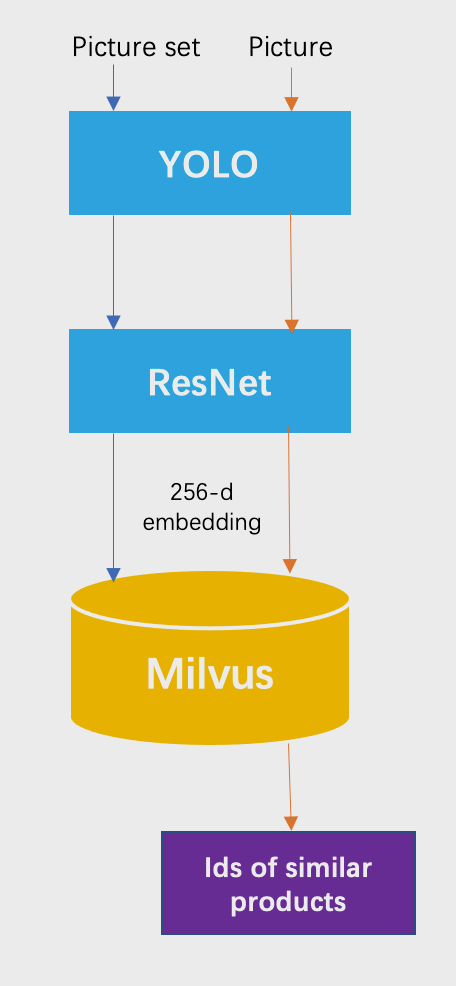
Milvus Image Reverse Search

- Open a Jupyter Notebook in VS code, and install the requirements.txt by running this command in a cell.
! pip install requirements.txt
- Start a redis server for metadata cache
! docker run --name redis -d -p 6379:6379 redis
- Connect to Milvus and Redis server
#Connectings to Milvus and Redis
from pymilvus import connections
import redis
connections.connect(host="127.0.0.1", port=19530)
red = redis.Redis(host = '127.0.0.1', port=6379, db=0)
red.flushdb()
- Create collection and add to index (Indexing is the process of efficiently organizing data, and it plays a major role in making similarity search useful by dramatically accelerating time-consuming queries on large datasets.)
#Creat a collection
from pymilvus import CollectionSchema, FieldSchema, DataType, Collection
collection_name = "image_search_engine"
dim = 2048
default_fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
default_schema = CollectionSchema(fields=default_fields, description="Search Image collection")
collection = Collection(name=collection_name, schema=default_schema)
# Create IVF_SQ8 index to the collection
default_index = {"index_type": "IVF_SQ8", "params": {"nlist": 2048}, "metric_type": "L2"}
collection.create_index(field_name="vector", index_params=default_index)
collection.load()
- Download training dataset for Neural Search using Cortx S3 API
import boto3
# create bucket named the current date
ACCESS_KEY = 'sgiamadmin'
SECRET_ACCESS_KEY = 'ldapadmin'
END_POINT_URL = 'http://192.168.1.14:31949'
s3_client = boto3.client('s3', endpoint_url=END_POINT_URL,
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_ACCESS_KEY,
verify=False)
s3_resource = boto3.resource('s3', endpoint_url=END_POINT_URL,
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_ACCESS_KEY,
region_name='None',
verify=False)
buckets = s3_client.list_buckets()
if buckets['Buckets']:
for bucket in buckets['Buckets']:
print(bucket)
s3_resource.Bucket('datasets').download_file('VOCtrainval_11-May-2012.zip', 'VOCtrainval_11-May-2012.zip')
- Extract the zip files and remove unnecessary data.
import zipfile
with zipfile.ZipFile("VOCtrainval_11-May-2012.zip","r") as zip_ref:
zip_ref.extractall("./VOCtrainval_11-May-2012")
! rm -rf ./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/Annotations
! rm -rf ./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/ImageSets
! rm -rf ./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/Annotations
! rm -rf ./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/SegmentationClass
! rm -rf ./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/SegmentationObject
- Insert the data into Milvus tool (This is the final step and your search app is ready for new images)
import os
import towhee
data_dir = "./VOCtrainval_11-May-2012/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/" # You can replace this to your local directory of image folders
pattern = "*.jpg"
subfolders = [os.path.join(data_dir, x) for x in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, x))]
print(subfolders)
steps = len(subfolders)
step = 1
for sub_dir in subfolders:
img_pattern = os.path.join(sub_dir, pattern)
paths = towhee.glob(img_pattern).to_list()
vectors = towhee.glob(img_pattern).exception_safe() \
.image_decode() \
.image_embedding.timm(model_name="resnet50") \
.drop_empty() \
.tensor_normalize() \
.to_list()
mr = collection.insert([vectors])
ids = mr.primary_keys
for x in range(len(ids)):
red.set(str(ids[x]), paths[x])
print("Inserting progress: " + str(step) + "/" + str(steps))
step += 1
- Now you can search for any similar images in the image dataset using the query vectors)
# Searching
import time
search_params = {"metric_type": "L2", "params": {"nprobe": 32}}
start = time.time()
results = collection.search(query_vectors, "vector", param=search_params, limit=3, expr=None)
end = time.time() - start
print("Search took a total of: ", end)
#Helper display function
import matplotlib.pyplot as plt
from PIL import Image
def show_results(query, results, distances):
fig_query, ax_query = plt.subplots(1,1, figsize=(5,5))
ax_query.imshow(Image.open(query))
ax_query.axis('off')
ax_query.set_title("Searched Image")
res_count = len(results)
fig, ax = plt.subplots(1,res_count,figsize=(10,10))
for x in range(res_count):
ax[x].imshow(Image.open(results[x]))
ax[x].axis('off')
dist = str(distances[x])
dist = dist[0:dist.find('.')+4]
ax[x].set_title("D: " +dist)
for x in range(len(results)):
query_file = search_images[x]
result_files = [red.get(y.id).decode('utf-8') for y in results[x]]
distances = [y.distance for y in results[x]]
show_results(query_file, result_files, distances)
Image search results

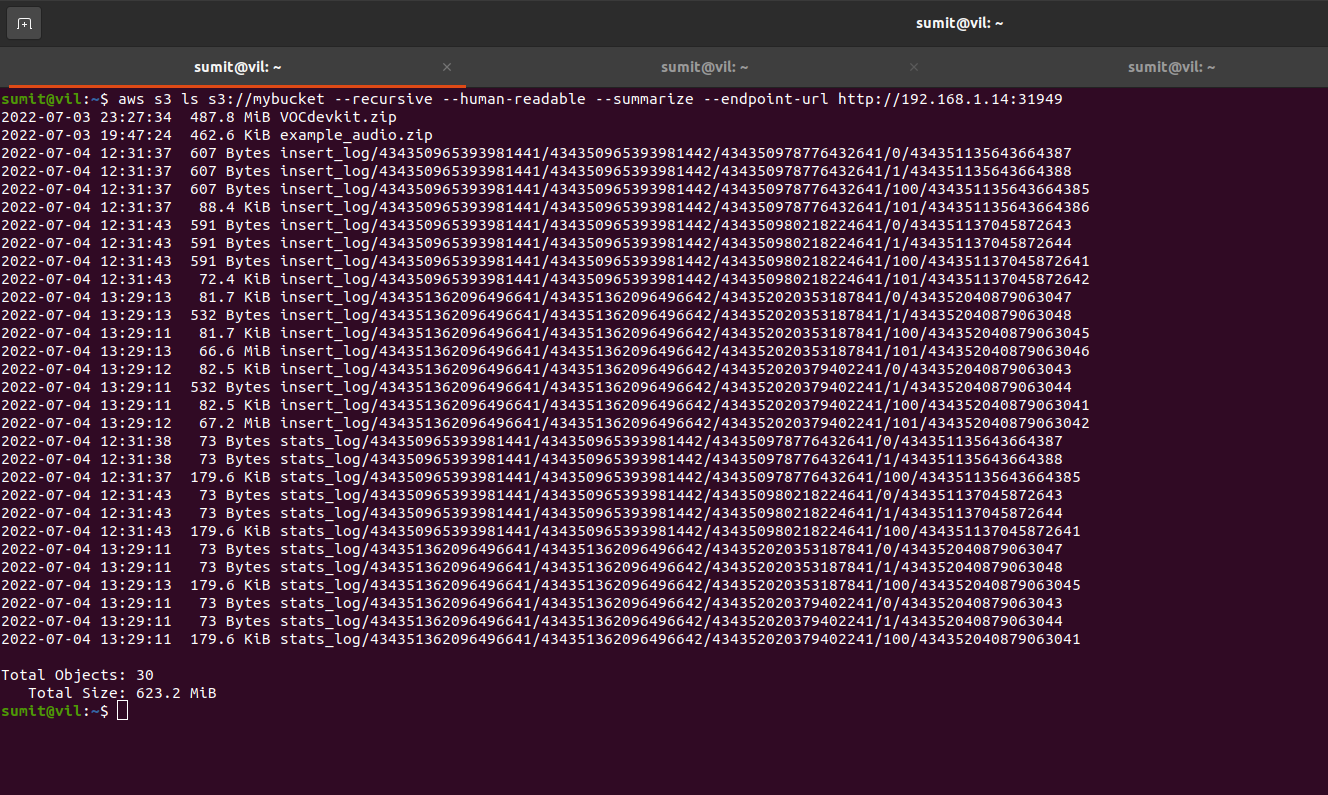
If you notice carefully, the size and number of objects keep growing in our Cortx bucket, since all the queries, indexes and logs are being stored for faster search retrieval and loading for our app. This is hugely beneficial as it prevents reindexing of data multiple times.

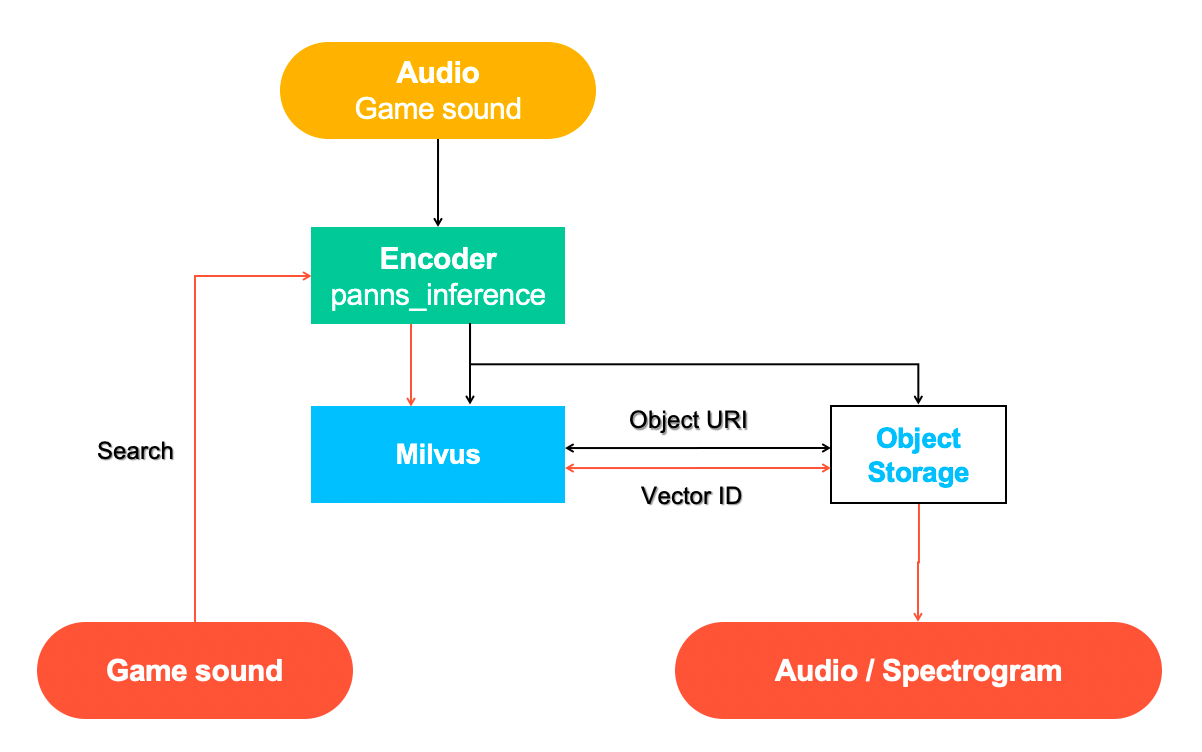
Milvus Audio Neural Search
In this demo, we will run an audio search training on the dataset uploaded on Cortx for faster audio searches using vector queries.

- Create a new collection
#Creating collection
import time
red.flushdb()
time.sleep(.1)
collection_name = "audio_test_collection"
if utility.has_collection(collection_name):
print("Dropping existing collection...")
collection = Collection(name=collection_name)
collection.drop()
#if not utility.has_collection(collection_name):
field1 = FieldSchema(name="id", dtype=DataType.INT64, descrition="int64", is_primary=True,auto_id=True)
field2 = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, descrition="float vector", dim=2048, is_primary=False)
schema = CollectionSchema(fields=[ field1,field2], description="collection description")
collection = Collection(name=collection_name, schema=schema)
print("Created new collection with name: " + collection_name)
#Indexing collection
if utility.has_collection(collection_name):
collection = Collection(name = collection_name)
default_index = {"index_type": "IVF_SQ8", "metric_type": "L2", "params": {"nlist": 16384}}
status = collection.create_index(field_name = "embedding", index_params = default_index)
if not status.code:
print("Successfully create index in collection:{} with param:{}".format(collection_name, default_index))
- Download audio dataset from S3 bucket and unzip it
s3_resource.Bucket('datasets').download_file('example_audio.zip', 'example_audio.zip')
import zipfile
with zipfile.ZipFile("example_audio.zip","r") as zip_ref:
zip_ref.extractall("./example_audio")
- Inserting data
import os
import librosa
import gdown
import zipfile
import numpy as np
from panns_inference import SoundEventDetection, labels, AudioTagging
data_dir = './example_audio'
at = AudioTagging(checkpoint_path=None, device='cpu')
def embed_and_save(path, at):
audio, _ = librosa.core.load(path, sr=32000, mono=True)
audio = audio[None, :]
try:
_, embedding = at.inference(audio)
embedding = embedding/np.linalg.norm(embedding)
embedding = embedding.tolist()[0]
mr = collection.insert([[embedding]])
ids = mr.primary_keys
collection.load()
red.set(str(ids[0]), path)
except Exception as e:
print("failed: " + path + "; error {}".format(e))
print("Starting Insert")
for subdir, dirs, files in os.walk(data_dir):
for file in files:
path = os.path.join(subdir, file)
embed_and_save(path, at)
print("Insert Done")
- Search can be done now on embedded vector audio NumPy array

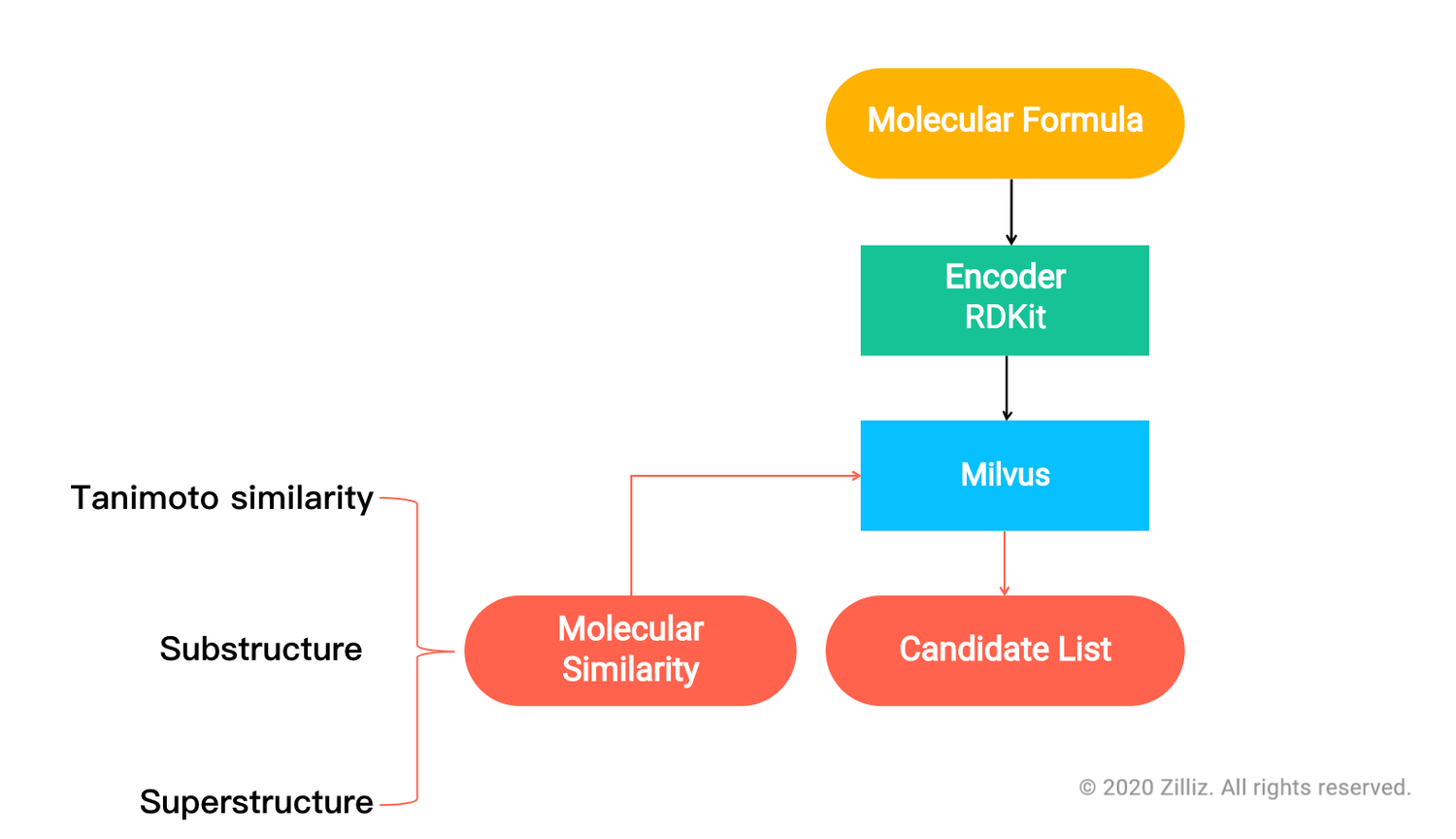
Milvus for Molecular similarity search and heterogenous data

Challenges we ran into
- Opencloudshare Cortx instance gave lots of problems and disconnections, so installed Cortx locally on VM.
- Milvus cluster requires a better computer system and nodes (could not test in cluster mode)
Accomplishments that we're proud of
- Using Cortx S3 as Object Storage Engine for Neural Search is something new that we haven't come across (Elastic search is also an option but still Neural search is more dynamic)
- The insert_log, stats_log and index loaded correctly from S3 Cortx bucket even after the Milvus application was released from memory (true data persistence which prevents repetitive indexing and log ingestion)
- Milvus a highly industry-recognized tool is going to be a major transition for data searches (3D models, documents, DNA, molecules and all kind of unstructured data in all fields)
What's next for Cortx Object Storage Integration with Milvus.io
- Next thing I plan for is full-scale heterogenous searches for text, documents, 3D models, DNA and molecular sequences.
- Also, integrating UI for data management and monitoring of Cortx S3 (volume of data can be high for big datasets, make sure we have enough space)
Built With
- amazon-web-services
- cortx
- docker
- helm
- milvus
- minikube
- mysql
- python
- redis
- s3



")

Log in or sign up for Devpost to join the conversation.