CORTEX
Inspiration
Two weeks. That is how long short-form creators currently wait for analytics to tell them whether a clip landed. By then the trend is dead. The two questions every creator asks before posting — Will this work? and Am I repeating myself? — have no good tool, despite both being brain-pattern questions.
In March 2026, Meta FAIR released TRIBE v2: a transformer that predicts the average human's whole-brain BOLD response at 1Hz across 20,484 cortical vertices, trained on people watching real content while in fMRI. The ASUS GX10 — Blackwell GB10, 128GB unified memory — made it deployable: enough RAM to hold TRIBE (~30GB), Gemma 2B, Whisper, and nomic-embed concurrently. No cloud GPU has this latency. No laptop has this RAM. A neuroscience model in a backpack that tells you what a viewer's brain will do with your draft, before you post.
What we built
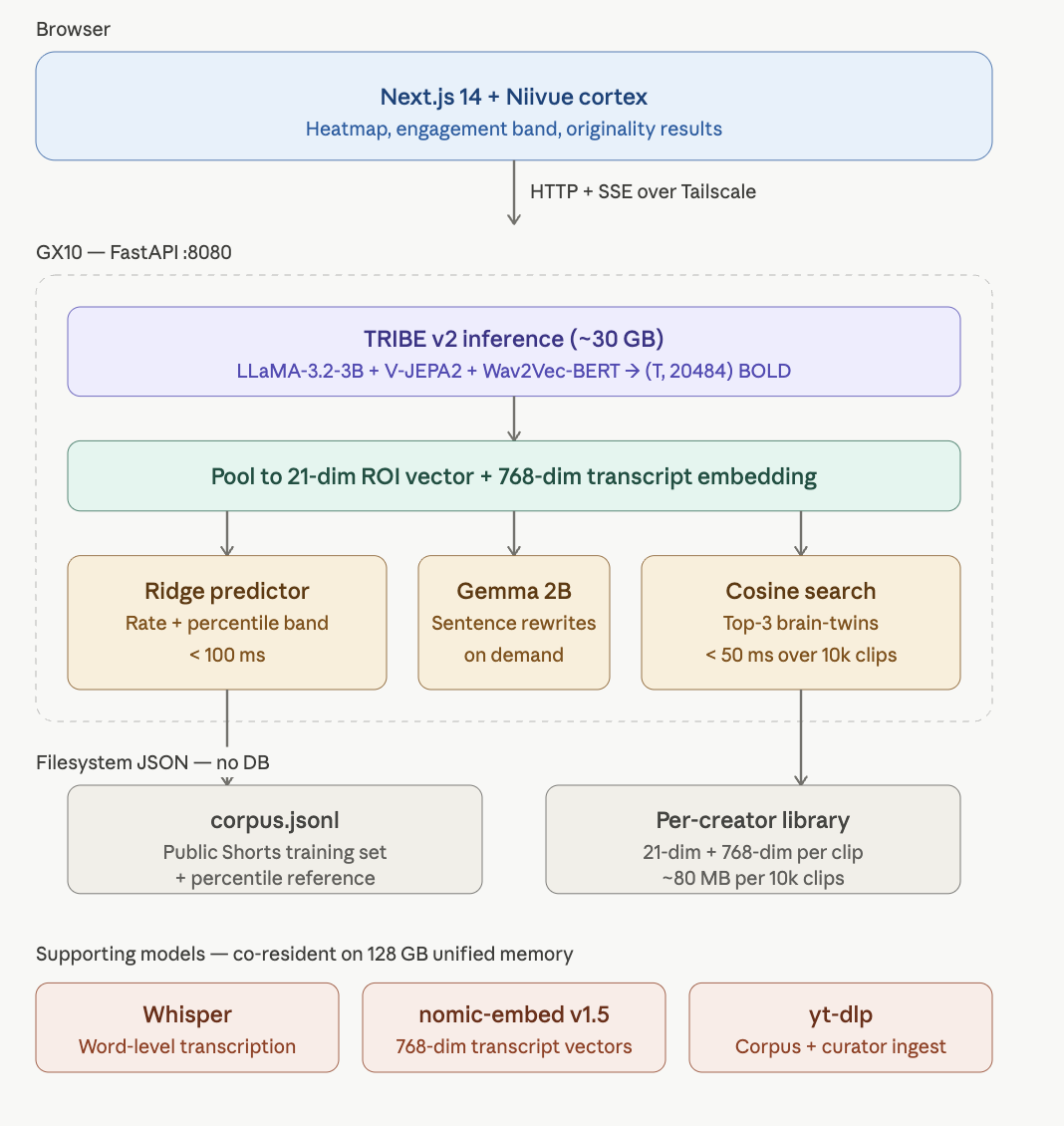
CORTEX runs one TRIBE pass on a draft (text, audio, or video) to produce a per-second whole-brain BOLD prediction. Three things fall out of that single inference:
- A brain heatmap. Per-sentence coloring for text (cold sentences trigger a Gemma 2B rewrite that preserves the claim), a two-track timeline for audio, and three live tracks for video — click a red cold-zone band to jump the player there.
- An engagement prediction. A 21-dim ROI feature vector plus three context dims feeds a Ridge regression, returning a predicted rate and a percentile band against real public Shorts. "Top 25% at your account size" is the load-bearing output, not "8.4%."
- An originality search. The creator's library persists as (21-dim pooled, 768-dim transcript) — no raw video kept. Cosine-rank in under 50ms returns the top-3 brain-twins with a per-region breakdown. A 10,000-clip back-catalog fits in ~80MB.
Inference runs once. All downstream calls reuse the cached features.
How we built it
Filesystem JSON and HTTP/SSE end to end — no Chroma, no SQLite, no vector DB, no WebSockets. For under 10k clips, brute-force numpy cosine beats any index after round-trip cost. Frontend is Next.js 14, TypeScript, Tailwind, and Niivue for the WebGL2 cortical surface. Backend is FastAPI on Python 3.11 running TRIBE v2 (LLaMA-3.2-3B + V-JEPA2 + Wav2Vec-BERT internally), Gemma 2B, Whisper, nomic-embed-text-v1.5, and scikit-learn Ridge. Everything runs on the GX10 over a Tailscale tunnel — nothing leaves the box.
We picked Ridge deliberately. The literature on virality says only 10–25% of variance is content-derivable; the rest is algorithm and timing. A bigger model would memorize noise. The predictor interface is swappable for XGBoost or a small MLP without touching anything else.
Challenges we ran into
TRIBE v2 postdates every LLM's training data, so day one was reading the FAIR repo cold and wrestling a NumPy <2.1 ABI pin, LLaMA-3.2-3B's HuggingFace gating, and a vendor patch in cortexlab.data.transforms before any inference happened. Predicting raw engagement rate did not work — the labels are right-skewed and broke Ridge's residual assumption, so we log-transformed and clamped. TRIBE is not thread-safe, which corrupted state until we wrapped the service in an asyncio.Lock(). And linear interpolation between 1Hz BOLD frames looked like a slideshow until we added smoothstep easing on the client up to 30fps.
What we learned
The biggest lesson was about what not to build. We considered auto-editing video by cutting cold zones and decided against it. The diagnostic is the deliverable. Creators do not want a tool that edits for them; they want one that explains why a clip is not landing.
The second lesson was idle compute as a feature. The GX10 sits idle ~95% of the time. That observation led us to design NemoClaw, an idle-time curator agent that picks queries via Gemma, runs yt-dlp ingest, TRIBE-encodes new clips, and refits the predictor with R²-rollback if new rows hurt the model. Reframing unused Blackwell silicon as a self-improving research assistant changed how we pitched the project.
What's next
Pluggable predictor (XGBoost or a small MLP). Merge NemoClaw to main and run it nightly. Multi-tenant library with auth. A phone-side ZETIC integration so creators can run a lightweight first-pass on-device and reserve the GX10 for full inference.
Built With
- 14
- 18
- 2b
- blackwell
- cloudinary
- css
- events
- fastapi
- framer-motion
- gb10
- gemma
- gx10
- huggingface
- llama-3.2-3b
- lucide-react
- next.js
- niivue
- nomic-embed-text-v1.5
- nvidia
- openai
- pydantic
- python
- pytorch
- react
- scikit-learn
- sentence-transformers
- server-sent
- sonner
- sse-starlette
- tailscale
- tailwind
- tribev2
- typescript
- v-jepa2
- wav2vec-bert
- whisper
- wireguard
- yt-dlp
- zustand



Log in or sign up for Devpost to join the conversation.