-

-
 GIF
GIF
How our model predicts the Coronavirus will spread over a year
-
 GIF
GIF
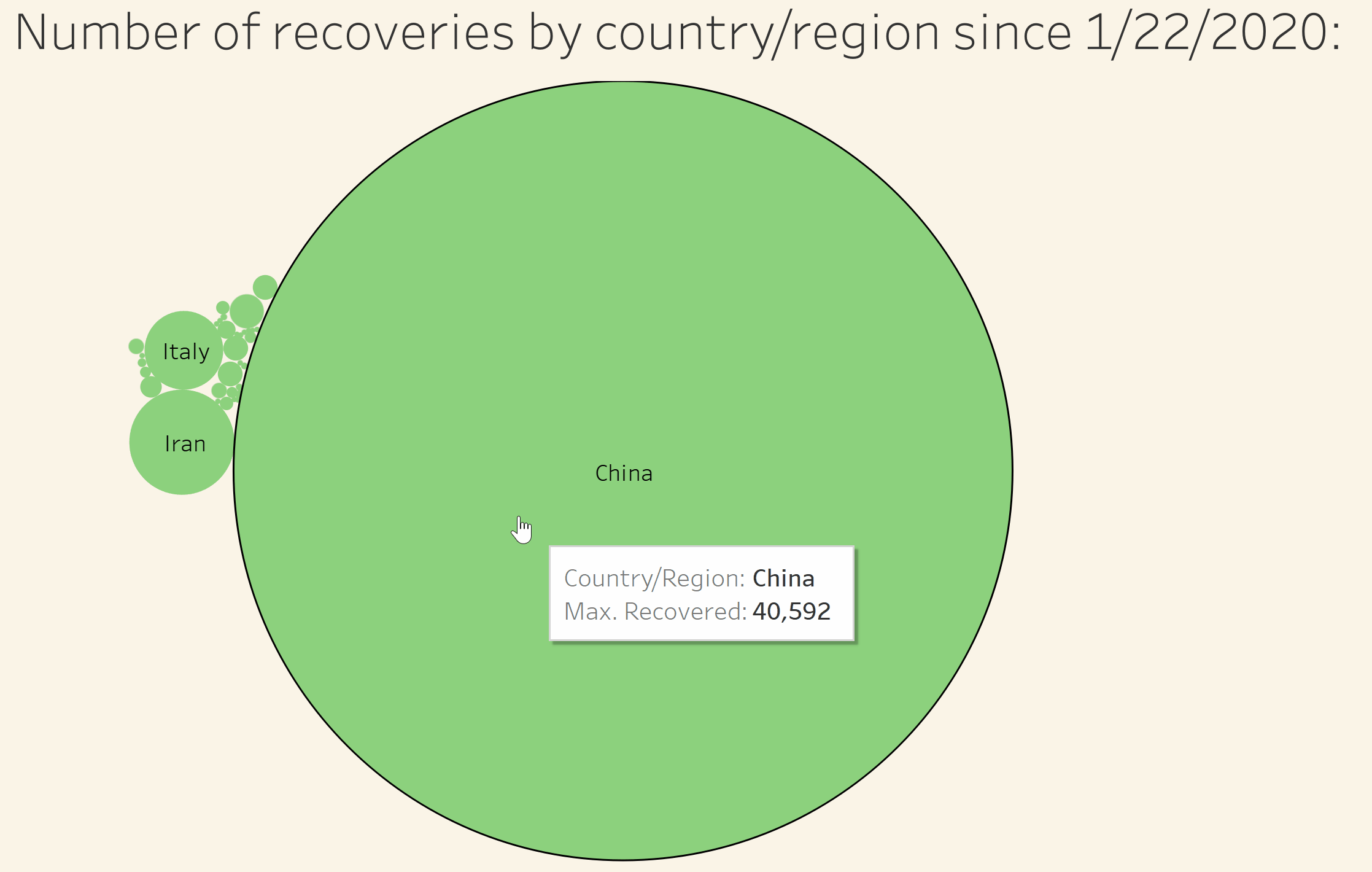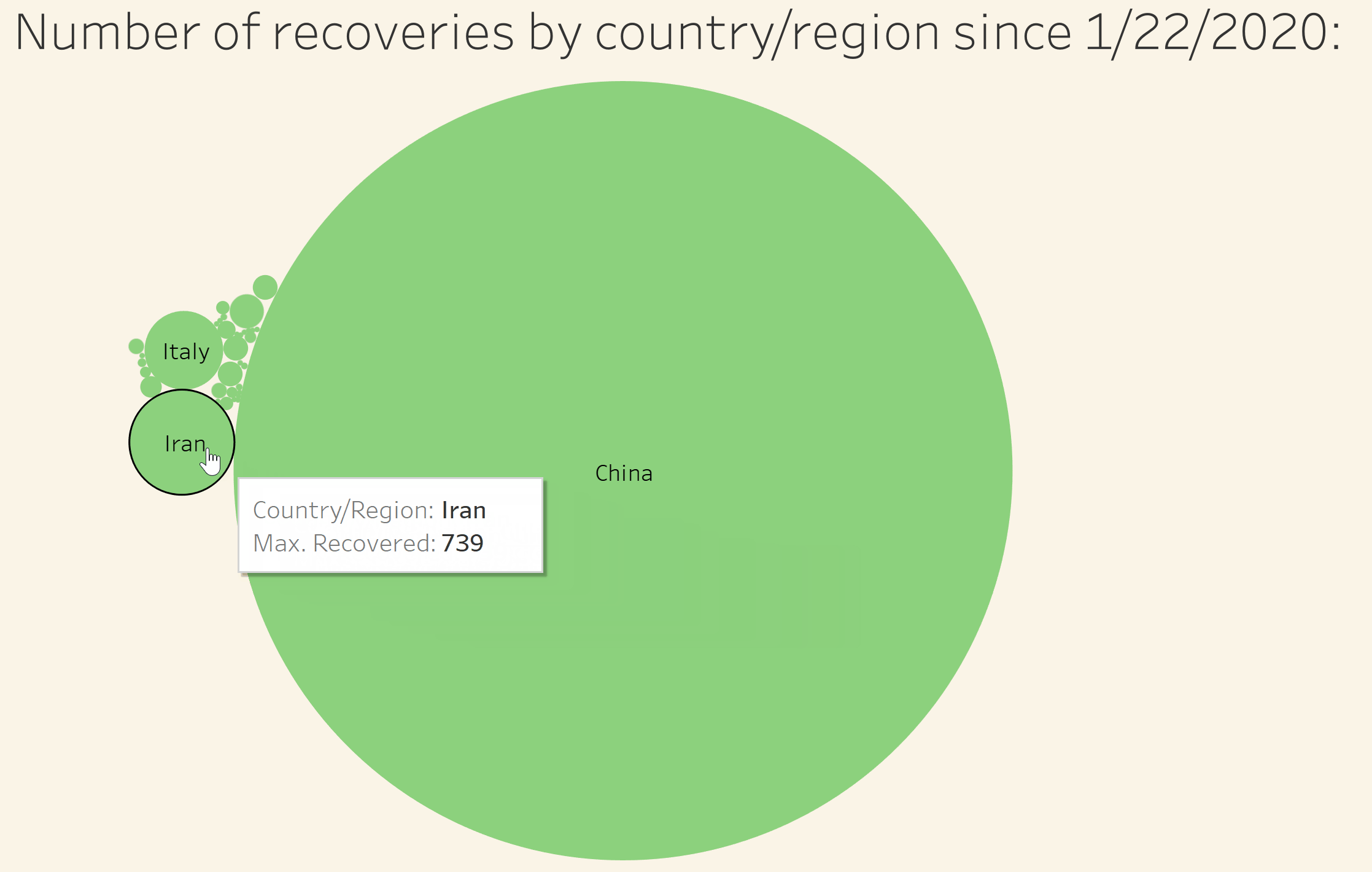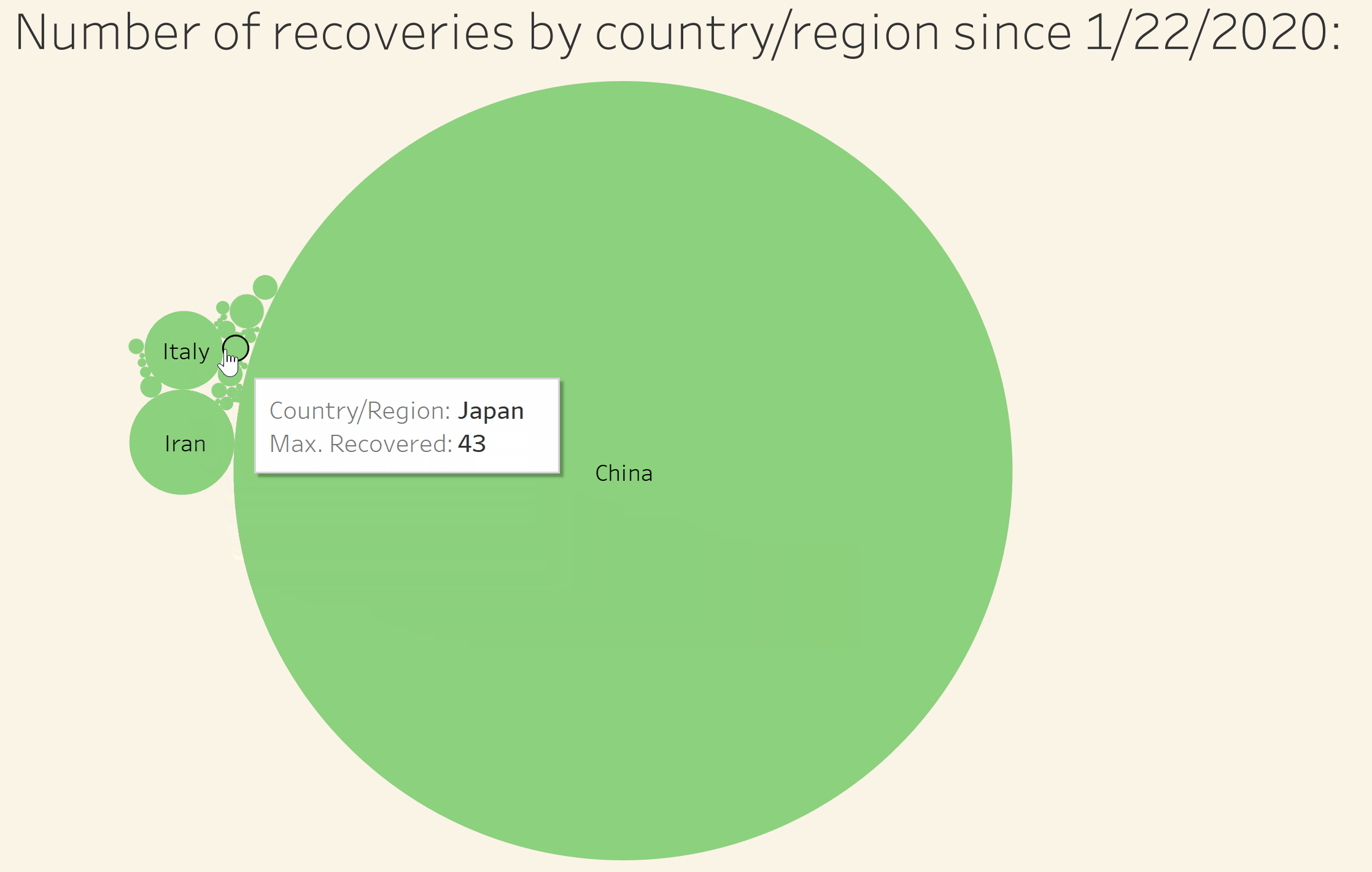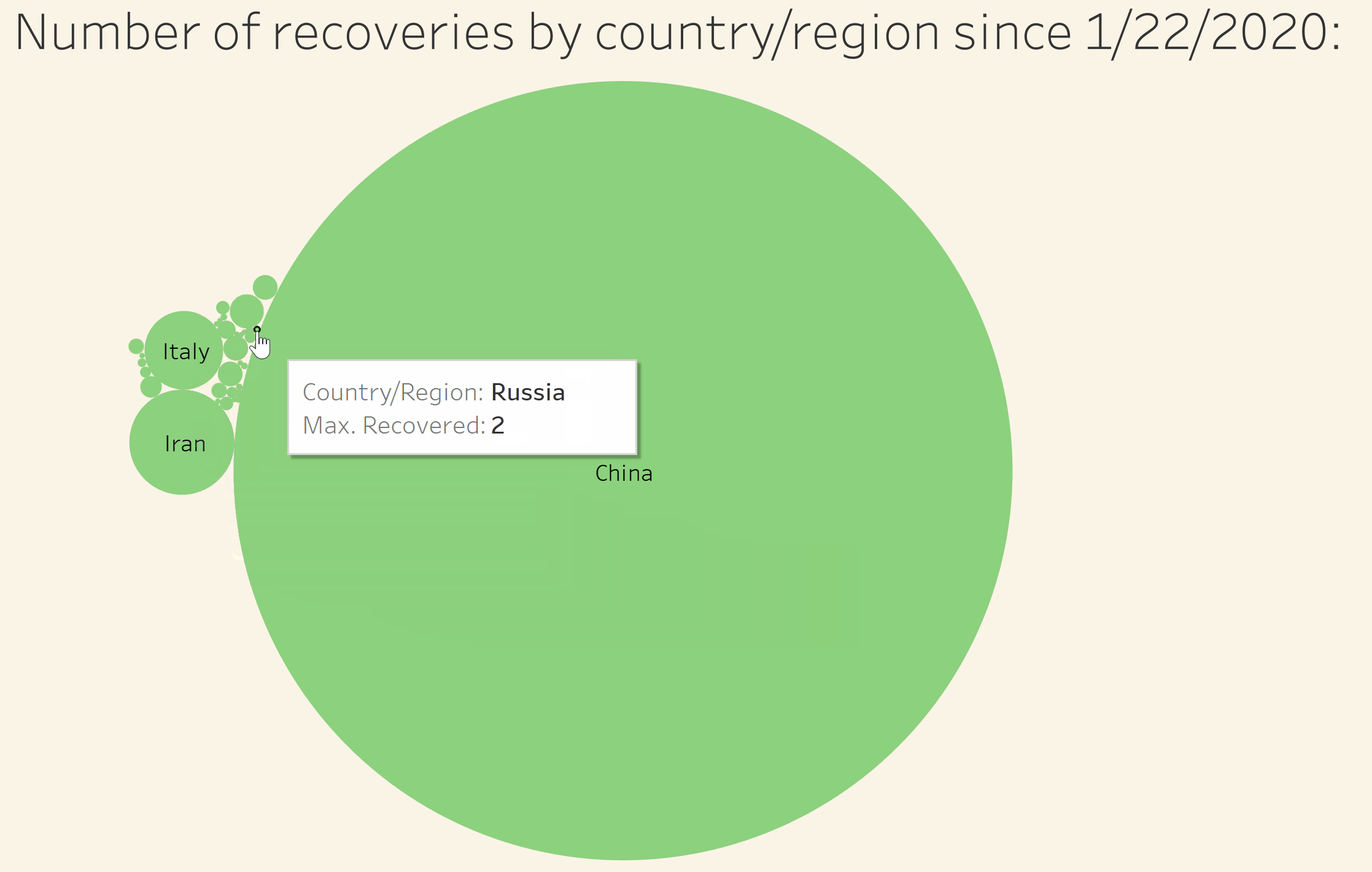
Visualize the number of recoveries by country/region in relation to all other affected countries/regions
-
 GIF
GIF
Visualize the number of deaths by country/region in relation to all other affected countries/regions
-
 GIF
GIF
Visualize the number of confirmed cases by country/region in relation to all other affected countries/regions
-

Utilized DBSCAN algorithm to cluster geospacial coordinates and reduce size of data set by roughly 95%





Live Website
http://coronadvisor.tech. The live website above provides real-time information about the spread of the coronavirus and whether or not it will affect your trip.
Video Demonstration
Check out our full video demo at the following link: http://coronadvisor.tech/video-demo.
Inspiration
Over the past weeks, the outbreak of the coronavirus has grown exponentially, and it has become a global concern. Six of the seven continents have been affected, and public concern has mounted. Moreover, the spread of the virus has caused many to have to cancel flights, often with no refund for their money.
This is where CoronAdvisor comes in.
Utilizing artificial intelligence and daily-updated data from Johns Hopkins, our application allows users to enter a location, specify a future date, then view the risk of CoronaVirus in this area on said date. Data returned includes information about the location's classification on the CDC's watch list, current number of confirmed cases, deaths, and recoveries, as well as a visualization of the spread of the virus in the surrounding area. With a prediction accuracy of 92%, as validated on the test set, our model offers one of the best forecasting-applications available on the spread of CoronaVirus throughout the world, well into the future! Test this service at the following link: http://coronadvisor.tech/video-demo.
What it does
How we built it
The first step was collecting and cleaning the data. The data was collected from Johns Hopkins, and each day's worth of data had to be merged together into one, large CSV. From here, missing values were imputed, numerical values were normalized, and categorical values were encoded, all using the SciKit-Learn library in Python. Next, we connected to the Google Maps Geolocation API, and fetched the latitude and longitude for each Country/Region and State/Province in question, then added this to the CSV file.
After the preliminary data was collected and cleaned, we tried using different Machine Learning models to predict (separately) the number of confirmed Coronavirus cases, number of deaths due to Coronavirus, and number of people that have recovered from Coronavirus, given the latitude & longidute and the number of previously deceased/confirmed/recovered by region. Eventually, after trying SVMs, Linear & Logistic Regression (with Polynomial Feature Expansion), and XGBoost, we settled on using a 3-layered Neural Network with the Rectified Linear Activation function to perform regression, achieving an r2 score of ~92%.
Predictions were made 365 days into the future, and all predictions were saved to a new CSV file. This new CSV's data was then used to create the frontend.
Challenges we ran into
Cleaning the data and making it usable by a model was one of the most challenging and time consuming portions. Dealing with missing values, a variety of different data formats, and poorly formatted columns and rows, a variety of programs had to be created in order to feature engineer and transform the data into something that a ML model could utilize.
After collecting the preliminary data, we implemented different machine learning models, but using the default latitude and longitude proved detrimental for some of the models to learn. Consequently, we converted the latitude and longitude into spherical coordinates thereafter, which significantly reduced the error. Moreover, after deciding to use either the Neural Network or XGBoost, both models were producing incredible results, which lead us to beleive there was a problem with the data. Upon further inspection, there were clearly instances of duplicate data, so, although, after removing these instances, the model had slightly worse results on the data, it generalised better.
For the frontend, we developed a webscraping algorithm that would enter the CDC website and get the names of the countries and the level of impact the coronavirus has on them. We utilized arcGis and Google's Autocomplete API as well as HTML, CSS, and JavaScript to make an outstanding UI along with Flask.
Accomplishments that we're proud of
With a concept as unpredictable as trying to predict the global spread of a virus, our team was very unsure which ML model to use, as well as the necessary parameters for each model. Ultimately, through a variety of experimentation, trial, and error, we settled on an artificial neural network of which predicted with 92% accuracy. Given the volatile nature of the spread of this disease, our team was very proud of creating a model that achieved this level of accuracy.
What we learned
Always allocate more time than expected on cleaning the data. Assume that things will go wrong, predictions will not go as planned, and programs will not work as expected. The majority of our time was spent trouble-shooting and making small tweaks/modifications, so always budgeting more time than anticipated and leaving a safety buffer was the biggest lesson learned during the course of this project.
What's next for CoronAdvisor
The next steps that we hope to take with this project is to create an even more polished, user-friendly web application, as well as a mobile application that users can take advantage of to stay up to date on the risks of CoronaVirus. Furthermore, we would like to implement SMS and emailing technologies to automatically notify users of when the virus has spread to a location that is within some radius of their current location.









Log in or sign up for Devpost to join the conversation.