Inspiration
Organizations often struggle with fragmented knowledge spread across PDFs, reports, policies, manuals, and internal documents. Finding the right information is time-consuming, and conflicting versions of information can create confusion. We wanted to build a system that transforms static documents into an intelligent, searchable knowledge base that acts as an institution's collective memory.
What it does
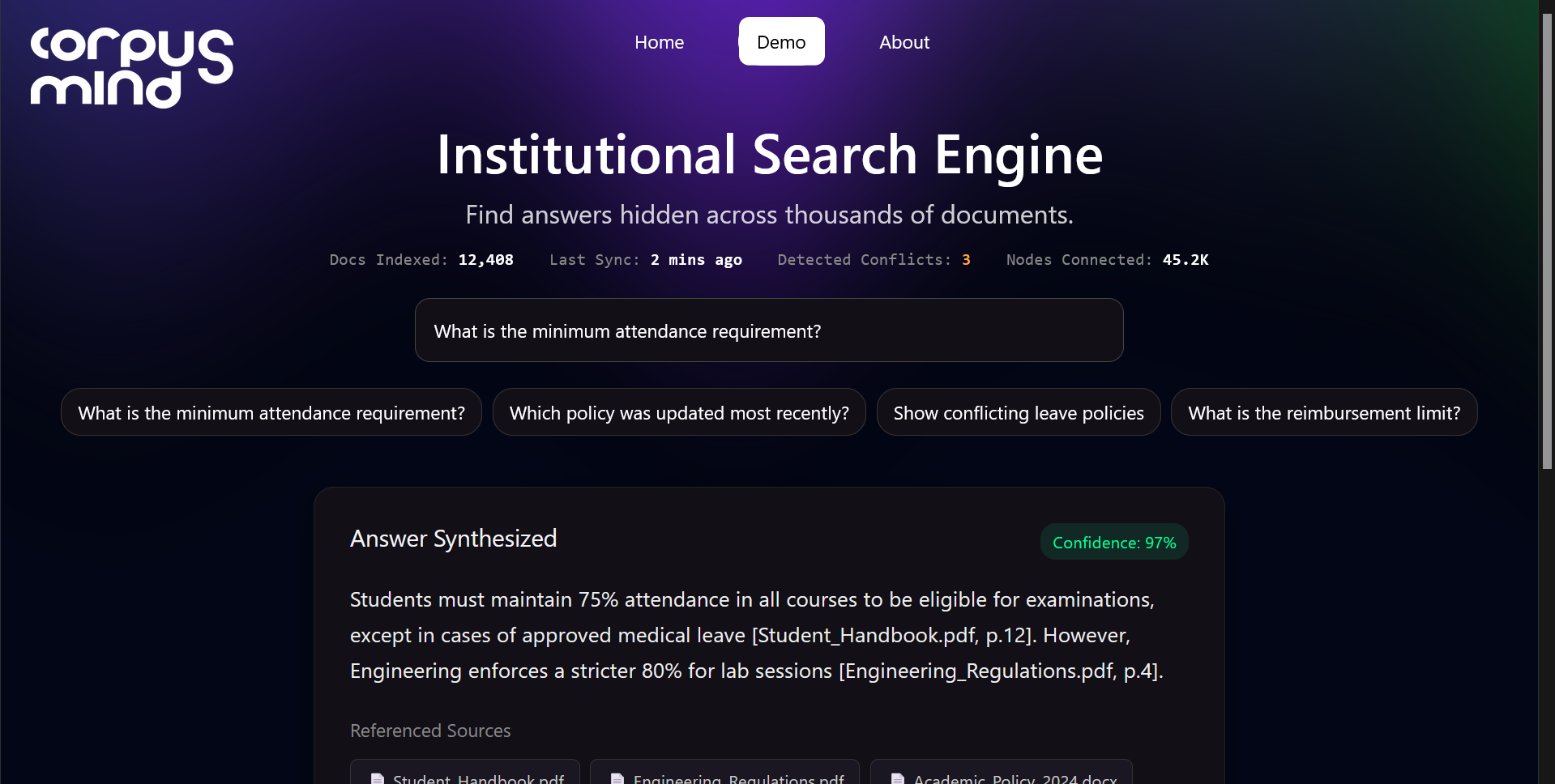
Corpus Mind is an AI-powered institutional knowledge engine that ingests documents, converts them into vector embeddings, and enables semantic search across organizational knowledge. Users can query information using natural language, discover relevant knowledge, identify conflicting information across sources, and surface valuable institutional insights.
How we built it
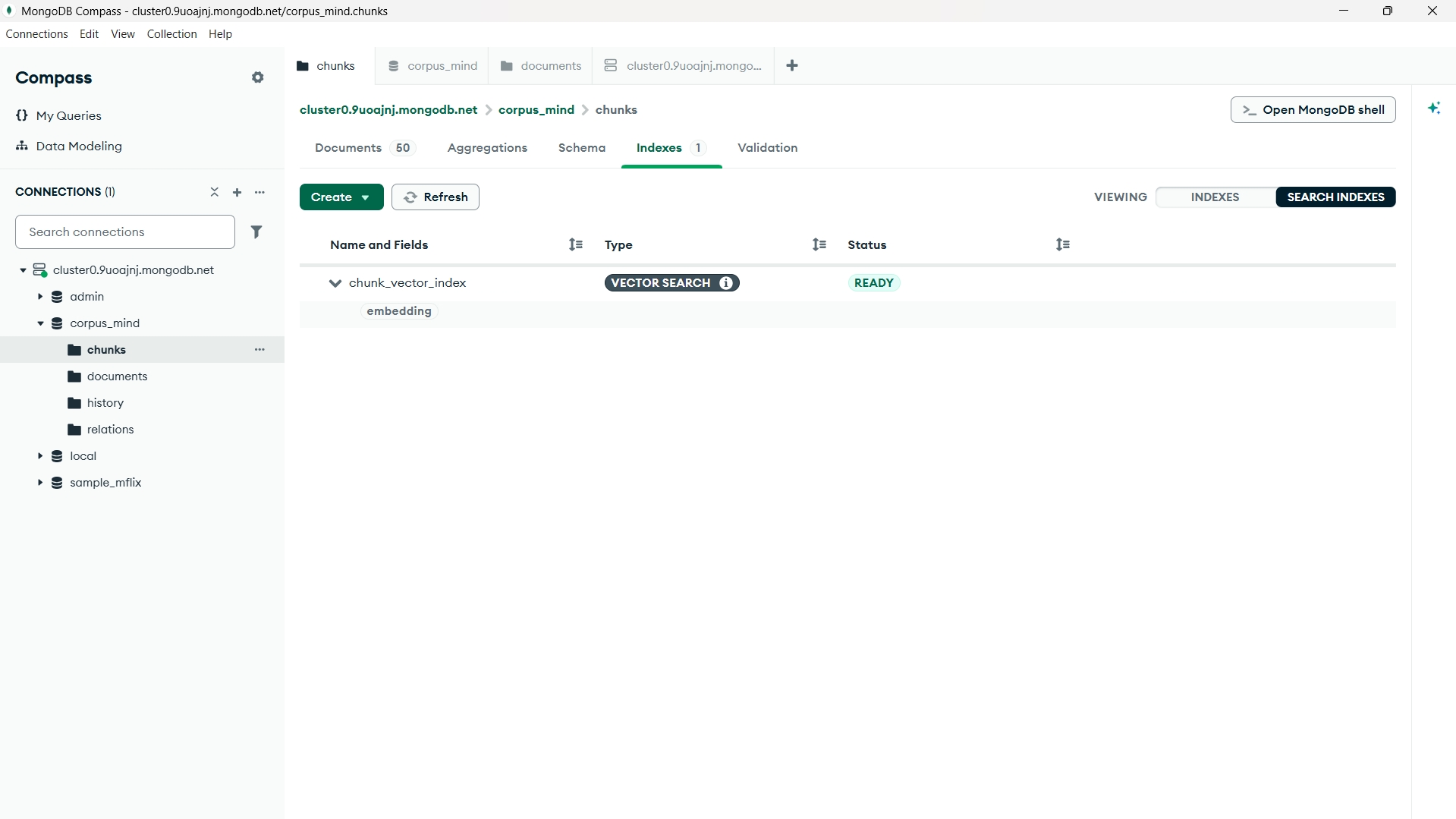
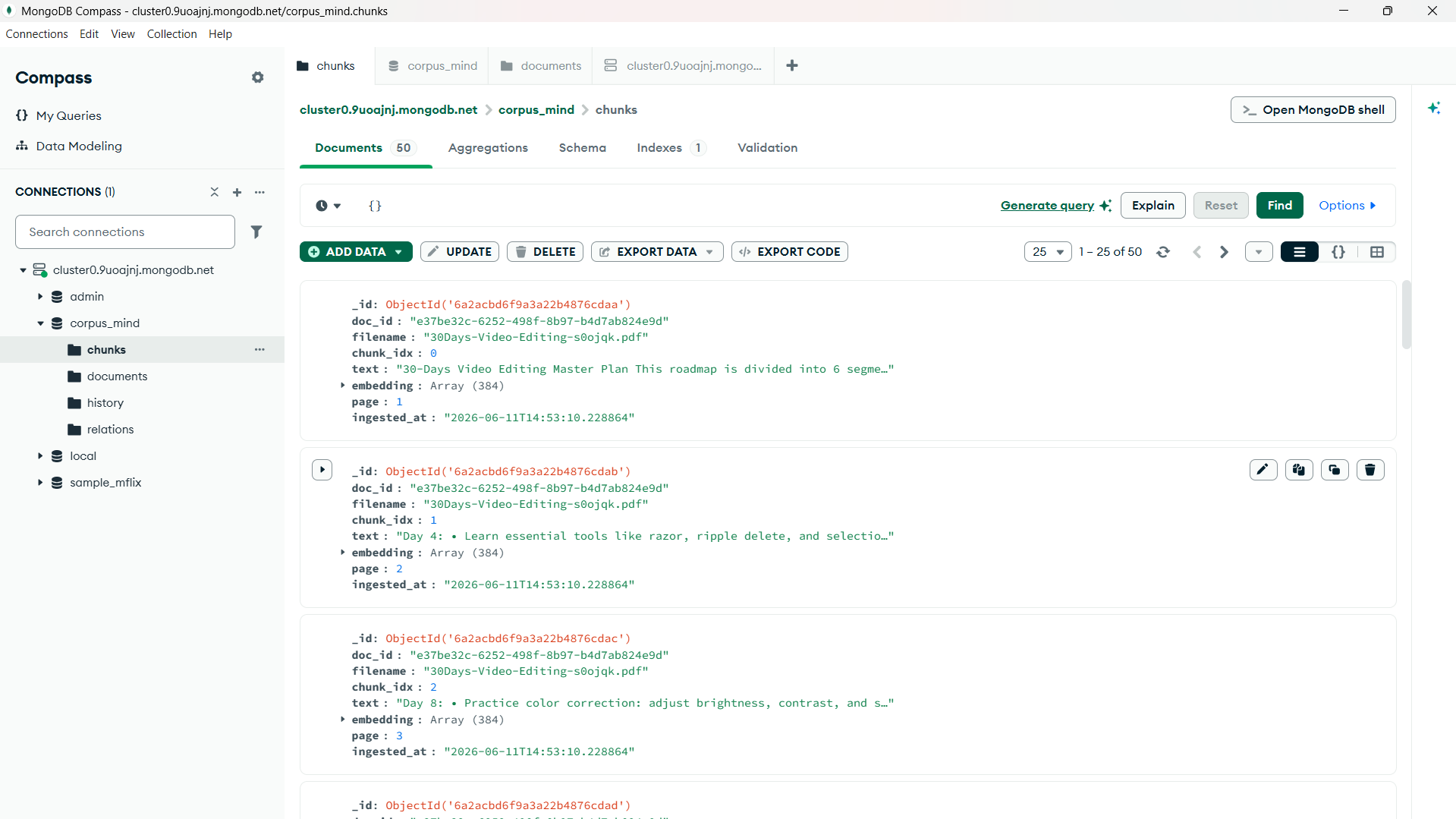
We built the frontend using React and the backend using FastAPI. Documents are processed and chunked before being embedded using SentenceTransformers. The embeddings are stored in MongoDB Atlas and retrieved through MongoDB Vector Search. Relevant chunks are then passed to an LLM-powered reasoning layer that synthesizes responses, cites sources, and highlights potential conflicts across documents.
Challenges we ran into
One of our biggest challenges was integrating multiple AI and retrieval components into a single workflow. We also faced challenges related to model inference, API reliability, vector search configuration, document processing, and ensuring that retrieved information remained relevant and accurate.
Accomplishments that we're proud of
We successfully built an end-to-end institutional knowledge system capable of document ingestion, semantic retrieval, conflict detection, and AI-powered reasoning. We are especially proud of creating a working knowledge pipeline that transforms unstructured documents into searchable institutional intelligence.
What we learned
Through this project, we gained hands-on experience with Retrieval-Augmented Generation (RAG), vector embeddings, MongoDB Atlas Vector Search, document processing pipelines, semantic retrieval, and AI system integration. We also learned the importance of balancing retrieval quality, performance, and user experience.
What's next for Corpus Mind
We plan to expand Corpus Mind with support for additional data sources such as emails, cloud drives, and enterprise platforms. Future versions will include real-time knowledge updates, advanced relationship mapping between documents, role-based access controls, analytics dashboards, and deeper AI-powered institutional intelligence capabilities.
Built With
- 3.1
- atlas
- fastapi
- javascript
- llama
- mongodb
- ollama
- python
- react
- search
- sentencetransformers
- vector

Log in or sign up for Devpost to join the conversation.