-
-
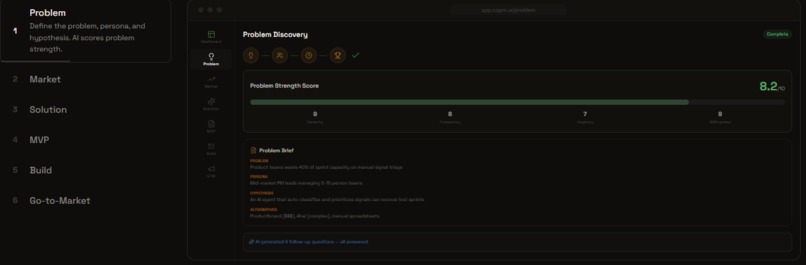
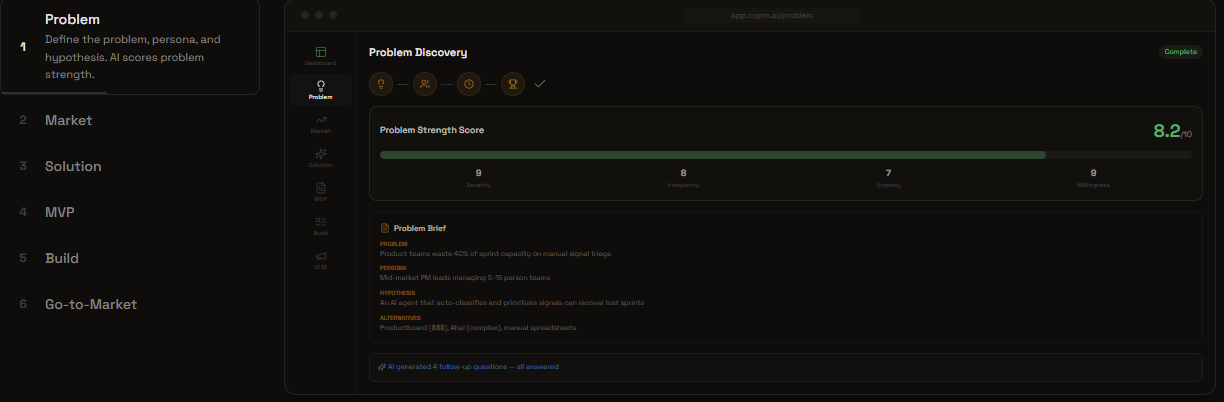
New Product Mode: Problem Discovery
-
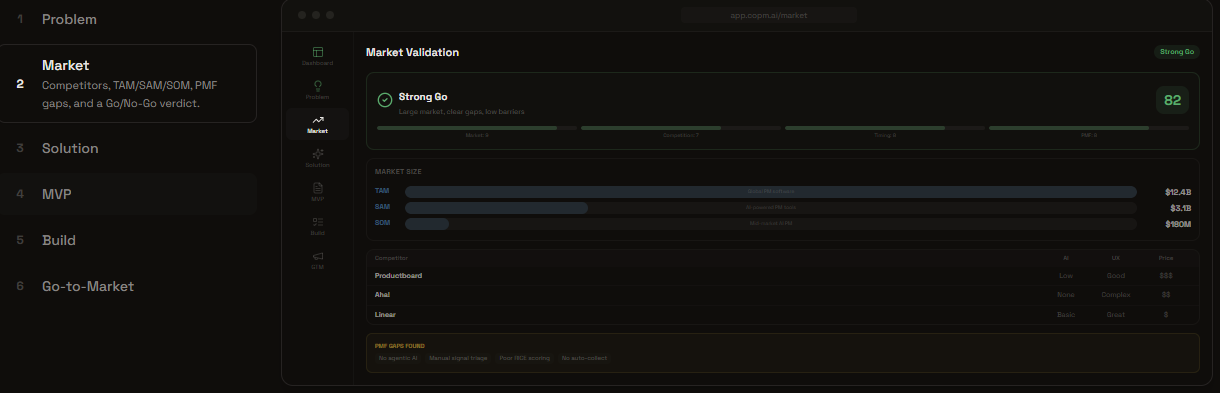
New Product Mode: Market Analysis
-
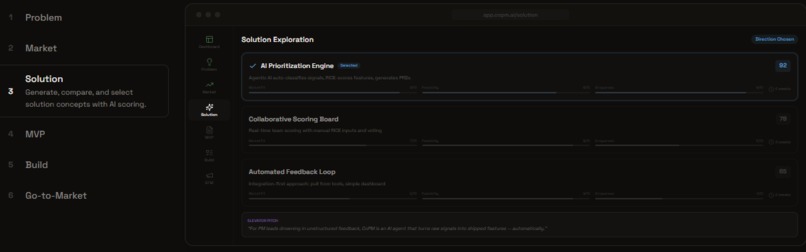
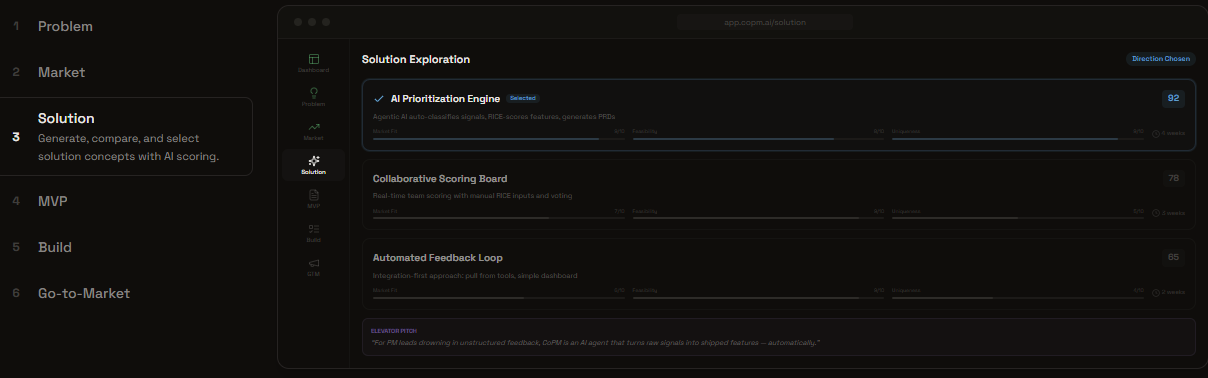
New Product Mode: Solution Design
-
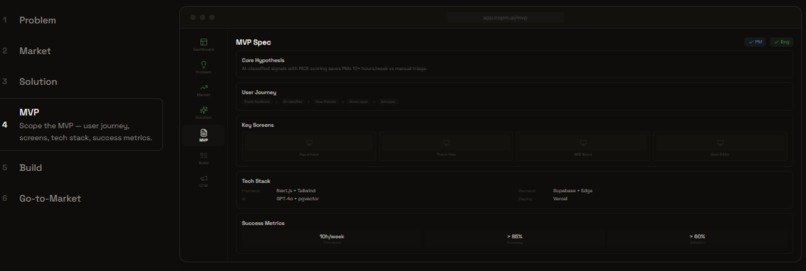
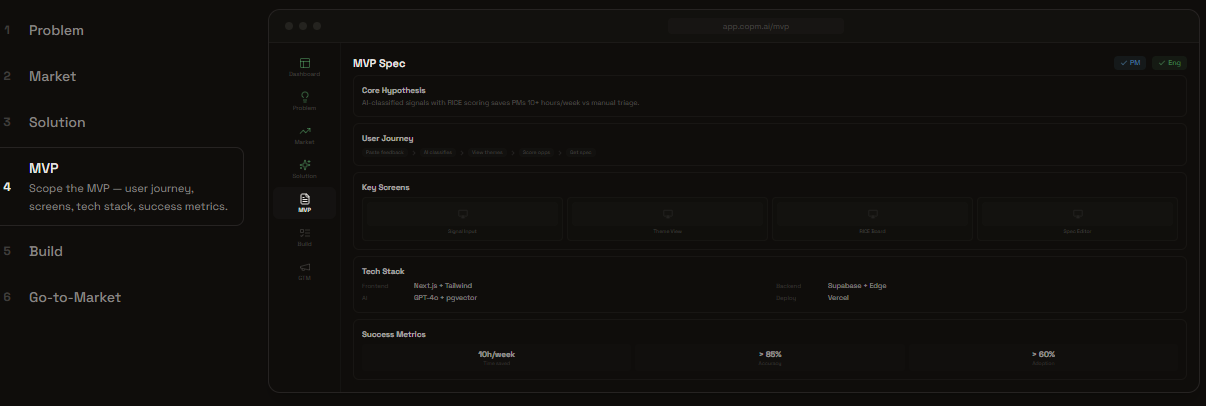
New Product Mode: MVP Specification
-
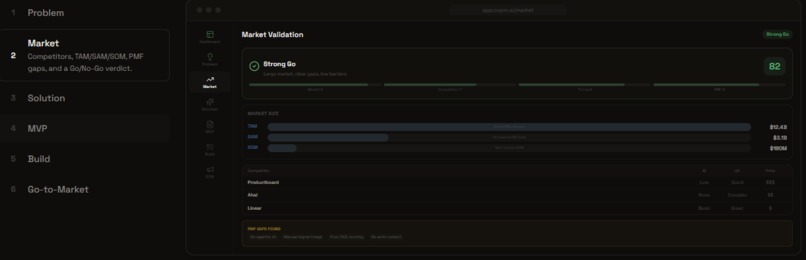
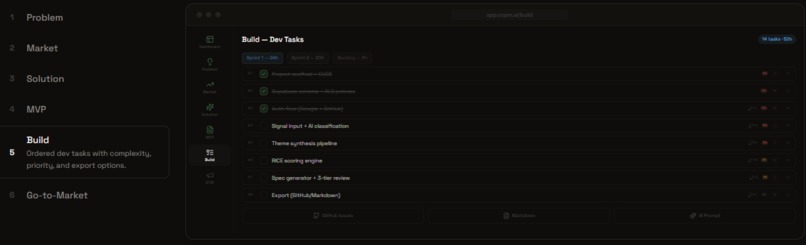
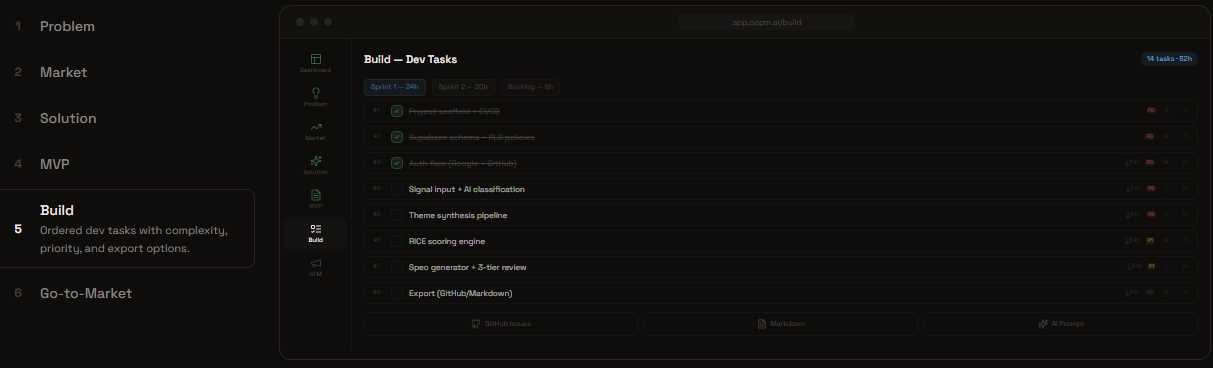
New Product Mode: Build
-
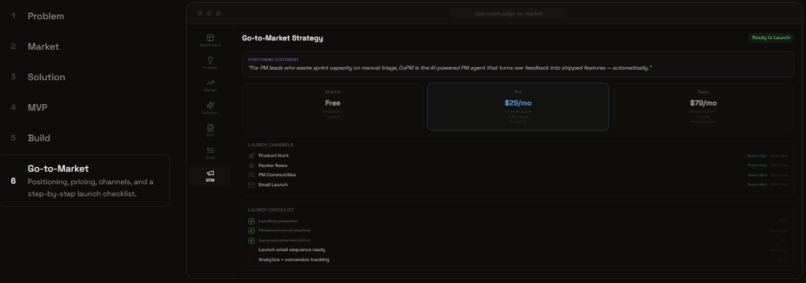
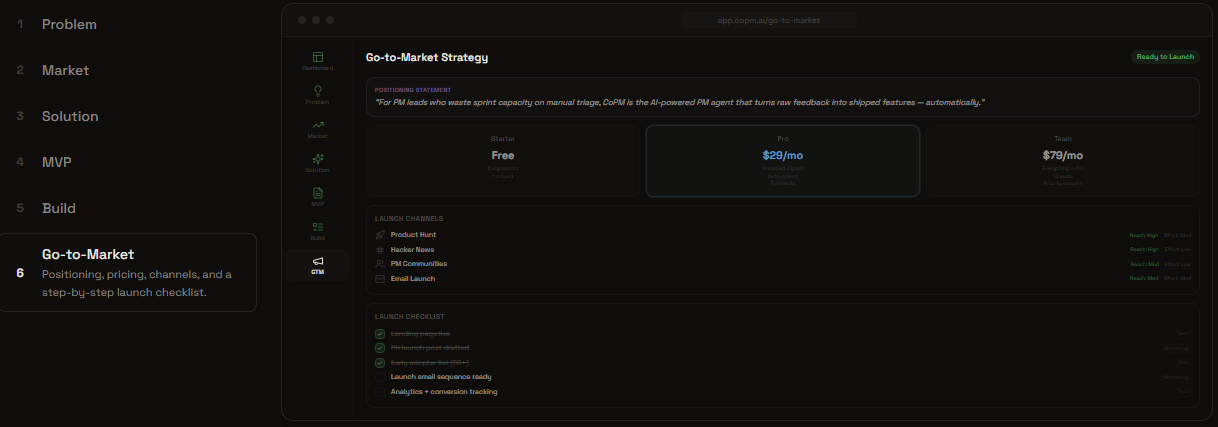
New Product Mode: Go-to-Market
-
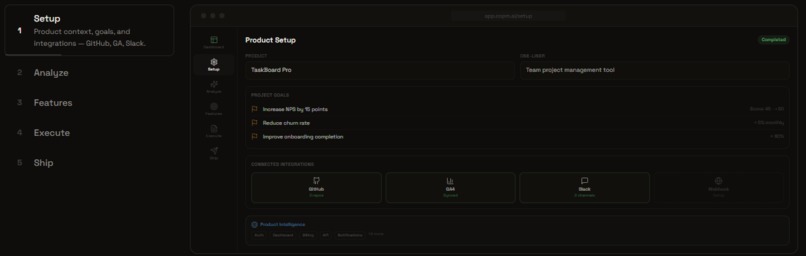
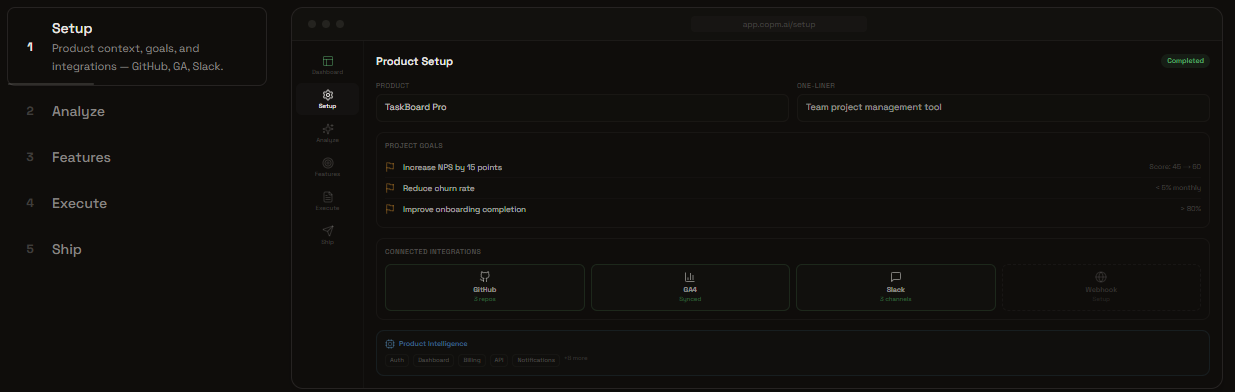
Feature Mode: Setup
-
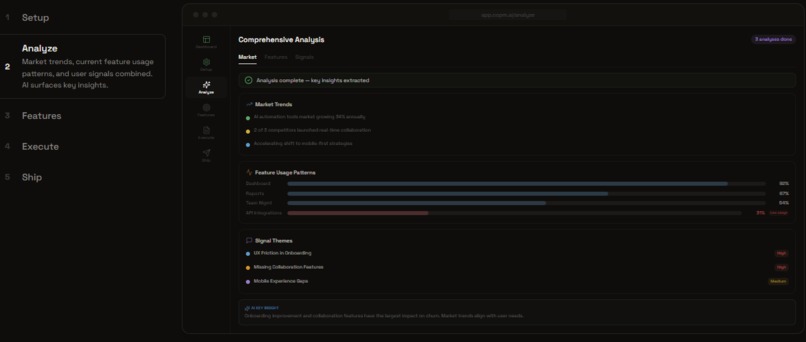
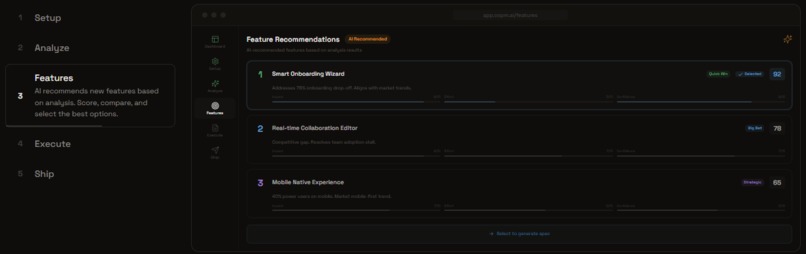
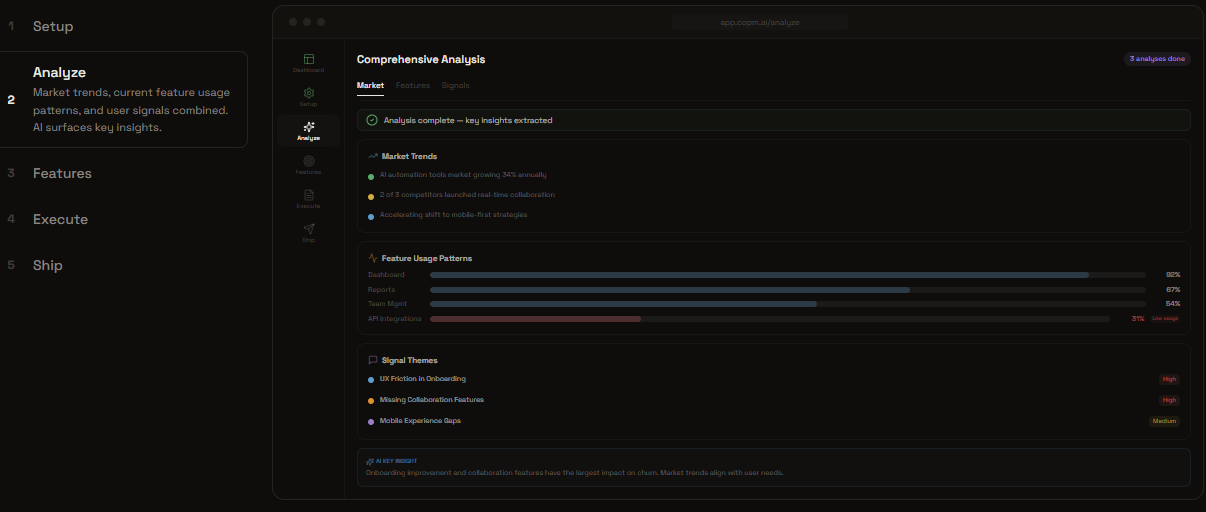
Feature Mode: Collect Signals and Analyze Themes, Market, and Competitors
-
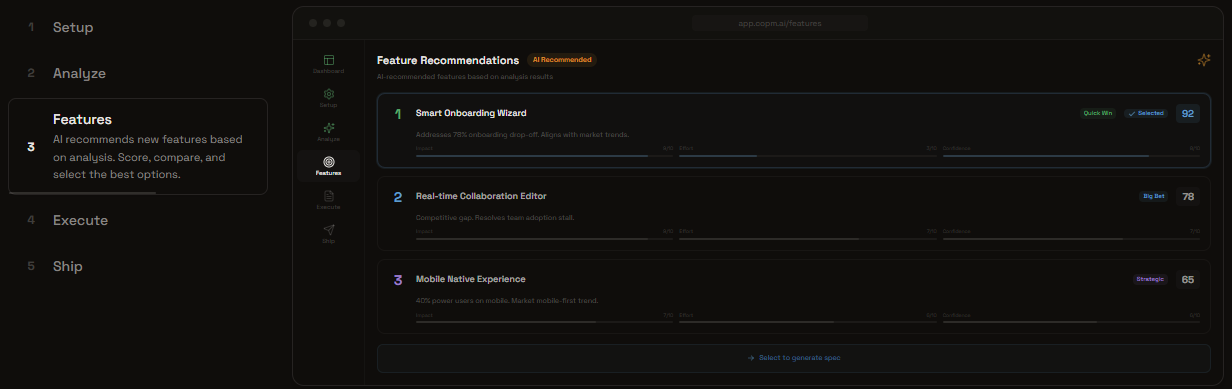
Feature Mode: Decide Priorities
-
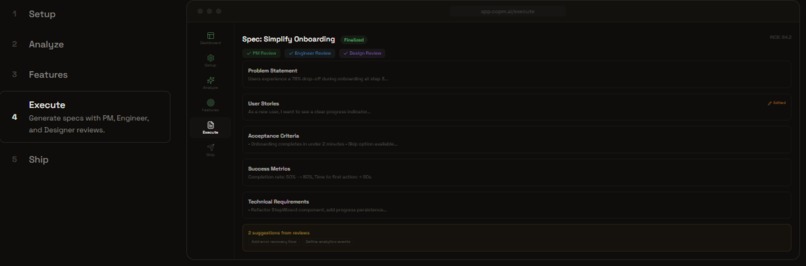
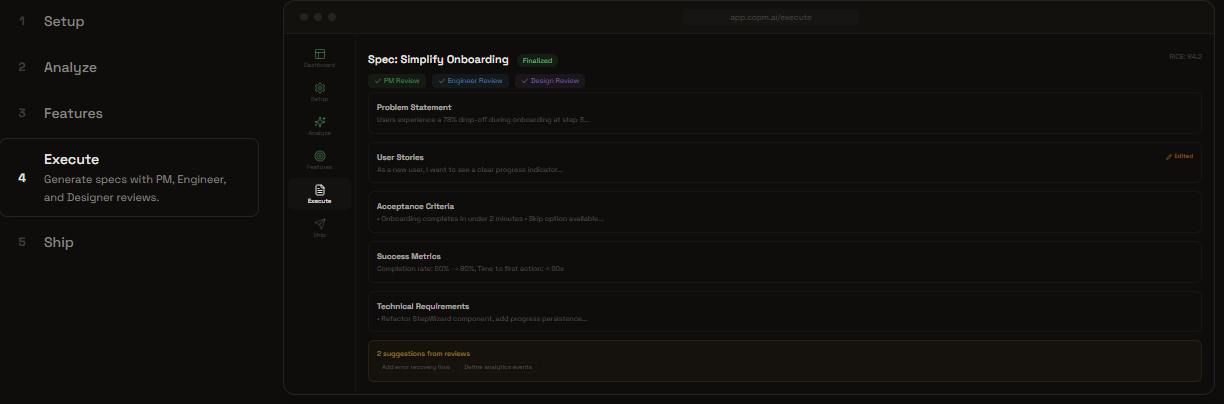
Feature Mode: Execute Specs
-
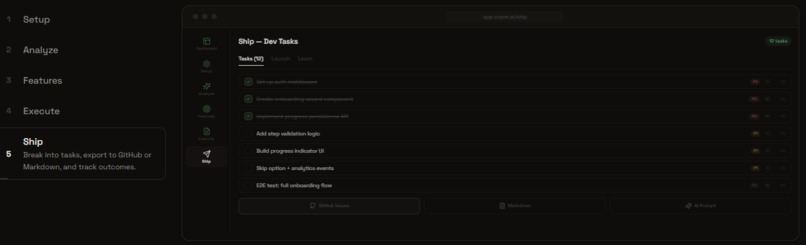
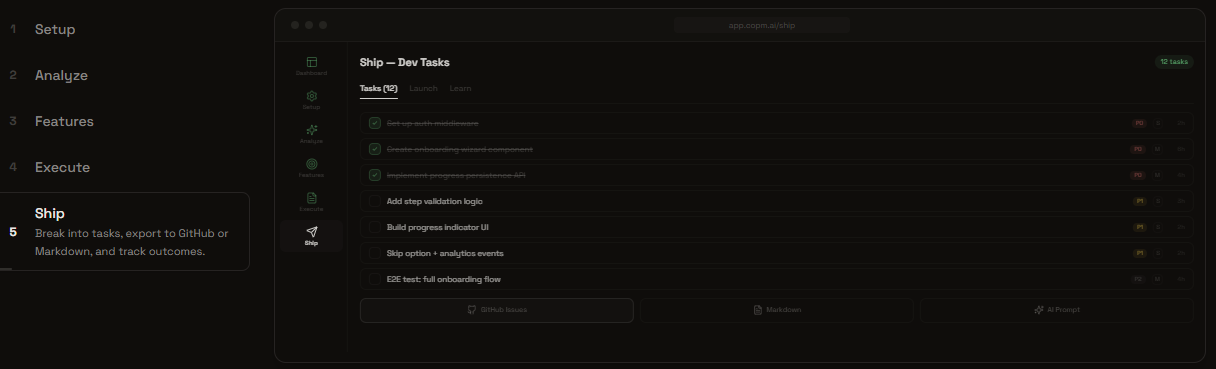
Feature Mode: Ship Tasks
Inspiration
As a product manager, I've seen firsthand how feedback drowns teams — scattered across Slack threads, support tickets, GitHub issues, meeting notes, and survey responses. Turning this chaos into prioritized features requires hours of manual synthesis, and critical signals often get lost. I asked myself: what if an AI agent could do the heavy lifting — while keeping the PM in full control?
CoPM was born from a simple frustration: the gap between "we have user feedback" and "here's what we should build next" is too wide. Existing tools are either glorified spreadsheets or black-box AI that PMs can't trust. I wanted something in between — an AI copilot that shows its work, cites its evidence, and lets humans override at every checkpoint.
Who it's for
- Product Managers drowning in unstructured feedback who need to synthesize signals into actionable priorities
- Solo founders & indie hackers validating new product ideas without a dedicated PM team
- Startup teams that need to move fast from user insight to shipped feature without losing rigor
What it does
CoPM is an AI-powered product management copilot with two complete workflows:
Feature Mode (7 steps): Collect signals → Analyze themes → Decide priorities → Execute specs → Ship tasks. For PMs adding features to existing products.
New Product Mode (7 steps): Define problem → Analyze market → Design solutions → Spec MVP → Build → Go-to-Market. For founders validating new ideas.
Key capabilities:
- Agentic AI, not a chatbot — a multi-step agent that plans, researches, and produces structured deliverables using tool calls
- Evidence-backed decisions — RICE scoring \( \frac{Reach \times Impact \times Confidence}{Effort} \) with impact-effort matrices and trade-off analysis, all traced back to real customer quotes
- Signal deduplication — semantic embeddings with pgvector (cosine similarity > 0.92) to catch duplicates and contradictions
- Human-in-the-loop checkpoints — users review, edit, or reject at every major step; edits are injected into the AI's next context
- Multi-source collection — paste, upload CSV/PDF, or auto-collect from GitHub, Slack, Zendesk, Intercom, and Google Analytics
- Rich artifacts — PRDs, task lists, GitHub issues, Markdown exports, and shareable links for stakeholder alignment
How I built it
The architecture centers on an agentic loop — the AI doesn't just answer questions, it orchestrates multi-step workflows using 5 specialized tools (extract features, find similar signals, propose themes, validate themes, review specs). Each pipeline step streams progress via Server-Sent Events, so users see the agent's reasoning in real-time.
I leveraged Microsoft AI alongside OpenAI API to power the agent's reasoning and analysis capabilities. I used Supabase with pgvector for both relational data and vector embeddings, enabling semantic signal deduplication and theme clustering. Row-Level Security ensures multi-tenant data isolation. The frontend is built with Next.js 15 App Router using server components for data fetching and client components only where interactivity demands it.
The checkpoint system is the architectural heart — at every critical decision point, the pipeline pauses, presents evidence, and waits for human input. Those decisions are logged for a full audit trail.
Challenges I faced
- Balancing AI autonomy with human control — too much automation feels like a black box; too little defeats the purpose. I iterated extensively on the checkpoint system to find the right balance.
- Signal deduplication at scale — naive string matching misses semantic duplicates. Implementing pgvector embeddings with cosine similarity thresholds required careful tuning to avoid false positives.
- SSE streaming reliability — keeping long-running AI agent sessions alive through SSE while handling checkpoints (pause → user input → resume) was a complex state management challenge.
- Dual-mode architecture — supporting two complete 7-step pipelines with shared components but different AI prompts and data models required careful abstraction without over-engineering.
Built With
- framer-motion
- microsoft-ai
- next.js
- openai
- pgvector
- postgresql
- react
- shadcn/ui
- supabase
- tailwind-css
- typescript


Log in or sign up for Devpost to join the conversation.