-
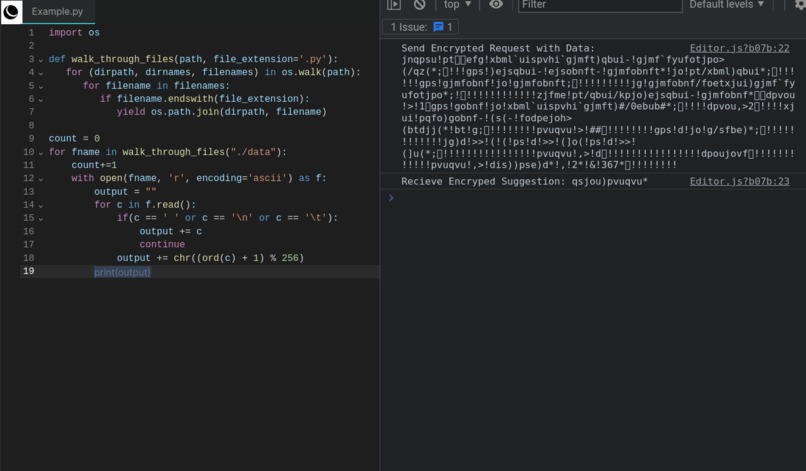
Suggestion Demo
-
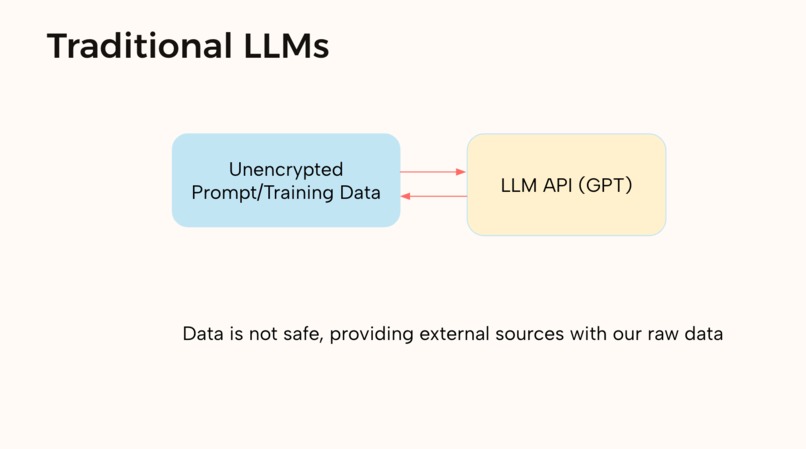
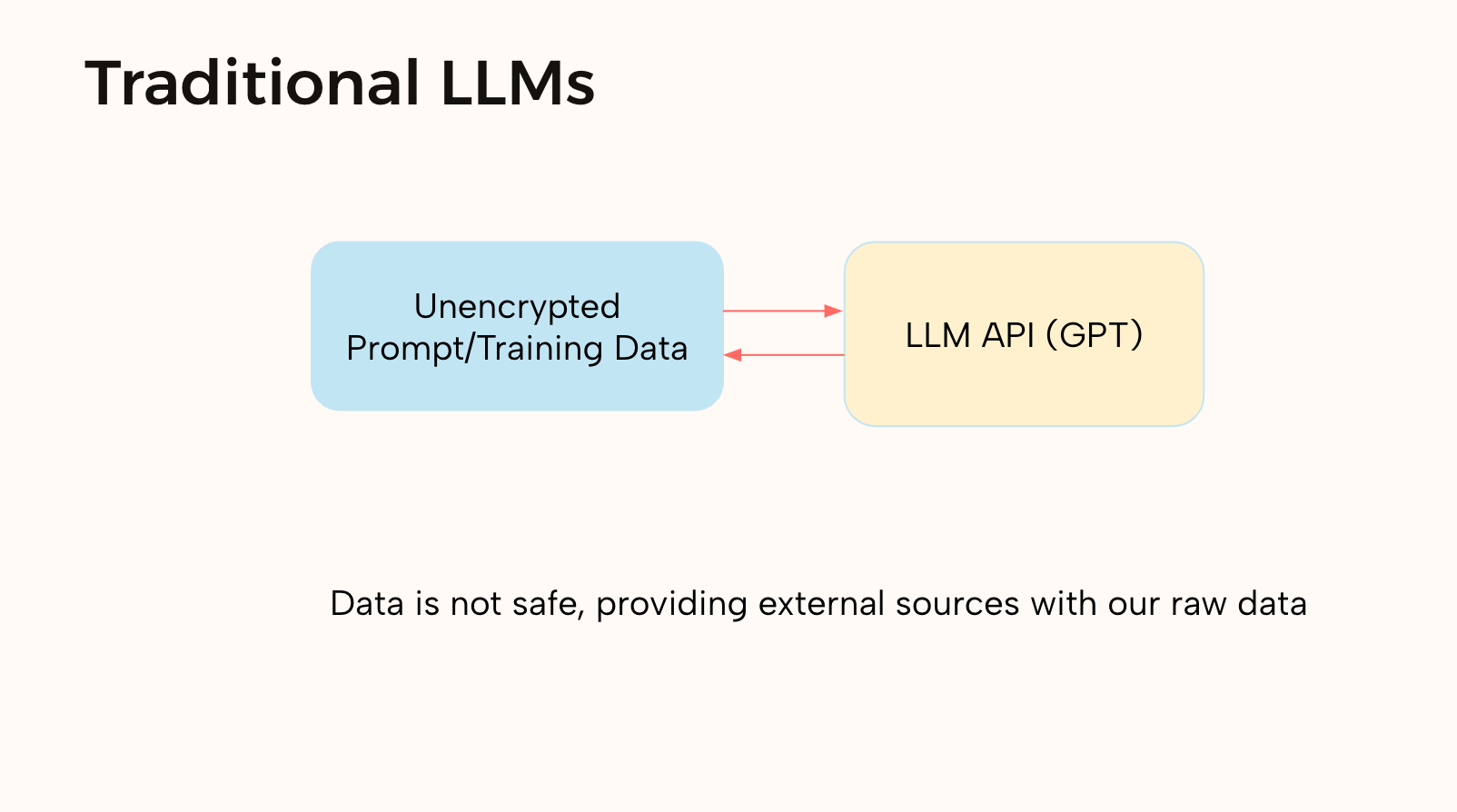
Traditional LLM
-
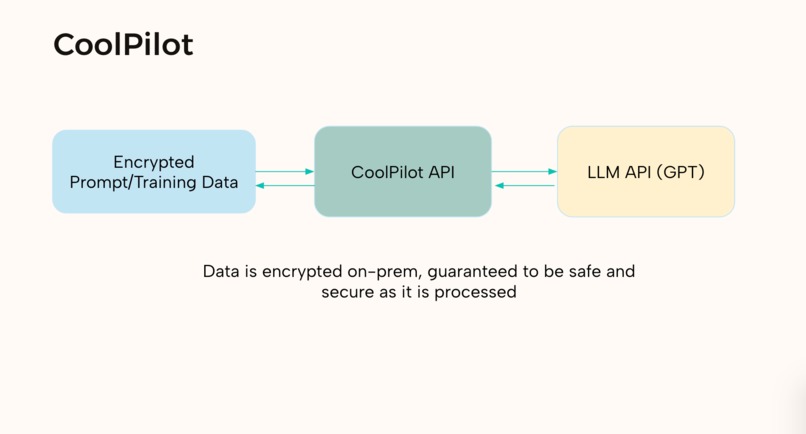
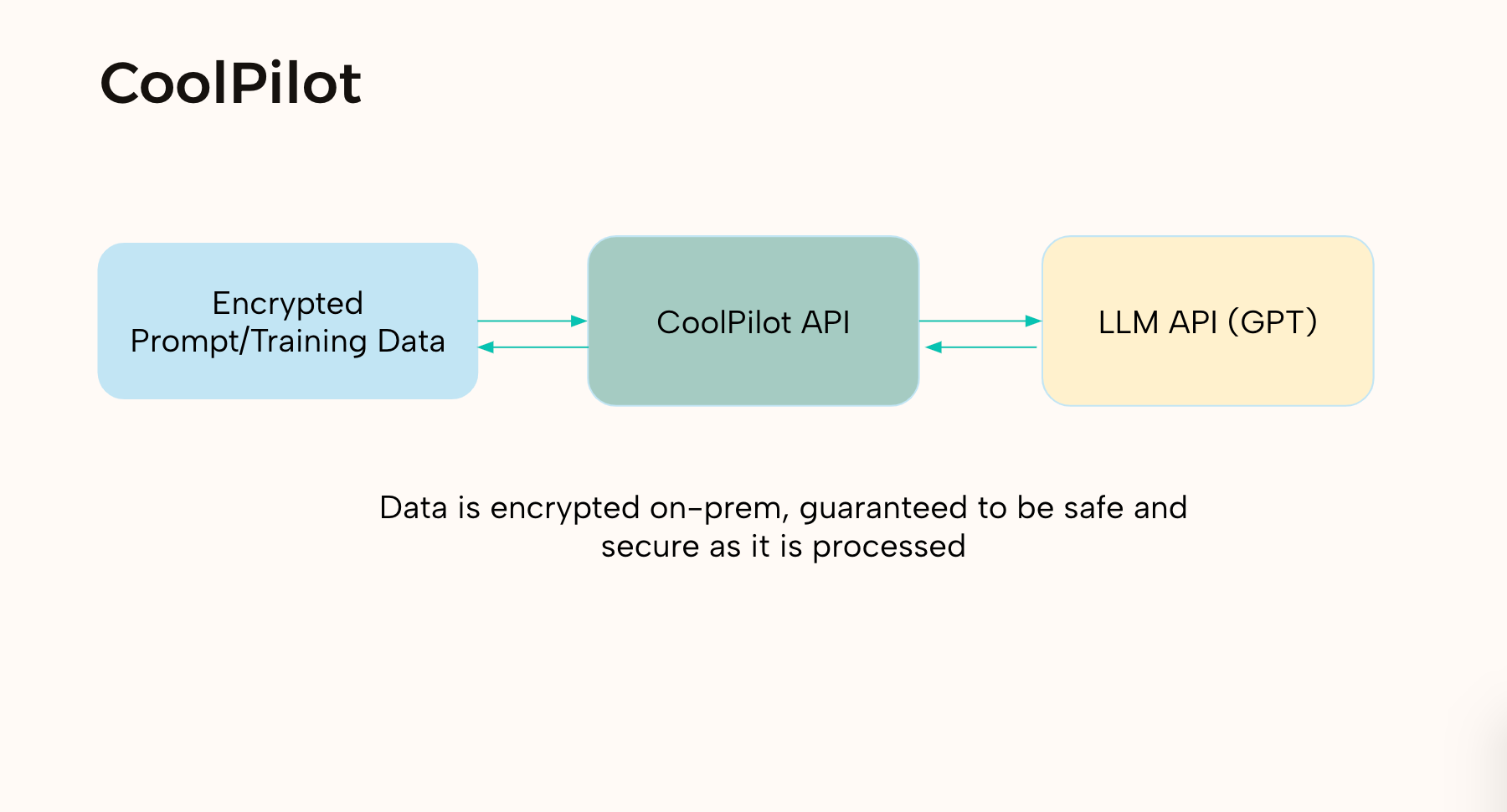
CoolPilot LLM
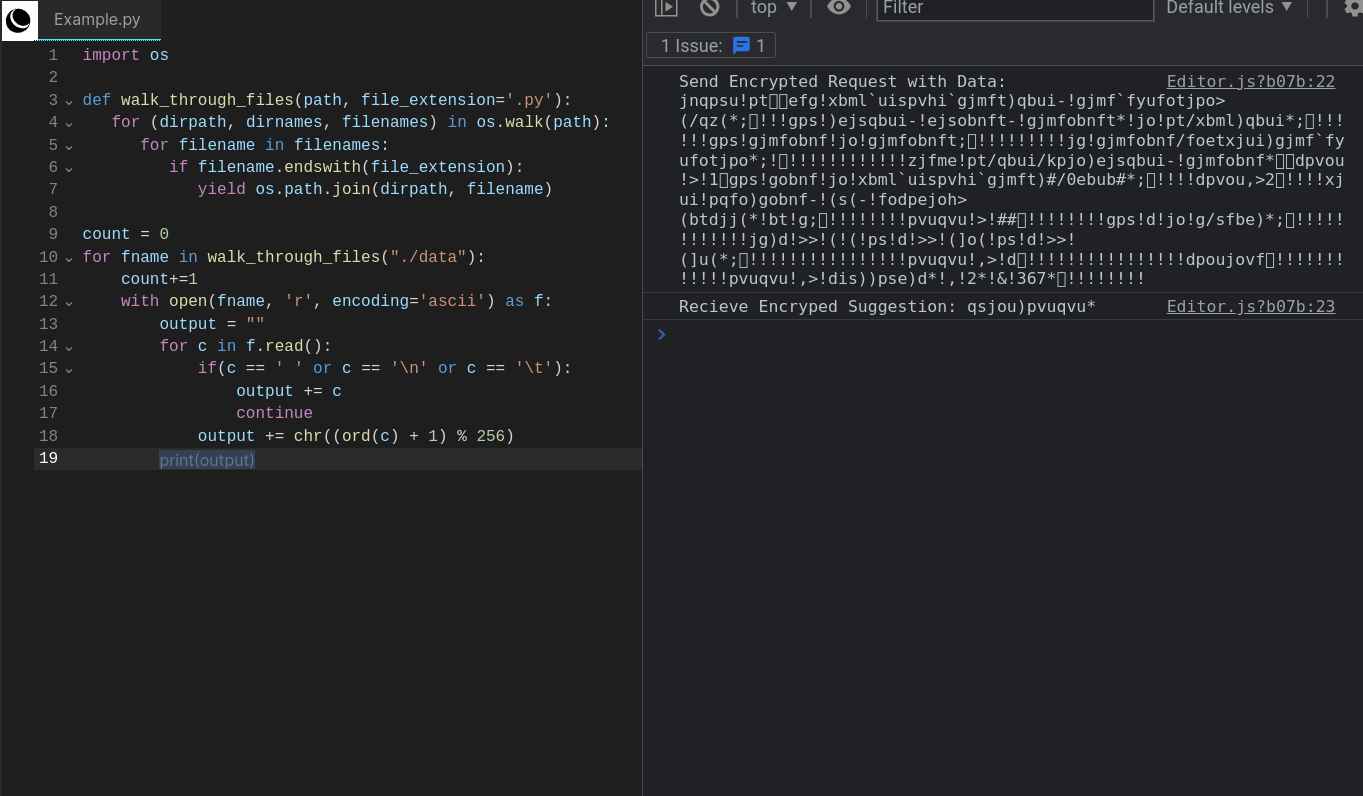
Inspiration
Large Language Models don't need to know personal information. When we use a LLM, who knows where the data we input is used. It could be used for training, leaked, or even spit out in another answer. We propose a safe and secure way to communicate with LLMs that keep all the power and hides our identity.
Using this method, we created an app for a specific use case: Companies want AI code tools to help their developers, but don't want to hand off their internal code to a black box. We help by creating models on encrypted text that returns encrypted text, providing clients an easy to use and customized code generation API without needing to know any internal code.
What it does
We first use a client-side homomorphic encryption to encrypt data (meaning its encrypted but we can still do operations on it). This way we (as the service provider) will never know the real un-encrypted code. We then train a large language model on this encrypted code, that outputs more encrypted code, for example code suggestions. We then return the generated results, which is decrypted client side by the user. This way, we can provide powerful tools for user's data, without ever knowing what the data really is.
In the rise of AI, this can have way more uses than code and LLMs. Companies want to protect their data, and users want to protect their privacy. This method can be used for both.
How we built it
We used Hugging Face tools and Pytorch to build our own customized LLM from scratch, as our encrypted code isn't English anymore. We then created a frontend in Nextj.js for the demo
Challenges we ran into
We ran into challenges on all steps of creating model, from finding a suitable dataset, getting the tokenizer working properly, and to actually getting it to produce reasonable results. We tried multiple methods of generating text data, such as fine tuning a pretrained model, prompt engineering, and custom model, and found that the third option, which was the most difficult, worked the best.
Accomplishments that we're proud of
We are proud of the front end user interface and the amount of effort we put into learning about large language models.
What we learned
We learned a lot about large language models, including what is going on behind the hood, and how to create our own from scratch.
What's next for CoolPilot
Since every client has a unique encryption scheme, we will need to train a LLM for each client from scratch, which is really expensive. We can try fine tuning or pretraining a LLM on a class of encrypted texts. Additionally, since our LLM is essentially learning a new language, it cannot provide context or answer queries about the code. To solve this, we can try adding additional annotated data to our training set.


Log in or sign up for Devpost to join the conversation.