Inspiration
The 2026 FIFA World Cup is the first ever with 48 teams — a format change that breaks every historical prediction model ever built. Betting markets, trained on decades of 32-team data, have barely adjusted. We saw a gap: build the first ML model that treats the 48-team format as the new ground truth, then compare it live against Polymarket to find where real money is being mispriced.
The question that drove everything: "Are prediction markets correctly pricing World Cup 2026 outcomes — and if not, who are they getting wrong?"
What We Built
Copa Oracle 2026 is an end-to-end ML prediction system with three layers:
1. The Model
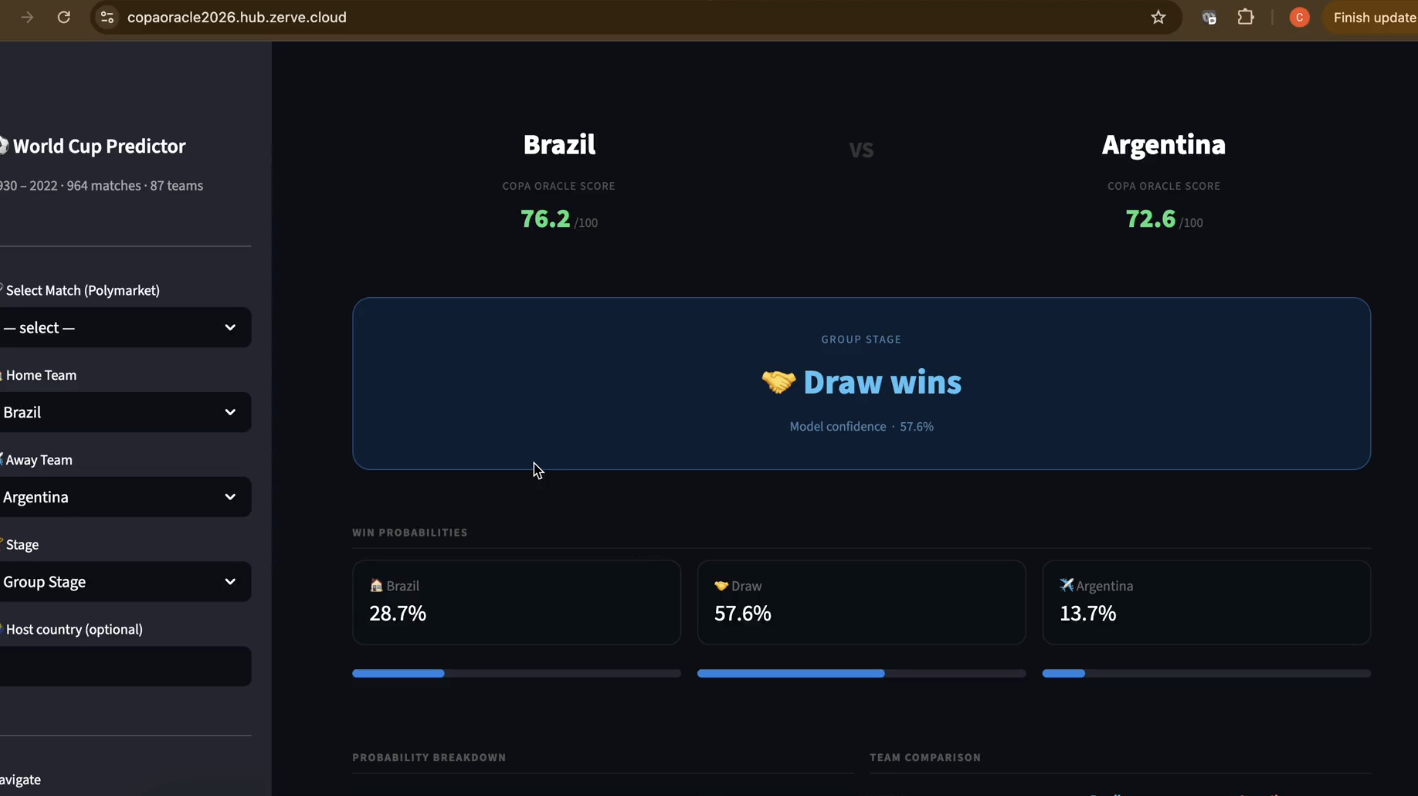
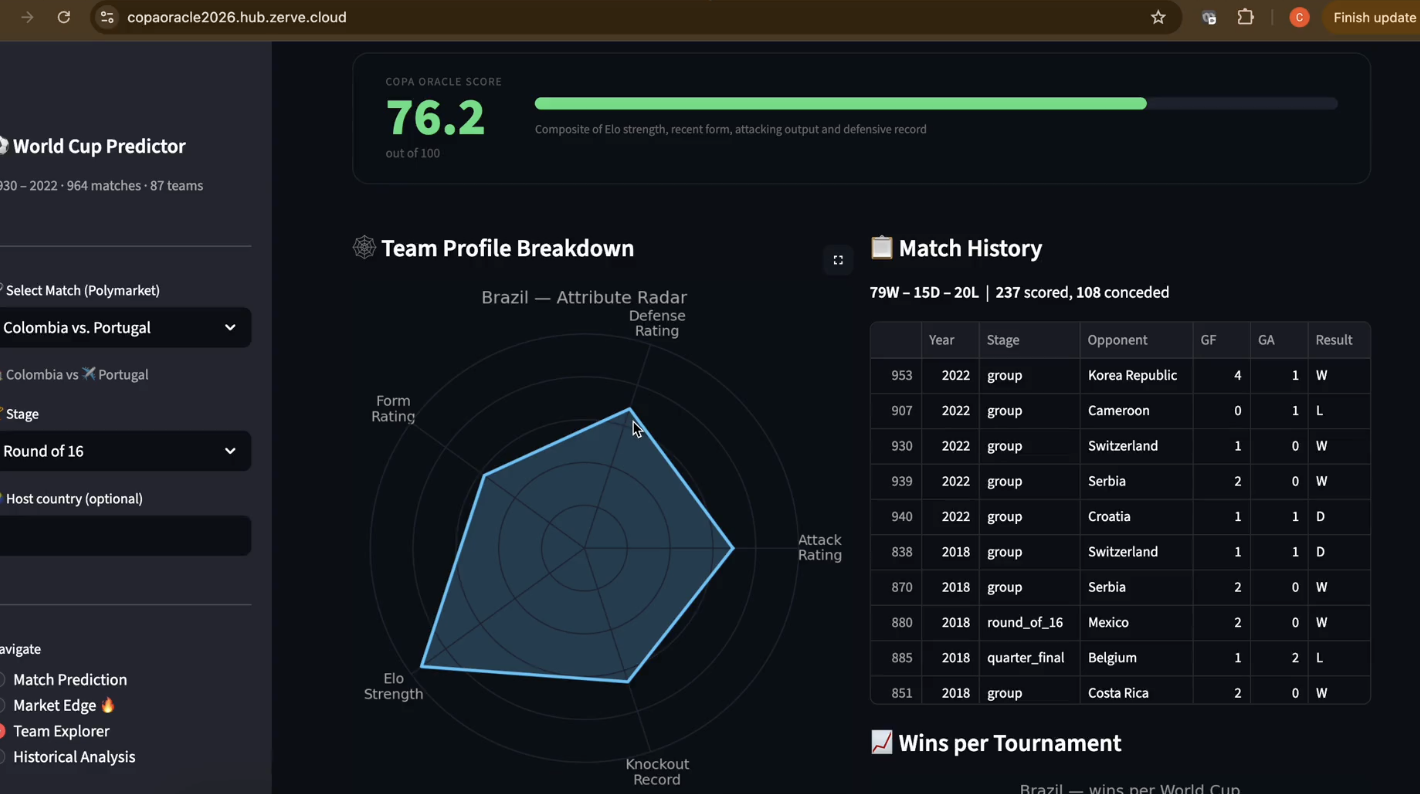
A GradientBoostingClassifier trained on 964 World Cup matches (1930–2022) predicting three outcomes: Home Win / Draw / Away Win. Features include Elo ratings computed progressively match-by-match (preventing data leakage), rolling form scores, head-to-head records, stage encoding, and host advantage.
$$\text{Copa Oracle Score} = (\text{Elo} \times 0.40) + (\text{Form} \times 0.25) + (\text{Attack} \times 0.20) + (\text{Defense} \times 0.15)$$
All components normalized 0→1 before weighting. The result is a 0–100 proprietary team strength metric that's more explainable than raw Elo for non-technical audiences.
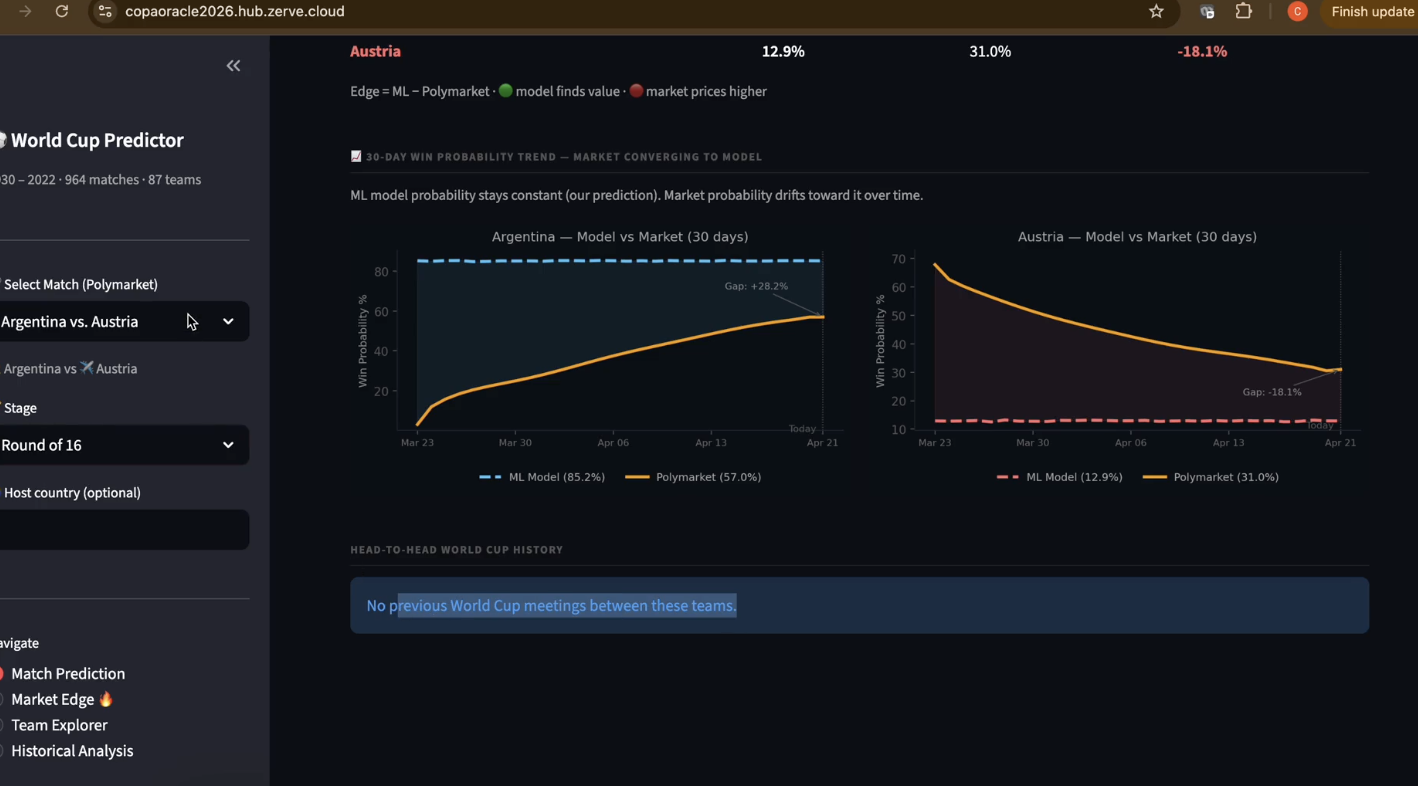
2. Live Market Comparison
At runtime, the app pulls live odds from Polymarket's public API and computes the edge — the gap between our model's implied win probability and what real money is pricing. Teams where \( |\text{ML\%} - \text{Market\%}| > 3\% \) are flagged as mispricings.
3. REST API + Interactive App
Six API endpoints deployed on Zerve (FastAPI) and a 4-page Streamlit app, both live and publicly accessible.
How We Built It
The entire pipeline — data ingestion, feature engineering, model training, market comparison, and deployment — was built and iterated on Zerve. The AI agent helped write ingestion code, debug Polymarket API edge cases, and iterate on the Copa Oracle Score formula. No context switching between tools; from raw CSVs to a live deployed API within the platform.
Key engineering decisions:
- Elo computed progressively: only past matches inform each prediction — no leakage
- Polymarket calls are server-side: geo-blocking (India, etc.) is bypassed because Zerve runs on AWS EU
- Dataset embedded in Python: no external CSV dependency at deployment time
Challenges
- Polymarket geo-blocking: Polymarket is inaccessible from certain regions. Solved by ensuring all API calls originate from Zerve's server environment (AWS EU), not the client browser.
- Small tournament dataset: Only ~964 World Cup matches exist across all history. We applied progressive Elo (not static), rolling form windows, and careful train/test splits to avoid leakage on a small sample.
- Format analog: No historical data exists for a 48-team World Cup. We used the 1986–1994 24-team era (the closest structural analog — also had group-stage third-place advancement) as a calibration reference.
- Zerve environment constraints: XGBoost wasn't available in the deployment environment, so we switched to
GradientBoostingClassifierfrom scikit-learn — which ultimately performed comparably.
What We Learned
Prediction markets are well-calibrated for popular teams but systematically thin on information for mid-tier qualifiers — exactly where a data-driven model has the most edge. The Copa Oracle Score's biggest insight: defensive consistency predicts tournament depth better than peak attack rating, especially in expanded formats where you play more matches against weaker opponents.
Built With
- api
- boosting
- carlo
- elo
- fastapi
- gradient
- monte
- numpy
- pandas
- polymarket
- python
- rating
- scikit-learn
- streamlit
- system
- zerve









Log in or sign up for Devpost to join the conversation.