CliniSearch: A Multimodal Medical Research & Radiology Assistant
Inspiration
In today's medical landscape, the volume of new research, clinical data, and patient information is growing at an exponential rate. We were inspired by the daily challenge faced by clinicians and researchers: how to quickly and accurately access and synthesize this vast sea of data to make informed decisions. A conversation with a radiology resident highlighted a specific pain point: the time-consuming process of cross-referencing a patient's imaging findings with their clinical history and the latest peer-reviewed literature. This sparked the core idea for CliniSearch: an AI agent that could not only "read" but also "see," acting as an intelligent assistant to bridge the gap between diverse medical data types.
What it does
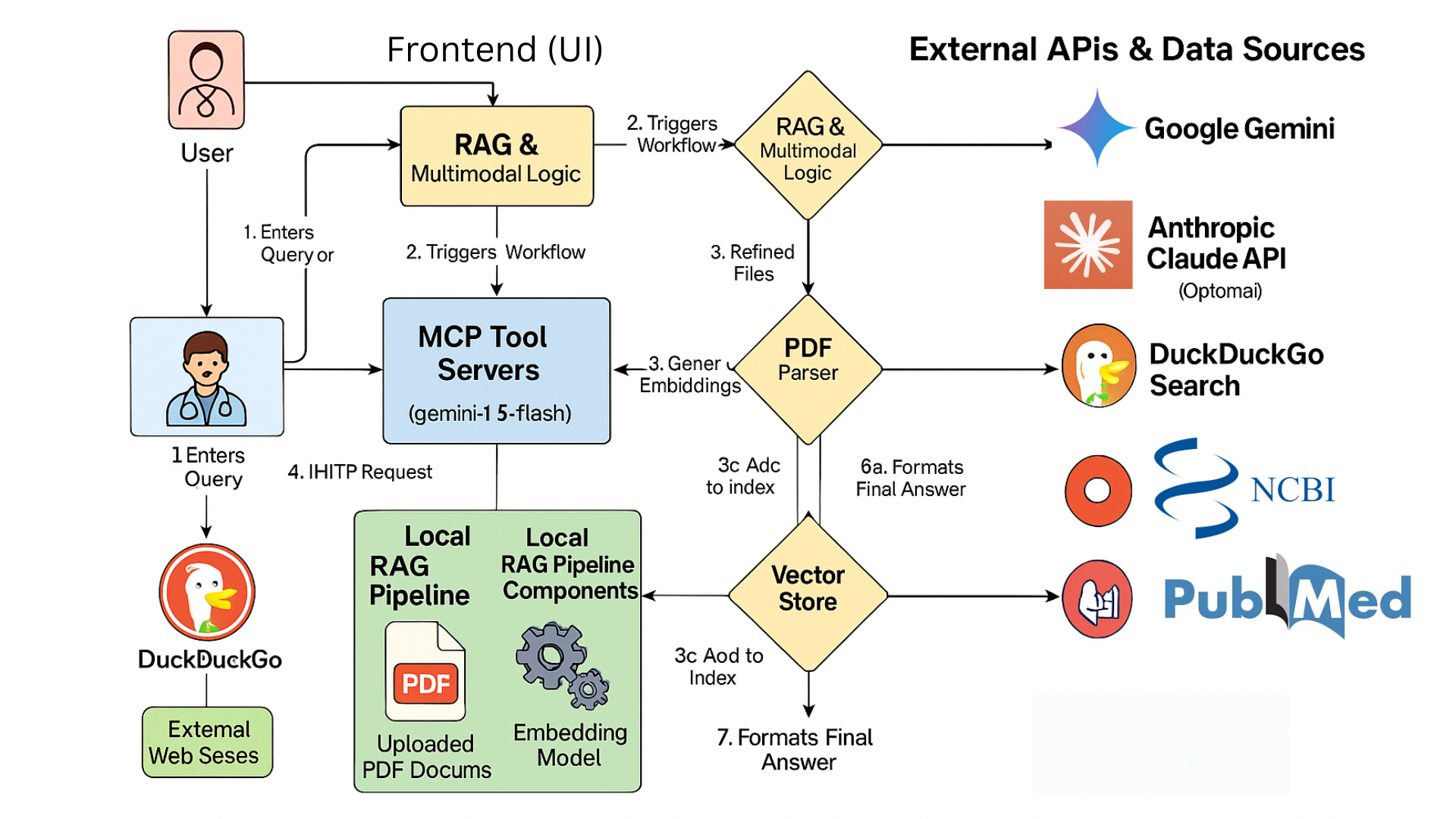
CliniSearch is a powerful, multimodal AI agent designed to be a "second brain" for medical professionals. Its functionality is split into two primary tools:
Medical RAG Q&A: Users can ask complex medical questions and receive synthesized, evidence-based answers. The agent retrieves information in real-time from three distinct sources:
- General Web Search: For broad context and general knowledge.
- PubMed: For access to peer-reviewed scientific literature.
- Uploaded Documents: Users can upload their own PDFs (research papers, reports) to create a private, searchable knowledge base for highly specific queries.
Radiology Image Analysis: This tool is designed specifically for radiologists. A user can:
- Upload an anonymized medical image (e.g., an X-ray).
- Optionally upload a related context document (e.g., a patient's clinical notes).
- The AI then analyzes the image, providing a preliminary description of findings and potential differential diagnoses, using the context from the uploaded text to deliver a more holistic and relevant analysis.
All outputs are clearly sourced with links, ensuring transparency and allowing for easy verification.
How we built it
We architected CliniSearch as a modular, modern web application with a clear separation of concerns.
Frontend: The user interface is built with Streamlit, chosen for its ability to rapidly create interactive and data-centric web apps in Python. We used tabs to separate the two main functionalities and custom styling to ensure a clean, professional UI.
Backend & Orchestration: The core logic resides within the Streamlit app (
app.py), which orchestrates calls to various backend components. We used Python'sasynciolibrary to handle concurrent requests to our data sources, improving efficiency.Tool Servers (MCP): We built two lightweight, independent tool servers using FastAPI to handle data retrieval. This "Model Context Protocol" approach makes the system modular and scalable.
- One server uses the
duckduckgo-searchlibrary for web searches. - The other uses
BioPythonto interact with the NCBI Entrez API for PubMed searches.
- One server uses the
AI & RAG Pipeline: This is the heart of our project.
- LLMs: We leveraged the Google Gemini API, specifically
gemini-1.5-flash-latest, for its powerful text synthesis and state-of-the-art multimodal (vision) capabilities. - Embeddings: For our local RAG feature, we used a
sentence-transformersmodel to generate vector embeddings from PDF text. - Vector Store: We implemented an in-memory vector database using FAISS from Meta AI, which allows for incredibly fast semantic similarity searches on the uploaded documents.
- LLMs: We leveraged the Google Gemini API, specifically
GCP Readiness: The project was built with an eye towards production, with a structure ready for deployment on Google Cloud Platform services like Cloud Run (for the app and servers) and Vertex AI (for embeddings and vector search).
Challenges we ran into
Real-time API Latency: Integrating multiple real-time APIs (Web Search, PubMed, Gemini) presented a challenge. Initial user requests were slow. We mitigated this by using
asyncioto run the data retrieval tasks concurrently, significantly speeding up the process.Context Window Management: LLMs have finite context windows. Combining information from three different RAG sources could easily exceed this limit. Our solution was to process each source independently and present separate, synthesized answers, which not only solved the technical problem but also improved the clarity and traceability of the output for the user.
UI State and Interactivity: Streamlit reruns the script on every interaction, which made managing the state of our vector store and file uploads tricky. We solved this by effectively using
st.session_stateto persist data across reruns and implementing logic to ensure PDFs were only processed once upon upload.
Accomplishments that we're proud of
True Multimodality: We're incredibly proud of the Radiology Analysis tab. It's not just an image-to-text model; it's a system that fuses visual analysis with contextual text-based RAG, which we believe is a significant step towards creating truly useful clinical AI assistants.
Modular and Scalable Design: By separating our data retrieval into microservice-like MCP servers, we've built a system that is easy to maintain and extend. Adding a new data source would be as simple as building another small FastAPI server.
Delivering a Polished UX: Despite the technical complexity on the backend, we managed to create a clean, intuitive, and professional-looking user interface that is genuinely usable.
What we learned
- The Power of RAG: We learned firsthand how Retrieval-Augmented Generation can ground LLMs in factual, real-time, or private data, drastically reducing hallucinations and increasing the reliability of their outputs.
- The Nuances of Prompt Engineering: Crafting effective prompts is an art. We learned how to structure prompts to instruct the LLM to use only the provided context, to cite sources, and to tailor its response for a specific audience (like a medical professional).
- Full-Stack Python Development: This project was a deep dive into the modern Python ecosystem, from backend APIs with FastAPI to interactive web UIs with Streamlit and advanced AI/ML libraries like FAISS and Sentence Transformers.
What's next for CliniSearch
CliniSearch is a powerful proof-of-concept with immense potential for growth. Our next steps would include:
- Deployment on GCP:6 -x Moving the application and its components to Google Cloud Platform to make it scalable, reliable, and accessible. This would involve using Cloud Run, Vertex AI Vector Search, and Document AI for more robust PDF parsing.
- Enhanced Conversational Memory: Implementing a more sophisticated chat history management system (e.g., using Firestore) to allow for meaningful follow-up questions.
- Deeper EMR/RIS Integration: Developing secure integrations with hospital systems (like EMRs) to automatically pull relevant patient context, further enhancing the AI's utility.
- Model Evaluation and Fine-Tuning: Rigorously evaluating the accuracy of different models (including the Claude family) and potentially fine-tuning a model on a specific medical domain for even higher accuracy and reliability.

Log in or sign up for Devpost to join the conversation.