-
-

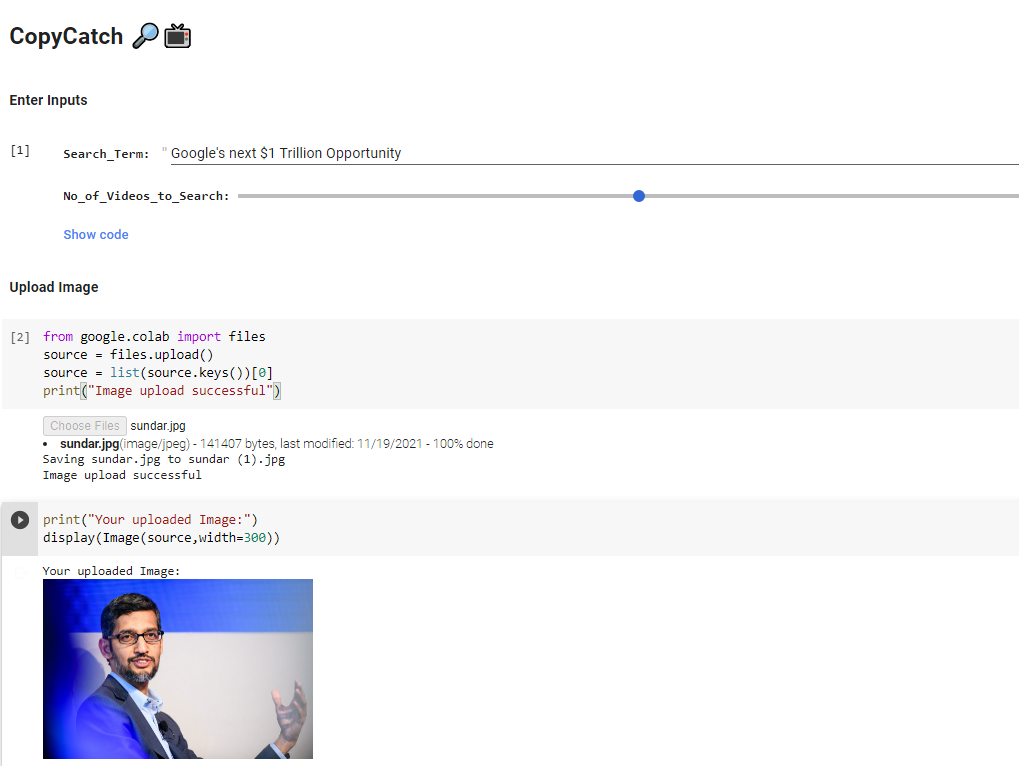
CopyCatch Parameters
-
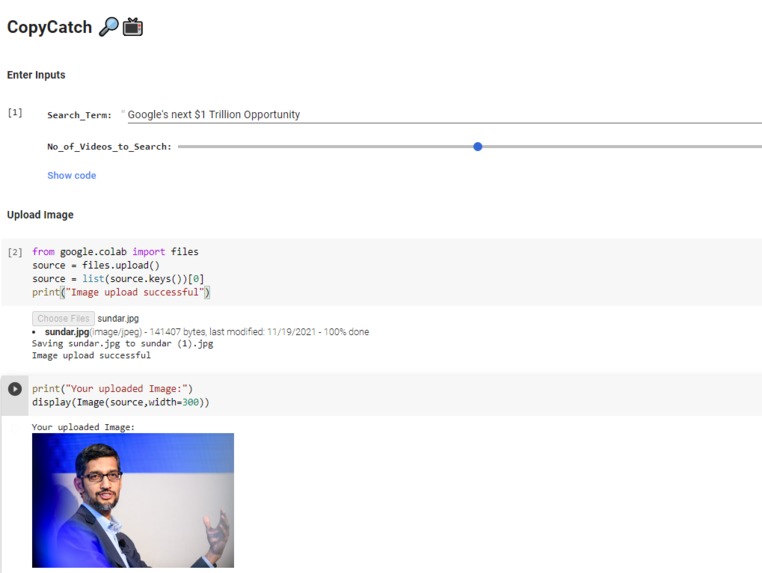
After Entering all parameters
-
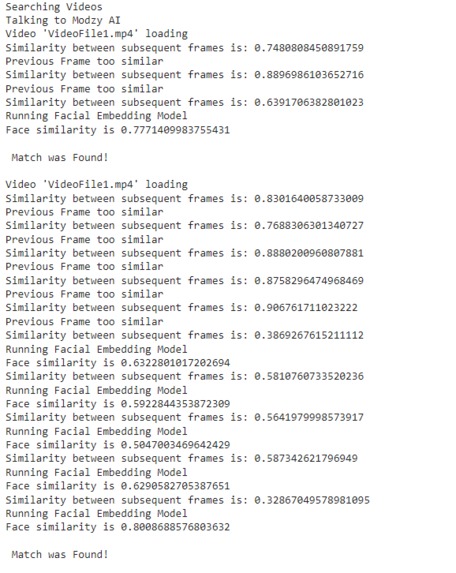
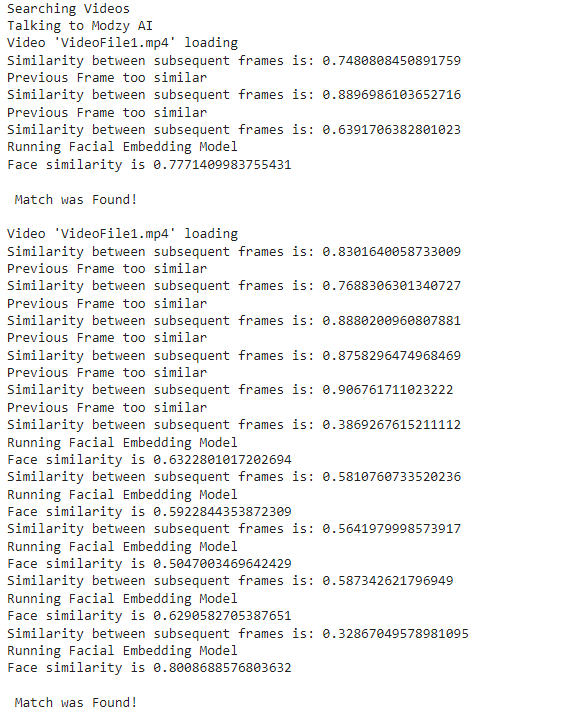
Video analysis
-
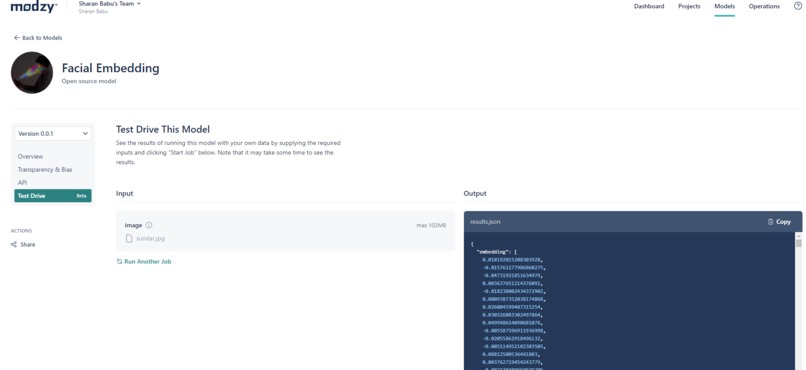
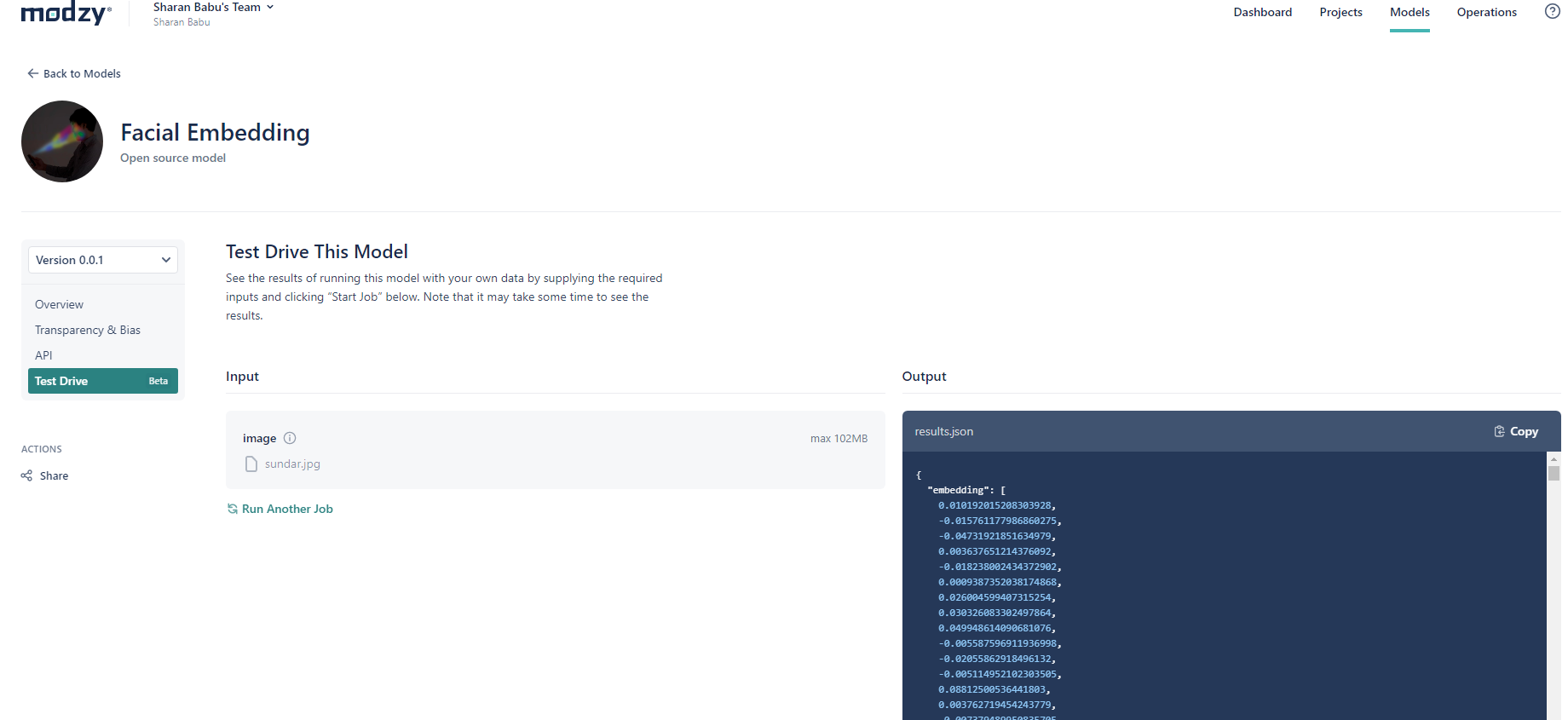
Modzy Facial Embedding AI Model
-
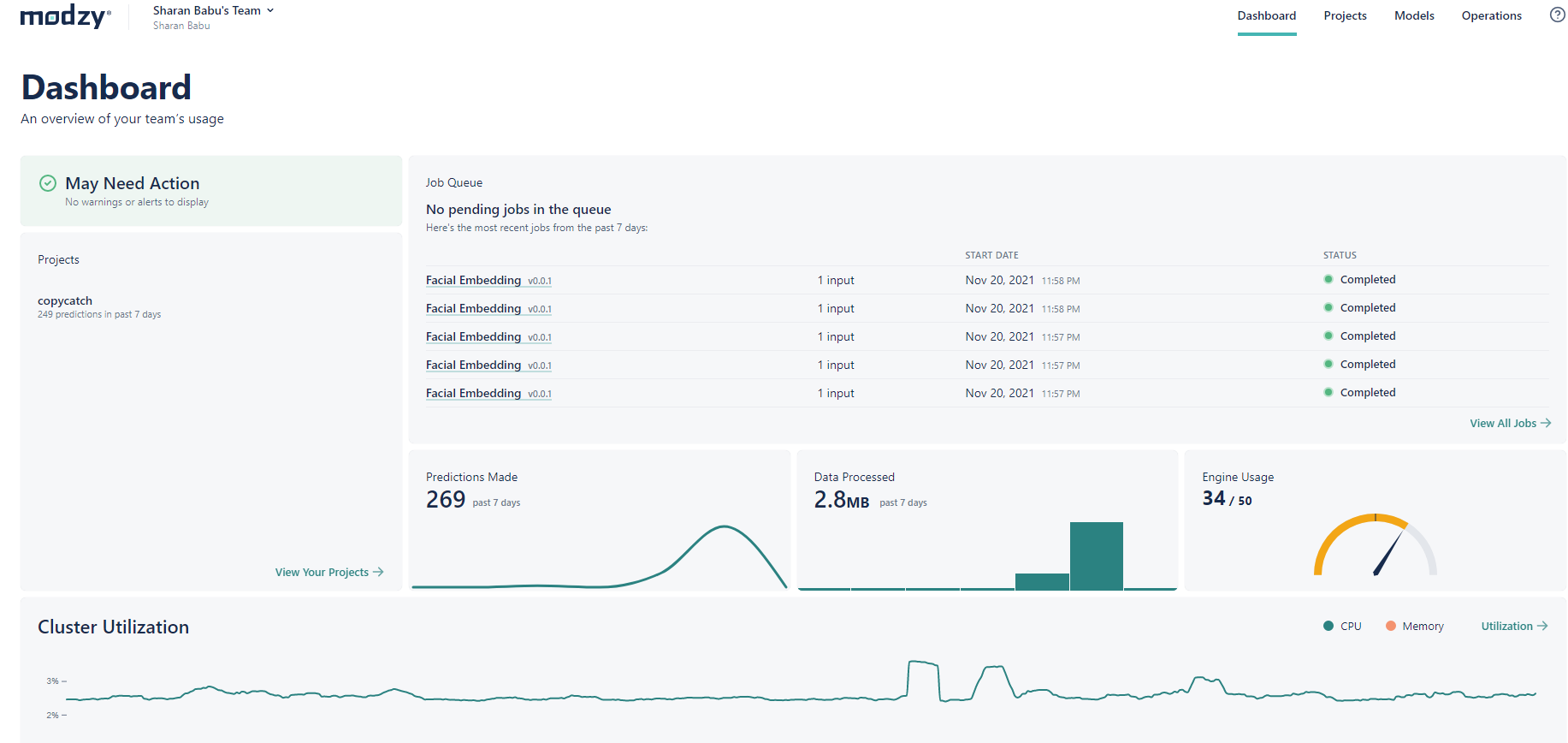
Modzy Dashboard
-
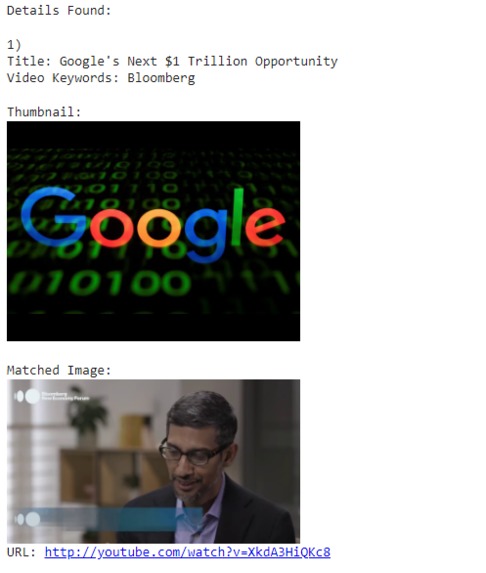
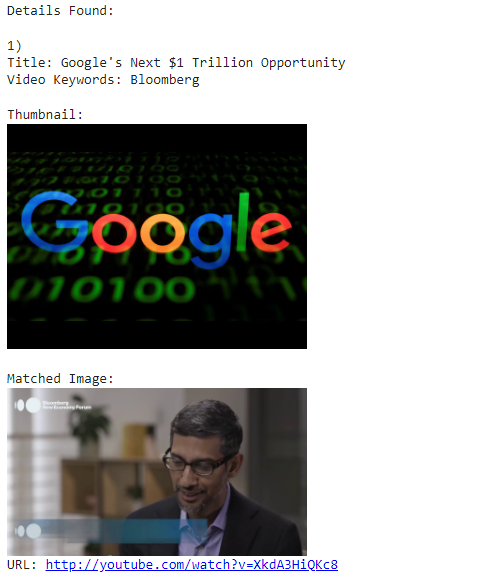
Video Results Part 1
-
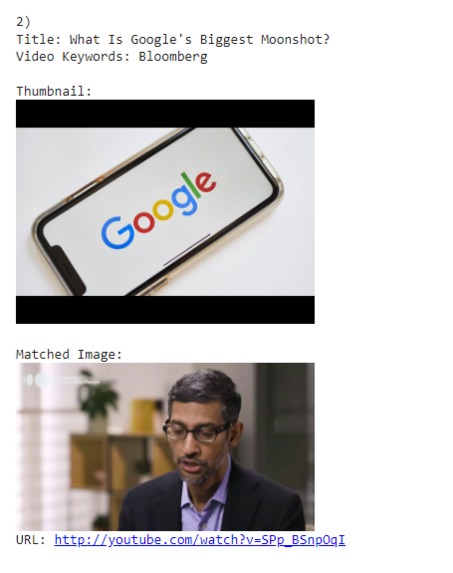
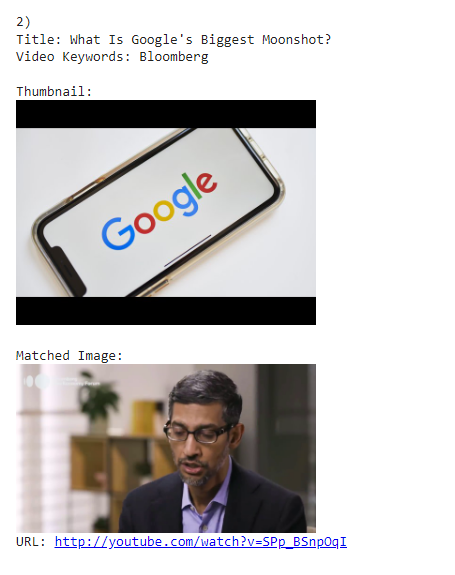
Video Results Part 2

Inspiration
To help creators and owners of content search for copyright-infringing videos on YouTube.
What it does

CopyCatch is helpful for automatically finding copyrighted content in a huge search space (Yt) and makes, call to action easier. Entering the search term, number of videos to search over, and reference image returns the required results. You now know which videos are to be flagged/taken down and you can do the same.
How we built it
The application was built using Modzy Facial Embedding Model.

First, videos related to the search term are downloaded from YouTube. These videos are analyzed to see if the reference face is present in any of those videos using the Modzy Facial Embedding Model. The model generates a 512-dimensional vector for faces present in the image. Cosine Similarity Function is then used to see if the face found in video frame similar to the face in reference image.
To optimize for performance, a measure called SSIM is being used to check the structural similarity of subsequent frames. If subsequent frames are very similar, computation is saved by not making a request to the Facial Embedding Model.
Challenges we ran into
Initially, all the video frames were sent to the Modzy Facial Embedding Model and this led to a slow run time. It was later optimized by using SSIM measure and now, only the distinct subsequent frames are computed upon. This decreases the number of calls to the model by Σ k-1 (summation from 1 to n) where 'n' is the number of scene changes in the video and 'k' is the number of frames in each scene.
Accomplishments that we're proud of
Copyright violation is very harmful to creators. Hence, I believe CopyCatch has the potential to make the lives of creators easier by protecting their content.
What we learned
Using Modzy AI Platform and models, opencv library to process videos and Deep Learning for Image Embeddings.
What's next for CopyCatch
Add video sources other than YouTube and multiple reference image upload.

Log in or sign up for Devpost to join the conversation.