-
-
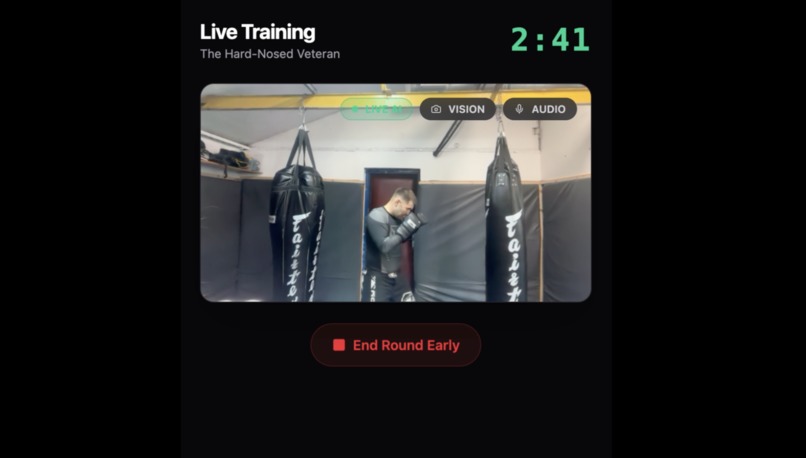
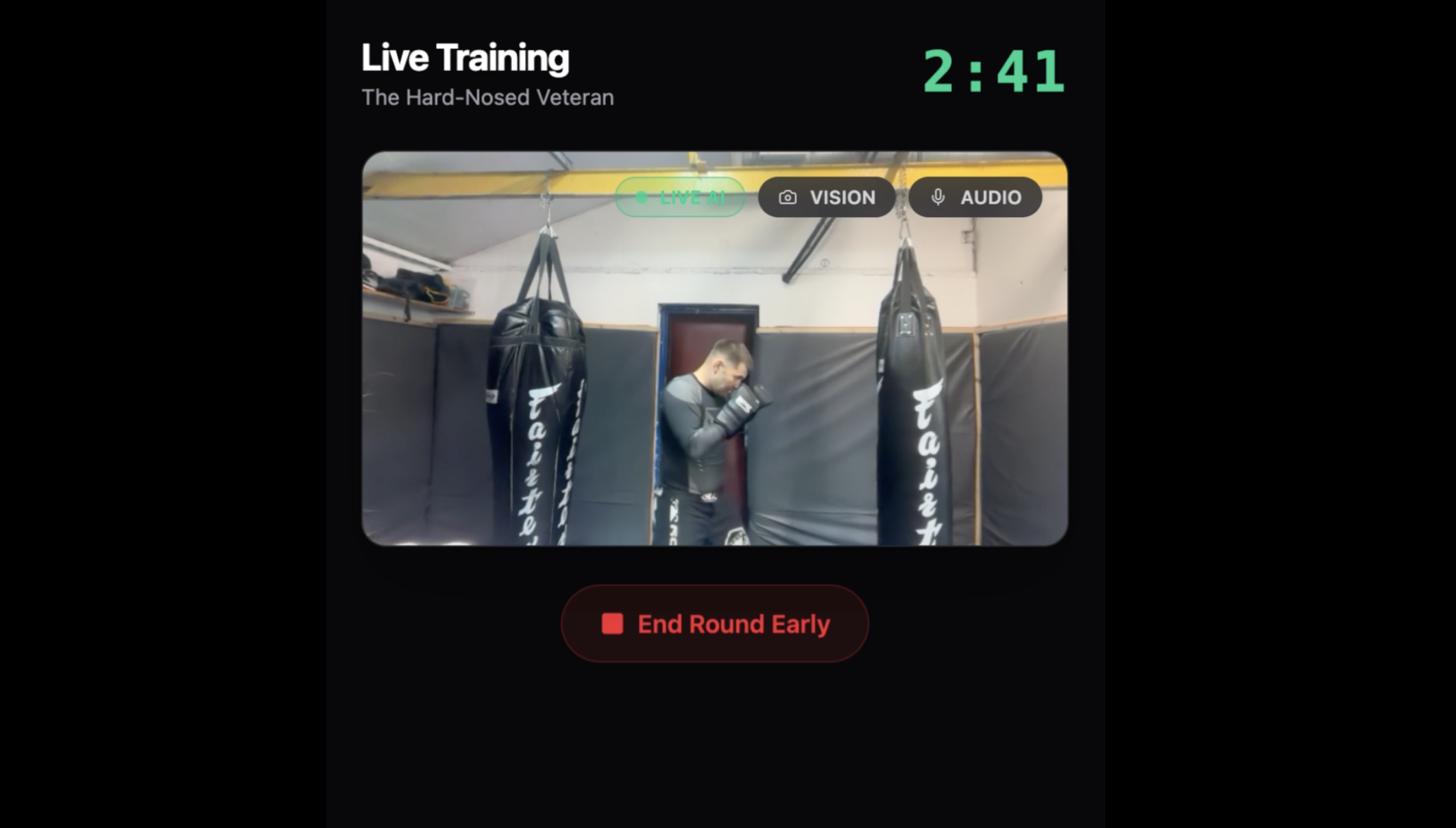
UI screen: live training
-
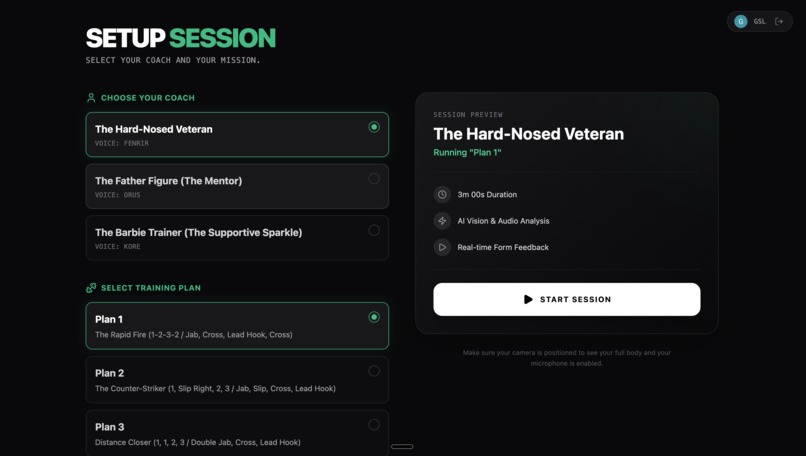
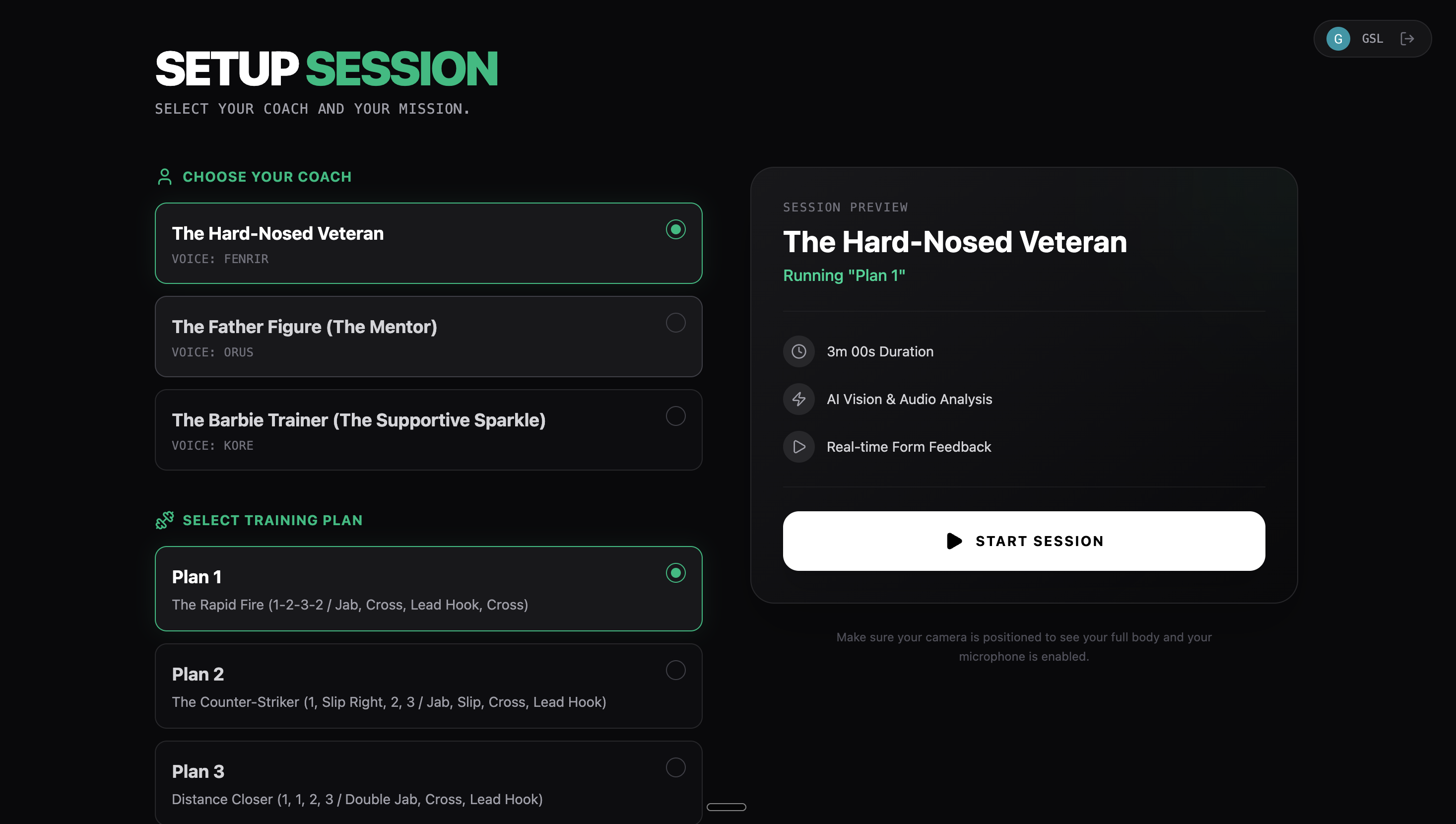
UI screen: round setup
-
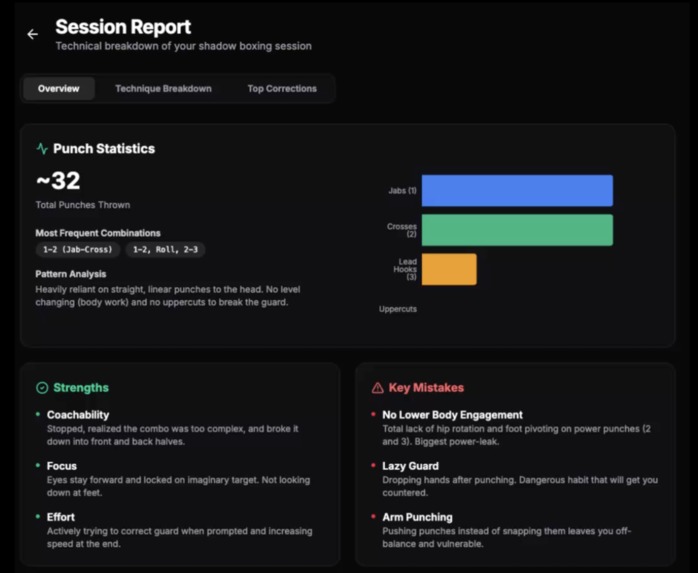
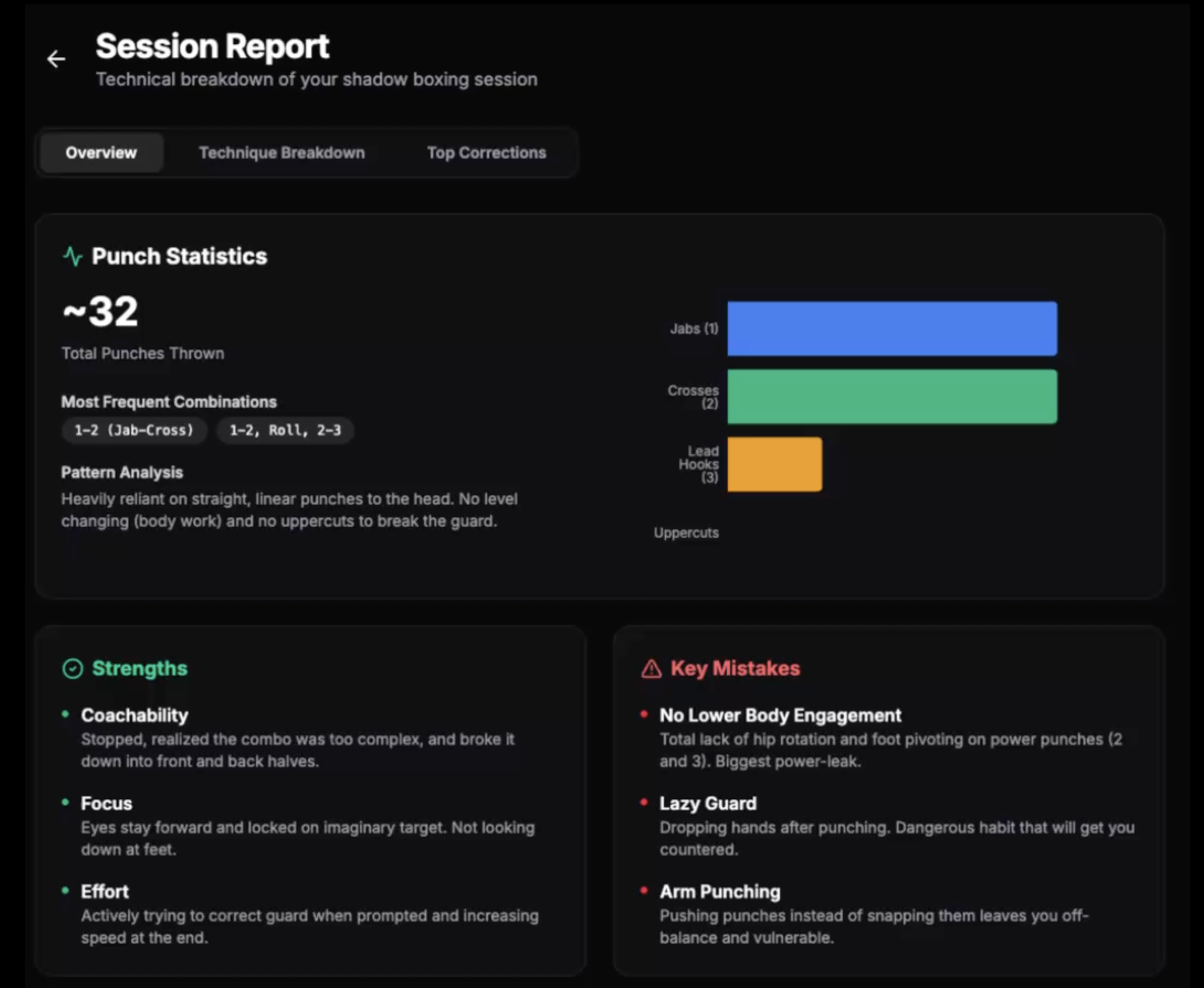
Prototype: Analytics Dashboard
-
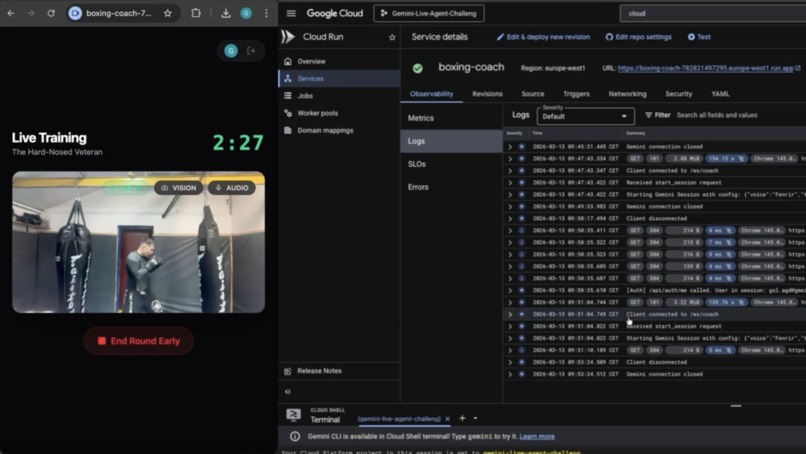
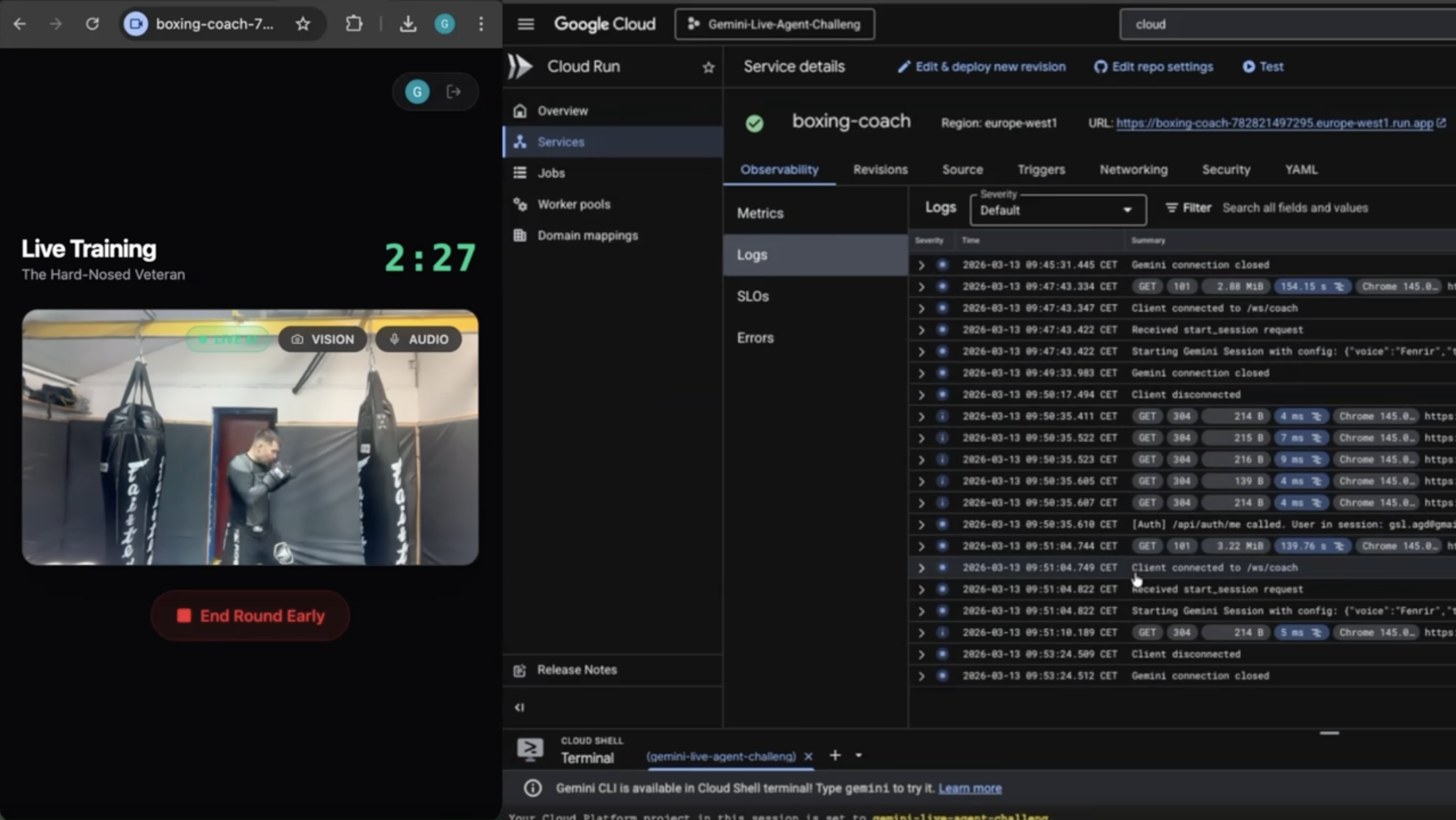
Testing GCP deployed application in gym
-
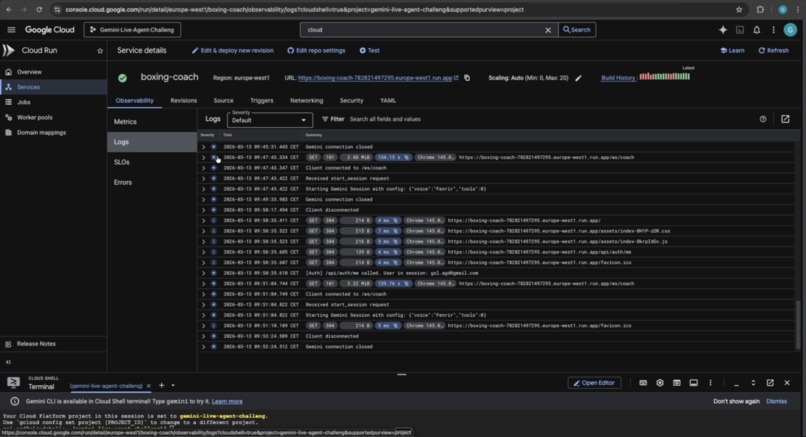
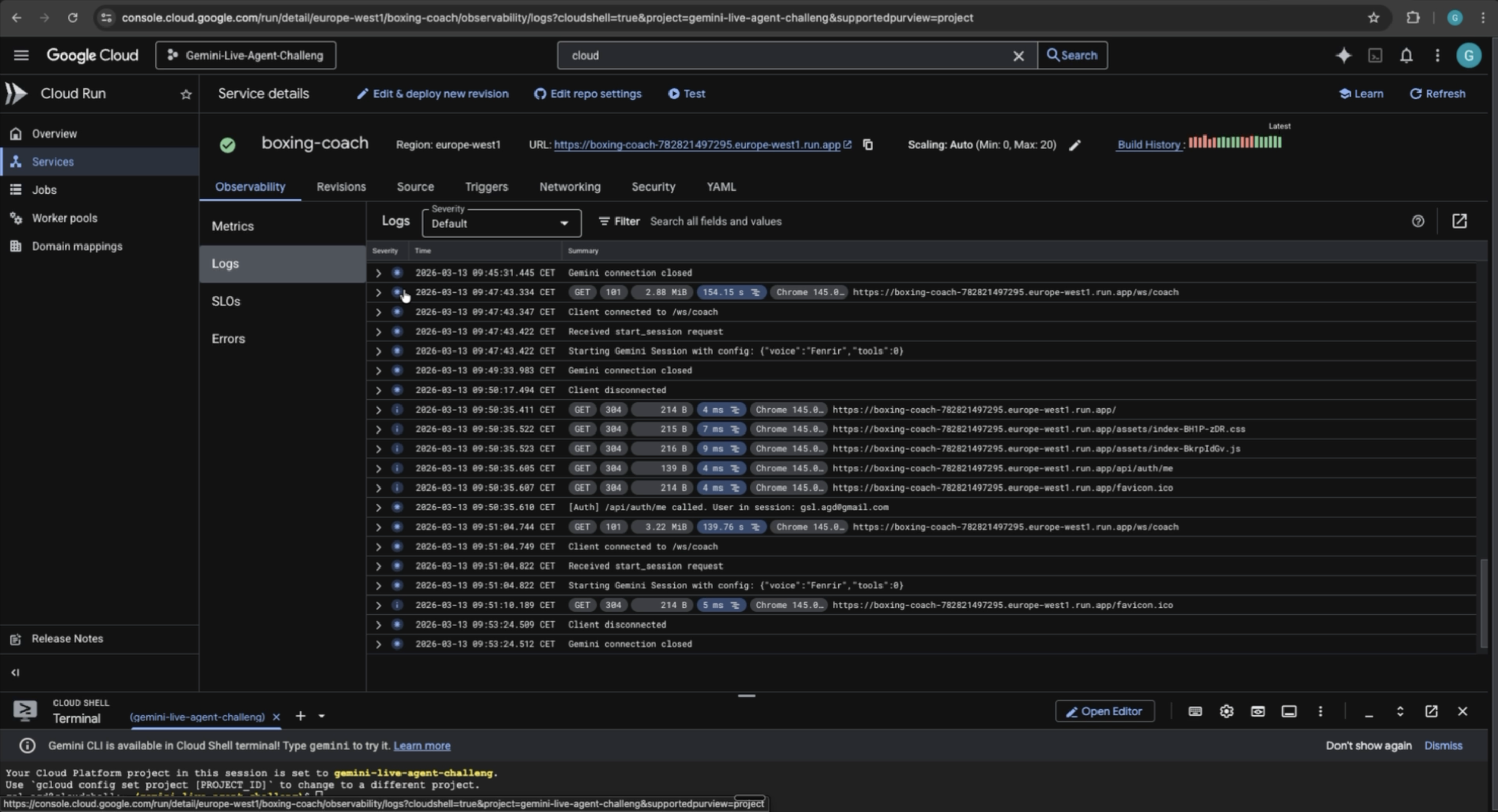
GCP: logs
-
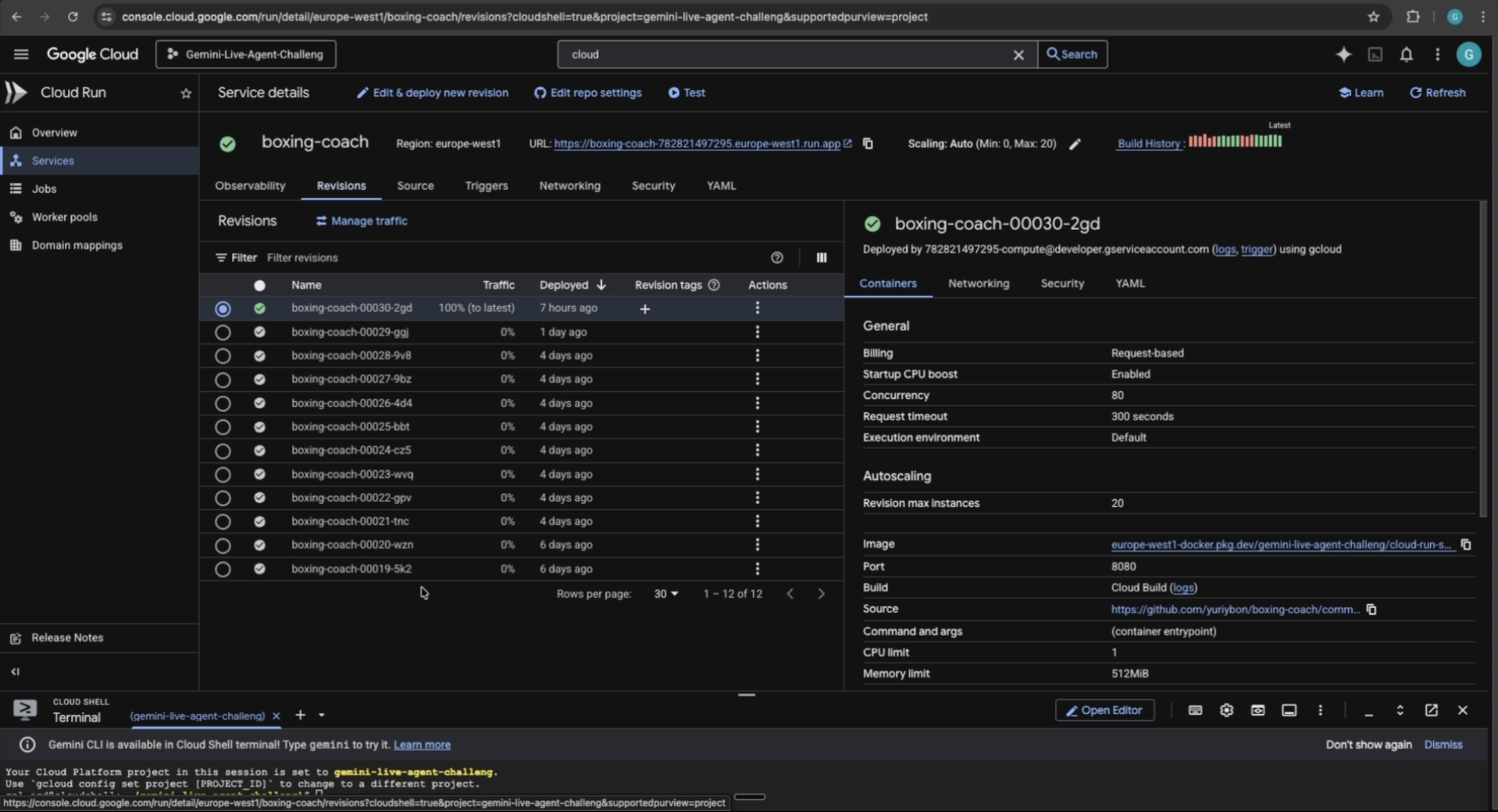
GCP: revision
-
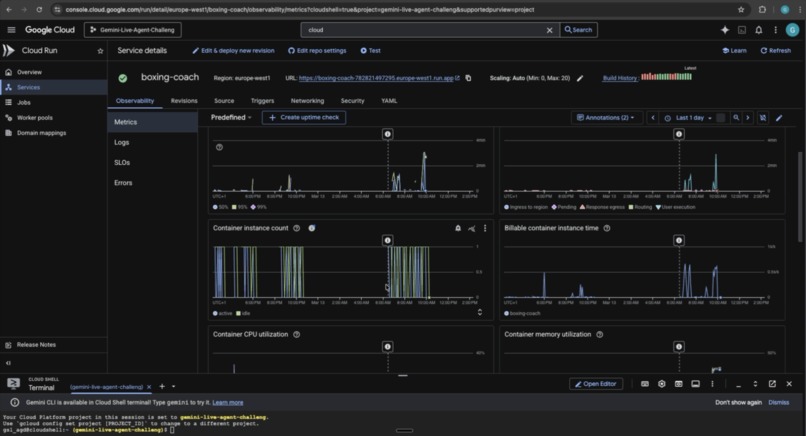
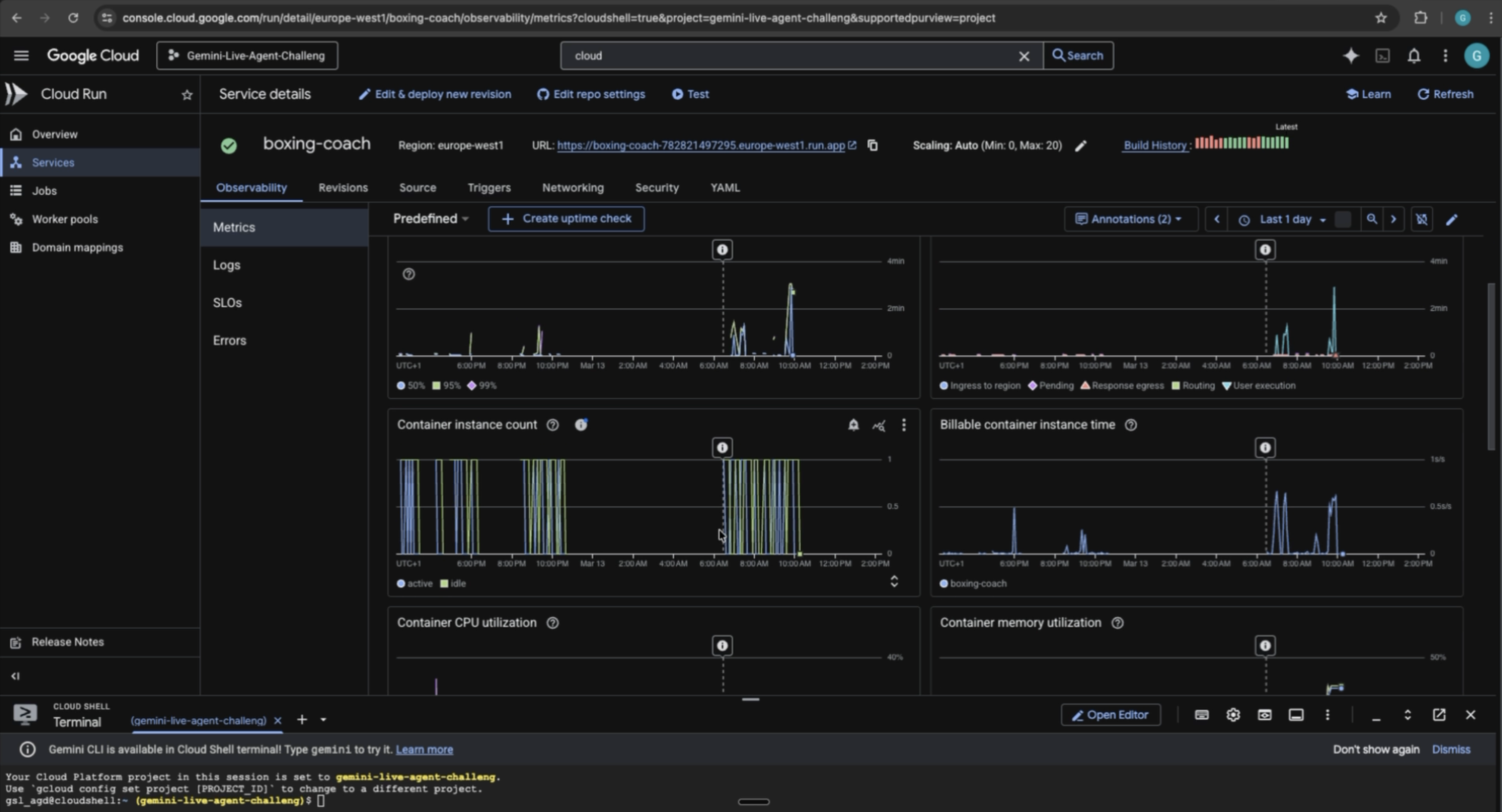
GCP: metrics
-
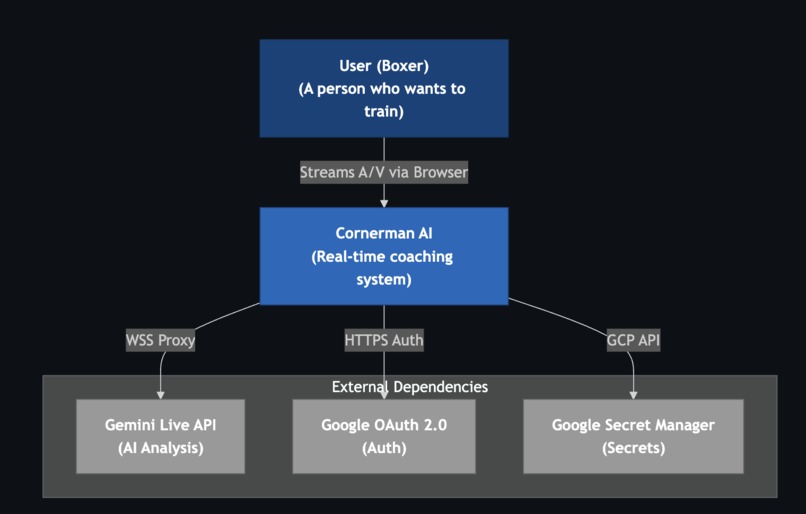
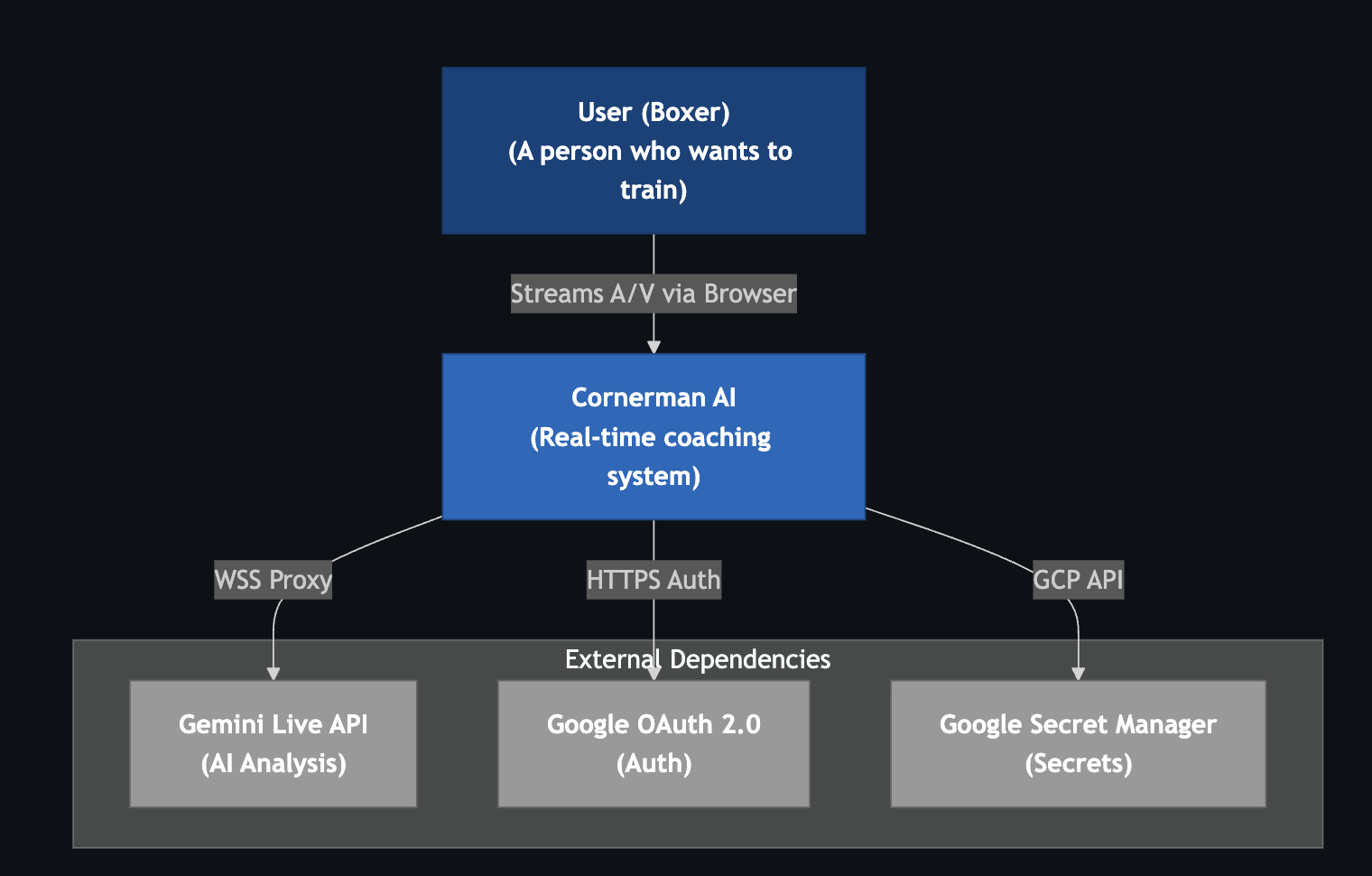
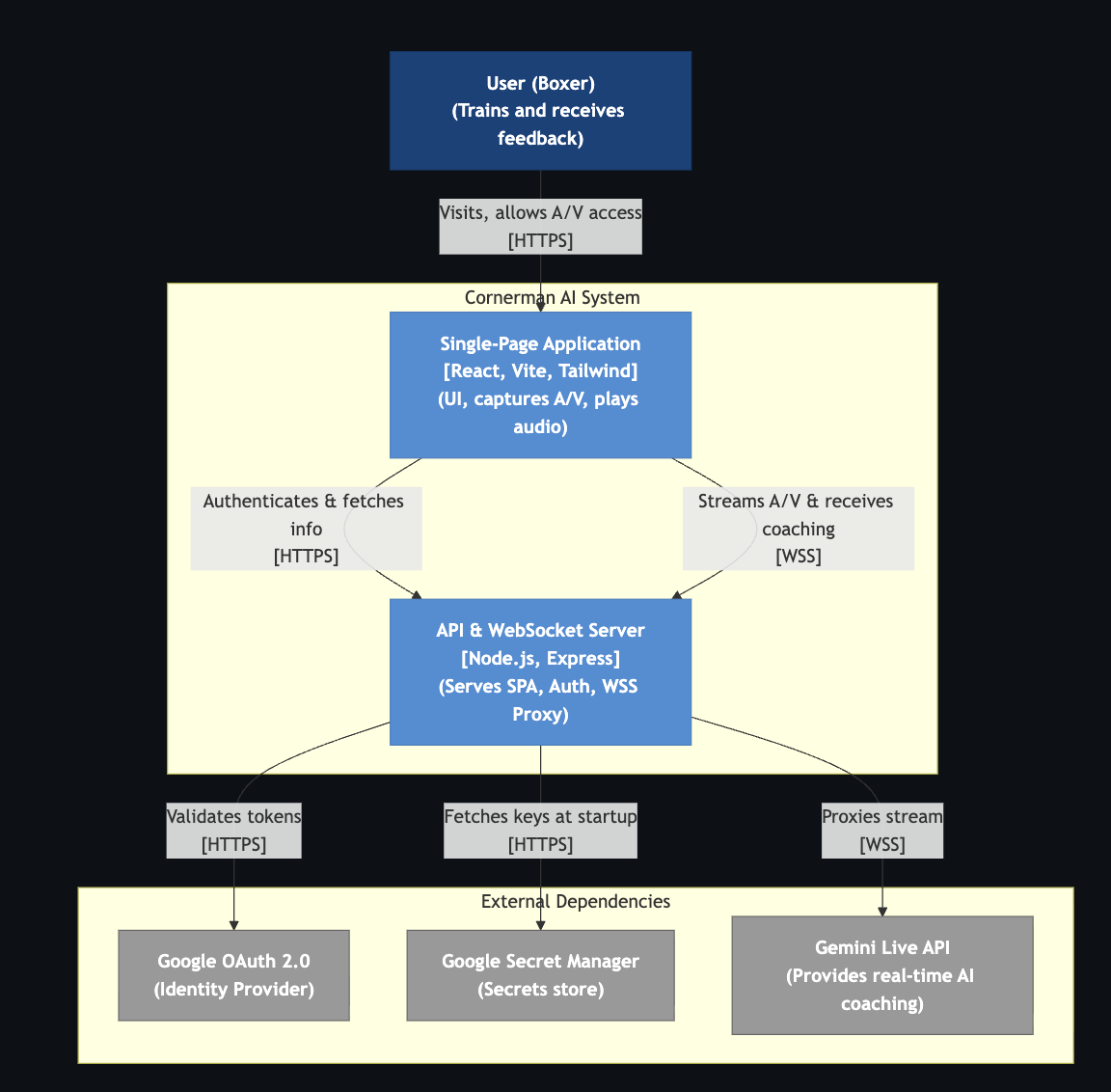
Level 1: System Context Shows the system in its environment, highlighting the user and external systems.
-
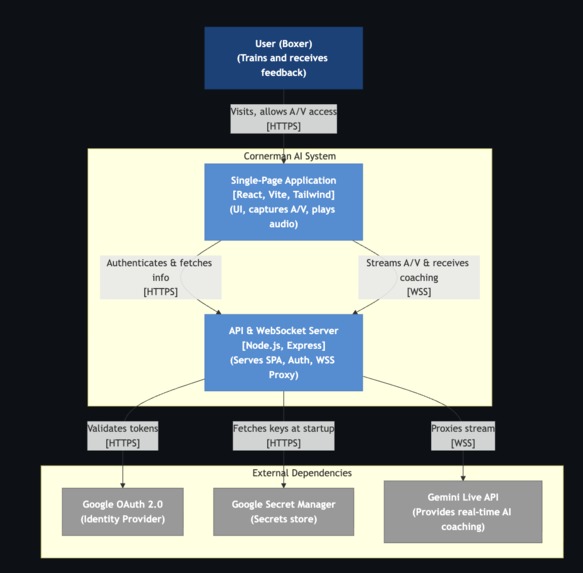
Level 2: Container Zooms into the system to show the high-level technical building blocks (containers) and how they interact.
-
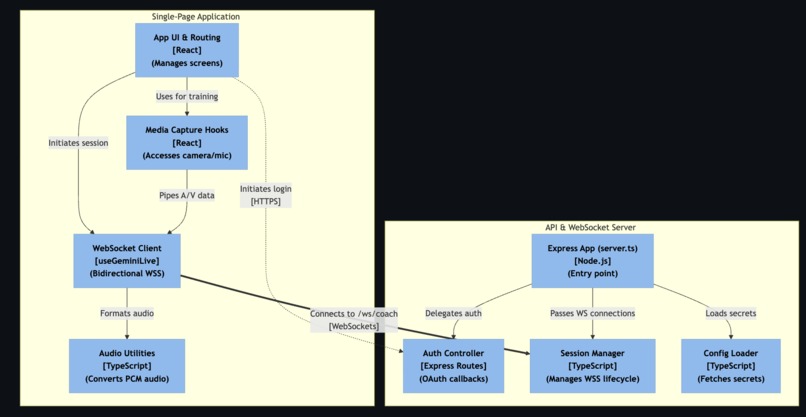
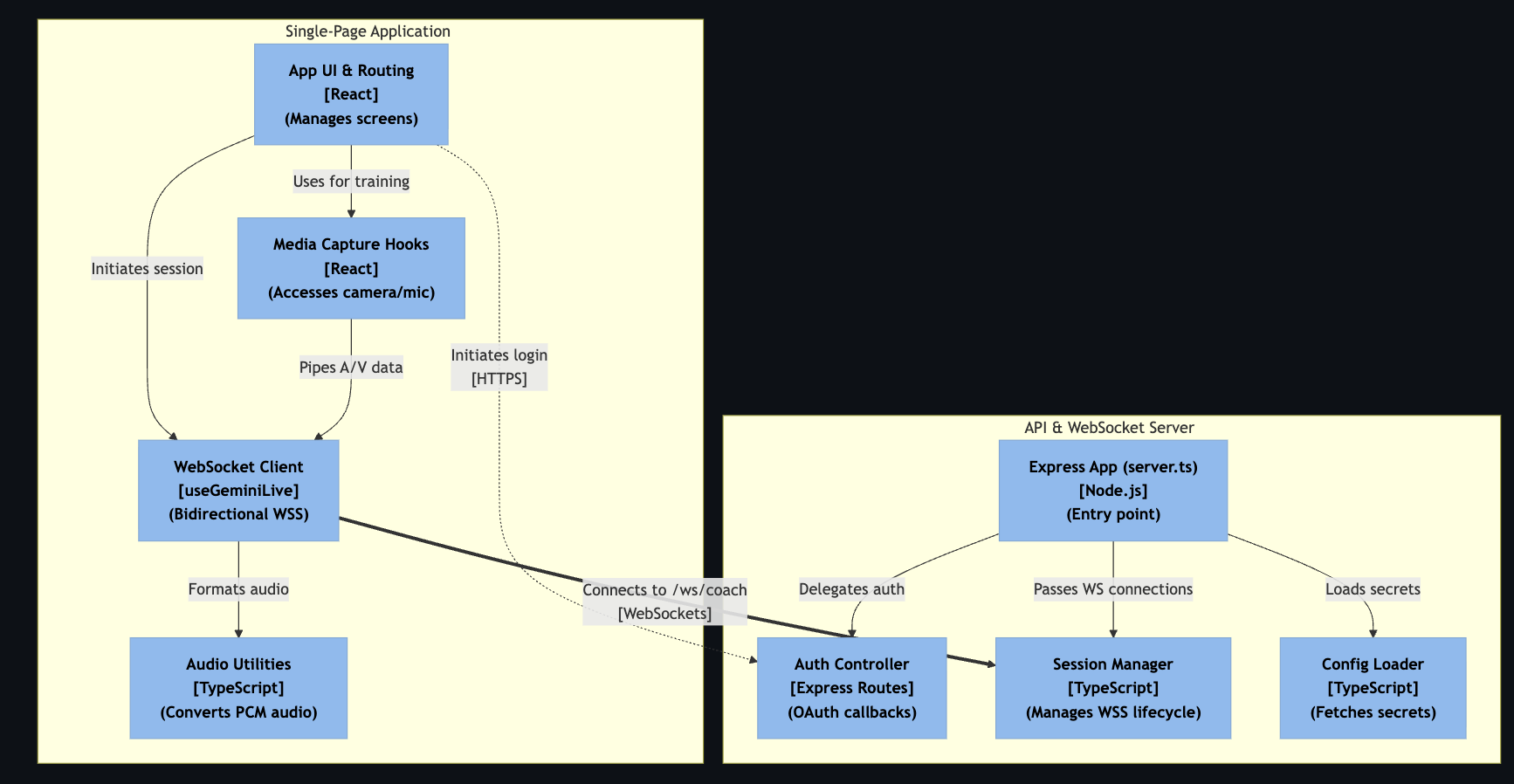
Level 3: Component Zooms into individual containers to show the components inside them.
-
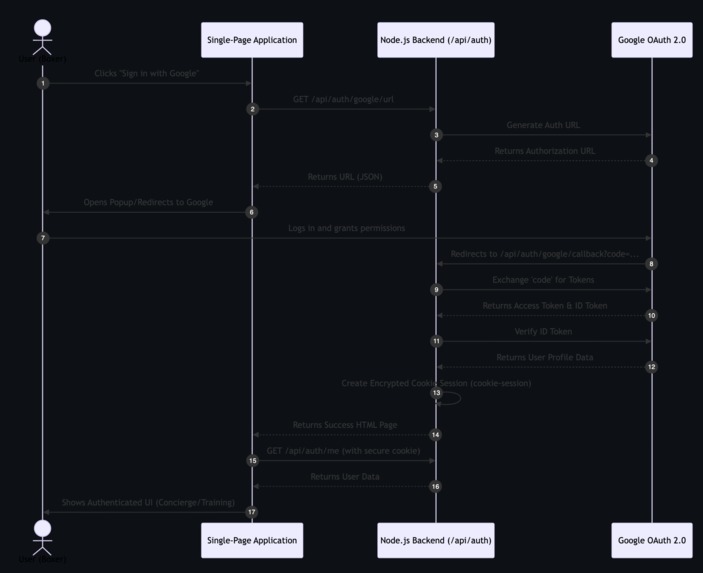
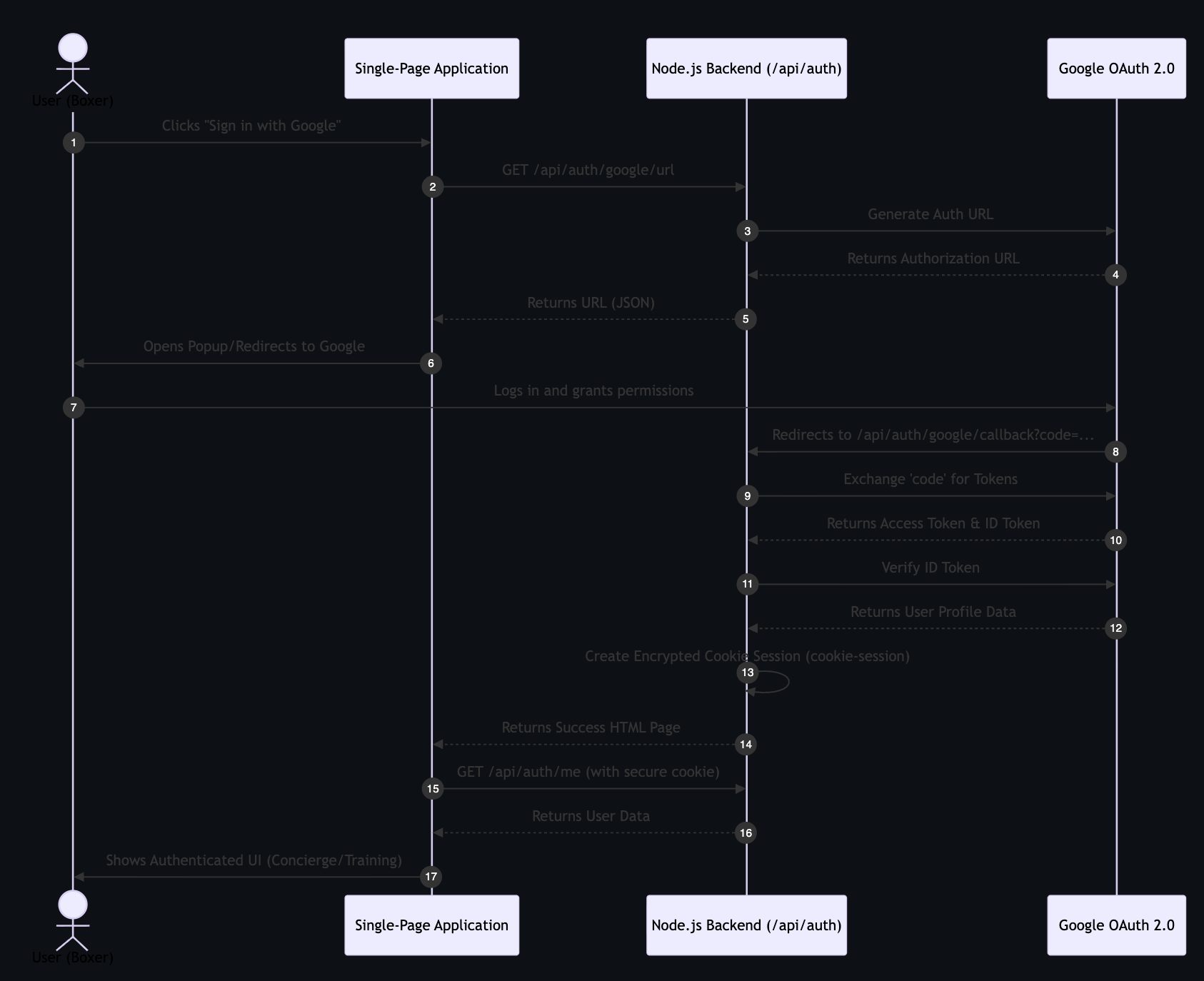
Sequence: Authentication Flow Shows the step-by-step Google OAuth 2.0 login process.
-
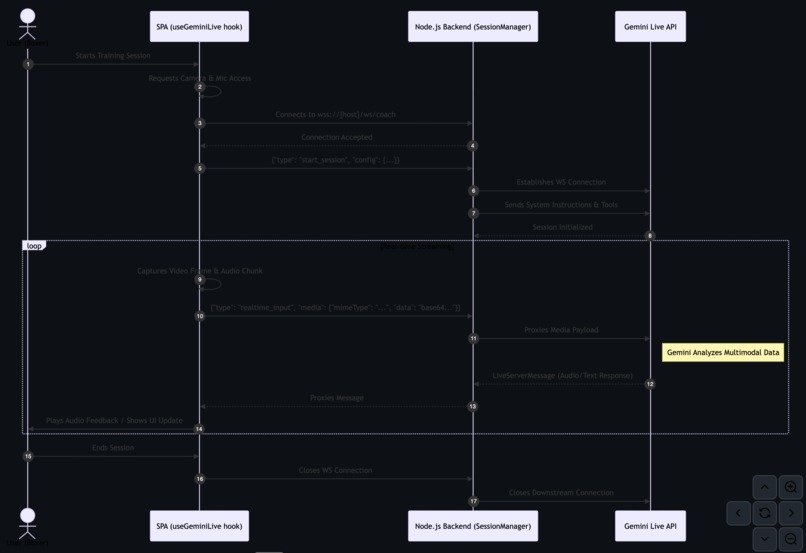
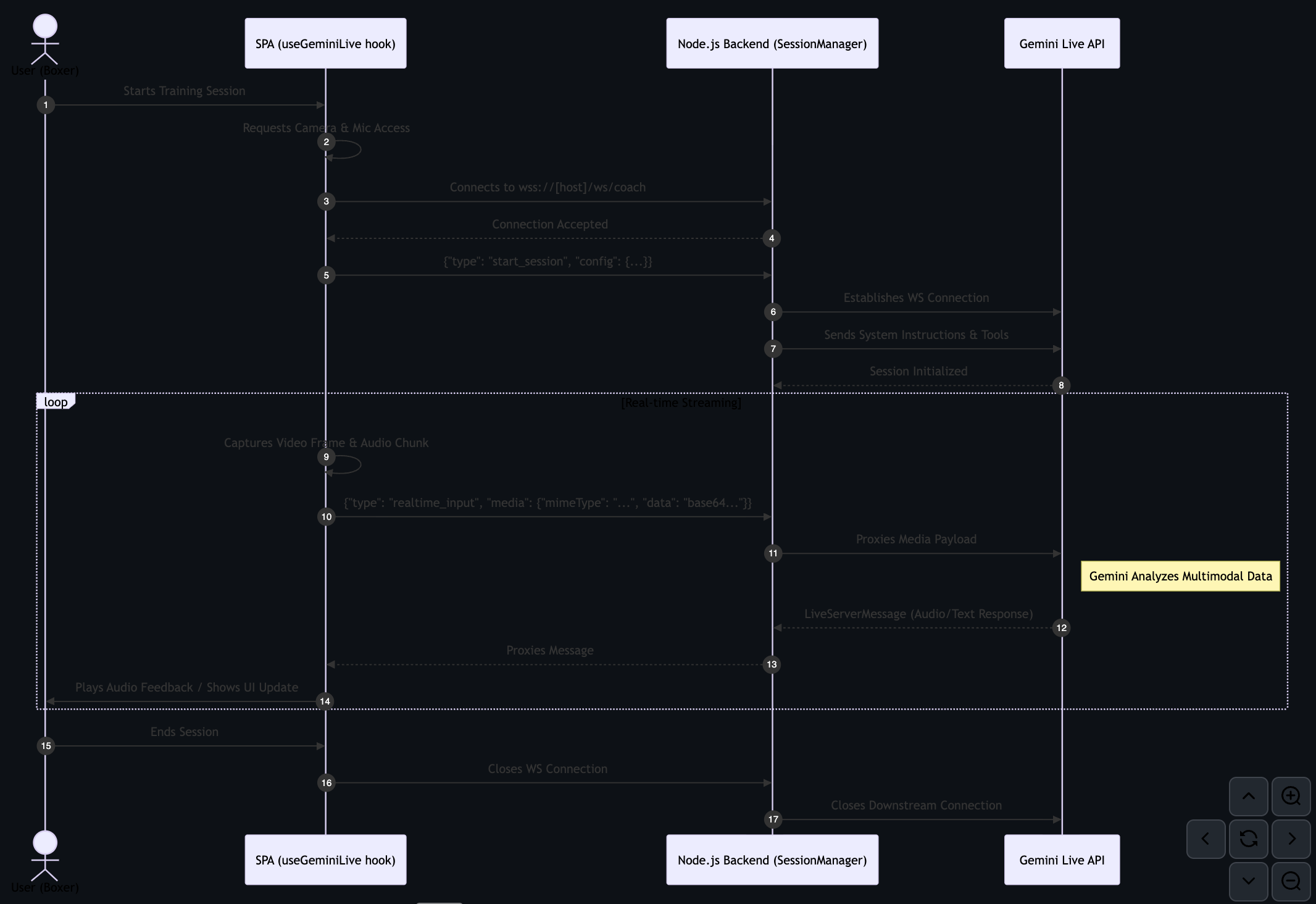
Sequence: Live Training Session Details the real-time bidirectional media streaming flow using WebSockets and the Gemini Live API.
From the Bag to the Cloud: How We Built a Real-Time AI Boxing Coach
The Spark
I've been training in combat sports for years. And there's a feeling every solo fighter knows.
You're in front of the bag. You throw a jab, a cross, a hook. Then you pause - not because you're tired, but because you've run out of ideas. Your brain is fully occupied with performing, and there's nobody to tell you what comes next. No feedback. No correction. No corner.
100 million people worldwide train in combat sports. Almost none have a personal coach. That gap stuck with me.
The Opportunity
As a PM building AI products, I had been following Gemini Live API closely, looking for the right problem to test it on. My colleague Yurii, an expert in generative AI and GCP, had been independently exploring live APIs. When we discussed the idea, the question became obvious: what happens if you put this in a boxing gym? The Gemini Live Agent Challenge gave us the chance to find out.
What We Built
Cornerman AI is a real-time AI boxing coach - hands-free, multimodal, and live. The fighter opens the app, sets up a session and starts a round. From that moment, everything is hands-free:
- The coach speaks - delivering timed combinations and motivation via Gemini's expressive native audio
- The camera watches - frame-level vision detects a dropped guard and fires an instant correction.
- The fighter can interrupt — saying "break it down" mid-round pauses the session, the coach explains, then resumes exactly where it left off
How We Built It
The app runs on Cloud Run. Gemini Live API handles all voice: bidirectional audio streaming with native speech understanding and expressive output. Support for Google Cloud Secret Manager for storing keys.
- Frontend: React 18, Vite, Tailwind CSS, Framer Motion.
- Backend: Node.js, Express, WebSockets (ws).
- AI: Google Gemini Live API (gemini-2.5-flash-native-audio-preview-09-2025).
- Auth: Google OAuth 2.0 + cookie-session.
- Infrastructure: Docker, Google Cloud Run, Google Cloud Build, Terraform.
The Challenges
The gym is not a quiet room. Noise broke our first build. We re-engineered the audio layer around reality, not assumptions.
1 FPS can't track punches. A combo lands in under a second. Vision was pivoted to slow signals only - guard drops, idle stance.
Gemini doesn't recognise punch sounds natively. We attempted to built a custom waveform analyser to detect impacts and fire structured events.
Tone is harder than tech. Coach became real when we stopped scripting outputs and defined how the coach thinks instead.
What We Learned
Gemini Live native audio hears the person, not a transcript Effort, urgency, and pace all survive. That's what makes the coaching feel alive. But it's not a universal tool. Sub-second movement needs dedicated vision models. The real work is always in the orchestration layer: what the model handles, what stays deterministic, and where the two connect.
Gemini Live vision works for static poses, not dynamic movement. 1 FPS cannot track a boxing combo. Vision belongs on slow-changing signals only - guard drops, idle stance, fighter presence. Within those limits, it is reliable and genuinely useful.
Triggers are what make the Live API feel like a real conversation. Passing punch events as structured triggers to Gemini Live was the single biggest improvement to the experience. Pauses landed naturally, callouts came at the right pace. The model steers remarkably well when given the right signals.
The voice is genuinely expressive - and it responds to energy. Gemini Live audio doesn't sound like TTS. It was built for real conversations. You can interrupt mid-sentence, change your mind, or ask a question mid-step - and the agent responds naturally.
Gemini handles post-round video analysis well - within clear limits. Gemini produced reliable basic observations: punch counts, guard drops, stance geometry. The rule we settled on: trust simple counts and static measurements, not complex technique critique. In a real product this becomes a foundation for a trainer marketplace - AI flags the clips, human coaches add expert judgment on top.
YOLO is the better alternative to explore for real-time movement analysis We started exploring YOLO-based vision models for punch and combo detection. They handle sub-second movements at the frame rates sport requires. The production architecture this points to: Gemini Live for expressive voice, a dedicated vision model for real-time physical analysis. Each doing what it is actually built for.
Native audio changes the quality of the interaction. Most voice AI systems run a three-step chain: audio → text → LLM → text → audio. Tone, pace, effort, and emotion are discarded at the first boundary. Gemini Native Audio removes those steps entirely — the model hears the person, not a transcript. A fighter asking "break it down" while breathing hard after a combo carries information a transcript erases. Coach Ray's response reflects it.
The real work is in orchestration. The model is capable. The work is in deciding what it handles, what stays deterministic, and where the two meet. That layer is where the product lives.
Built With
- cloudbuild
- cloudrun
- docker
- express.js
- framermotion
- gemini
- node.js
- oauth
- react
- tailwind
- tailwind-css
- vite
- websockets


Log in or sign up for Devpost to join the conversation.