-
-
Report generation agent pipeline
-
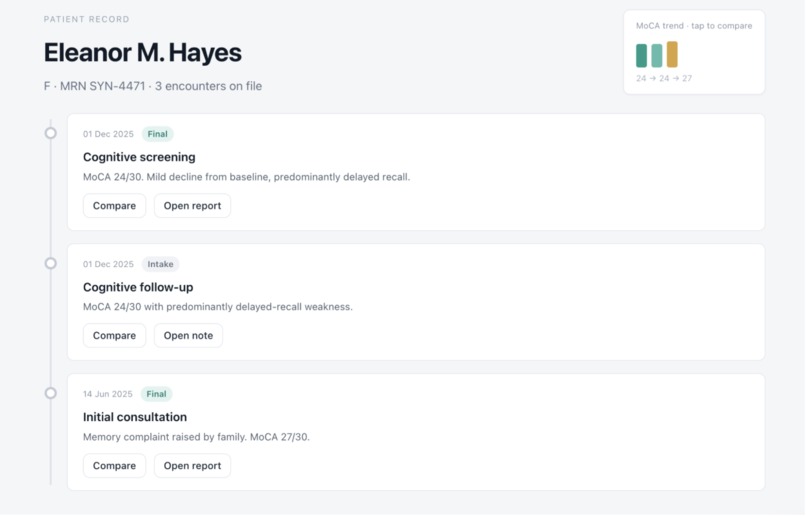
Patient history RAG
-
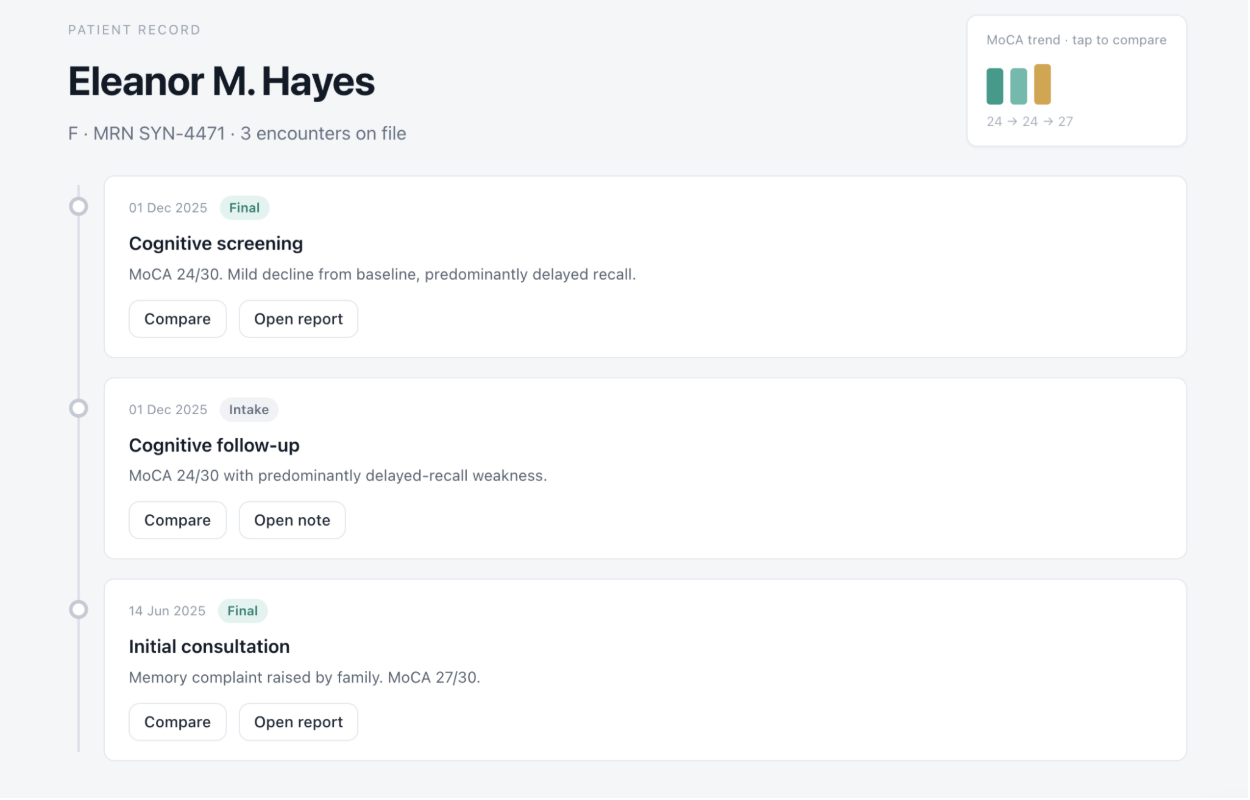
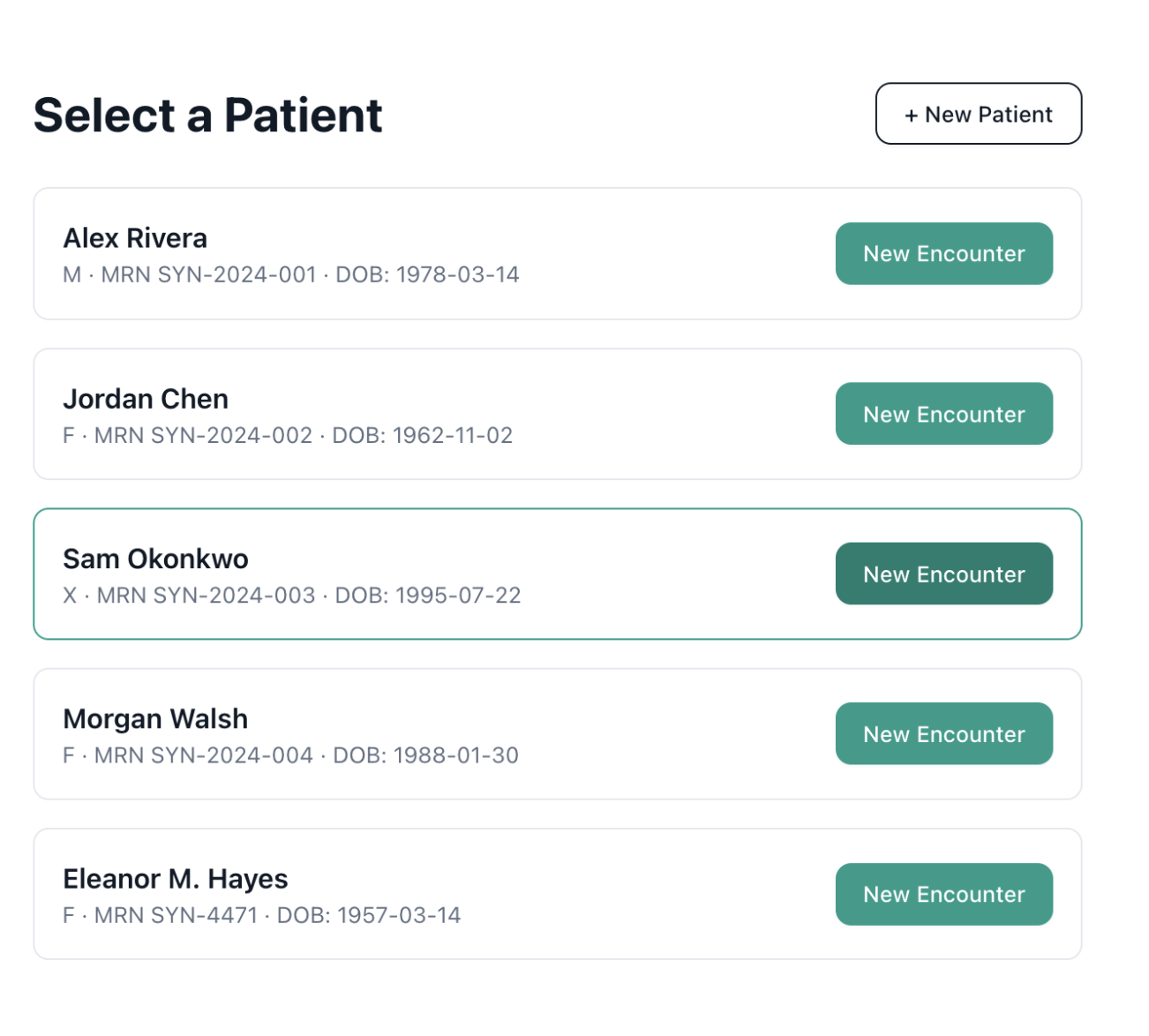
Patient selection
-

Annotatable neuropsych report

Inspiration
Neuropsychological evaluation is one of the most cognitively demanding (and most paperwork-heavy) corners of clinical practice. A single visit (clinical interview, a battery of standardized tests, behavioral observation) routinely turns into hours of report writing before a patient ever gets an answer. While working with the team at Momentous Health, we watched neuropsychologists do this firsthand: brilliant clinicians spending more time formatting normative test scores into prose than they spent with the patient.
That bottleneck is about to get worse, not better. The population is aging, referrals for cognitive evaluation (dementia workups, ADHD assessments, post-concussion screening) are climbing, and the supply of neuropsychologists isn't scaling with demand. Documentation overhead isn't a side cost in this field; it's the rate limiter on how many patients a clinician can actually see. We built Cortex to attack that rate limiter directly, without asking clinicians to trust a black box with their patients' clinical judgment.
What it does
Cortex turns a patient visit (a voice transcript plus structured neuropsych test scores) into a clinically structured, normatively-grounded report draft, with a human-reviewable trail at every step.
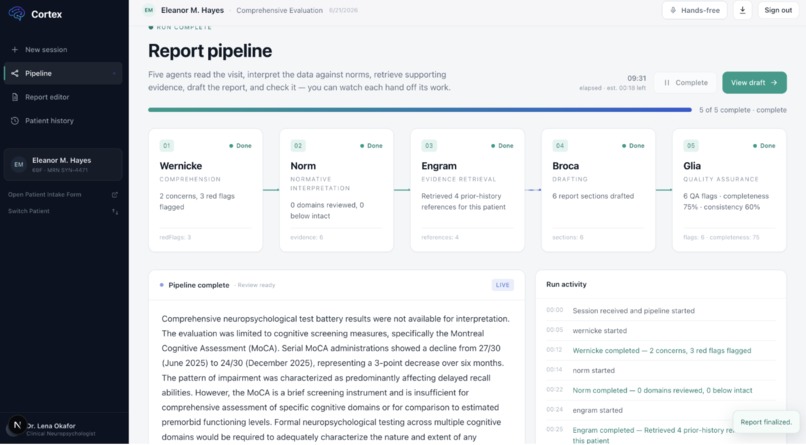
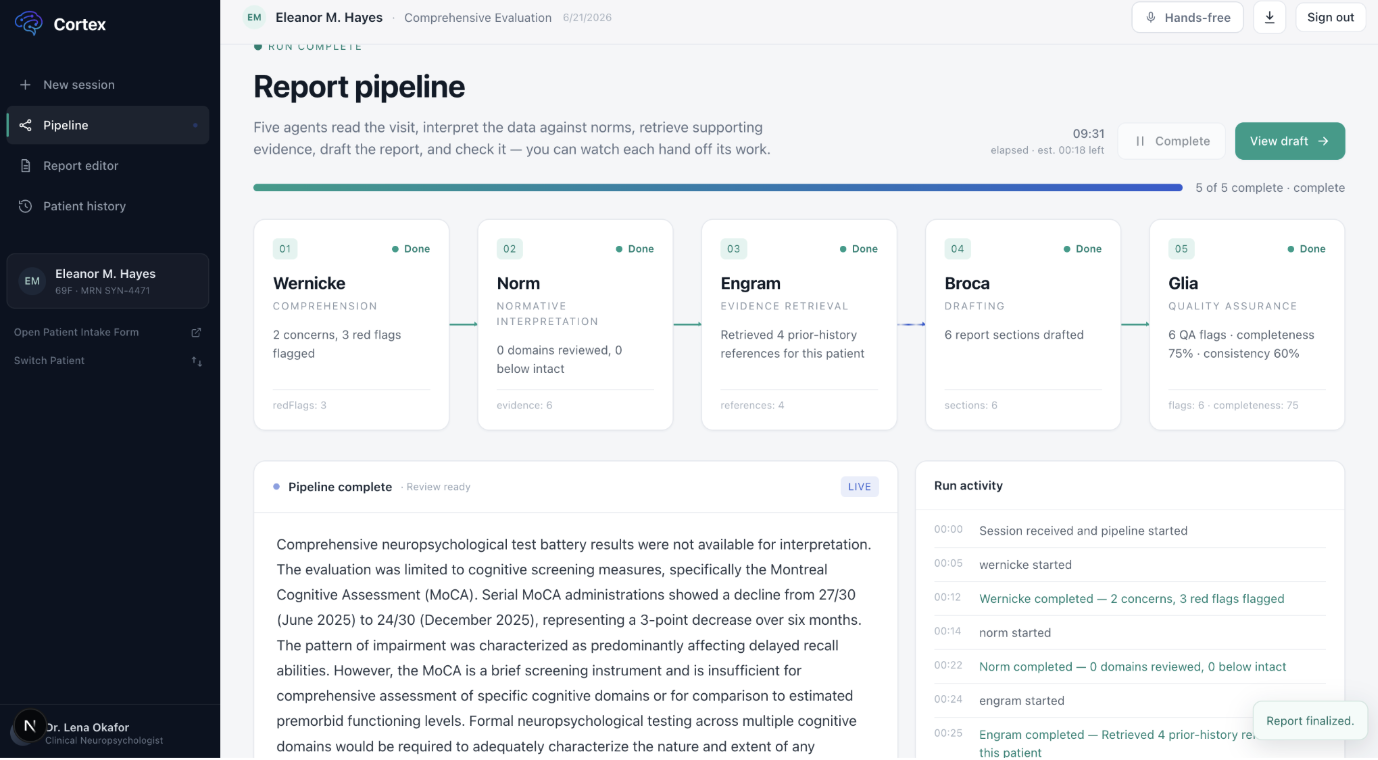
A clinician (or the synthetic demo workspace, no credentials required) feeds in a visit: audio gets transcribed via Deepgram's medical speech model, test battery scores attach as structured data, and a five-stage agent pipeline takes over:
- Wernicke ingests the transcript and patient record into structured clinical context, presenting concerns, history, behavioral observations, functional impact, and explicit uncertainty flags.
- Norm interprets test scores against normative data retrieved from a RAG corpus in Redis, producing domain-by-domain clinical interpretation instead of bare percentiles.
- Engram supplies grounded evidence so every claim downstream can be traced back to a source.
- Broca drafts the actual report sections in clinical prose.
- Glia acts as QA, reviewing the draft against the evidence trail and raising flags for anything under-supported or inconsistent.
Anything Glia flags doesn't just get silently corrected by another model call. It routes into a human-in-the-loop annotation packet, bundling the transcript, test data, every agent's intermediate output, and the specific flags, for a qualified human reviewer to adjudicate before the report reaches the clinician for sign-off. That review loop, not just the generation pipeline, is the actual product.
How we built it
- Next.js 15 (App Router) + TypeScript, deployed to Vercel/Railway.
- Five-agent Claude pipeline (Anthropic Sonnet), with each agent scoped to a single, narrow responsibility and a strict JSON output contract; no agent is allowed to do another's job.
- Deepgram Nova medical model for visit transcription.
- Redis as the patient-memory and normative-RAG layer, kept strictly separate from Firestore, which holds only live report drafts and session statem never patient history. This data-lane separation is enforced architecturally, not just by convention.
- Human-in-the-loop annotation system: a packet builder assembles everything a reviewer needs (demographics, transcript, test battery, every agent's raw output, QA flags) into a single reviewable unit, served through a tokenized review link, so a domain expert can adjudicate the agent pipeline's output without needing pipeline internals.
- Firebase Auth for clinician login, Arize (OTLP) + Sentry for tracing and hallucination monitoring on the agent pipeline itself.
- A demo/configured mode switch on every external service; the entire pipeline runs end-to-end on synthetic patients with zero credentials configured, falling over to real infra incrementally as keys are added. This made it possible to build and demo clinically-sensitive software without ever needing real PHI in development.
Challenges we ran into
- Keeping five agents honest about their lane. It's tempting to let one big prompt do clinical reasoning, normative interpretation, and drafting all at once. Splitting it into Wernicke → Norm → Engram → Broca → Glia made each agent's failure mode legible; when something goes wrong, we know which stage owns it, instead of debugging one giant prompt.
- Designing for trust, not just accuracy. A neuropsych report can't ship on "the model was probably right." Glia's QA flags and the human annotation hand-off exist because precision and reliability in this domain matter more than speed; the architecture had to make disagreement and uncertainty visible rather than averaging them away.
- Making the review loop actually usable, not decorative. Human-in-the-loop is easy to bolt on as a checkbox and hard to make genuinely reviewable. The annotation packet had to carry enough context (full agent trail + specific flags, not just a final draft) for a reviewer to adjudicate quickly without re-deriving the clinical reasoning from scratch.
Accomplishments that we're proud of
- A multi-agent pipeline where every stage is independently inspectable, evaluatable, and traceable to a source; Engram's evidence grounding means a clinician can ask "why did it say this" and get a real answer, not a hallucinated citation.
- A real human-in-the-loop review mechanism, not a fig leaf: flagged outputs get bundled with full context and routed to a reviewer before sign-off.
- An architecture that runs convincingly end-to-end in demo mode, with no real credentials and no real PHI, while still exercising the exact same code paths as the production-configured system.
- Observability built in from day one (Arize + Sentry) rather than bolted on after something broke.
What we learned
- In clinical domains, the hard problem isn't "can an LLM draft a plausible report"; it's "can the system make its own uncertainty visible and route it to a human before it matters." Precision and reliability come from architecture (narrow agents, explicit flags, human adjudication), not from a bigger prompt.
- Strict separation of concerns at the infrastructure level (Redis vs. Firestore, demo vs. configured) pays for itself immediately the moment you're handling anything sensitive; it turns "don't accidentally leak PHI" from a discipline problem into a structural guarantee.
- Multi-agent pipelines are only as trustworthy as their weakest handoff. Most of our debugging time went into the boundaries between agents, not the agents themselves.
What's next for Cortex
- Closing the loop from human annotation back into the pipeline, using reviewer corrections to tune Norm's normative interpretation and Glia's flagging thresholds over time, rather than treating each review as a one-off.
- Expanding the normative RAG corpus and broadening test-battery coverage beyond the current fixture set toward the instruments used most often in real intake.
- Tightening the Band remote-agent integration so the five-stage pipeline can run as independently addressable agents in a clinician's existing tools, not just inside the Cortex app shell.
- Formal validation against real (de-identified, IRB-appropriate) report pairs to quantify time saved and report quality versus a clinician working unassisted; the next real test of whether this actually moves the bottleneck.
Built With
- arize
- claude
- css
- deepgram
- docker
- embeddings
- firebase
- google-cloud
- microsoft-band
- node.js
- opentelemetry
- react
- redis
- sentry
- tokenrouter
- typescript


Log in or sign up for Devpost to join the conversation.