Inspiration
I've been studying how CX agents are built and noticed a pattern. Almost every implementation relies on complex workflow trees for routing, RAG pipelines for knowledge, separate integrations for voice, chat, and vision, and intent classifiers to hold it all together. It works. But it got me thinking.
When a new support rep starts a job, nobody hands them a flowchart of every possible customer scenario. They get a training manual. An SOP. It teaches them how to greet customers, how to diagnose problems, when to escalate, and where to find answers. Within days, they're solving real problems.
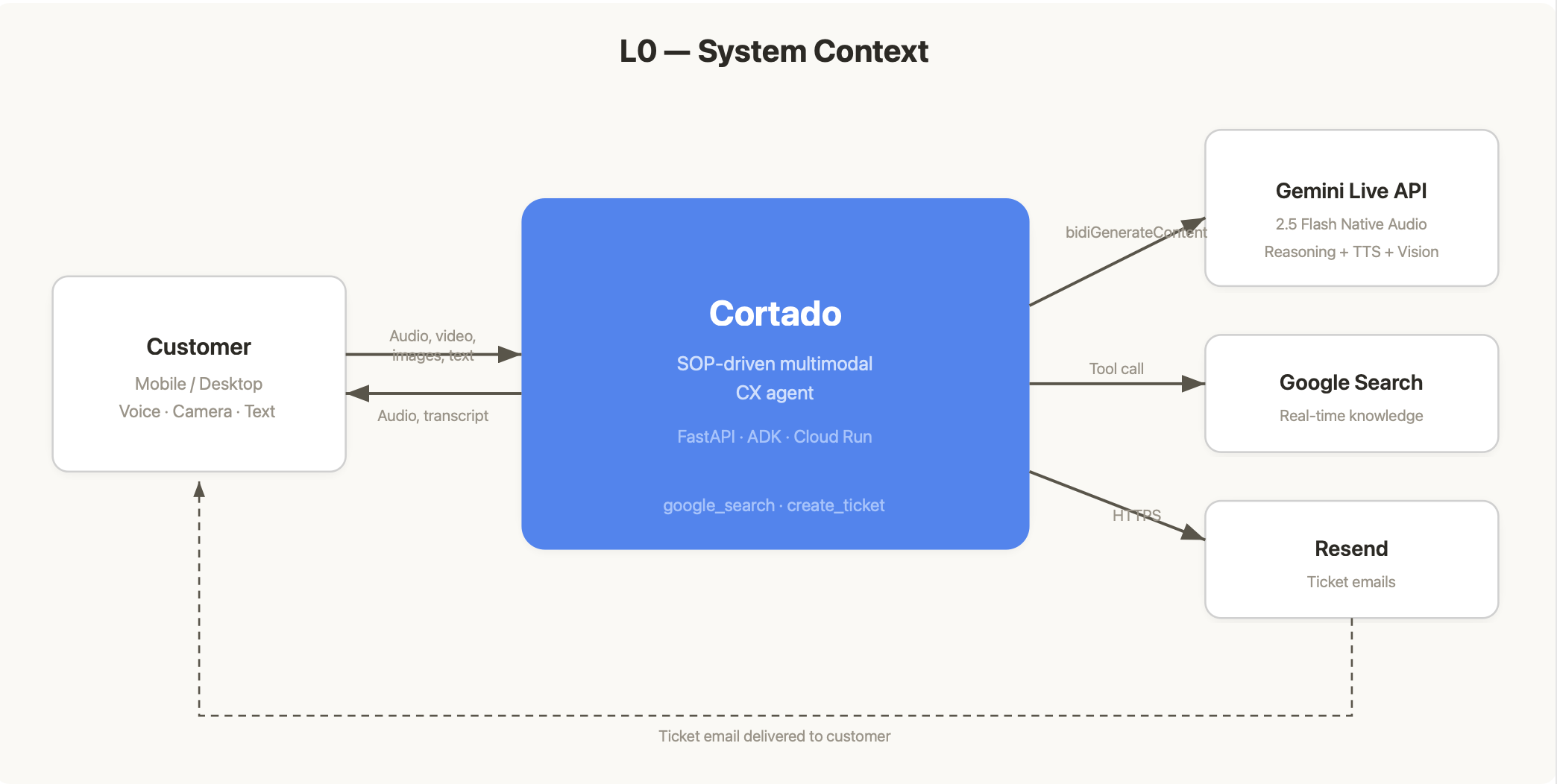
I wanted to test whether an AI agent could work the same way. Give it an SOP instead of a workflow tree. Give it Google Search instead of a vector database. And use the Gemini Live API so voice, camera, text, and images all flow through one model in real time. Cortado is the result of that experiment.
What it does
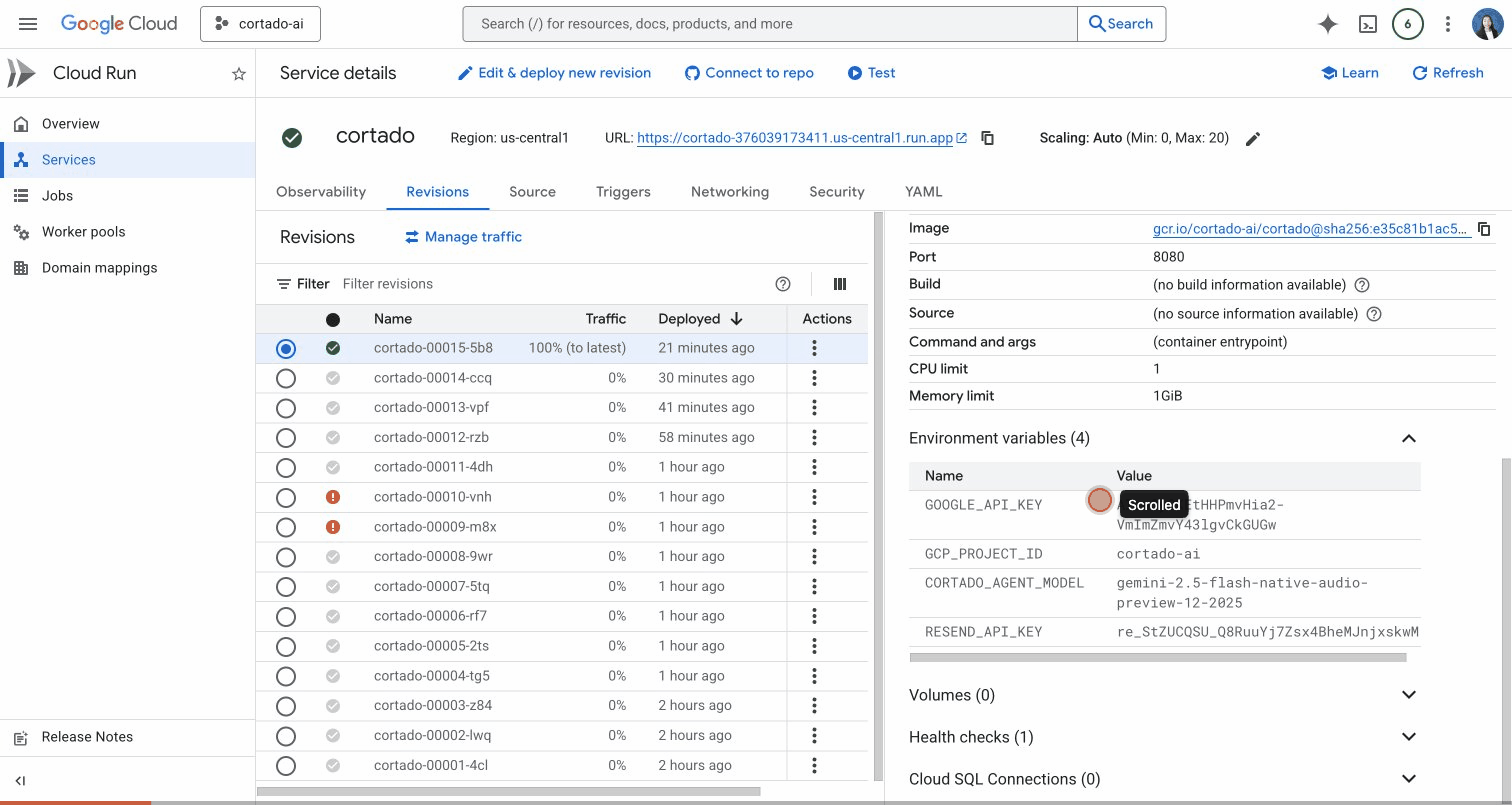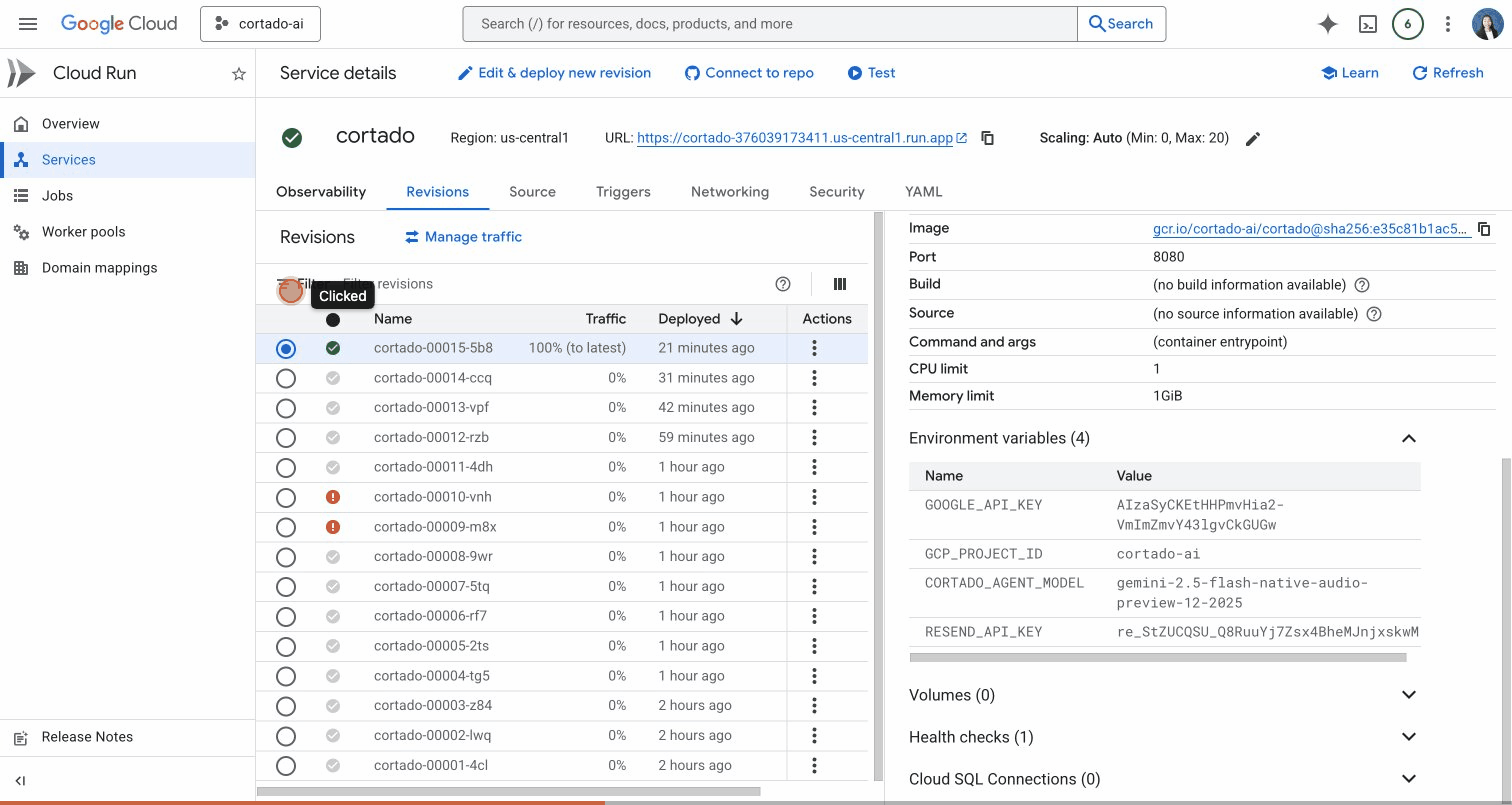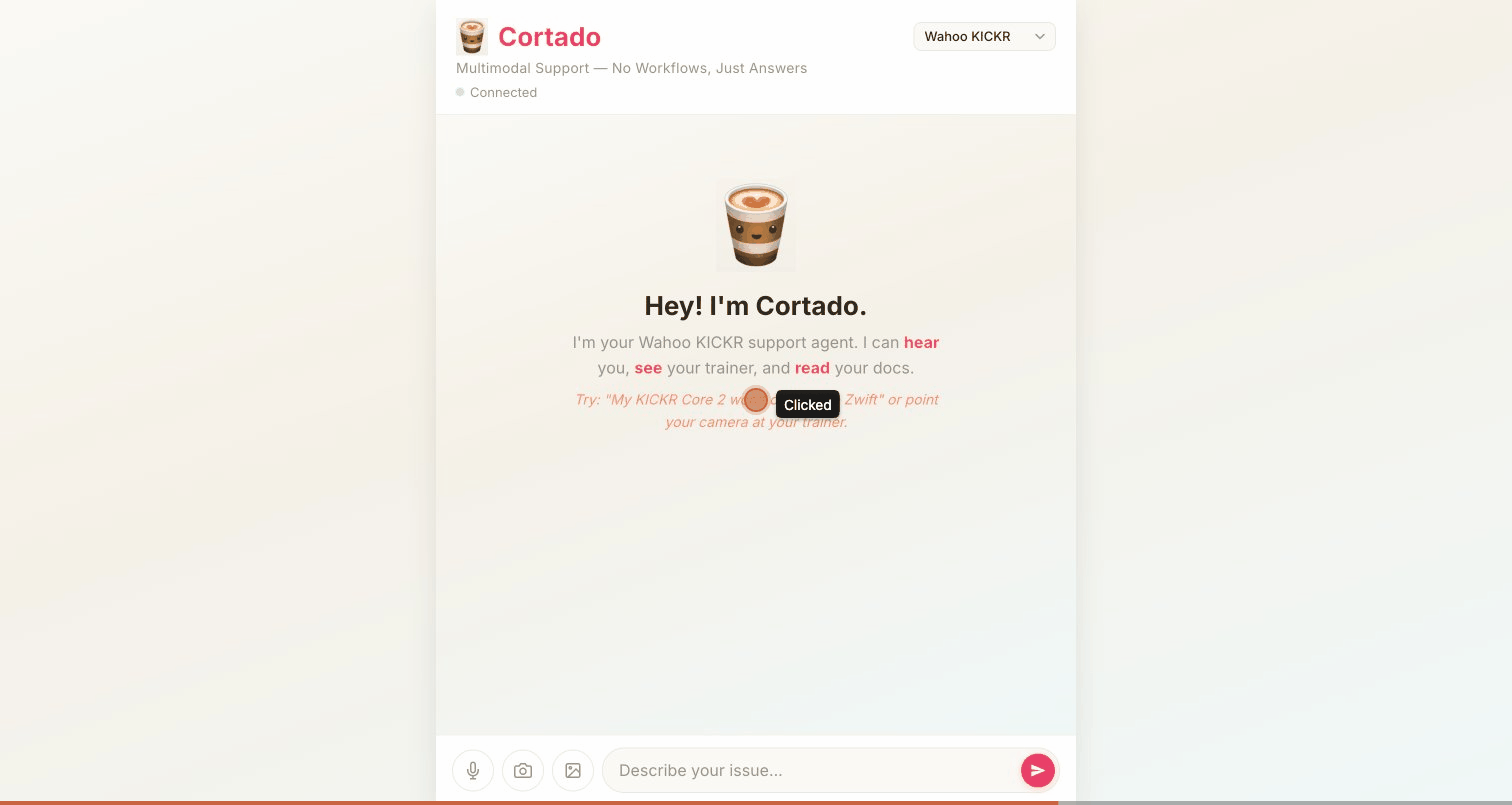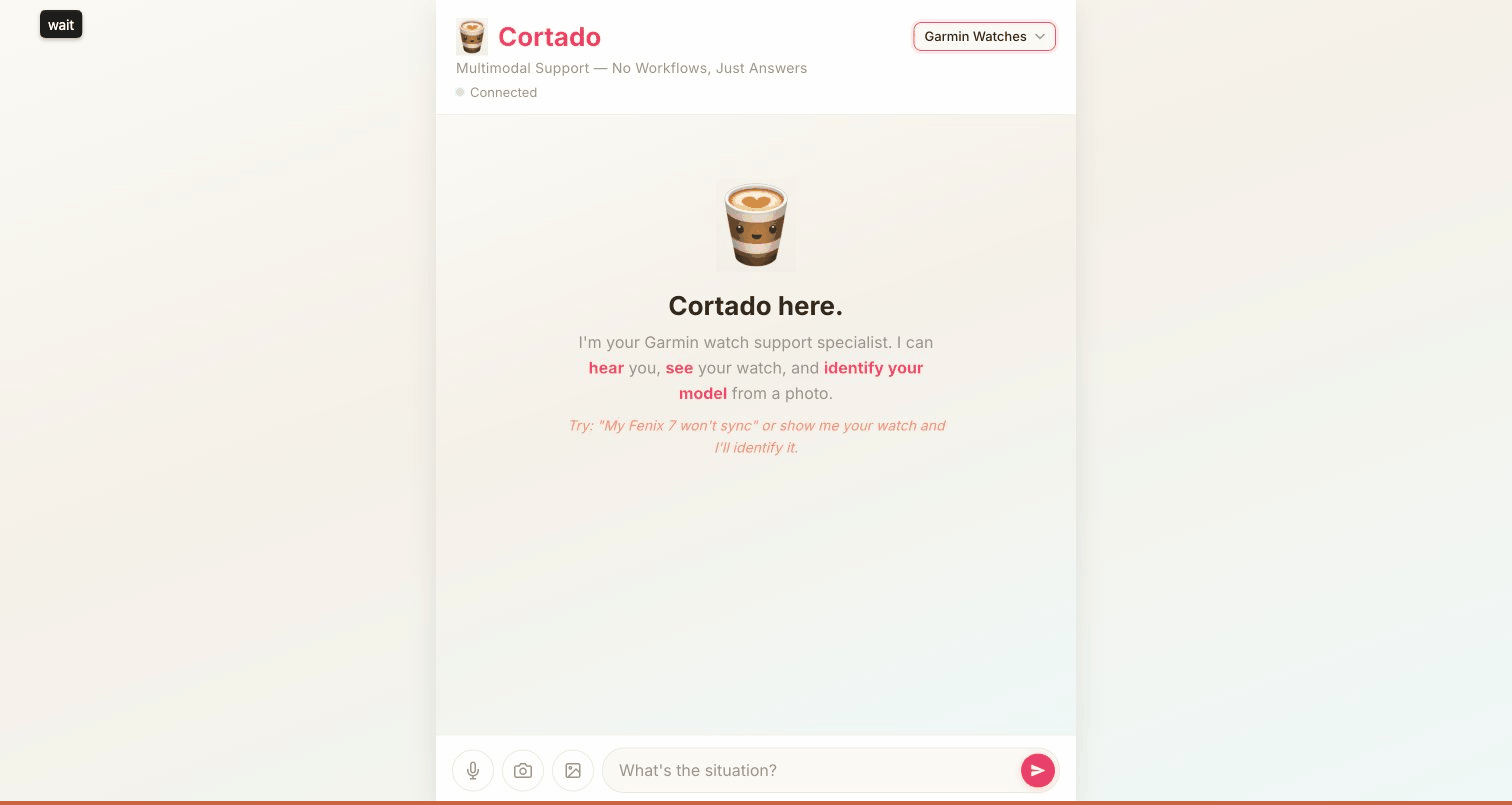
Cortado is a multimodal customer support agent built on the Gemini Live API. A customer can talk to it, point their phone camera at a product, type a question, or upload a screenshot, all in the same session. The agent hears, sees, reads, and responds with natural voice powered by Gemini 2.5 Flash Native Audio.
The entire knowledge layer is a single SOP document combined with Google Search. The SOP defines the agent's behavior, personality, tone, escalation rules, and search strategy. It contains zero product knowledge. When the agent needs an answer, it searches the web in real time. Official support sites, YouTube tutorials, community forums.
To prove this architecture is domain-agnostic, Cortado ships with two completely different support agents. A friendly cycling buddy for Wahoo KICKR trainers, and a tactical tech sergeant for Garmin watches. Switching between them is a dropdown. The SOP is the only thing that changes. Same code, same tools, same infrastructure.
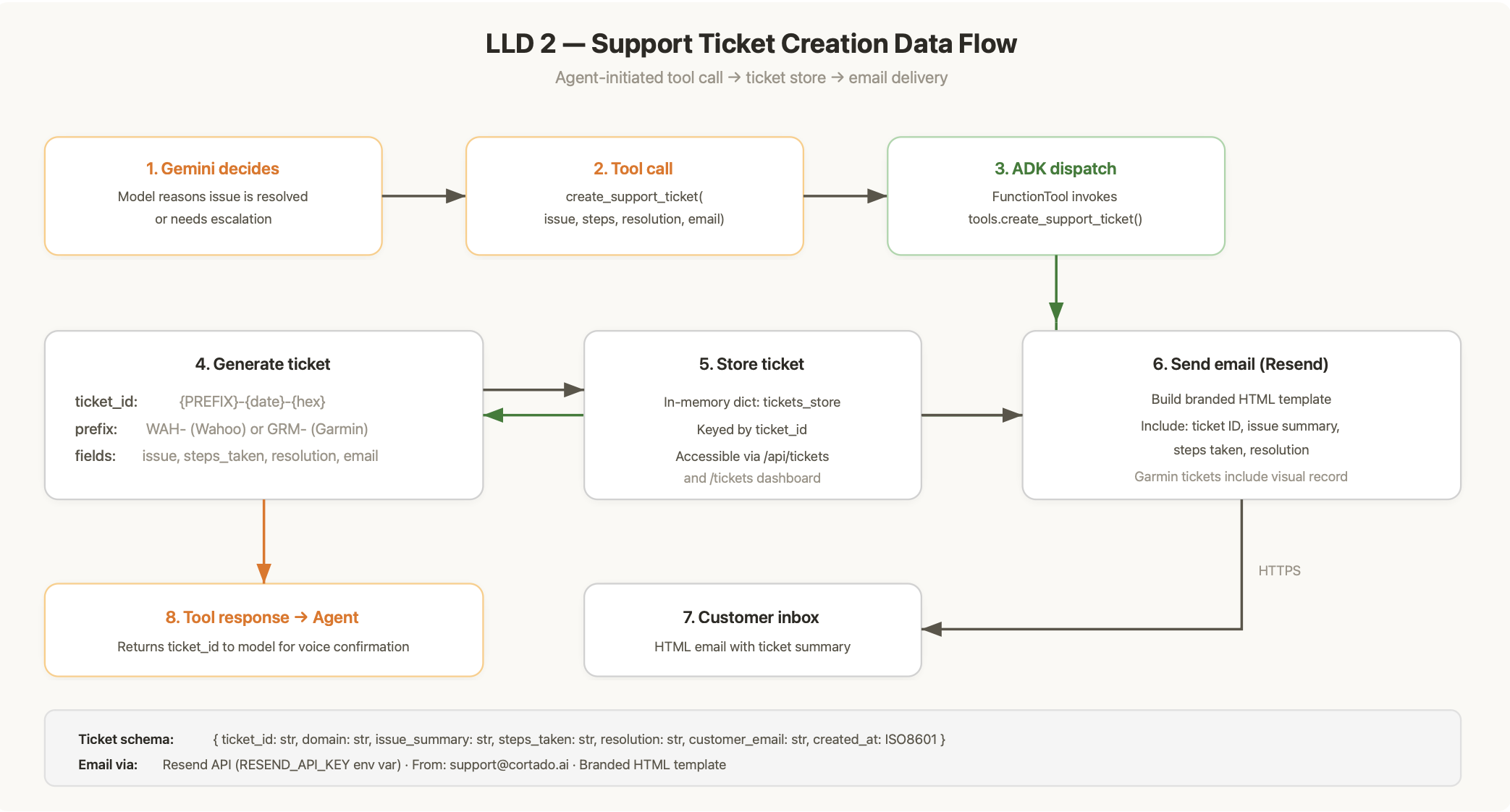
The agent also creates support tickets with branded HTML email confirmations via Resend, complete with unique ticket IDs (WAH- or GRM- prefixed) and a real-time dashboard.
Watch a Highlight Reel Here: https://youtu.be/katlvn3WvG4 Watch The Complete Demo Video Here: https://youtu.be/uGsuj6gQyU4
How I built it
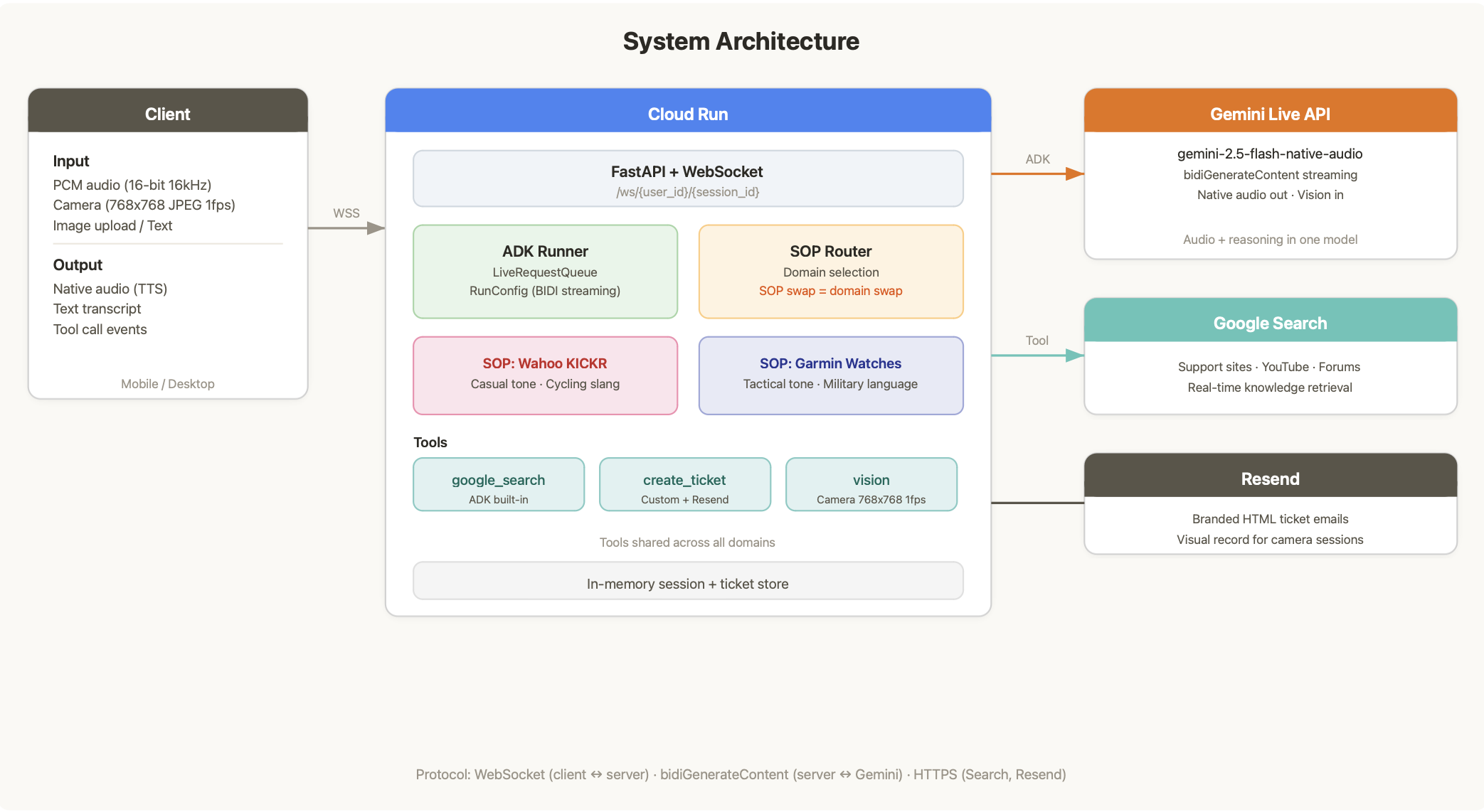
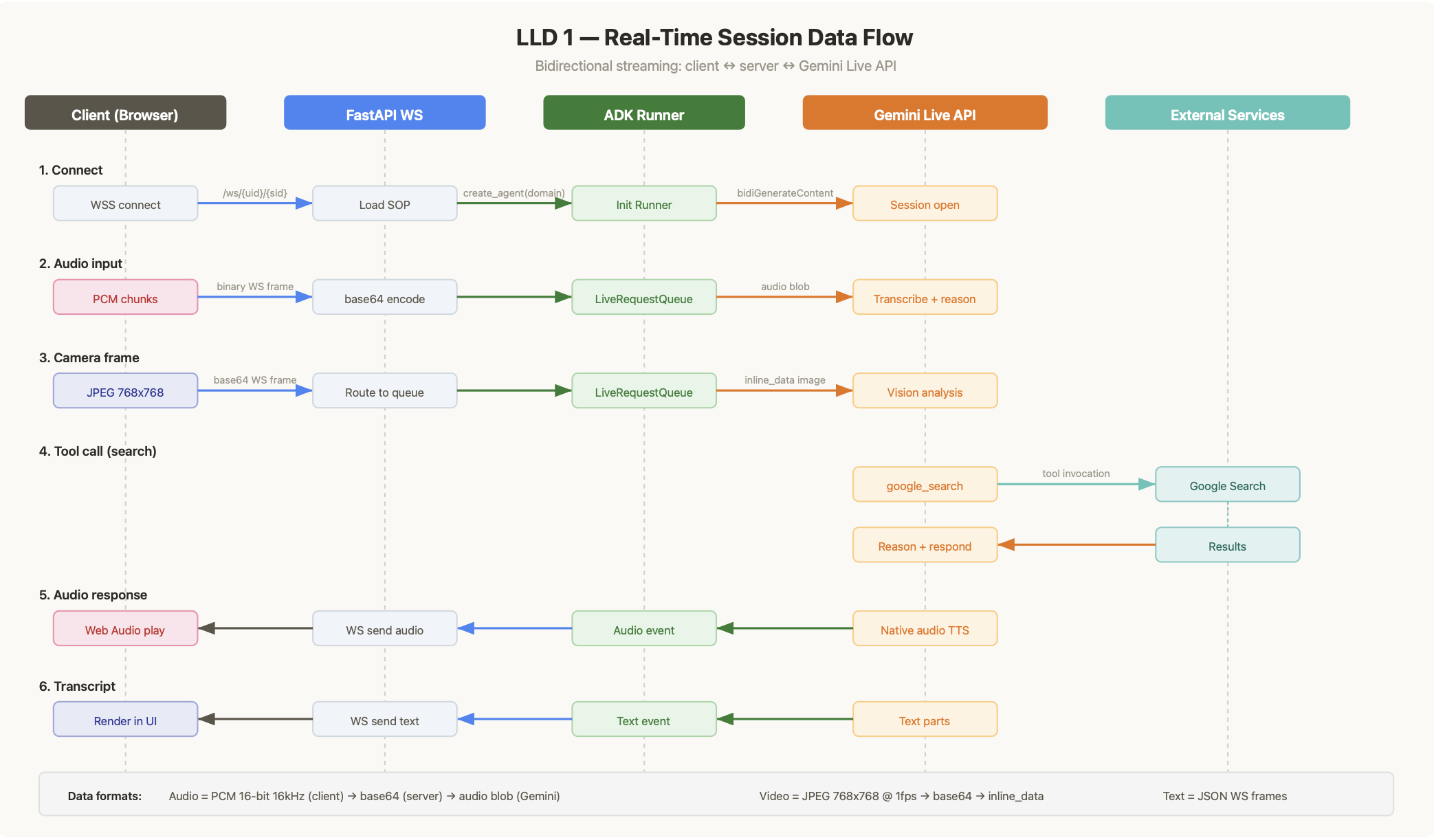
Gemini Live API for real-time bidirectional WebSocket streaming. All customer input (PCM audio at 16-bit 16kHz, JPEG camera frames at 768x768 1fps, text, images) flows into one connection, and native audio responses stream back through the same path.
Google ADK in streaming bidi mode as the agent framework. Each session gets a LiveRequestQueue that manages the bidirectional stream with Gemini's bidiGenerateContent endpoint.
Gemini 2.5 Flash Native Audio (gemini-2.5-flash-native-audio-preview-12-2025) handles voice natively. No separate STT or TTS services. The model reasons about audio directly and generates speech as output.
Google Search as the real-time knowledge layer via ADK's built-in google_search tool. No RAG pipeline, no vector database, no ingestion. The agent searches when it needs answers.
FastAPI + uvicorn on the backend, handling WebSocket connections with binary frame support for audio and camera data.
Cloud Run + Cloud Build for deployment. A single deploy.sh script enables GCP APIs, builds the container, deploys with session affinity for WebSocket stability, and outputs a live HTTPS URL (required for mic/camera access in the browser).
Why Google Cloud. Cortado needs HTTPS to access the microphone and camera in the browser. Cloud Run gives you that out of the box with managed certificates, WebSocket support, and session affinity for stable Gemini Live API connections. The deploy pipeline is a single shell script that enables GCP APIs, builds the container, and outputs a live URL. And since the entire stack is Google (ADK, Gemini, Search, Cloud Run), auth, networking, and debugging all live under one roof. Worth noting: I missed the hackathon GCP credit deadline, so this entire project was built and deployed on personal API credits, fully self-funded.
Resend for branded HTML ticket confirmation emails.
The frontend is vanilla HTML/CSS/JS with Web Audio API and AudioWorklet processors for PCM audio capture and playback.
Note: Concept, architecture, system design, and SOPs are a solo effort. I partnered with AI for coding.
Challenges I ran into
Audio pipeline complexity. Getting PCM audio flowing bidirectionally over WebSocket with the right encoding (16-bit, 16kHz, base64) through ADK's LiveRequestQueue to Gemini and back took significant iteration. AudioWorklet processors on the client side and binary frame handling on the server side were both essential.
Vision honesty. Early on, the agent would confidently identify products from blurry or poorly angled camera feeds. It took explicit honesty guardrails in the SOP ("if you cannot clearly identify the device, ask the customer to adjust the camera") to get the agent to admit uncertainty instead of guessing. Big lesson in how much behavior is shaped by the SOP.
SOP engineering. Writing an effective SOP is harder than it sounds. The personality, search strategy, visual assessment guidelines, and escalation rules all have to work together coherently. Small changes in wording produced noticeably different agent behavior. The SOP is the brain and personality.
WebSocket session management. Maintaining stable bidirectional WebSocket connections through Cloud Run required session affinity configuration. Without it, requests could land on different instances and break the Gemini Live API connection mid-conversation.
Accomplishments that I'm proud of
Domain switching works. The Wahoo cycling buddy and the Garmin tech sergeant feel like completely different agents. Different personality, different tone, different search targets, different visual behavior. And the only difference is a string. That validates the core hypothesis.
Adding Garmin took hours, not months. Once the Wahoo domain was working, standing up Garmin was purely an SOP writing exercise. No new code, no new integrations, no new pipelines. If this pattern holds, supporting N domains costs O(N) in writing effort and O(1) in engineering.
It feels like a real conversation. Gemini 2.5 Flash Native Audio combined with the Live API's bidirectional streaming makes interactions feel natural in a way that's hard to appreciate until you hear it. Barge-in works. "Can you show me that?" works. It's not a chatbot with a voice layer bolted on.
One-command deployment. deploy.sh takes a project ID and API key, and gives back a live HTTPS URL. Open it on your phone, grant mic and camera, and you're talking to Cortado.
The architecture diagrams tell the full story. L0 context diagram, system architecture, real-time session flow, and ticket creation flow. The system is simple enough that four diagrams cover the entire design.
What I learned
The SOP is the product. The entire difference between a friendly cycling buddy and a tactical watch sergeant is a system prompt. Same codebase, same tools, same infrastructure. The SOP captures everything that makes a support agent feel domain-specific, and Gemini handles the reasoning, search, and conversation.
Real-time search can replace RAG for public knowledge. For products with solid public documentation (support sites, YouTube, forums), Google Search finds answers in real time and always returns the current version. No ingestion pipeline, no stale embeddings. For proprietary internal knowledge, you'd still want RAG or MCP. Different problem, different tool.
Native audio changes what's possible. No transcription hop, no synthesis hop, no cascading latency. The conversation feels natural. Combined with the Live API's bidirectional streaming, this is the capability that makes SOP-based voice support viable.
Vision honesty has to be explicitly taught. The model is perfectly capable of saying "I can't quite make that out, could you move closer?" It just needs the SOP to set that expectation. Agent behavior is shaped far more by the training manual than most people realize.
The Gemini stack is cohesive. ADK for the agent framework, Gemini Live API for real-time streaming, Native Audio for voice, Google Search for knowledge, Cloud Run for deployment. Everything integrates cleanly under one roof. When debugging at 2am during hackathon crunch, there's one console, one set of logs, one IAM model.
Self-funded infrastructure. I missed the deadline for hackathon GCP credits, so every API call, every Cloud Run deployment, every Gemini request came out of pocket. It forced me to be deliberate about testing and deployment. No room for wasteful iteration loops.
What's next for Cortado
More domains. Two domains validate the pattern. The interesting question is whether it holds at 50 or 500 domains with thousands of concurrent sessions.
MCP integration for private knowledge. Both test domains have excellent public documentation. For products where critical knowledge is internal, MCP alongside the SOP would extend coverage without losing the architectural simplicity.
A/B testing SOP variants. Small changes in SOP wording produce noticeably different agent behavior. A framework for testing SOP variants against resolution rate and customer satisfaction metrics would turn SOP writing from art into engineering.
Formal evaluation. Evaluation is currently qualitative. Structured test cases with human panels, measuring resolution accuracy, customer satisfaction, and task completion rates against workflow-based baselines.
Persistent ticket storage. The current in-memory ticket store is fine for demo. A production deployment would need durable storage with full conversation history and analytics.
Built With
- fastapi
- gemini-2.5-flash-native-audio
- gemini-live-api
- google-adk
- google-cloud-build
- google-cloud-run
- html/css
- javascript
- python
- resend
- web-audio-api


Log in or sign up for Devpost to join the conversation.