-
-
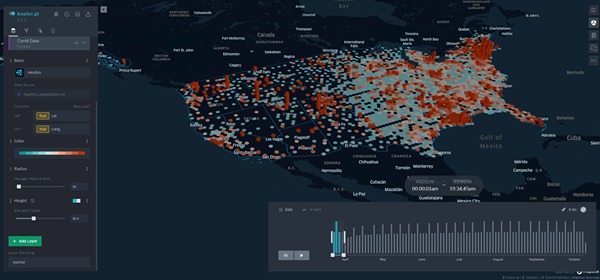
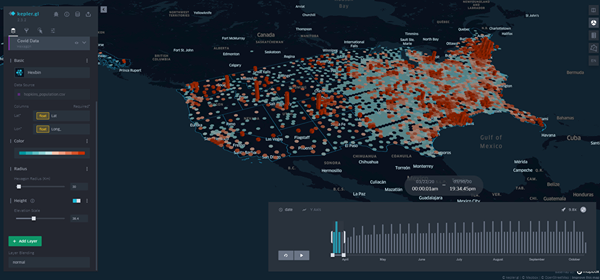
3D mapping of coronavirus outbreaks (cases)
-
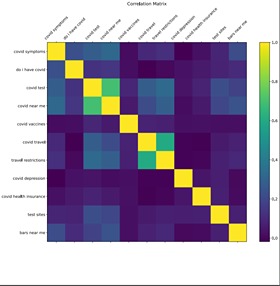
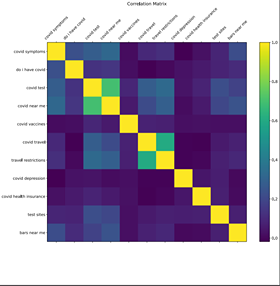
Correlation map between all of the search queries
Inspiration
In the midst of the COVID-19 pandemic, several models attempted to predict the future number of cases and deaths. However, most of them are based on curve fitting methods and on epidemiological models that have proven to be unhelpful with the rapidly changing behavior of the spread of the virus. We planned to use Google search data as an early detector of coronavirus outbreaks in local communities 1-2 weeks into the future. This could help government officials and healthcare providers to prepare hospital supplies for the next wave.
What it does
When a user goes to the platform, he/she is able to visualize (in 3 dimensions) the severity of local cases across the US both in the past and in the future (predicted with an RNN). The height of the hexagons represents the number of cases per 100,000 population whereas the color represents the number of deaths per 100,000 population.
How we built it
First, we fetched coronavirus case data from Johns Hopkins University, which was split into a file per day. After combining that, we used Pytrends to fetch search data from different states of the United States from the past 6 months. Some examples of the queries we used are "COVID symptoms" and "travel restrictions". Then, after cleaning all the data, we built a Recurrent Neural Network to predict new outbreaks for the next 2 weeks. In total, we used 16 features: 11 Google trend queries, confirmed cases and deaths per capita, date, and location (lat-long) to train our neural network. Given the complexity of the model and the size of the data, we could not run it locally, so we used Google Cloud Computing to train the final model. We also used Google Cloud Storage to store our data used the Prediction API to interact with our model. After we had the past + future data, we used the kepler.gl platform to visualize it.
Challenges we ran into
- Cleaning the data was hard as Google Trends API was not consistent. There were many states which had incomplete city-wide data, dates where no data was present, and generally, Pytrends was very complex to use due to timeouts and request restrictions.
- Understanding how to use RNN with Time Series data and making sure that the data was optimal for the machine learning model.
- Getting the model to work with our data as we intended
Accomplishments that we're proud of
- The RNN architecture and its accuracy
- Selection of relevant Google trend queries
- Effective and clear data visualization
What we learned
- How to get Google search trends using Pytrends
- How to use different time series machine learning models
- How to put our model on Google Cloud Computing
- How to use Google Cloud Shell for managing data and training jobs
- How to user Kepler
What's next for CoroNachos
- Including more Google search queries
- Automating data scraping from Johns Hopkins and RNN prediction so the tool is always up to date
- Connecting Kepler to Google Cloud API so that it can fetch predicted trend data live
Built With
- google-cloud
- google-trends
- kepler
- machine-learning
- python
- pytrends
- tensorflow
Log in or sign up for Devpost to join the conversation.