Inspiration
I have a differential equations midterm on Monday. I've got 15 PDFs, 3 lecture transcripts, handwritten notes, and screenshots scattered across my laptop. I spent 6 hours this weekend not studying — but finding and organizing content I'd already learned.
That's broken.
I built Cortex because I was tired of the scavenger hunt. Drag a PDF into the notch, 60 seconds later you're studying auto-generated flashcards from a knowledge graph. Zero manual organization. Zero typing flashcards. Just drop content and study.
What it does
Three surfaces, one pipeline:
1. Cortex Drop (macOS notch app)
- Drag PDFs, URLs, or images into your Mac's notch
- ⌘V to paste text/screenshots/URLs
- Smart course routing: "backpropagation.pdf" auto-assigns to CS 229
- Status pill: "Sending → Sent to [Course Name]"
2. Cortex API (8-stage pipeline)
Runs async while you continue working:
Parse → PDFs (pymupdf), URLs (trafilatura), images (Claude vision OCR with LaTeX)
Chunk → 500-token sliding windows
Embed → OpenAI text-embedding-3-small (1536-dim vectors)
Extract → Claude Sonnet 4.5 pulls 0–6 concepts per chunk (title, definition, gotchas, examples)
Resolve → Course-scoped vector similarity prevents duplicates:
- Cosine ≥ 0.92 → merge
- 0.80–0.91 → LLM tiebreaker
- < 0.80 → new concept
Edges → Infer prerequisites via LLM, co-occurrence from shared chunks
Flashcards → 3–6 auto-generated cards per concept (definition/application/gotcha/compare)
Signals → Detect struggle patterns (repeated questions, gotcha-dense material, practice failures)
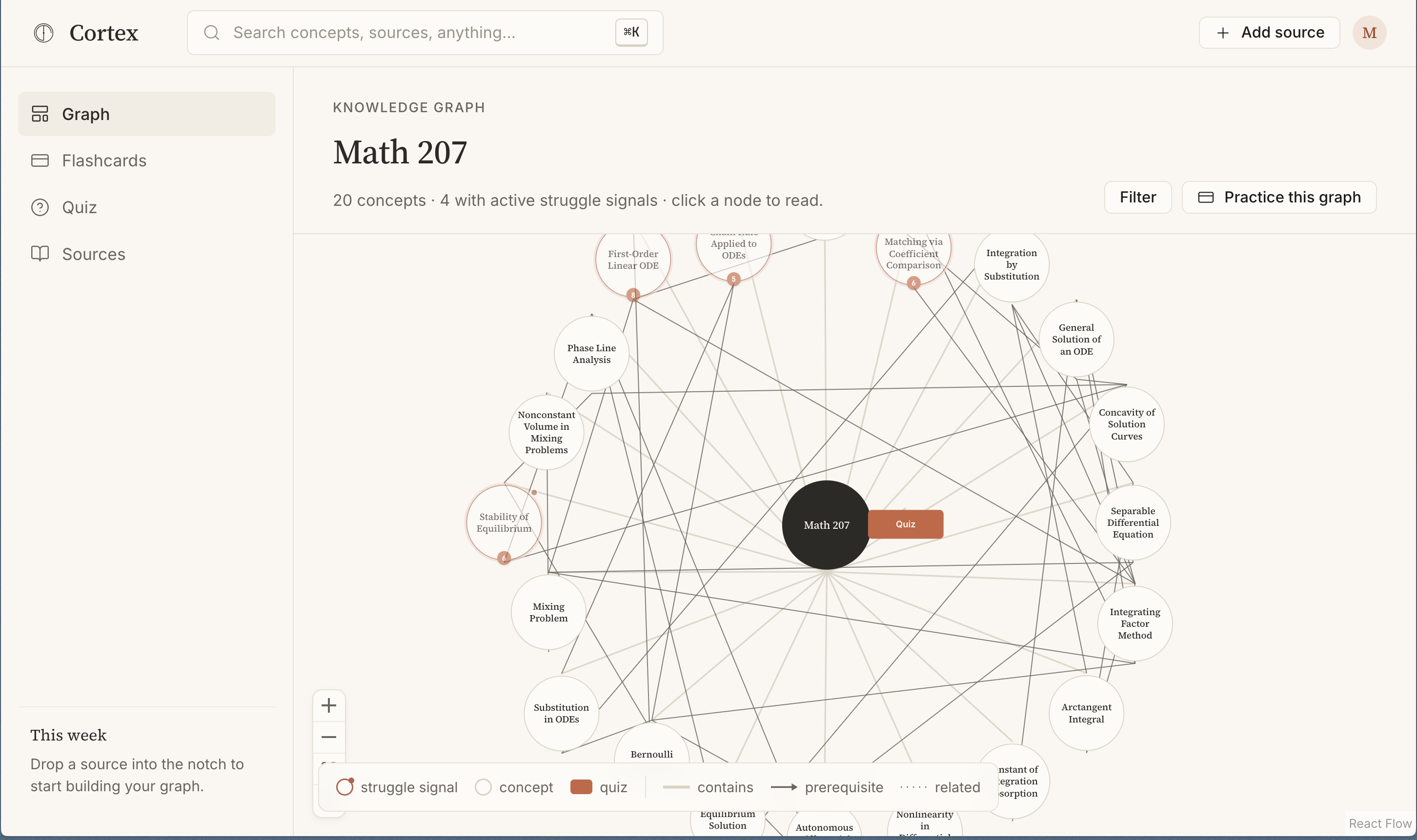
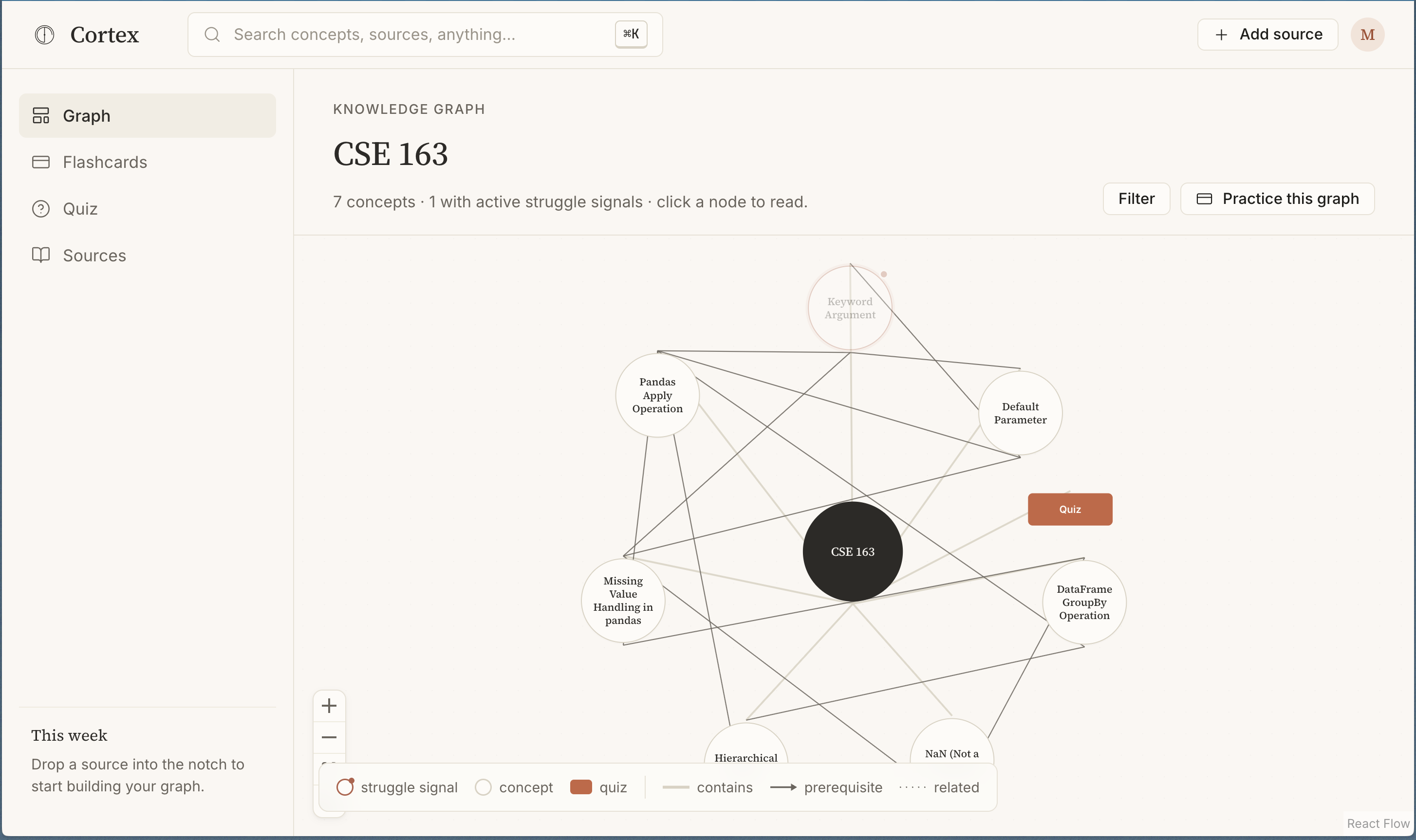
3. Cortex Web (React Flow graph)
- Interactive graph: concepts sized by source count, colored by struggle signals, laid out by prerequisite depth
- Pulsing red dots on struggling concepts
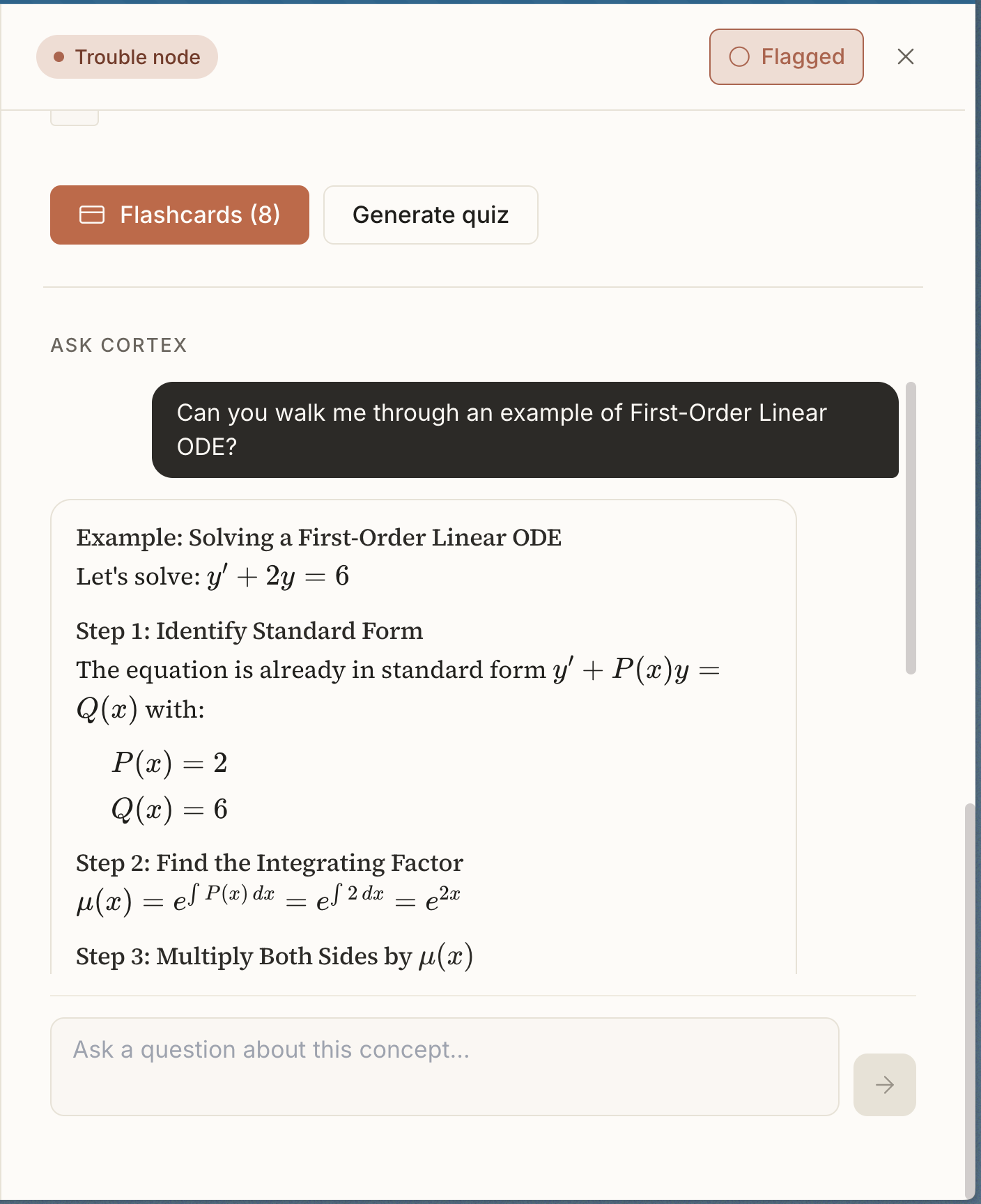
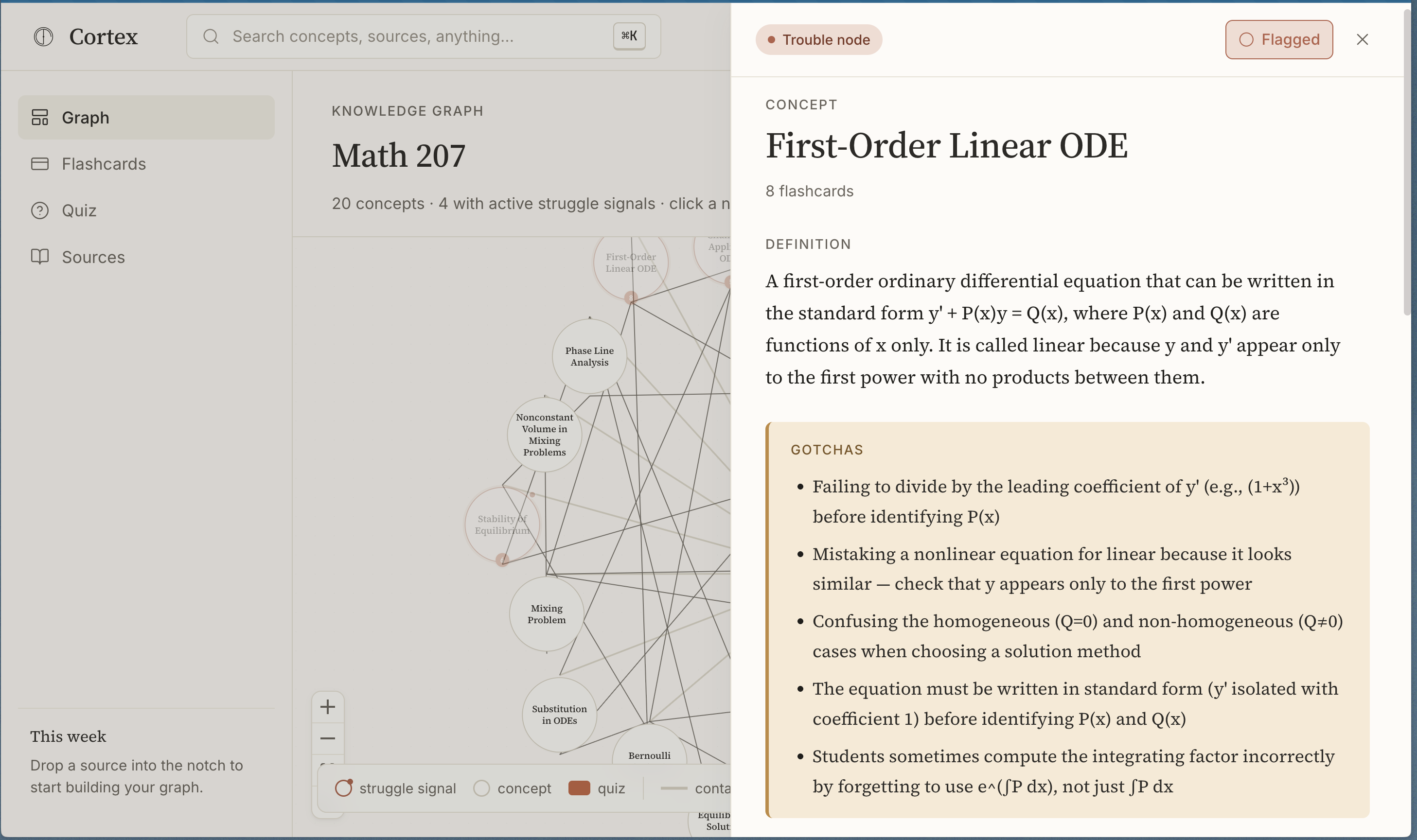
- Click a node → definition, gotchas, source citations with page numbers
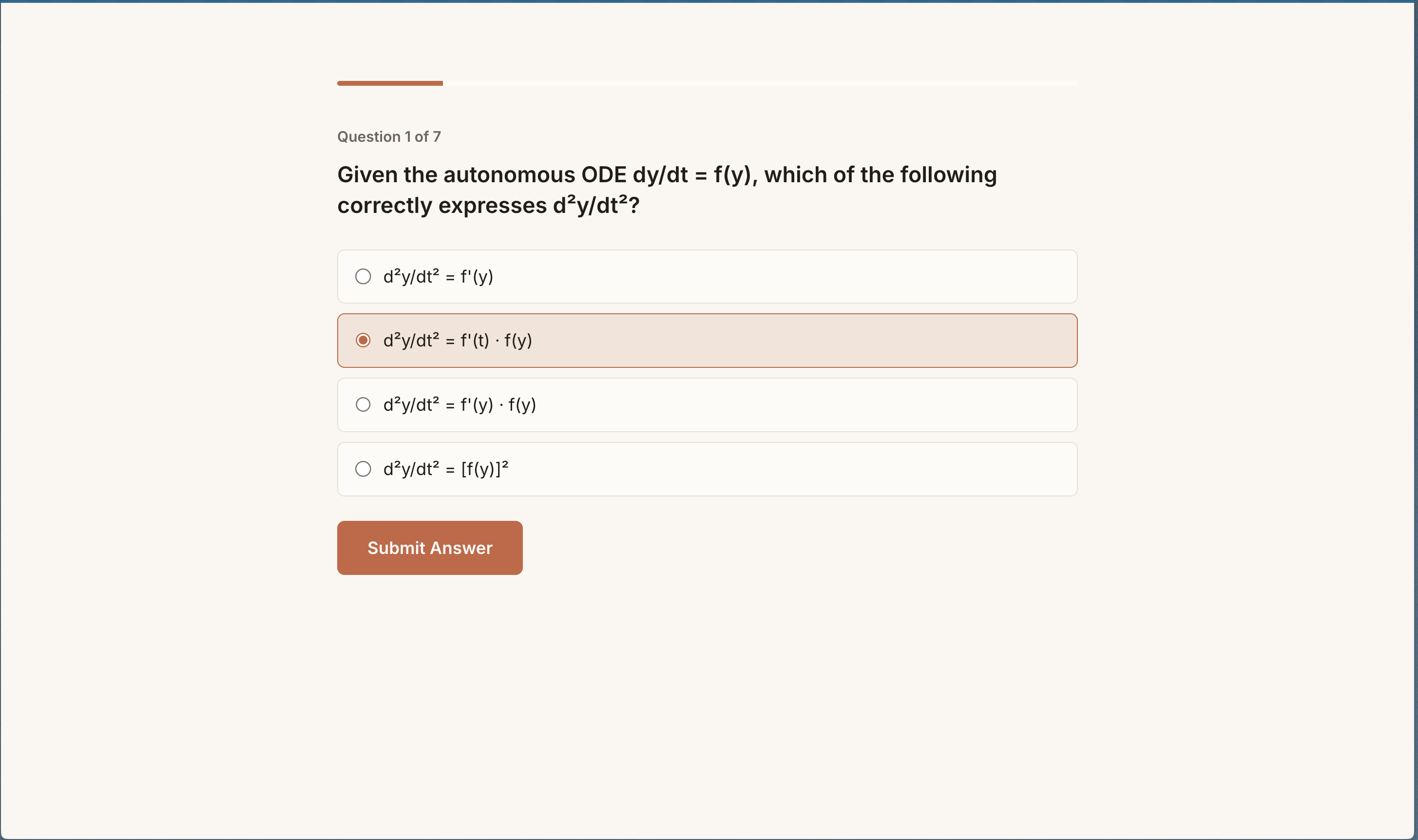
- One-click quiz targets weak spots
- Flip-card study mode
How I built it
Stack:
- Notch: Swift/SwiftUI fork of NotchDrop (MIT) — 4 files in isolated
Cortex/subfolder - Backend: FastAPI + Postgres 16 + pgvector (HNSW index)
- AI: Claude Sonnet 4.5 (extraction, OCR), OpenAI embeddings
- Frontend: Next.js 14, React Flow, dagre layout, Tailwind
Challenges
Concept deduplication was the hardest problem
Early versions created a new node for every chunk, leading to graphs with dozens of near-identical "Newton's Second Law" nodes. The fix was strict course-scoped resolution with a tunable similarity threshold — concepts only merge within a course, never across them.
The notch surface introduced Swift ↔ backend communication challenges
URLSession doesn't attach an Origin header, which broke standard CORS middleware. The fix was a custom middleware layer that treats a missing Origin as trusted-local rather than rejecting it.
Processing state management
Documents go through pending → processing → done states. On server restart, any document stuck at processing would hang forever. The fix: reset all processing → pending at FastAPI startup.
Accomplishments
Live drop works consistently: PDF → 60s → new graph nodes with edges. No competitor does this.
Deduplication actually works: 3 PDFs about "Gradient Descent" = 1 rich node, not 3 duplicates.
Flashcard quality is tutor-grade: Gotcha cards like "T/F: Gradient descent always finds global minimum" — not "Q: What is X?"
Clean NotchDrop fork: 4 files, minimal diff, reverts to original behavior when disabled.
What I learned
Technical
- You don't need fancy separate tools for AI search — a regular database with the right extension handles it at this scale
- Small infrastructure decisions (like how a server restarts, or how CORS headers work) can silently break your whole app if you miss them
- CSS animations are deceptively tricky to get feeling right
Product
- Simplicity ships. Cutting SRS scheduling and mastery scores wasn't a compromise — it made the core loop cleaner and faster to build
- The ingestion UX (drag into the notch, pick a course, done) needed to be invisible or people wouldn't use it
- A knowledge graph is only useful if the same concept doesn't show up fifteen times — deduplication is the product
Process
- Breaking the project into strict phases (ingest → graph → flashcards → quiz) kept scope from exploding
- Hand-writing database migrations instead of auto-generating them saved hours of debugging edge cases
- Treating the macOS app, backend, and frontend as three separate surfaces with clear contracts between them made it possible to work on each without breaking the others
What's next
v1.1 (make it real):
- SRS scheduling (due dates, intervals) — flashcards are flip-only right now
- Mastery scoring — graph colored by 0–1 mastery heat map
- Multi-user accounts (currently single-user)
v1.5 (expand surface):
- YouTube transcript ingestion with timestamp citations
- Chat log ingestion (Slack/Discord) for struggle detection
- Adaptive quizzing (real-time difficulty adjustment)
v2 (study platform):
- Collaborative graphs for study groups
- TA Mode (instructor analytics on student submissions)
- Mobile app (camera OCR, offline review)
North star: Eliminate the creation tax on flashcard learning. You read, Cortex builds the graph, you study.
Built With
- anthropic-claude
- docker
- fastapi
- nextjs
- openai
- pgvector
- postgresql
- python
- react
- react-flow
- sqlalchemy
- swift
- swiftui
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.