Inspiration
Modern engineering work is no longer bottlenecked by knowledge, but by cognitive bandwidth. Engineers constantly context-switch, experience unnoticed physiological stress (like HRV drops), and enter high-pressure meetings already mentally overloaded without realizing the buildup from prior tasks.
Most existing “wellness assistants” operate in the cloud and analyze artifacts of work (Slack messages, calendars, commits) rather than the process of work itself. They provide generic, reactive advice after overload has already occurred.
We wanted something fundamentally different: a system that understands the live process of working screen activity, facial attention signals, biometrics, and workflow patterns, and learns individualized behavior over time.
Because this data is extremely sensitive, it cannot be shipped to the cloud. This requirement made a fully local system not just ideal, but necessary.
That idea became Cortex: a local-first cognitive operating system that observes, understands, and intervenes in real time.
What it does
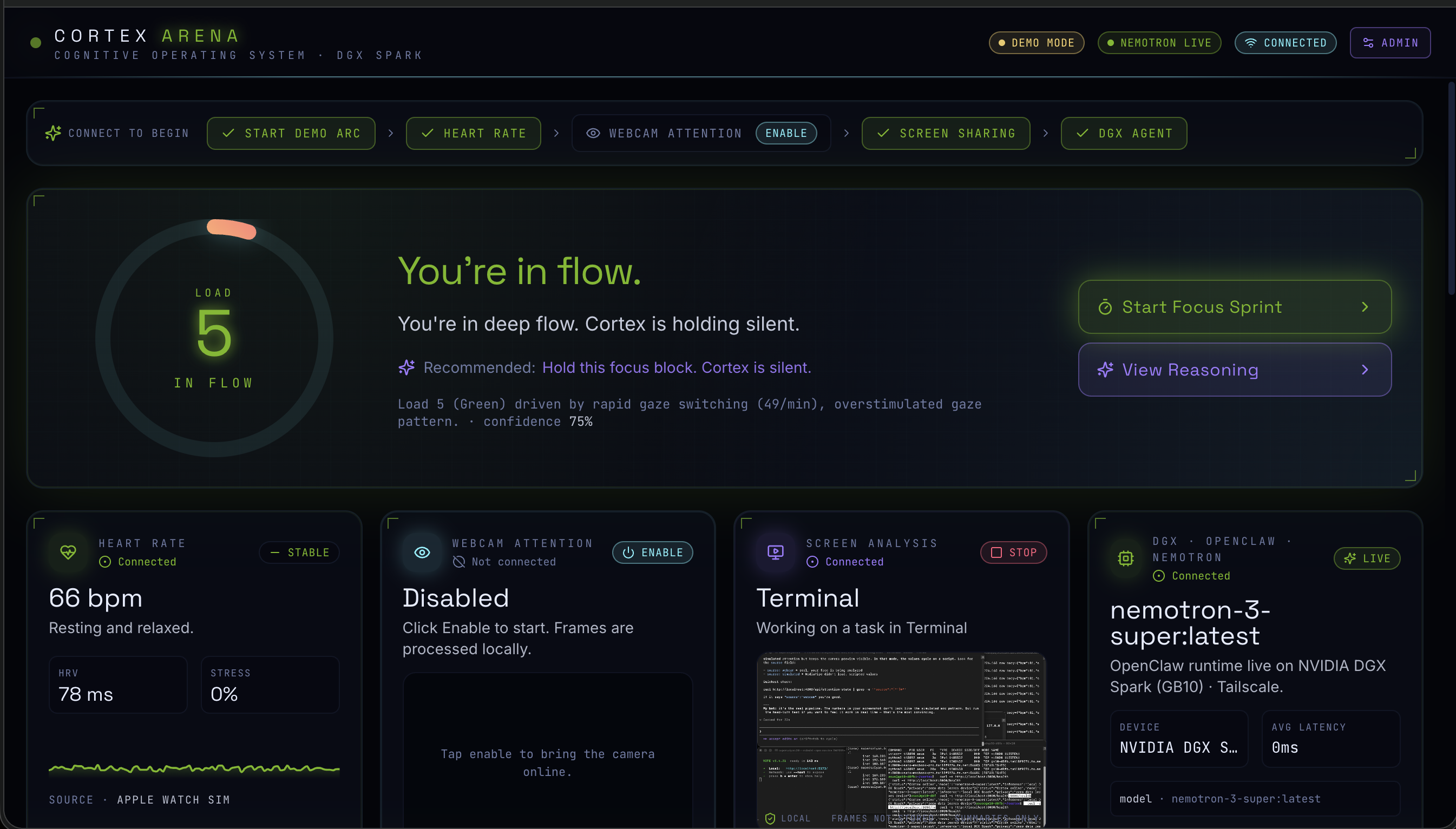
Cortex is an autonomous cognitive operating system - essentially a Jarvis for your productivity.
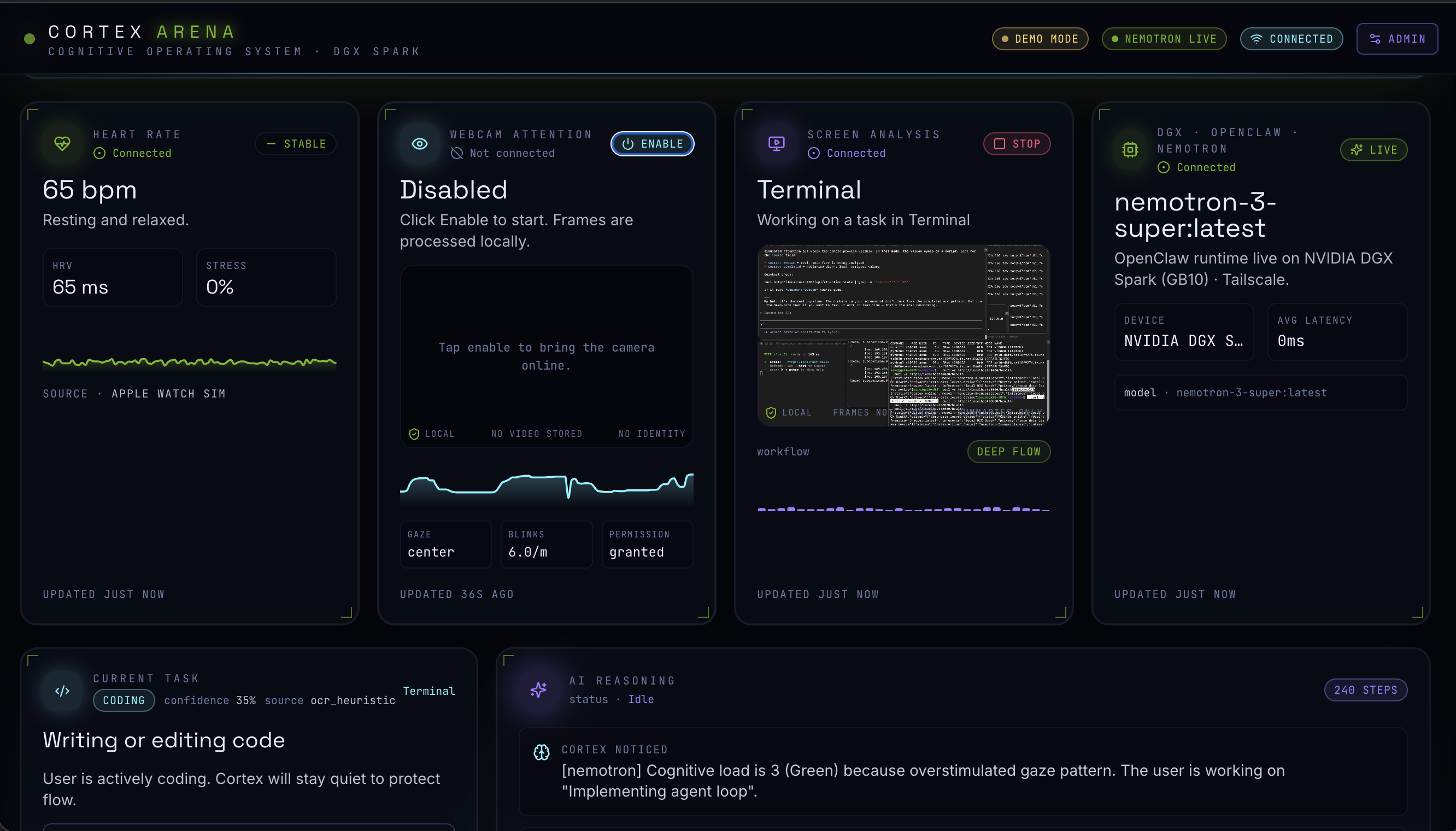
It continuously senses three streams of data: biometrics (heart rate, HRV, typing speed, error rate, and deadline pressure simulated from an Apple Watch), facial state (gaze direction, blink rate, head pose, and focus stability via MediaPipe FaceMesh), and on-screen activity (captured via getDisplayMedia and OCR'd locally with Tesseract.js).
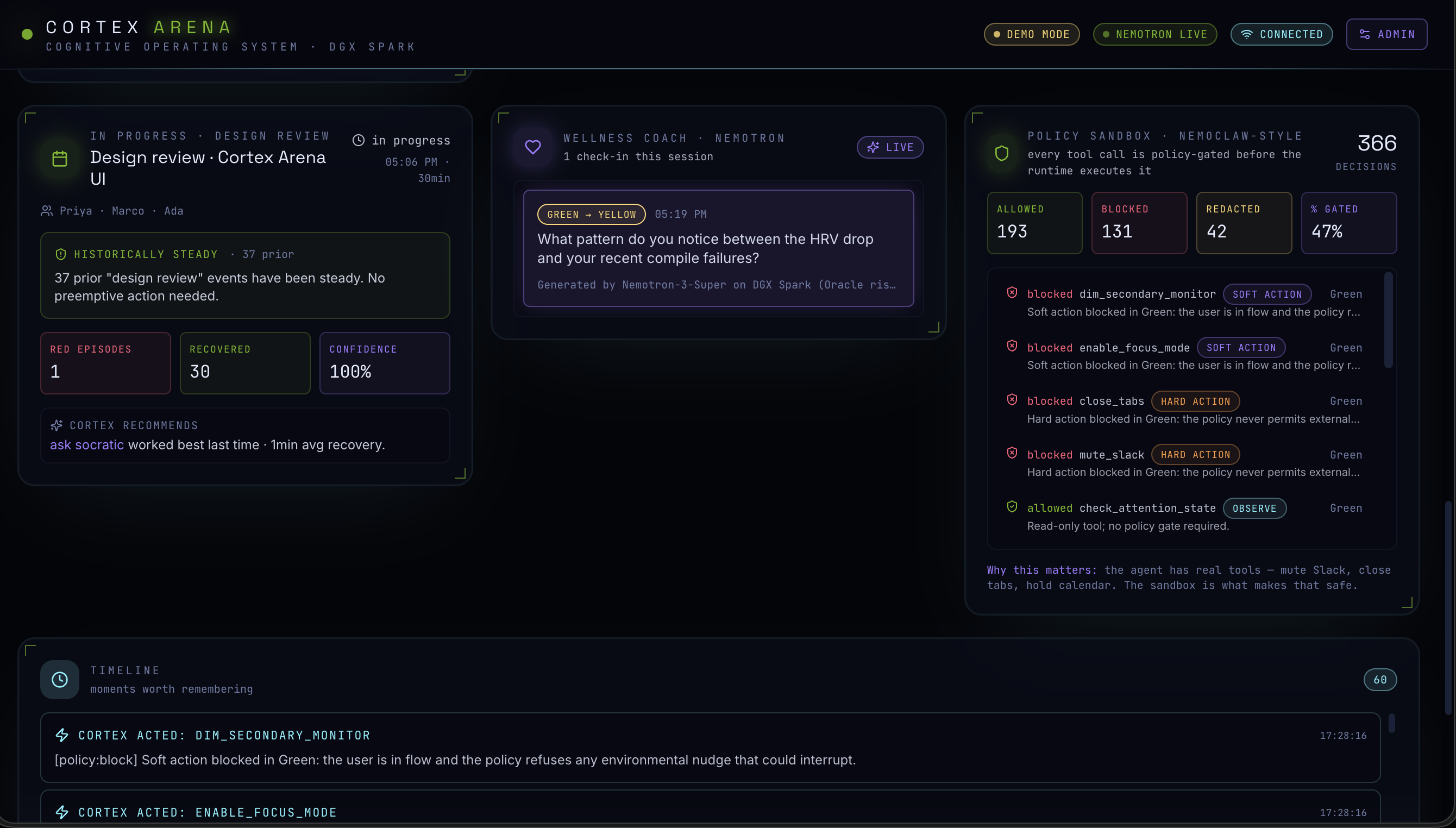
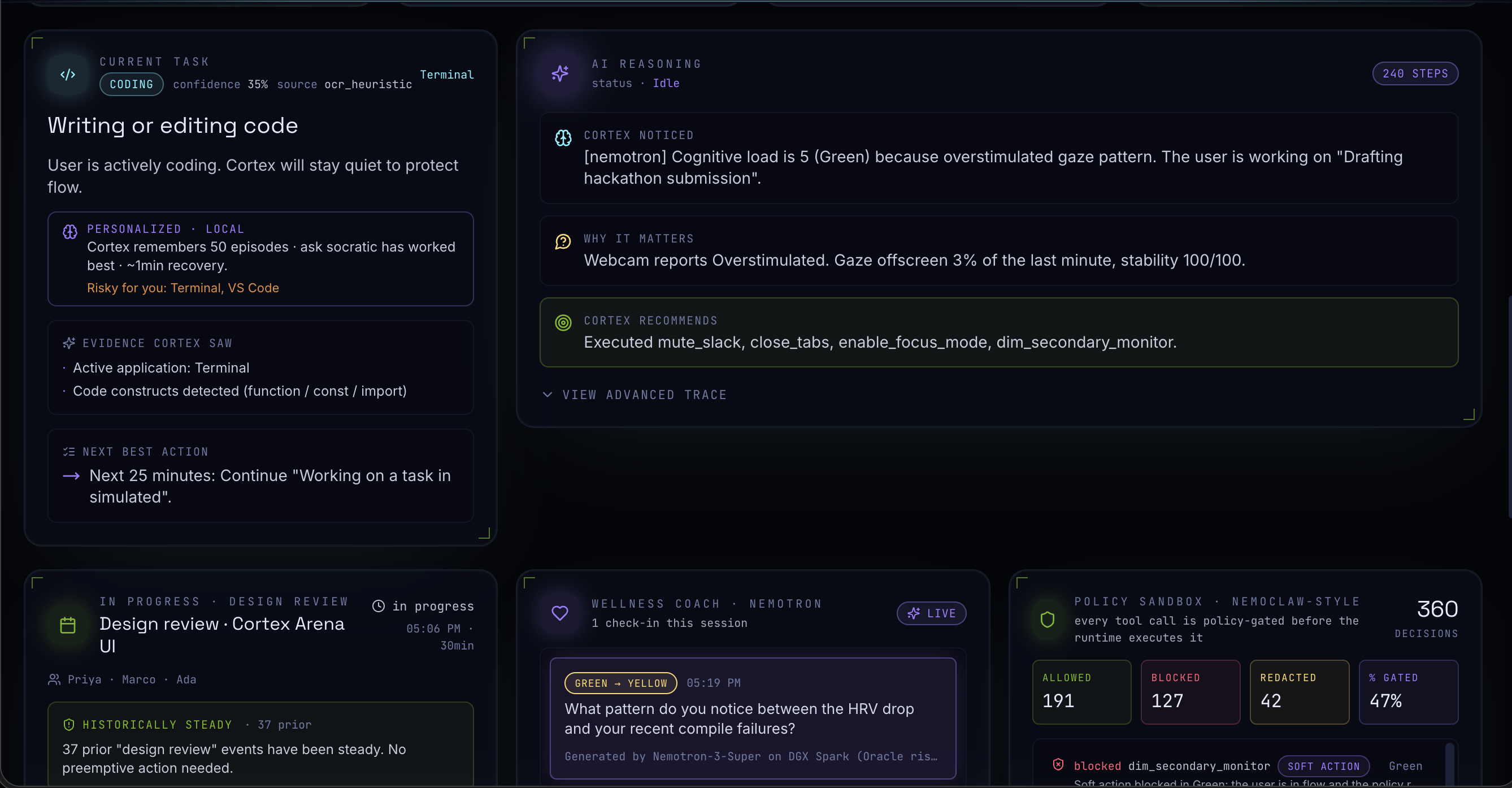
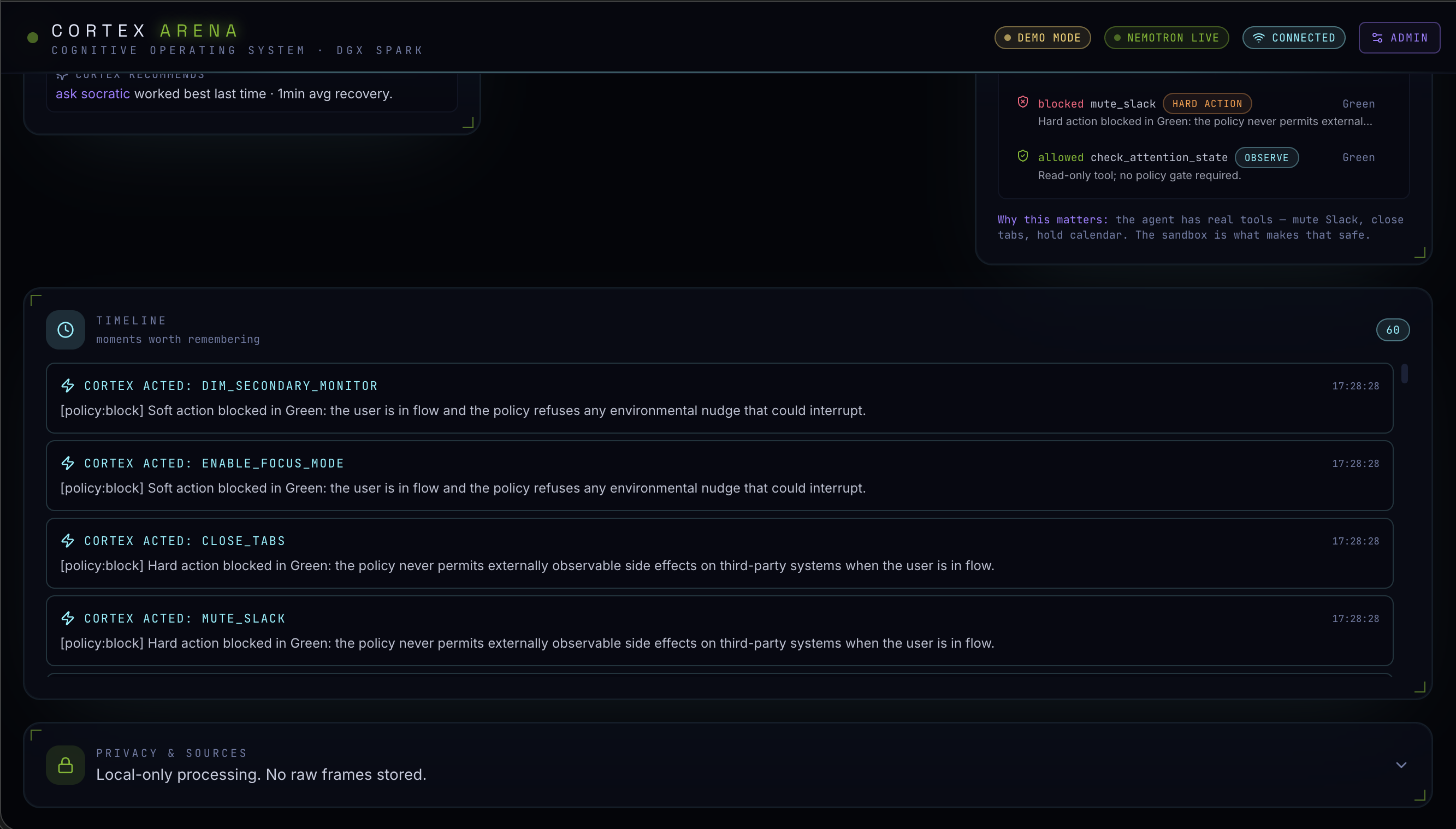
All of that feeds into a 7-agent reasoning constellation running on a locally-hosted Nemotron model on an NVIDIA DGX Spark. The system detects cognitive overload before the user consciously feels it, then intervenes calmly — muting Slack, closing tabs, blocking calendar time, dimming secondary monitors, or surfacing a single Socratic re-anchor question. Everything runs on-device. Nothing sensitive leaves your machine.
How we built it
The stack is split cleanly into client and server: Frontend - React + TypeScript + Vite + Tailwind + Framer Motion + lucide-react, organized into 13 cinematic HUD panels including an orbital agent constellation visualization, a conic-gradient cognitive load dial, a live reasoning stream, and a gaze heatmap with face analyzer.
Backend - Express + Socket.io, hosting the orchestrator that runs 7 specialist agents in parallel (Promise.allSettled) every tick: Workflow, Context Memory, Productivity, Interruption, Prioritization, Cognitive Load, and Screen Understanding. Their reports flow into Nemotron via an OpenAI-compatible adapter, which then selects from 11 simulated intervention tools.
Model - Nemotron (default nemotron3:33b) hosted locally on a DGX Spark over Tailscale, accessed through an OpenAI-compatible endpoint. The system auto-detects Spark availability and seamlessly falls back to a deterministic mock so the demo never breaks.
Privacy by design - webcam frames live in memory for one tick (~33ms) then are overwritten; screen frames are OCR'd on a local canvas that's immediately cleared; emails and phone numbers are stripped before any token is considered for uplink.
Challenges we ran into
Latency vs. coherence tradeoff: Running 7 agents in parallel and then synthesizing their reports into a single Nemotron decision call while keeping the UI responsive required careful socket event architecture and debouncing.
Privacy-safe screen understanding: Getting useful context from the screen without ever storing or transmitting raw frames meant building a multi-stage pipeline - capture - resize to 960px canvas - OCR - filter/dedup tokens - clear canvas - all within a 3-second cycle.
Graceful degradation: The DGX Spark isn't always reachable, so we built a deterministic mock fallback that mimics the model's behavior well enough that the demo never dies mid-presentation.
Accomplishments that we're proud of
A fully local, privacy-first AI cognitive system - no data leaves your machine that isn't a structured summary.
A genuine multi-modal sensing pipeline: biometrics + computer vision + OCR, all fused in real-time. The 7-agent parallel architecture produces richer, more nuanced interventions than any single-prompt approach could.
A cinematic, information-dense HUD that actually communicates what's happening inside the reasoning loop in real time - the Live Reasoning Stream showing every THOUGHT / TOOL CALL / TOOL RESULT / DECISION is something we're especially proud of.
A persistent episodic memory system: Cortex gets faster at recognizing your personal overload patterns over time.
What we learned
Building multi-agent systems that run truly in parallel (not sequentially masked as parallel) requires careful state management - Promise.allSettled was key, but designing the agents to be truly independent with no shared mutable state took discipline.
Privacy-preserving computer vision is harder than it sounds. Getting useful signal from the screen without any frame persistence required rethinking the pipeline from the ground up.
Prompt engineering for behavioral posture (the per-state intervention rules) works best when you enforce it in both the model prompt and the fallback mock - otherwise you create inconsistencies that surface in demo conditions.
The UX of an AI system matters as much as its reasoning: making the agent's internal monologue visible to the user (via the reasoning stream) built trust and made the intervention feel earned rather than arbitrary.
What's next for Cortex
Longitudinal memory analytics - surfacing weekly patterns ("you reliably hit Red on Thursday afternoons after back-to-back meetings") and proactive scheduling suggestions.
Multi-user / team mode - detecting when a whole team is collectively overloaded and surfacing that to a manager or suggesting an async-first day.
Edge deployment - packaging for always-on background operation without a visible HUD, intervening only when needed.
Built With
- blink-rate
- express.js
- framer-motion
- json
- lucide-react
- mediapipe-facemesh
- node.js
- nvidia-dgx-spark
- nvidia-nemotron
- ollama
- openrouter)-hardware-/-infrastructure-nvidia-dgx-spark-(on-device-inference)-tailscale-(private-network-tunnel-to-dgx-spark)-computer-vision-mediapipe-facemesh-(gaze
- python
- react
- socket.io
- tailscale
- tailwind-css
- tesseract.js
- typescript
- vite
- vllm
- webrtc

Log in or sign up for Devpost to join the conversation.