Inspiration
Every engineer who's been on-call knows the feeling. It's 2am, an alert fires, and you're staring at five different tabs containing observability dashboards, logs, deployment history, and tickets trying to manually correlate what broke and why. The tooling tells you that something is wrong. It rarely tells you why.
I wanted to build the thing we wished existed: an agent that handles the first 15 minutes of incident investigation automatically, consistently, and with the context needed to make better decisions.
What it does
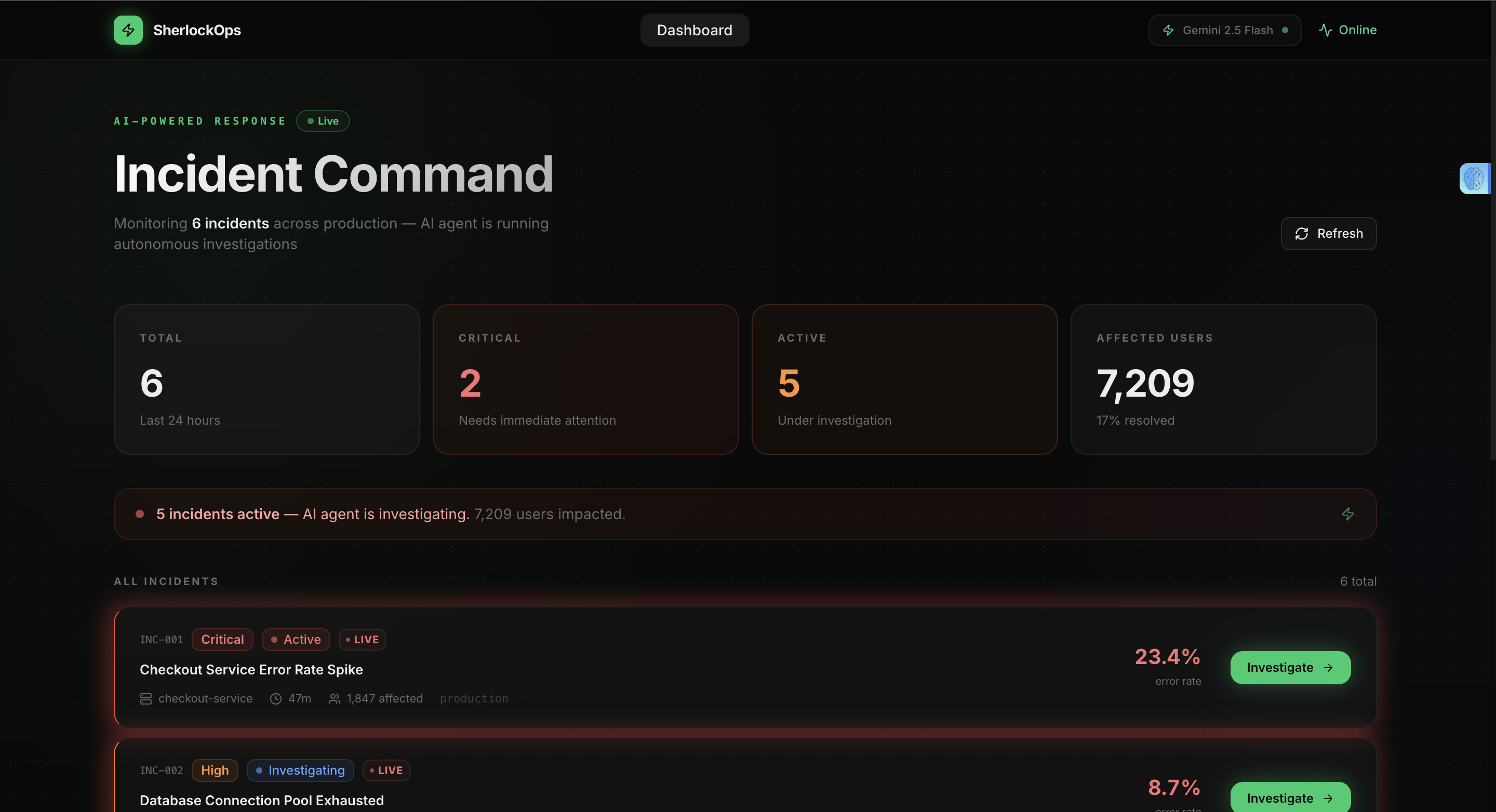
SherlockOps is an autonomous SRE incident investigation agent.
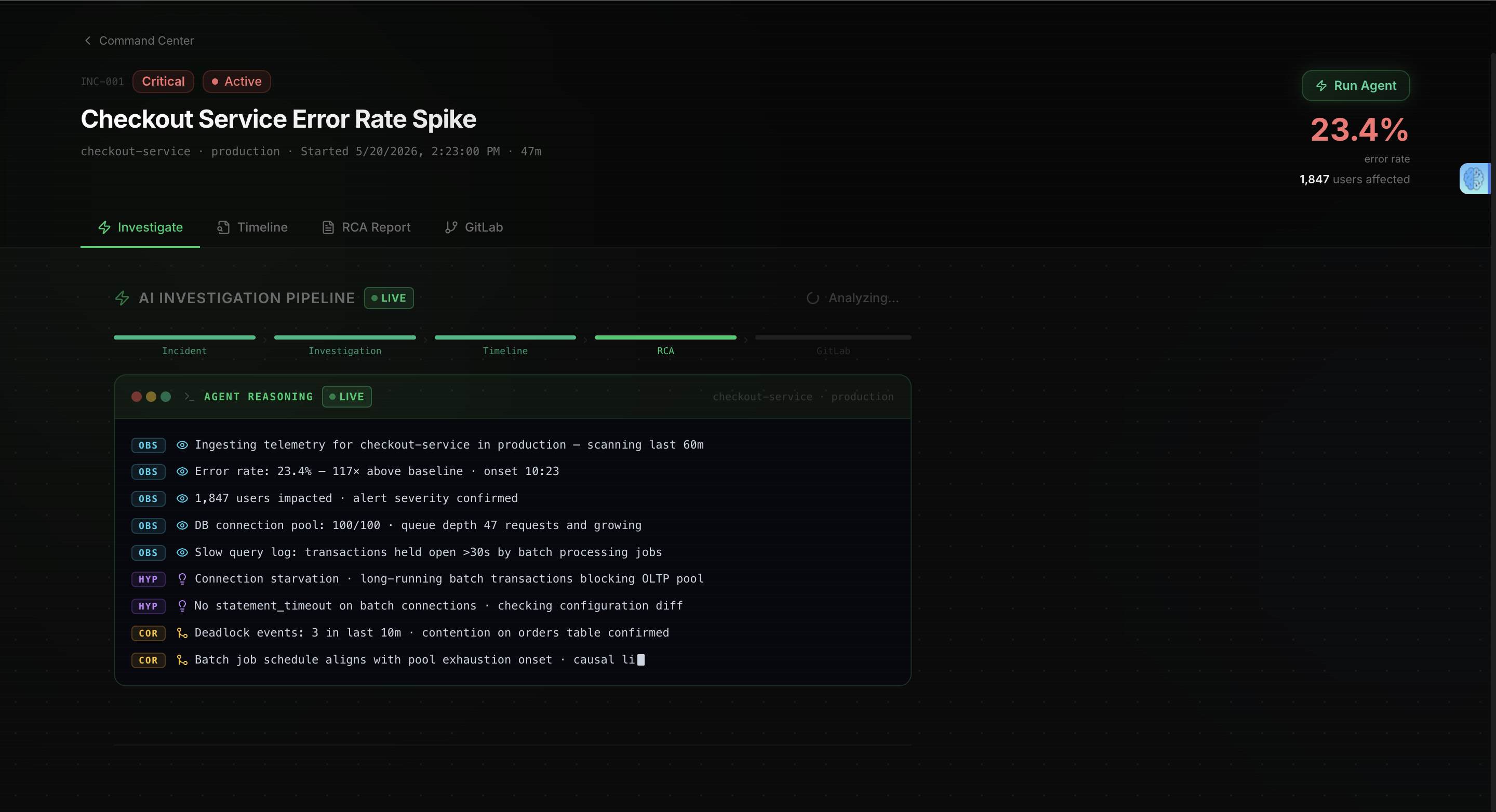
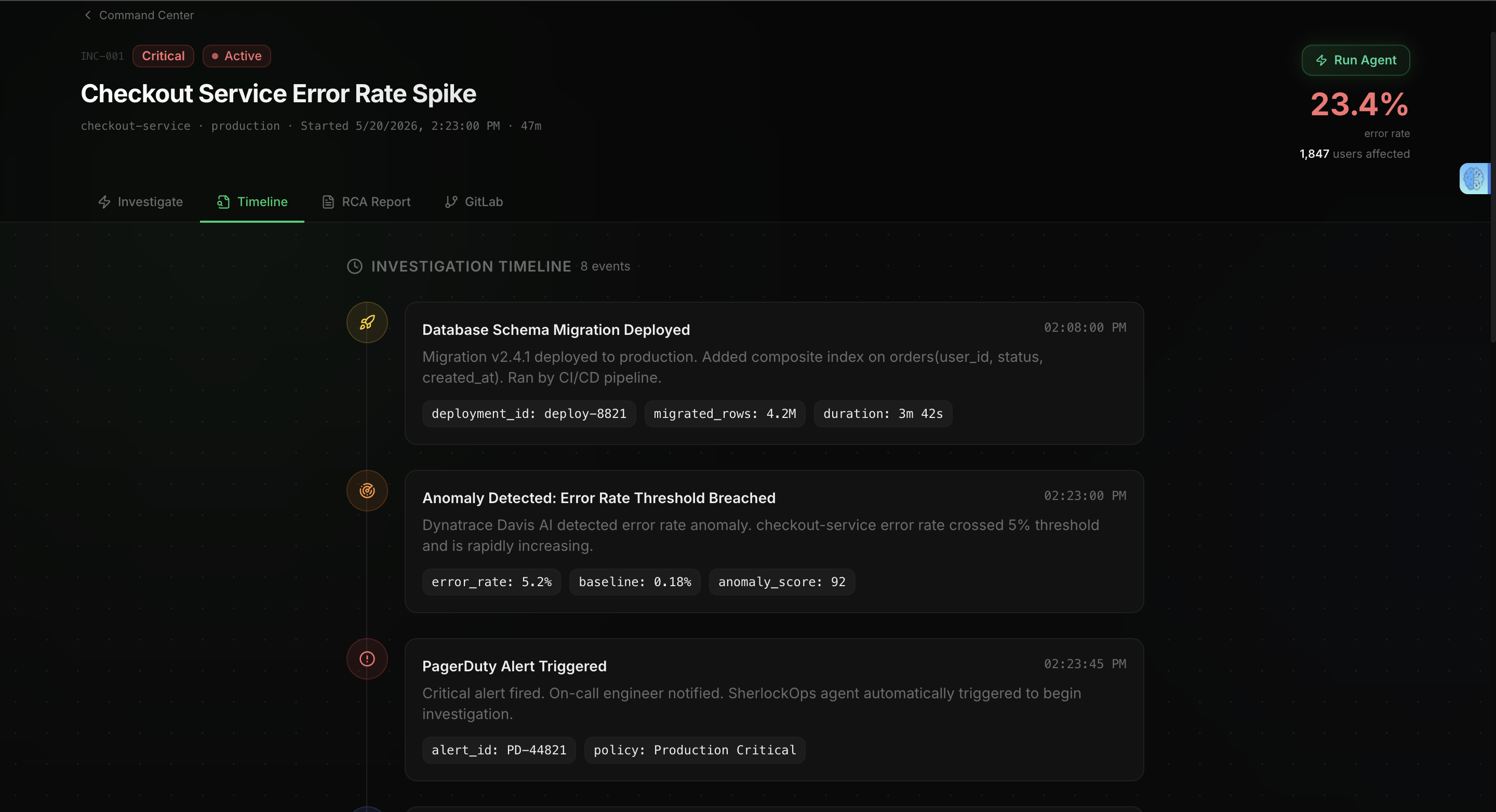
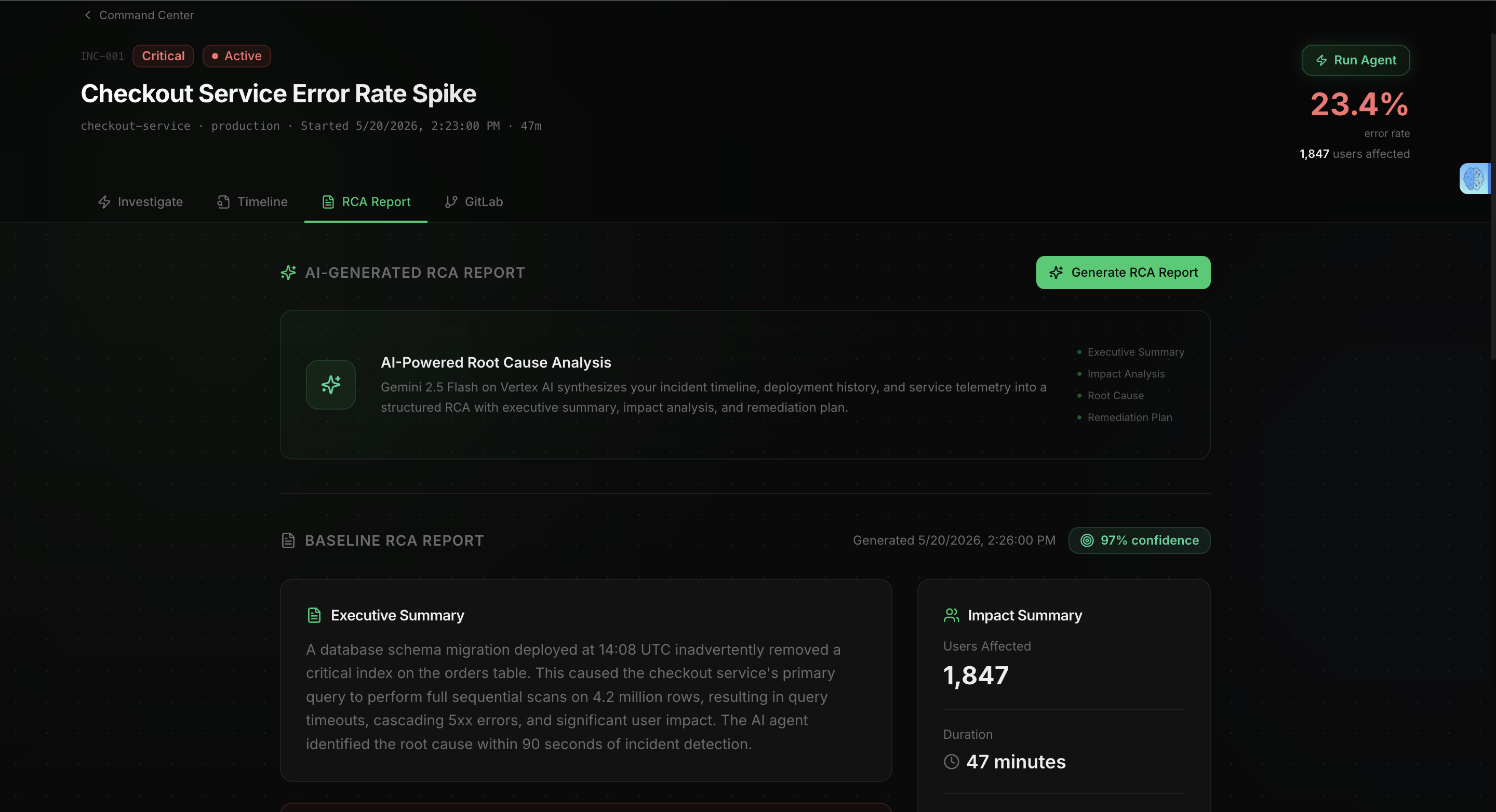
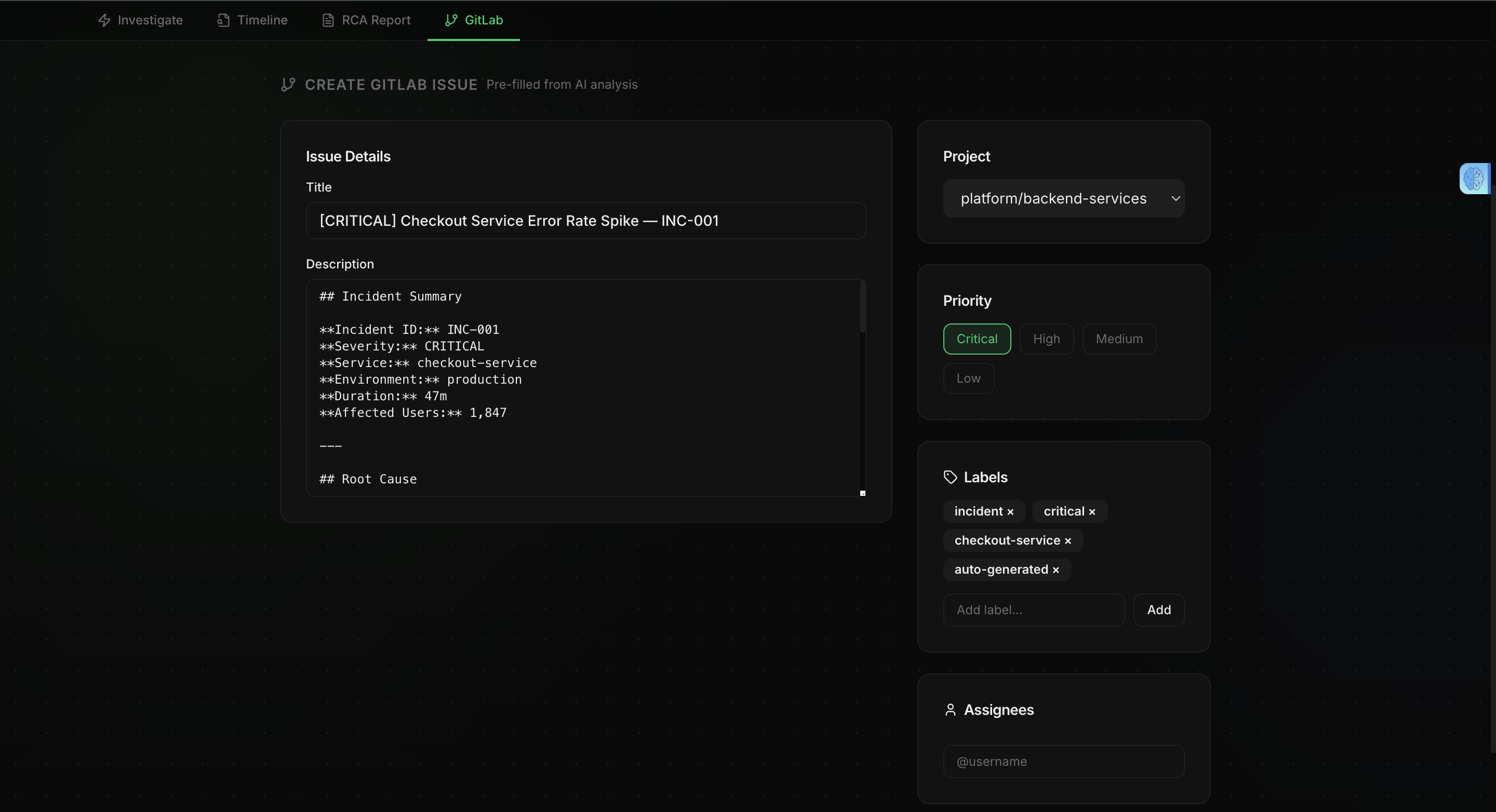
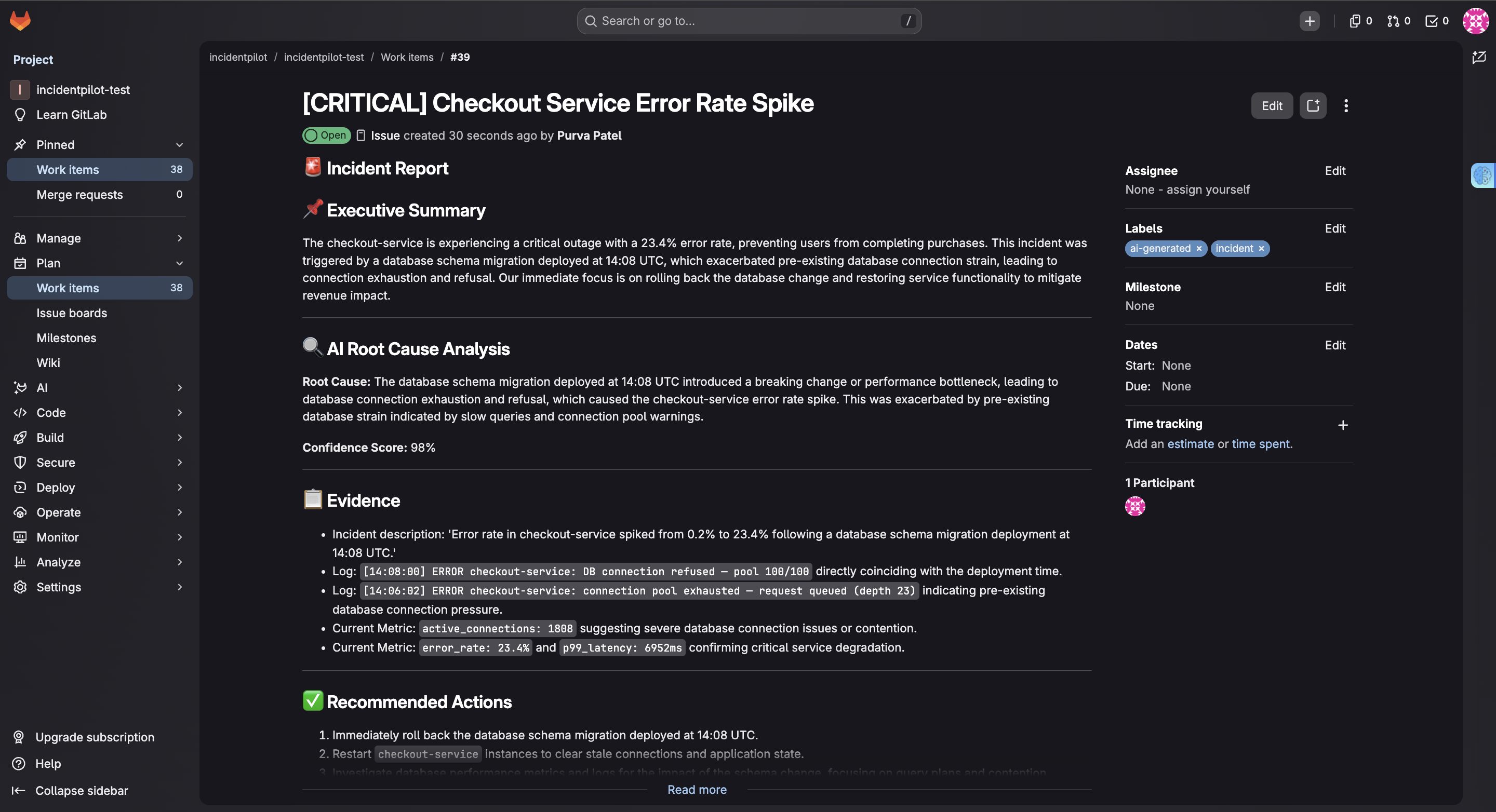
When an incident comes in, it automatically begins the investigation workflow. It gathers observability context from Dynatrace, uses Gemini 2.5 Flash on Vertex AI to analyze the evidence, and produces a structured root cause analysis with confidence scoring, supporting evidence, and prioritized remediation steps. It then creates a GitLab issue for the engineering team automatically.
The entire investigation pipeline runs in under 90 seconds.
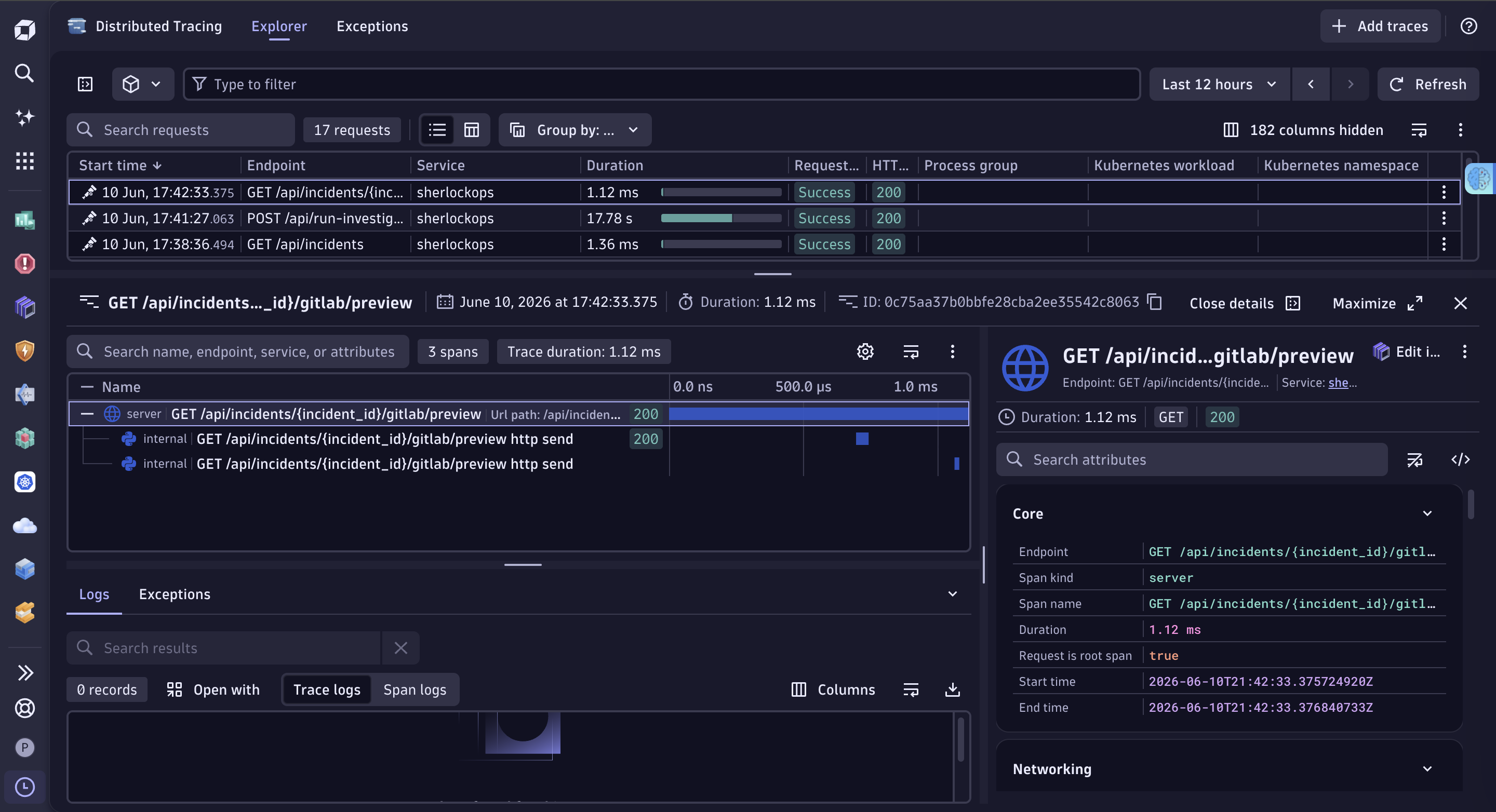
Built with: Google Agent Development Kit (ADK) for agent orchestration Gemini 2.5 Flash on Vertex AI for reasoning and analysis Model Context Protocol (MCP) to provide the agent with real-world tools Dynatrace for observability, telemetry, and agent tracing OpenTelemetry for end-to-end workflow visibility GitLab integration for automated remediation tracking FastAPI + Next.js for backend and frontend Cloud Run for deployment
How I built it
I started with a simple question: what does a strong on-call engineer actually do in the first few minutes of an incident?
They check metrics, examine recent changes, inspect logs for error patterns, form hypotheses, and gather enough evidence to identify the most likely cause. That workflow became SherlockOps' agent toolset.
I used Google's Agent Development Kit (ADK) to build an agent with five tools:
list_incidents investigate_incident fetch_dynatrace_problems fetch_dynatrace_services create_gitlab_issue
The agent decides which tools to use and in what order. I designed the tools and investigation workflow while ADK handled the orchestration layer.
The agent is powered by Gemini 2.5 Flash through Vertex AI, allowing it to reason over incident context and observability data.
I also exposed these capabilities through Model Context Protocol (MCP), creating a standardized tool interface that allows MCP-compatible clients to interact with SherlockOps.
For observability, I instrumented API calls, agent actions, and LLM interactions with OpenTelemetry and sent traces directly into Dynatrace. This makes the entire investigation workflow visible including tool calls, latency, and execution flow.
Challenges I ran into
Vertex AI migration
I started with a direct Gemini API integration, then migrated the agent workflow to Vertex AI to align with the hackathon requirements. Setting up authentication, IAM permissions, and Application Default Credentials across local development and Cloud Run required careful configuration.
Tool reliability
AI agents are only as reliable as the tools they use. Early versions of the agent could become confused when observability tools returned empty data or unexpected responses. I improved reliability by making every tool return structured JSON responses with explicit status fields, allowing the agent to handle missing data gracefully instead of making assumptions.
Local vs Cloud deployment
The MCP server required newer Python support for the full streamable HTTP transport. Local development and Cloud Run environments had different runtime constraints. To solve this, I implemented a REST fallback while keeping the full MCP protocol available in production environments.
Accomplishments that I'm proud of
The biggest accomplishment was getting the complete incident response pipeline working end-to-end:
Incident detected → investigation launched → observability gathered → root cause identified → GitLab issue created.
The entire workflow completes with no manual investigation steps.
I'm also proud that the MCP implementation is a real integration layer rather than a demo. SherlockOps exposes usable tools that can be called by MCP-compatible clients.
And shipping the entire project solo from agent design to deployment was a major milestone.
What I learned
The biggest insight: observability data is fuel for AI reasoning.
When Gemini only received incident descriptions, the analysis was generic. When it received real context like metrics, error patterns, service information, and timelines, the quality of the investigation improved dramatically.
The quality of an AI agent's output depends heavily on the quality of the context and tools available to it.
The second insight: MCP is a powerful abstraction for action-taking agents. The difference between a chatbot and an agent is the ability to interact with real systems. MCP provides a standardized way to connect those systems to AI workflows.
The third insight: deploying early forces better engineering decisions. Running on Cloud Run exposed real challenges around authentication, environment configuration, and reliability that would not appear in a purely local demo.
What's next for SherlockOps
Future improvements: Webhook-triggered investigations where Dynatrace alerts automatically start analysis
Slack/Teams integration to deliver RCAs directly into incident channels
Historical incident pattern matching to identify recurring failures
GitLab CI/CD remediation workflows with human approval gates
The bottleneck in incident response isn't human intelligence. It's having the right context available at the right time.
SherlockOps helps bridge that gap.
Built With
- css
- docker
- dynatrace-entities-api
- dynatrace-metrics-api
- dynatrace-opentelemetry-ingest
- dynatrace-problems-api
- fastapi
- gemini
- google-cloud
- next.js
- python
- tailwind
- typescript
- vertex-ai

Log in or sign up for Devpost to join the conversation.