Inspiration
Today, over 6 billion people use the internet worldwide, and studies suggest that roughly 60-70 % of internet users access it through laptops and computers. As our dependence on computing devices grows, so do challenges such as resource bottlenecks, performance degradation, thermal stress, and inefficient system utilization.
Yet most monitoring tools remain passive. They collect metrics, display dashboards, and generate alerts, but they still rely on humans to analyze the data and make optimization decisions.
We wanted to explore a future where systems don't just report problems—they learn from them and optimize themselves.
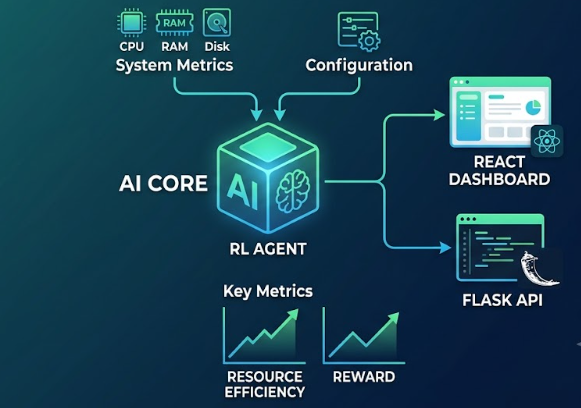
That vision led to CorePilot AI, an autonomous Reinforcement Learning platform that continuously monitors CPU, memory, and storage behavior, learns optimization policies from live system data, and adapts in real time. By combining intelligent decision-making, real-time monitoring, automated training, and self-healing process management, CorePilot AI transforms traditional system monitoring into an active, self-optimizing ecosystem.
What it does
CorePilot AI transforms passive monitoring into active optimization.
The system:
- Collects system metrics every few seconds
- Tracks CPU, RAM, and Disk utilization
- Generates training datasets automatically
- Trains a Reinforcement Learning model
- Makes real-time optimization decisions
- Adjusts system parameters dynamically
- Visualizes live metrics, rewards, and actions through a dashboard
Key Statistics
- Monitors 3 critical system resources continuously
- Processes hundreds of system observations per hour
- Maintains a complete real-time optimization loop
- Provides sub-second dashboard updates
- Supports 24/7 autonomous monitoring
- End-to-end pipeline consisting of 6 integrated modules
- Built using Python, PyTorch, Flask, React, and Chart.js
How we built it
| Module | Description |
|---|---|
| Data Collector | Collects real-time CPU, RAM, and Disk metrics |
| Data Labeler | Generates labeled training data automatically |
| RL Trainer | Trains the Reinforcement Learning model |
| Live RL Agent | Makes real-time optimization decisions |
| Flask API Layer | Serves data and model predictions through APIs |
| React Dashboard | Visualizes live metrics, rewards, and actions |
| Layer | Technologies |
|---|---|
| Backend | Python, Flask, PyTorch, psutil |
| Frontend | React.js, Axios, Chart.js, Tailwind CSS |
Reinforcement Learning Setup
State Space:
- CPU Usage
- RAM Usage
- Gamma
Actions:
- Decrease Gamma
- Maintain Gamma
- Increase Gamma
Reward Function:
Reward = 100 − (0.6 × CPU + 0.3 × RAM + 0.1 × Disk)
The agent continuously learns which action maximizes long-term system efficiency.
| Step | Component | Purpose |
|---|---|---|
| 1 | Data Collector | Capture live system metrics |
| 2 | Data Labeler | Prepare training dataset |
| 3 | RL Trainer | Train optimization policy |
| 4 | Live RL Agent | Predict optimal action |
| 5 | Flask API | Expose model outputs |
| 6 | React Dashboard | Display real-time analytics |
Challenges we ran into
- Designing meaningful rewards from raw system metrics
- Creating reliable labels without manual annotation
- Preventing unstable RL behavior during training
- Synchronizing real-time data collection with dashboard updates
- Managing multiple autonomous processes simultaneously
- Building a complete RL pipeline that could operate continuously
Accomplishments that we're proud of
- Built a complete end-to-end Reinforcement Learning system from scratch
- Successfully connected monitoring, training, inference, APIs, and visualization into one platform
- Developed an autonomous optimization loop capable of making live decisions
- Created a scalable architecture for future hardware-level optimization
- Demonstrated how Reinforcement Learning can move beyond simulations into real-world system management
Project Metrics
- 6 major software modules
- 4 integrated technology layers
- Real-time analytics dashboard
- Autonomous decision-making engine
- Continuous data collection and training pipeline
What we learned
Through CorePilot AI, we gained hands-on experience with:
- Reinforcement Learning fundamentals
- Reward engineering
- System observability
- Real-time data pipelines
- API development
- Frontend visualization
- Autonomous systems design
Most importantly, we learned that the hardest part of Reinforcement Learning is not building the model—it is designing the environment and reward structure that allows the model to learn meaningful behavior.
What's next for CorePilot AI
Our long-term vision is to evolve CorePilot AI into a fully autonomous infrastructure optimization platform.
Future enhancements include:
- CPU frequency scaling
- Thermal management
- Fan-speed control
Vision
CorePilot AI aims to transform computing systems from being monitored by humans to becoming systems that can understand, adapt, and optimize themselves autonomously.

Log in or sign up for Devpost to join the conversation.