-
-

Logo
-
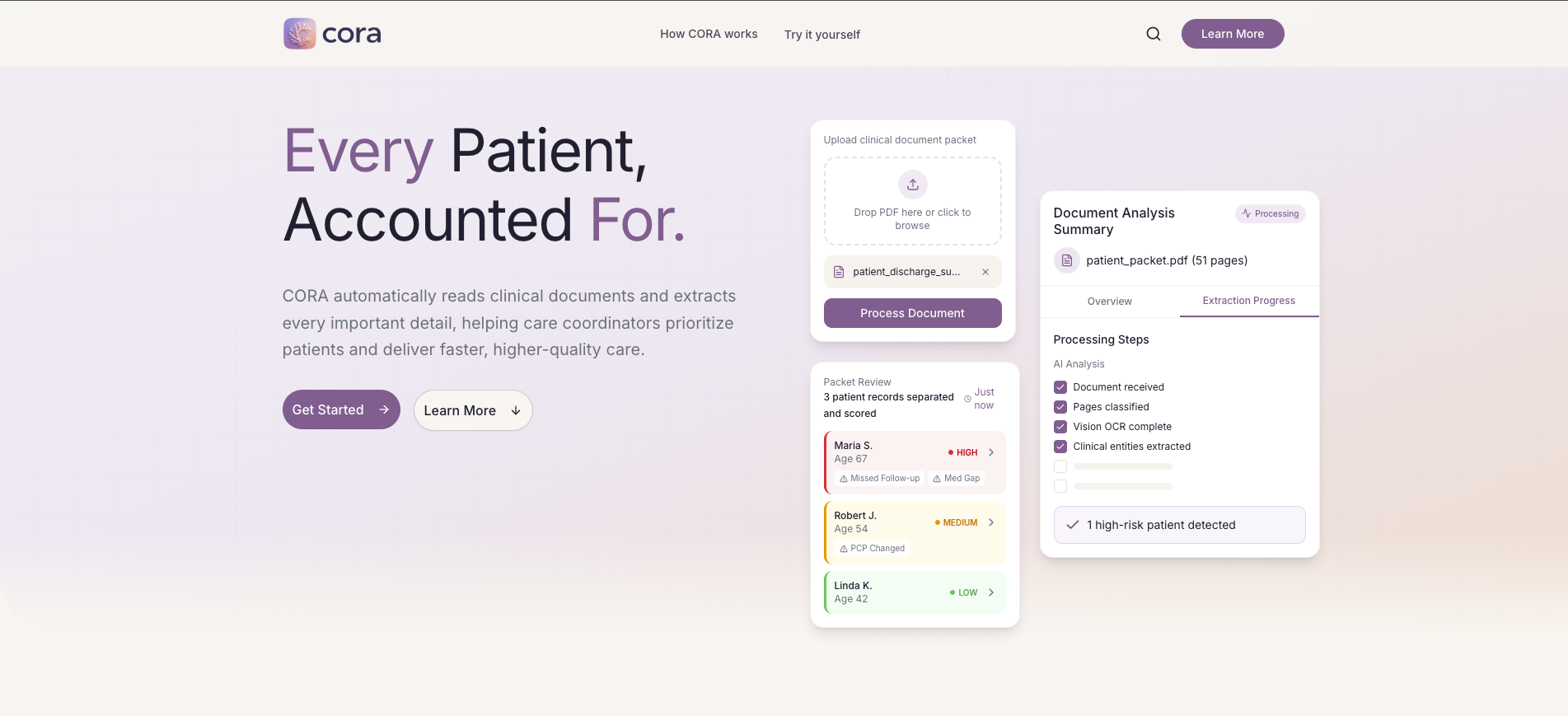
CORA Landing Page
-
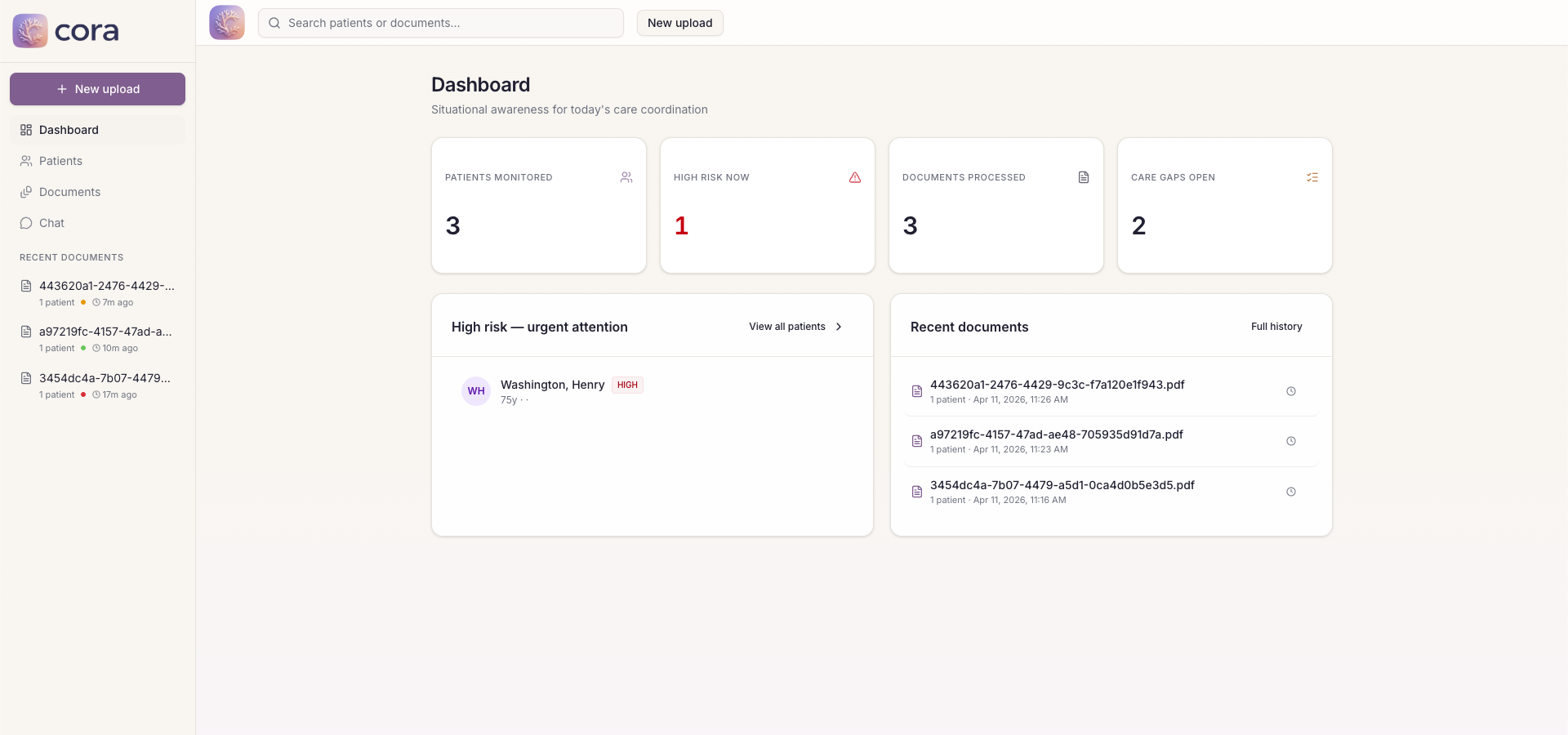
CORA Dashboard View
-
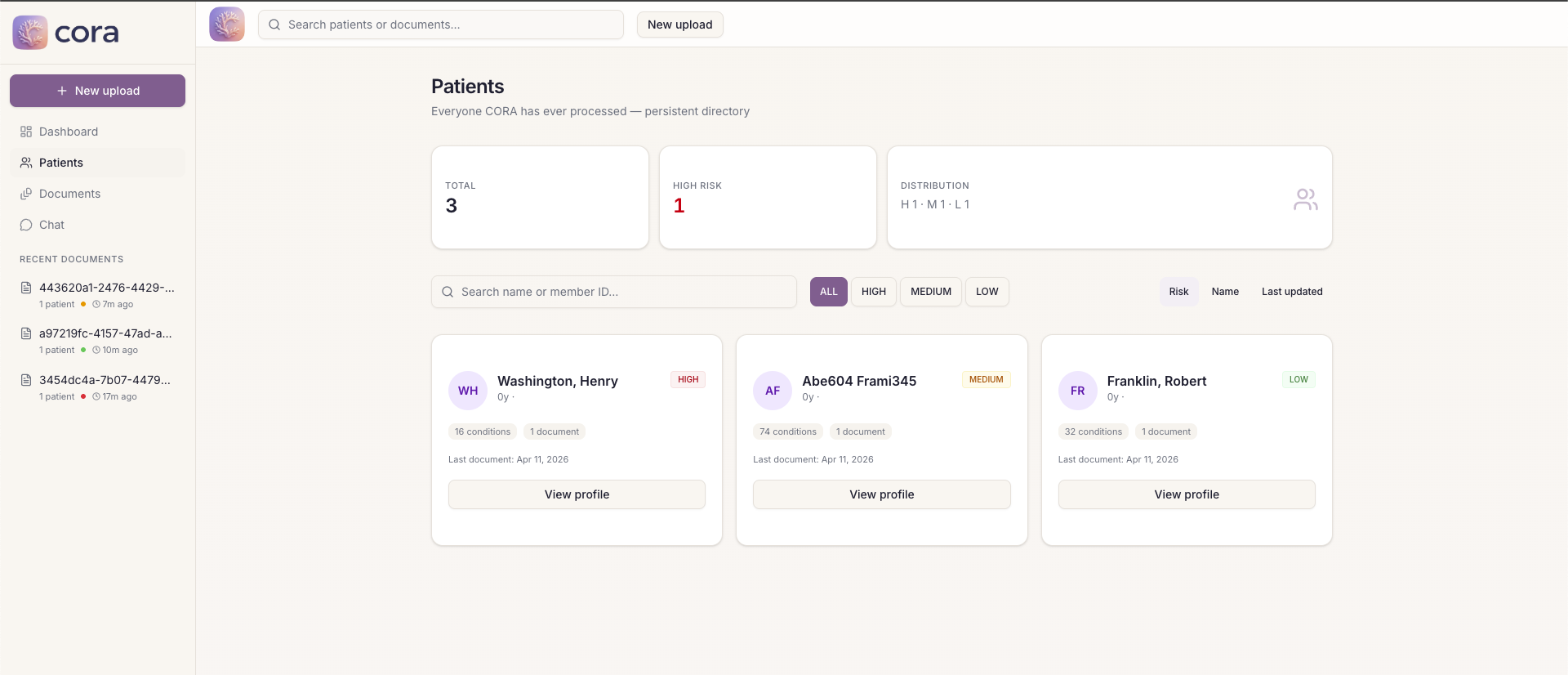
CORA Patient View
-
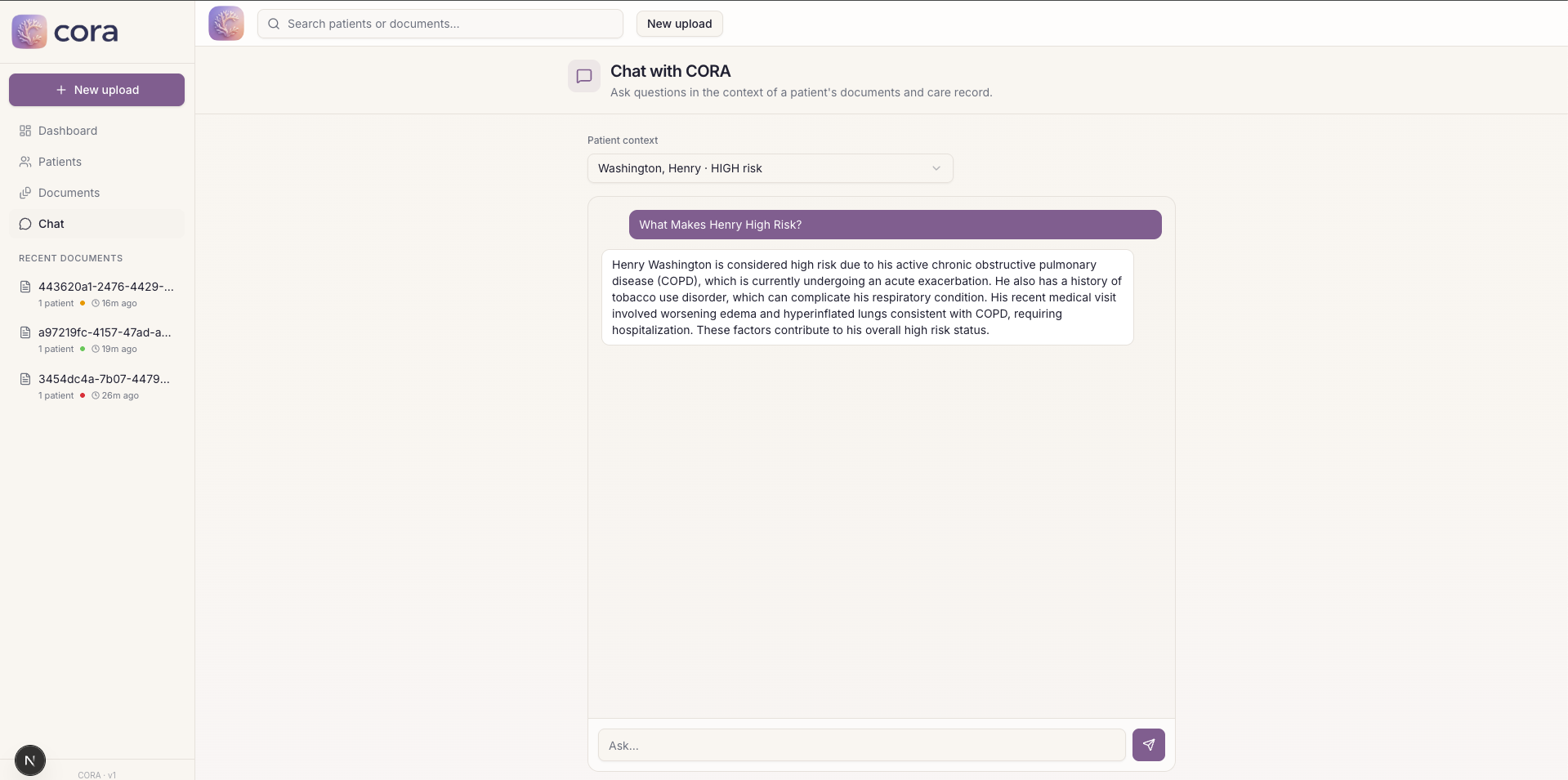
CORA Chat View

Inspiration
For the Elevance Healthcare track, we build a production-style REST API that processes doctor visit summary documents. We were really inspired by the potential of this service, and chose to also build a downstream application that care coordinators can use to utilize this.
Care coordinators manage 50 to 100 patients at a time. Every day they get huge stacks of medical documents, discharge summaries, visit notes, transfer records, and they have to read through all of it manually just to figure out who needs a follow-up call.
We wanted to fix that with our service, easing the burden on care coordinators.
What it does
Our API processes multi-page doctor visit summary documents/images and returns structured JSON file with key information gathered from the document. We were able to support cases with large files, multiple patients, mixed modality, among others.
The extraction logic is decoupled from the API and stored in a separate skills file, making it easy for non-technical people to change the rules used to extract information from the documents.
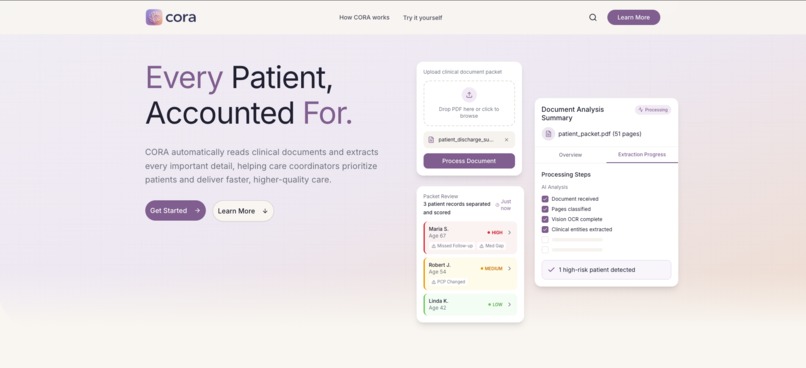
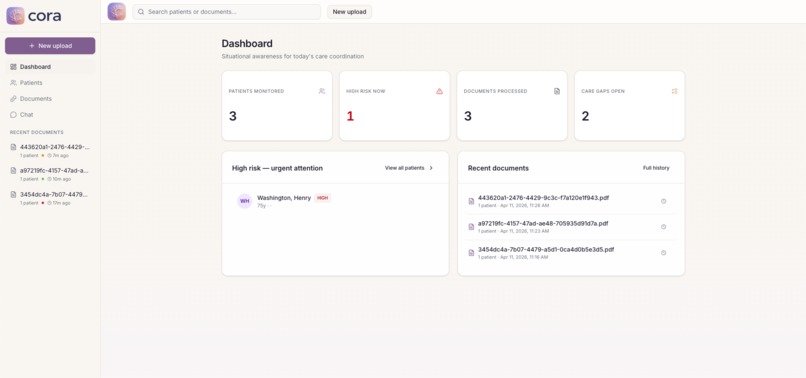
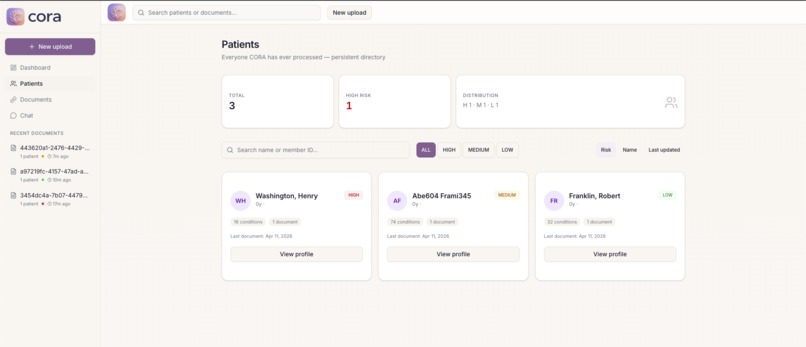
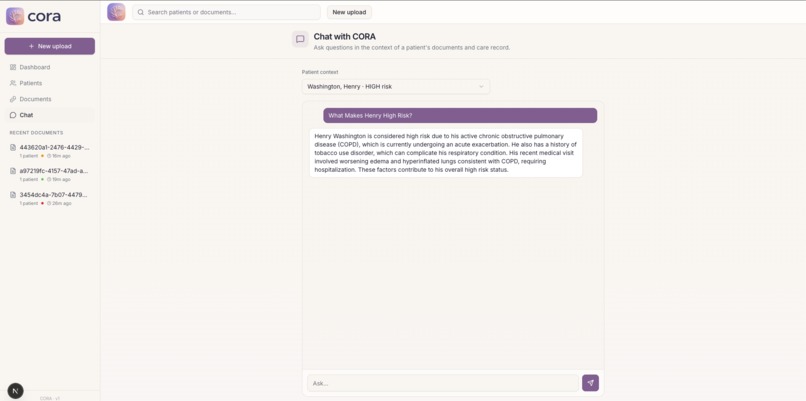
The application we built on top of the API is CORA. CORA takes any clinical document packet and turns it into an actionable patient workspace. Upload a PDF, CORA reads every page including scanned and handwritten forms, finds every patient in the document even if multiple patients are mixed together, extracts their conditions, medications, lab results, and visit history, then ranks them by risk score which is based on real HEDIS Transitions of Care criteria.
- Did the patient have a follow-up within 7 days of discharge? Was medication reconciliation completed? Did their primary care doctor change between visits? CORA answers all of that automatically and puts the highest risk patients at the top of the queue so coordinators know exactly who to call first.
CORA's key features include:
- accurate citations, facts are traced back to the exact page and text it came from
- patient profiles persisting across upload, CORA automatically merging related documents
- chat panel to ask plain English questions about any patient
How we built it
The backend is a FastAPI async job system. When a PDF comes in it runs through four stages:
- Classify each page as digital or scanned
- Chunk the document into visit sized groups using regex boundary detection
- Extract clinical data from each chunk using GPT-4o with a rolling context window that carries patient identity forward across chunks
- Finalize the result with risk scores and transition of care flags
Scanned and handwritten pages go through GPT-4o vision. PyMuPDF checks each page and if it does not have enough extractable text or is dominated by images it gets converted to a PNG and sent to the vision model instead.
All clinical logic lives in a YAML skill file completely separate from the application code. The pipeline just reads the skill file and follows it.
For our application CORA, built on top of the API, we implemented the data persistence via SQLite, and used Next.js 16 with Framer Motion animations on the frontend. When a new document comes in, CORA matches patients using member ID, MRN, or name plus date of birth, then updates their profile additively so nothing gets overwritten.
Challenges we ran into
Processing speed was the biggest one. Our first version ran everything sequentially and a 60 page document was taking over 10 minutes. We started to run parallel calls to GPT-4o to solve this issue, but then ran into rate limits. In the end, we implemented a hybrid approach which batches calls, while maintaining a rolling summary to avoid loss of context. We also switched to GPT-4o-mini to process calls faster.
Page classification was also tricky. Our first classifier only looked at text length to decide between digital and scanned paths. Radiology pages with short captions next to large images were getting misclassified as digital and the visual content was being ignored. We added an image area check so pages where images dominate get routed to vision regardless of how much text is there.
Patient matching across documents was harder than expected. The same patient might show up as "Marcus Webb" in one document and "Webb, Marcus A." in another. We built a token overlap name matcher that strips middle initials and punctuation and requires an exact date of birth match to avoid accidentally merging two different patients.
Accomplishments that we're proud of
We're really proud of getting the full stack working end to end in 24 hours. We learned a lot about how services like this could work in production, and how to ensure both reliability and accuracy.
The longitudinal patient profiles are also something we are genuinely proud of. CORA remembers results based off of multiple documents. Every upload enriches the patient's profile and you can see lab trends changing across multiple visits. That turns it from just a tool into a real platform that care coordinators can use.
What we learned
The hardest part of clinical AI is not the model. It is the data. Medical documents are inconsistent, multi modal, and full of edge cases that no single prompt handles perfectly. Keeping the skill file and the actual pipeline separate helped us address this issue, letting us iterate quickly to handle different document cases.
What's next for CORA
We would love to explore more approaches to making the API faster, this was an interesting challenge we had during the hackathon, and we want to expand its capabilities to handling even bigger documents without loss of accuracy.
We want to expand the skill file system so health plans can configure their own extraction rules without touching any code directly through CORA, making it adaptable to different documentation standards.
Longer term, the risk scoring model needs to get more sophisticated. Right now it is rule based and intentionally simple. With enough patient data you could train a model that predicts readmission risk from the extracted clinical picture directly.
Built With
- aiosqlite
- fastapi
- framer-motion
- gpt-4o
- next.js-16
- openai
- pymupdf
- python
- radix-ui
- sqlite
- tailwind-css
- typescript


Log in or sign up for Devpost to join the conversation.