-
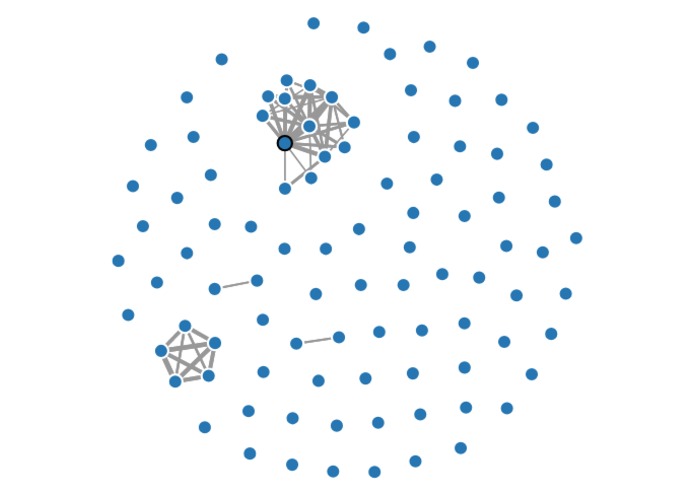
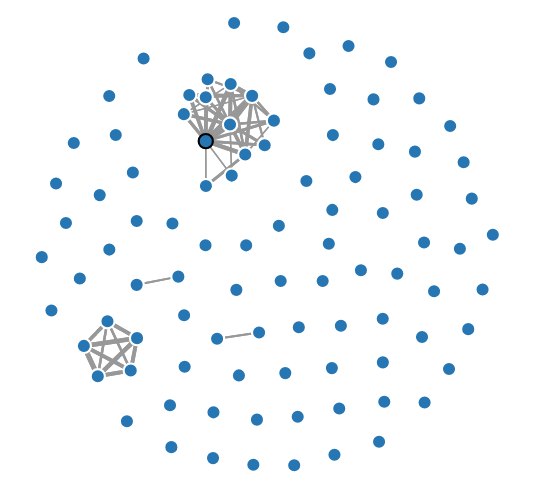
Subgraphs revealing substantial dependencies in growth scores
-
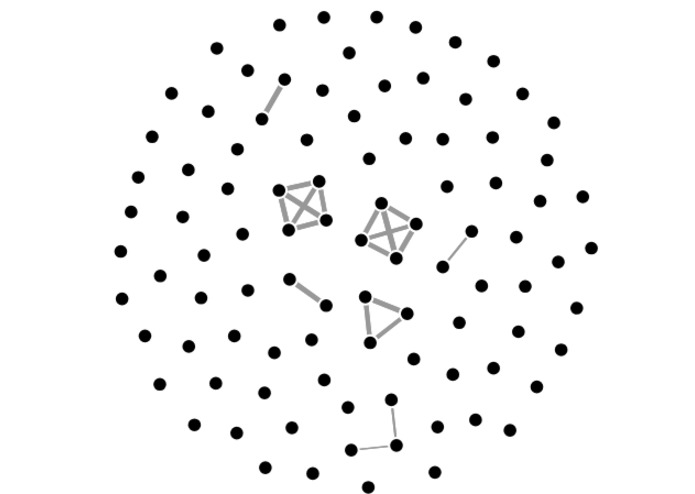
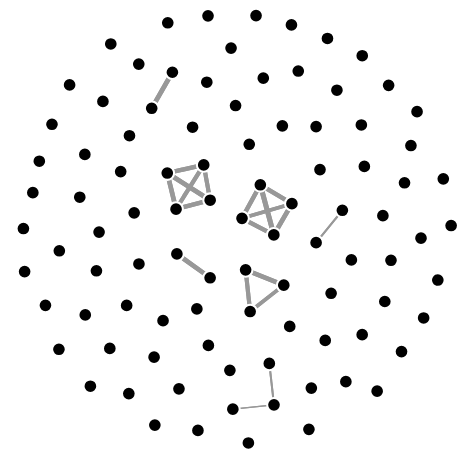
Subgraphs revealing substantial dependencies in financial returns
Inspiration
We really loved thinking about what would be the best unsupervised model to compare statistics given as time series. It was an interesting probability/statistics problem to understand what dependencies we really wanted to capture between companies (companies might be correlated for simply being part of the stock market). Once we got the sufficient correlations between companies, we found that visualizing the dependency graph and finding fundamental subgraphs helped select which dependencies were substantial.
What it does
Finds relationships between companies based on the time series of certain statistics based on their stock data. Our clusters can reveal companies which are tightly correlated within their sectors, as well as companies which similarly experienced large changes within prices in the same time period.
How we built it
The project mainly consists of a python script which handles the retrieval and processing of the data, and a simple d3 web applet to visualize our results.
We pulled data from Goldman Sachs API, consisting of stock statistic time series from the past several years for 100 companies. We parsed the time series, and to eliminate the natural trend of the market we restricted ourselves to correlating first order differences of these time series.
We also considered several metrics with which to cluster the series, and chose what we ultimately considered the best metric in terms of practical results and intuitive appeal. Furthermore, finding K-cliques in a corresponding graph segmented the 100 companies into naturally occurring groups.



Log in or sign up for Devpost to join the conversation.