-
-
Diagram
-
Dashboard
-
DC Analysis
Inspiration
The global forensic crisis is undeniable. Medical examiners are drowning in paperwork, spending up to 6 hours per day documenting autopsies manually. This administrative bottleneck leads to delayed justice, grieving families waiting weeks for answers, and critical errors in death certification due to fatigue. We identified a fundamental gap in current legal-tech: existing tools are merely dictaphones. They listen, but they do not understand. We were inspired by the potential of Large Reasoning Models (LRMs). We realized that in a high-stakes environment like a morgue, speed is not enough; we need deep, analytical validation. We set out to build not just a tool, but a cognitive colleague that validates medical findings in real-time.
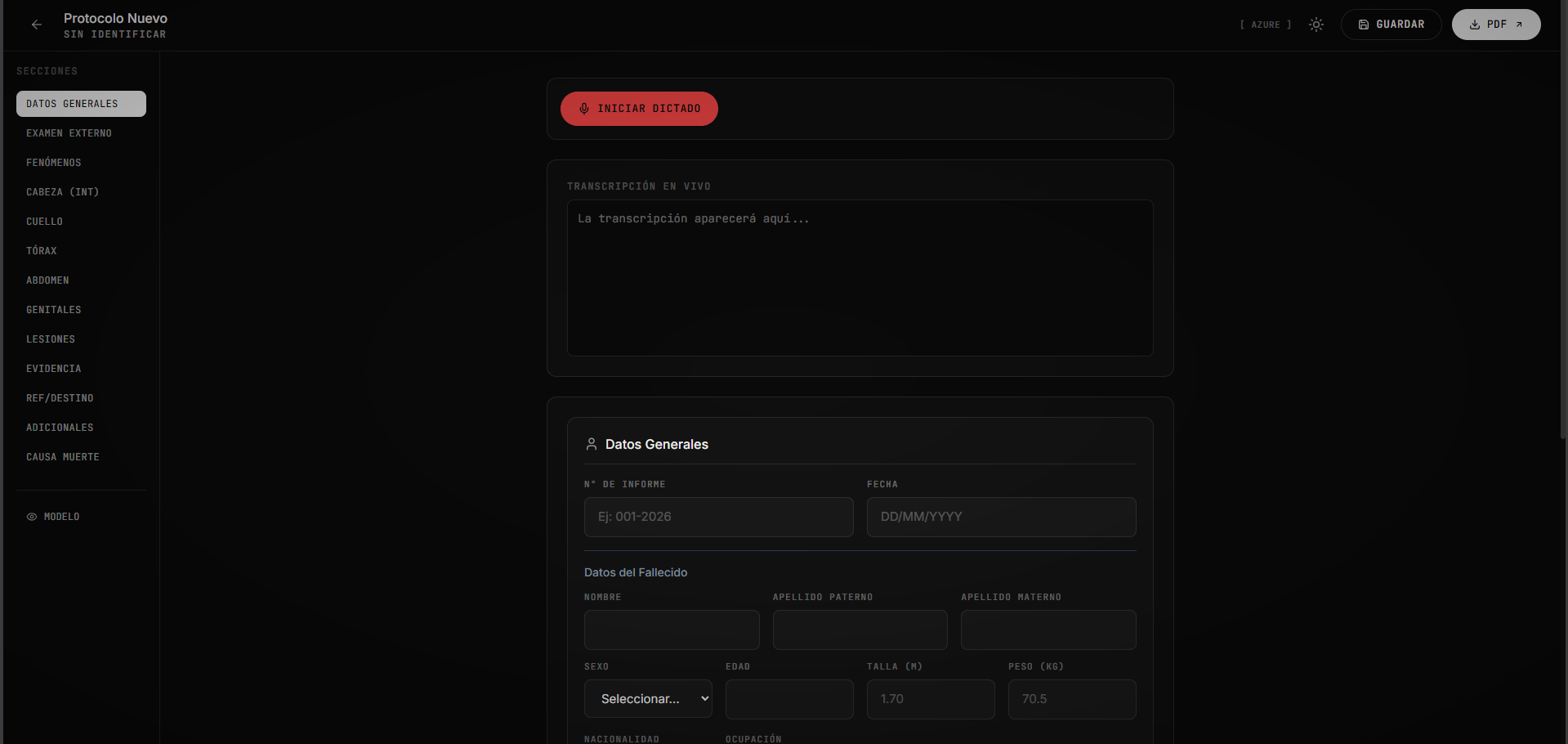
What it does
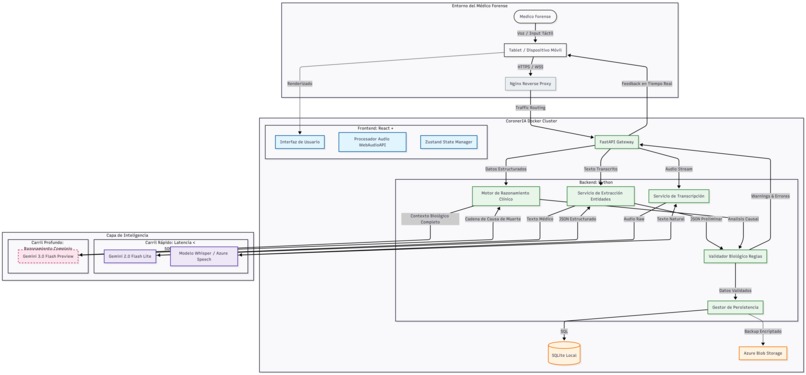
CoronerIA is the world's first intelligent forensic copilot powered by a novel Hybrid AI Architecture. It transforms the autopsy workflow by digitally splitting tasks between two specialized models:
1. The Real-Time Assistant (Speed)
Powered by Gemini 2.0 Flash Lite, this layer handles the "mechanical" heavy lifting.
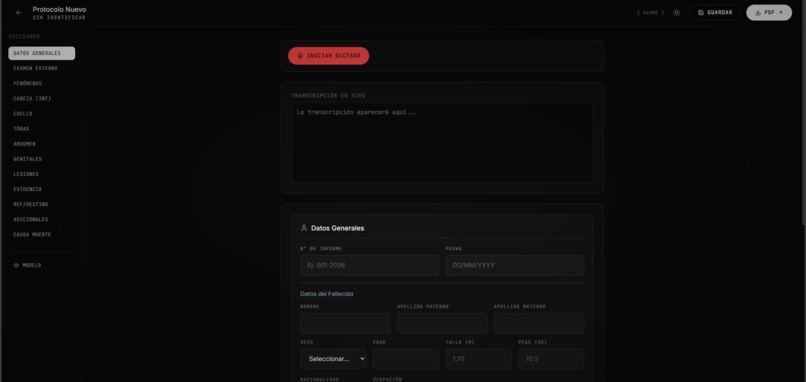
- High-Speed Dictation: Ingests voice commands in the noisy morgue environment with near-zero latency.
- Entity Extraction: Normalizes complex anatomical terminology in milliseconds.
- Protocol Automation: Instantly fills out the standardized legal forms required by the judiciary. ### 2. The Clinical Reasoner (Intelligence) Powered by Gemini 3 Flash Preview, this layer handles the "cognitive" analysis.
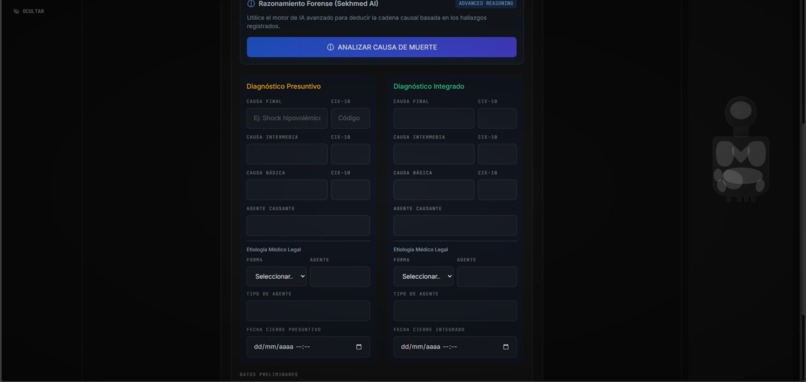
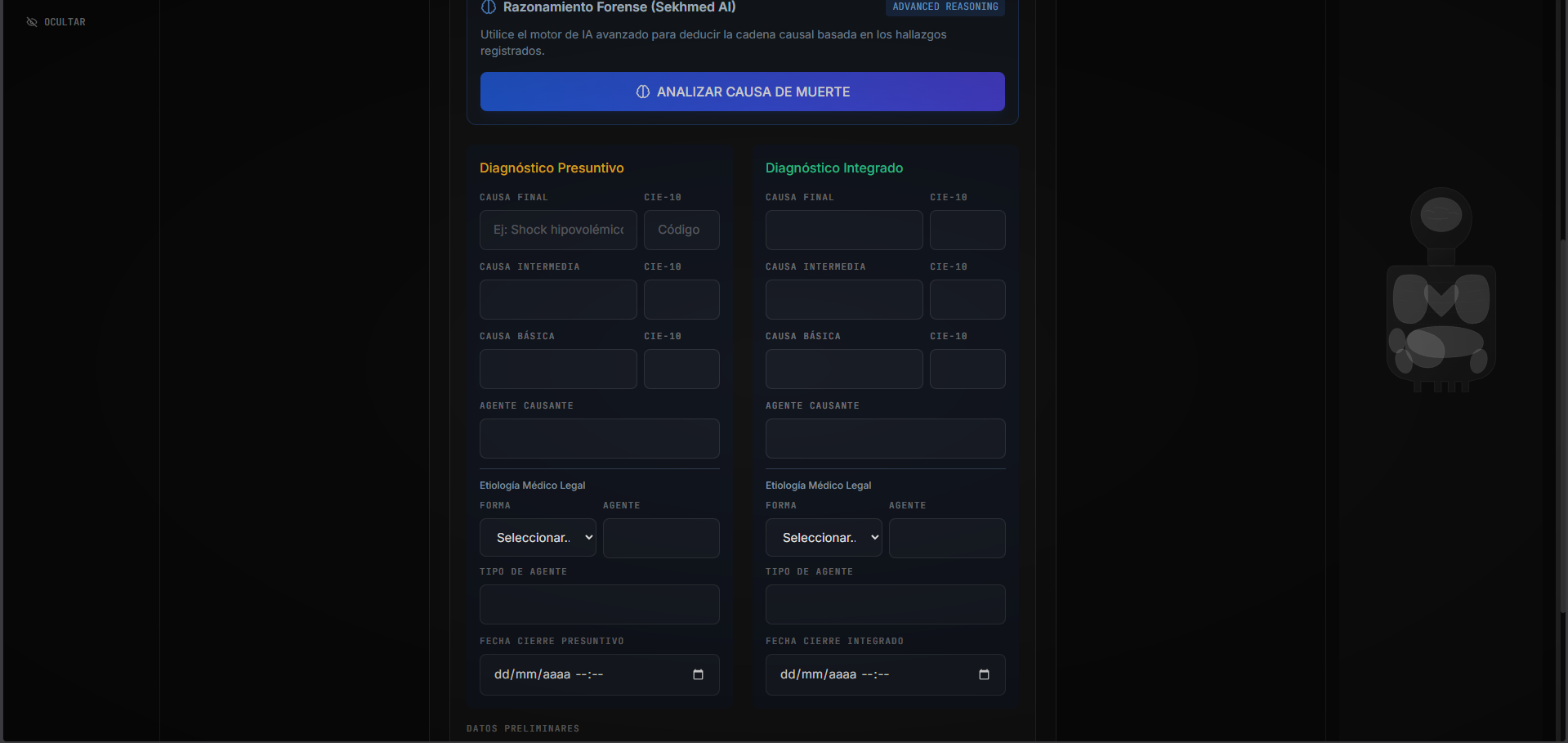
- Cause-of-Death Reasoning: Processes structured biological data to suggest the causal chain (Basic, Intermediate, and Final causes of death).
- Inconsistency Detection: acts as a second pair of eyes, flagging contradictions (e.g., "Liver weight [1500g] does not match signs of Cirrhosis").
- Socratic Validation: Explains why a conclusion was reached, citing medical principles. # How we built it We engineered CoronerIA as a production-grade, offline-first web application designed for secure government infrastructure:
- Frontend (The Edge): Built with React & TypeScript. We implemented a custom
AudioStreamProcessorto handle dictation chunks locally, ensuring reliability even with unstable hospital Wi-Fi. - Backend (The Core): Powered by Python (FastAPI), orchestrating an asynchronous AI pipeline using the Strategy Pattern to decouple logic from specific AI providers.
- The Hybrid Engine:
- Layer 1: We integrated Gemini 2.0 Flash Lite on Vertex AI for ultra-low latency.
- Layer 2: We utilized the Gemini 3 Preview Reasoning endpoints with a specialized prompt engineering framework involving "Chain of Anatomical Thought".
- Infrastructure: Fully containerized with Docker, capable of running on-premise or in a hybrid cloud, neutralizing data privacy concerns. # Challenges we faced
- The "Thinking" Latency: Integrating a reasoning model (Gemini 3) into a real-time app was non-trivial. The reasoning process is computationally intensive and slow. We solved it by architecting an asynchronous event loop: simple tasks are resolved instantly, while complex reasoning happens in a background worker, notifying the frontend via WebSockets/Polling when the deep analysis is ready.
- Medical Hallucinations: Analyzing causes of death requires 0% error. We implemented a Biological Validation Middleware (using Pydantic validators) that cross-references AI outputs with standard anatomical weight tables (e.g., organ weights vs. BMI) before showing them to the user. # Accomplishments that we're proud of
- 70% Reduction in administrative reporting time achieved in our simulations.
- Successful Hybrid Architecture: Proving that combining a small, fast model with a large reasoning model offers a superior UX than using a single giant model.
- Privacy by Design: Implementing a system that respects Chain of Custody, making it viable for immediate real-world pilot programs. # What we learned We learned that Hybrid AI is the definitive architecture for specialized professional software. One giant model is not the solution for everything. Combining a fast, cost-effective model for real-time interaction with a powerful "reasoning" model for complex logic creates a user experience that is both responsive and profoundly intelligent.

Log in or sign up for Devpost to join the conversation.