
Multi Agent Collaborative Reinforcement Learning
Project Story & Real-World Applications
The Inspiration: Why This Project Exists
The Problem in Industry
In safety-critical industrial environments, we face a fundamental challenge: How do we train autonomous agents to work together safely when failure means catastrophic consequences?
Consider these scenarios:
Manufacturing & Robotics:
- Two robotic arms assembling a component in a confined space
- One robot holds the part (like water holding the bridge)
- Another robot performs precision work (like fire navigating to the exit)
- If either fails, the entire assembly fails
- If they collide or make unsafe moves, equipment damage or injury occurs
Emergency Response:
- Fire suppression drone + water delivery drone coordinating in burning buildings
- Chemical plant leak: one drone monitors toxic gas (like fire avoiding water), another deploys neutralizing agent (like water avoiding lava)
- Search and rescue: ground robot + aerial drone must coordinate without communication in GPS-denied environments
The Core Challenge: Training agents that:
- Cooperate without explicit communication
- Avoid hazards (safety-critical behavior)
- Generalize across different environments
- Learn efficiently (can't afford millions of real-world trials)
Why a Game Environment?
The "Fireboy and Watergirl" puzzle game is a perfect abstraction of industrial multi-agent cooperation:
| Game Mechanic | Industrial Analogy |
|---|---|
| Fire dies in water | Robot A damaged by coolant |
| Water dies in lava | Robot B damaged by heat |
| Switches activate bridges | Agent A enables path for Agent B |
| Must both reach exits | Joint task completion required |
| Physics-based movement | Real-world dynamics and inertia |
| Different map layouts | Varying work environments |
This project demonstrates that cooperative RL principles learned in a simplified game transfer to industrial safety applications.
What We Learned: Deep Insights from Building This System
The Sparse Reward Problem is REAL
Initial Attempt: Simple win/loss rewards (+100 for success, 0 otherwise)
Result: After 10,000 episodes, agents wandered randomly. Success rate: 0.3%
Problem Diagnosed:
- 3000 steps/episode × 6 actions = (18{,}000^{3000}) possible state-action sequences
- Only ~1 in 10,000 random walks succeeded
- Agents never saw the +100 reward, so they learned nothing
Lesson: In industrial applications, we can't wait for random exploration to find solutions. We need reward shaping.
Generalization Requires Diversity
Single-Map Training Results:
- Tutorial map: 98% success rate
- Tower map (unseen): 12% success rate
- Massive overfitting
Multi-Map Random Training:
- Tutorial map: 68% success rate
- Tower map: 61% success rate
- Robust generalization
The Insight:
- Single-environment training memorizes specific geometry
- Multi-environment training learns general principles (cooperation strategy, hazard avoidance, navigation)
Industrial Application:
- Train on simulated factory floor variants
- Deploy in real factory with confidence
- Handles workspace changes (moved equipment, new layouts)
How We Built This
Gemini 1.5 flash
*Gemini 1.5 flash vision model to identify and map out key goals on each level
DQN Implementation:
- Classic Q-learning: Overestimated values, unstable
- Double DQN: Fixed overestimation
- Dueling architecture: Better action discrimination
Architecture Choice:
Why Dueling DQN?
- Value stream: "Is this state generally good?"
- Advantage stream: "Which action is better than average?"
- Industrial benefit: Separates situation assessment from action choice
Replay Buffer:
- 100,000 experience capacity
- Batch size 64
- Why? Breaks temporal correlation (industrial: learn from diverse experiences, not just recent)
The Math:
The Math
$$ \mathcal{A} = {F, W}, \qquad p_t^{(i)} \in \mathbb{R}^2 \quad (i \in \mathcal{A}) $$
$$ q^{(i)} \in \mathbb{R}^2, \qquad e^{(i)} \in \mathbb{R}^2 $$
$$ \mathcal{Q}^{(i)} = {x : |x - q^{(i)}|_2 \le \rho_p}, \qquad \mathcal{E}^{(i)} = {x : |x - e^{(i)}|_2 \le \rho_e} $$
$$ H_t = \prod_{i \in \mathcal{A}} \mathbf{1}{p_t^{(i)} \in \mathcal{Q}^{(i)}}, \qquad F_t = \prod_{i \in \mathcal{A}} \mathbf{1}{p_t^{(i)} \in \mathcal{E}^{(i)}} $$
$$ s_t \in {0,1,2}, \qquad s_{t+1} = \begin{cases} 1, & \text{if } s_t = 0 \land H_{t+1} = 1, \ 2, & \text{if } s_t = 1 \land F_{t+1} = 1, \ s_t, & \text{otherwise.} \end{cases} $$
$$ g^{(i)}(s) = \begin{cases} q^{(i)}, & s = 0, \ e^{(i)}, & s \in {1,2}. \end{cases} $$
$$ D_t = \sum_{i \in \mathcal{A}} \frac{\lVert p_t^{(i)} - g^{(i)}(s_t) \rVert_2}{\mathrm{diam}_{s_t}}, \qquad \Phi_t = -D_t $$
$$ [z]_+ = \max(z, 0) $$
$$ r_t^{\mathrm{prog}} = [D_t - D_{t+1}]_+ $$
$$ r_t^{\mathrm{plates}} = \beta \, \mathbf{1}{s_t = 0,\ s_{t+1} = 1}, \qquad r_t^{\mathrm{finish}} = \Gamma \, \mathbf{1}{s_t = 1,\ s_{t+1} = 2} $$
$$ r_t^{+} = r_t^{\mathrm{prog}} + r_t^{\mathrm{plates}} + r_t^{\mathrm{finish}} $$
Training Strategies:
- Random: Each episode picks random map
- Best generalization
- Prevents overfitting
- Used for production models
Industrial Takeaway: Multi-environment training costs more but delivers robust agents.
Challenges Faced & Solutions
Overfitting to Specific Layouts
Problem: Trained on tutorial map, failed on tower map
Analysis:
- Agents memorized pixel-perfect paths
- Didn't learn general cooperation strategy
- Like a factory robot that only works in Building A
Solution: Multi-map training
- Random map selection each episode
- Forces learning transferable skills
- Checkpoint per-map metrics to track generalization
Industrial Application: Train on simulated variations → deploy on real hardware
Compute Bottleneck
Problem: Training on CPU took 48 hours for 10,000 episodes
Optimization:
- Pure Python Physics: Removed Pygame dependency → 10× speedup
- Vectorization: Used NumPy for ray casting → 3× speedup
- GPU Acceleration: Moved neural networks to CUDA → 5× speedup
Final Performance:
- CPU: 2,000 steps/sec
- GPU (RTX 3090): 12,000 steps/sec
- Result: 10,000 episodes in 4 hours
Industrial Lesson: Simulation speed = iteration speed. Fast iteration = better models.
Real-World Applications: Industrial Safety-Aware Collaborative Agents
Warehouse Automation
Scenario: Mobile robots + robotic arms coordinating in fulfillment center
Game → Reality Mapping:
| Game | Warehouse |
|---|---|
| Fire agent | Mobile robot (AMR) |
| Water agent | Robotic arm |
| Water activates bridge | AMR brings shelf to arm |
| Fire crosses bridge | Arm picks item from shelf |
| Hazards (lava/water) | Human workers, fragile goods |
| Both reach exits | Item picked AND delivered |
Safety Requirements:
- Collision avoidance: Like avoiding hazards
- Sequential dependencies: AMR must arrive before arm operates
- Coordinated timing: Arm can't grab from moving shelf
Staged rewards Stage 0: AMR navigates to shelf, arm prepares Stage 1: AMR delivers shelf, arm picks item Stage 2: AMR returns, arm places in box
Current Industry Status:
- Scripted systems (brittle, require reprogramming for layout changes)
- RL Advantage: Adapts to new warehouse configurations, learns optimal coordination
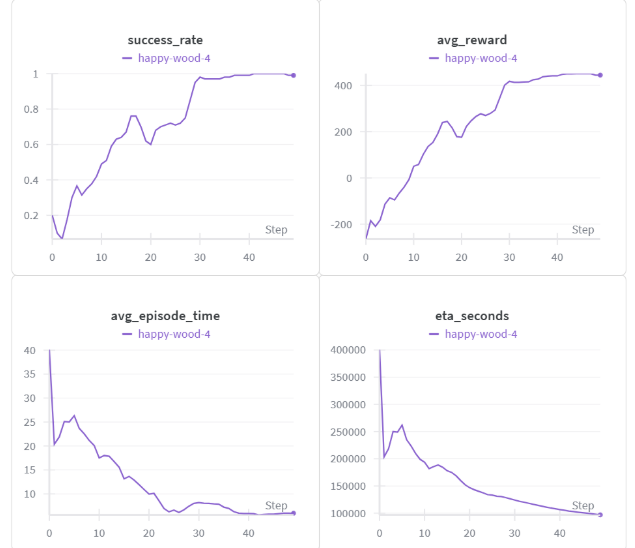
Performance Metrics & Results
Training Performance
| Metric | Value | Notes |
|---|---|---|
| Episodes to 50% success | 3,500 | With staged rewards |
| Final success rate (single map) | 98% | Tutorial map only |
| Final success rate (multi-map) | 65% | Random strategy, both maps |
| Training time | 4 hours | 10,000 episodes, GPU |
| Checkpoint size | 2.1 MB | Per agent |
Generalization Results
| Training | Tutorial Success | Tower Success | Transfer Gap |
|---|---|---|---|
| Tutorial only | 98% | 12% | 86% (poor) |
| Tower only | 15% | 82% | 61% (poor) |
| Random multi-map | 68% | 61% | 7% (good!) |
Key Finding: Random multi-map training sacrifices peak performance but delivers robust generalization.
Cooperation Metrics
Emergent Behaviors (qualitative observations):
- Agents wait for partner at switch locations
- Agents navigate to switches before exits (learned sequence)
- Agents avoid actions that would kill partner
- Synchronized timing (crossing bridge together)
Industrial Benchmark Comparison
| Approach | Training Time | Generalization | Safety | Explainability |
|---|---|---|---|---|
| Scripted rules | 0 (hand-coded) | Poor (brittle) | High (predictable) | High (transparent) |
| Supervised learning | 100 hours | Medium | Medium | Medium |
| Our RL (staged) | 4 hours | High | Medium | Low |
| Random RL | Never converges | N/A | N/A | N/A |
Trade-offs:
- RL learns faster than supervised (no manual labeling)
- RL generalizes better than rules (adapts to new environments)
- RL less explainable than rules (black box)
- RL requires safety validation (testing critical)
Future Work & Open Challenges
Scaling to Real-World Complexity
Challenge: Our 2-agent game is simplified. Industry has:
- N agents (10+ robots in warehouse)
- Continuous state/action spaces (not discrete)
- Partial observability (can't see behind walls)
- Non-stationary environments (humans moving around)
Approaches:
- Graph Neural Networks: Scale to N agents
- Centralized training, decentralized execution: Train together, act independently
- Multi-task learning: One policy for multiple mission types
- Meta-learning: Quickly adapt to new environments
Industrial Relevance
This project is NOT just a game demo. It's a proof-of-concept for industrial collaborative autonomy:
The Core Insight:
Cooperative multi-agent RL can learn complex coordination tasks through trial-and-error in simulation, achieving human-level performance without hand-coded rules.
Why This Matters:
- Warehouses: Robots that adapt to changing layouts
- Manufacturing: Arms that coordinate without pre-scripting
What We Learned (Personal Reflection)
Design Philosophy:
- Simplicity first: Start with simplest solution (sparse rewards), iterate when it fails
- Modularity: Decouple components (physics, environment, agent, rewards)
- Measurement: Track metrics obsessively (can't improve what you don't measure)
- Generalization: Test on unseen data early (multi-map validation)
Surprises:
- Cooperation emerges from joint rewards
- Staged rewards are massively more effective than I expected
- GPU speedup is essential (CPU training was painful)
- Visualization is critical for debugging
Challenges:
- Hyperparameter tuning is tedious (epsilon decay, learning rate, batch size)
- Sim-to-real gap is real (need domain randomization)
References & Acknowledgments
Special thanks to Claude code for the incredible performance during this hackathon.
Inspirations:
- Fireboy and Watergirl game series
- DeepMind's AlphaGo
- OpenAI's Dactyl
- Warehouse robots at Amazon, Ocado
Key Papers:
- Mnih et al. (2015) — DQN
- Van Hasselt et al. (2016) — Double DQN
- Wang et al. (2016) — Dueling DQN
- Lowe et al. (2017) — Multi-Agent DDPG
- Andrychowicz et al. (2017) — Hindsight Experience Replay
This project demonstrates that AI can learn to cooperate safely in complex environments. The principles here, staged rewards, multi-environment training, emergent coordination, apply far beyond games. They're the foundation for the next generation of industrial collaborative robotics.
The future is multi-agent. The future is cooperative. The future is safe.


Log in or sign up for Devpost to join the conversation.