🌟 Inspiration
In today's hyper-connected world, telecommunications companies handle millions of customer interactions daily across multiple channels—phone calls, social media, review sites, and support tickets. Yet, a persistent challenge remains: how do we transform this ocean of unstructured feedback into actionable insights that genuinely improve customer experience?
We were inspired by T-Mobile's commitment to customer satisfaction and their "Un-carrier" philosophy. We asked ourselves: What if we could give customer service teams a crystal ball? A real-time dashboard platform that doesn't just collect feedback but understands it, analyzes it, and displays it for teams to take actionable insight.
Our vision was ambitious: build a comprehensive data-driven dashboard that monitors sentiment across major channels, identifies emerging issues, analyzes call transcripts for quality assurance, and provides executives with actionable insights—all in real-time.
🛠️ What It Does
Our T-Mobile Customer Intelligence Platform is a full-stack data-driven dashboard solution that revolutionizes how telecommunications companies understand and respond to customer sentiment:
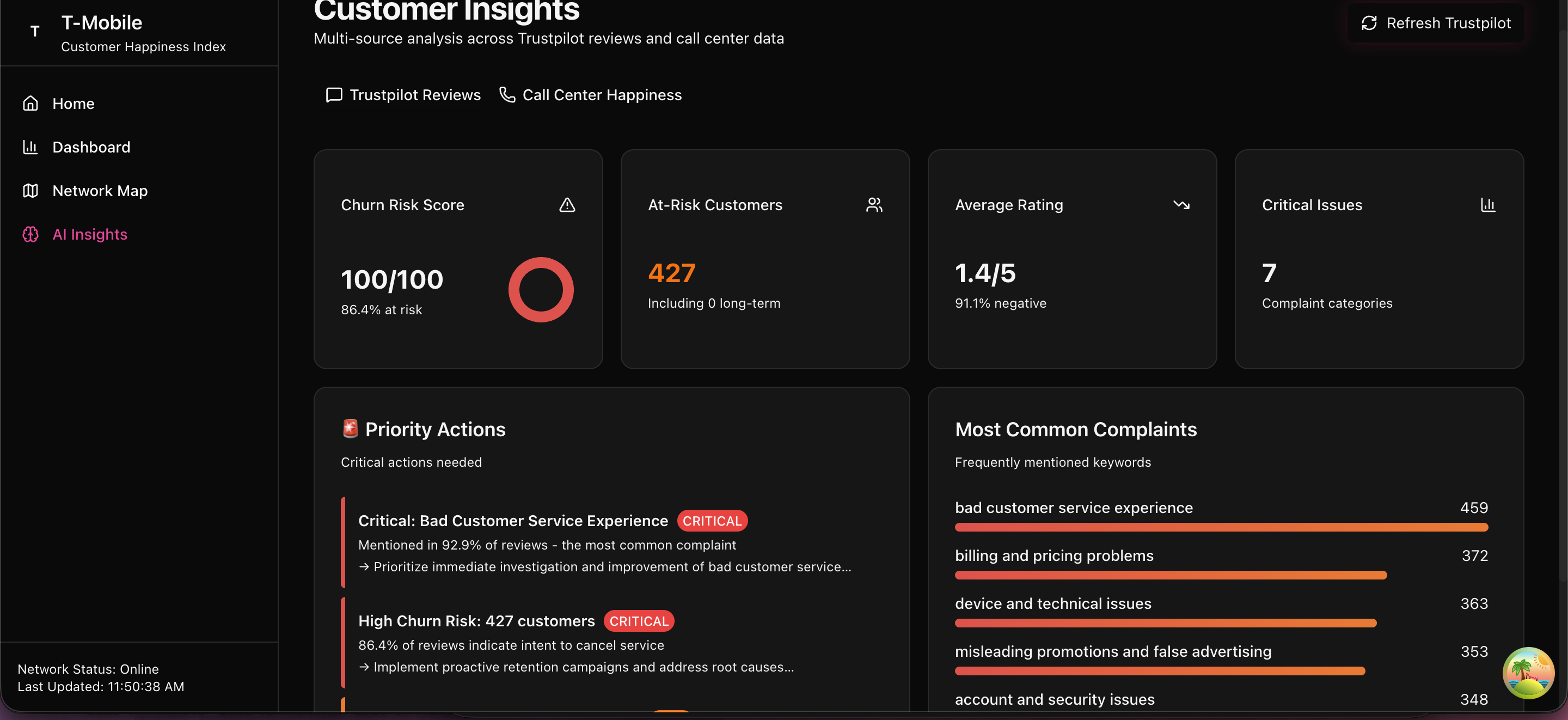
📊 Real-Time Multi-Channel Sentiment Analysis
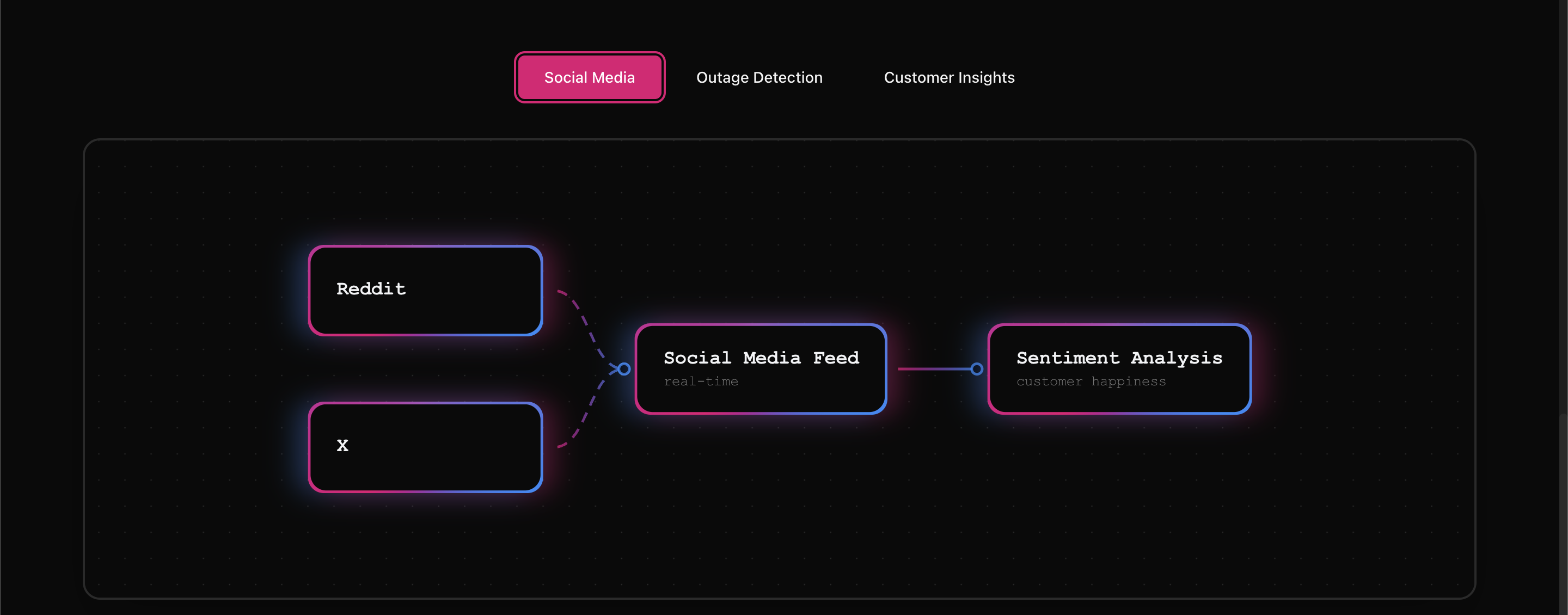
- Social Media Monitoring: Continuously ingests and analyzes Reddit posts (PRAW) and Twitter/X mentions (Tweepy), with rate-limit aware backoff, deduplication, and retry logic
- Review Aggregation: Scrapes and normalizes Trustpilot reviews (Selenium + BeautifulSoup) and applies zero-shot classification using BART (
bart-large-mnli) to extract issues, churn risk, and sentiment - Historical Trending: Tracks sentiment evolution and topic prevalence with time-windowed aggregates and visualizations
🎯 AI-Powered Call Transcript Analysis
- Processes hundreds of customer service call transcripts using Google's Gemini 2.5 Flash with schema-constrained JSON outputs
- Generates three key metrics for each call:
- Sentiment Label: Positive, Neutral, Negative, or Mixed
- Sentiment Score: Continuous scale from -1.0 (very negative) to 1.0 (very positive)
- CSAT Prediction: Customer satisfaction score (1–5) based on interaction quality
- This data is mapped to categories/functional areas for operational visibility
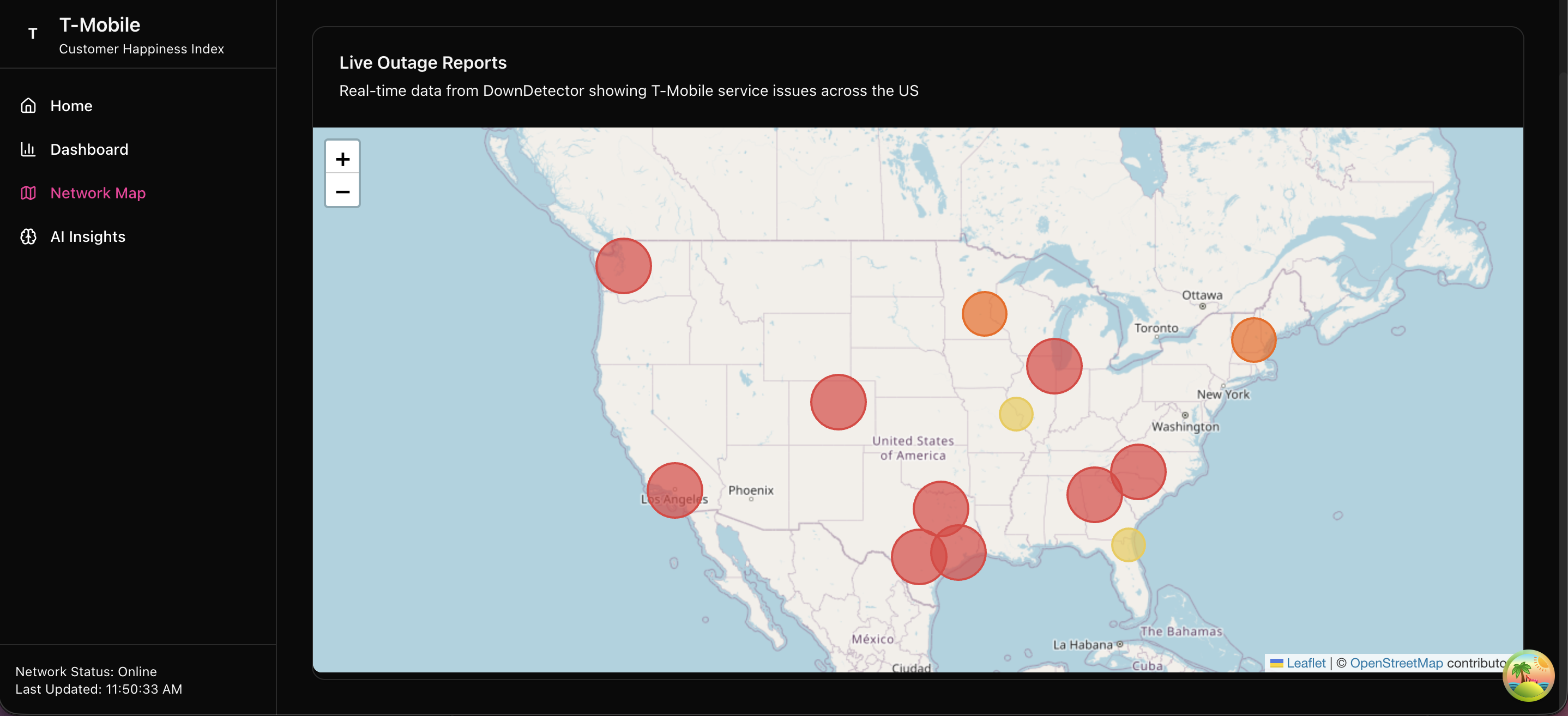
🗺️ Network Outage Intelligence
- Real-time outage detection via DownDetector headless scraping (with explicit waits and pagination)
- Geographic enrichment and mapping of disruptions
- Priority queue for critical incidents, with freshness guards and cached snapshots
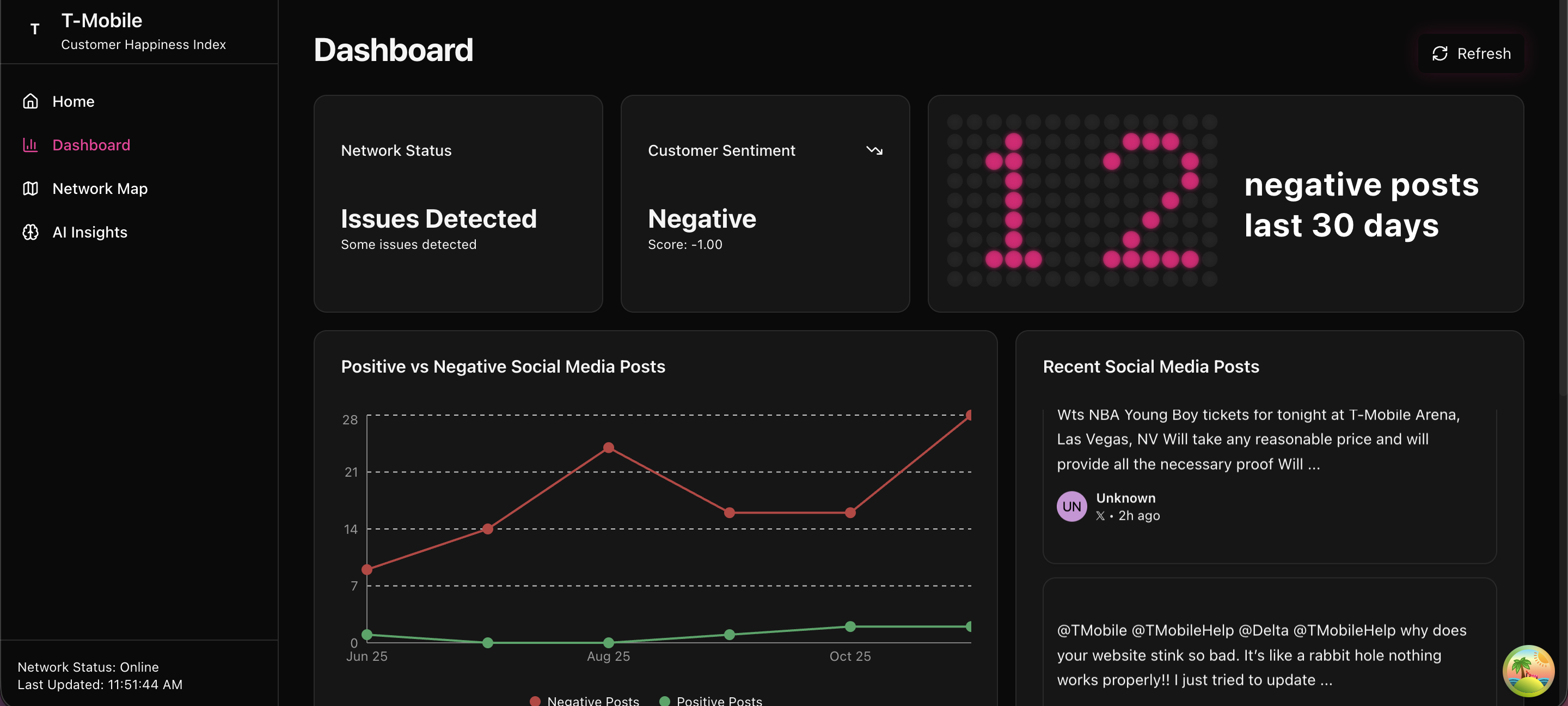
📈 Executive Dashboard
- Unified view across Reddit, X/Twitter, Trustpilot, DownDetector, and call transcripts
- Cycling stats matrix and real-time feeds for at-a-glance metrics
- Trend analysis and predictive insights
- TanStack Query caching for fast rendering, background refetch, tuned stale windows, and minimal API load
🏗️ How We Built It
Architecture
We architected a modern, scalable full-stack application with clear separation of concerns:
Frontend (React + TypeScript + Vite)
- Framework: React 18 with TypeScript for type safety
- UI Library: ShadCN + Tailwind CSS with Lucide Icons and T‑Mobile theming
- State Management: TanStack Query with hierarchical query keys, 30-minute
staleTimefor expensive insights, 1-hourgcTime, background refetch, and exponential backoff - Charting: Recharts with animated, responsive visualizations
- Real-time Updates: Stale-while-revalidate and optimistic UI with granular loading/error states
Backend (Python 3.12 + FastAPI)
- API Framework: FastAPI with async endpoints and CORS
- Data Processing: Pandas and NumPy for normalization, aggregation, and time-series stats
- AI Integration: Google Gemini (google-genai SDK) for transcript scoring with strict schema validation
- Web Scraping & APIs:
- Trustpilot (Selenium + BeautifulSoup) for dynamic content and pagination
- DownDetector headless scraping with time-based cache invalidation (e.g., 24h)
- Reddit (PRAW) and X/Twitter (Tweepy) with automatic backoff and retries (Tenacity)
AI/ML Pipeline
- Zero-Shot Reviews: BART
bart-large-mnlifor multi-label issue classification and churn risk without training - LLM Transcripts: Gemini 2.5 Flash with schema-constrained outputs for reliable parsing
- Batch Processing: Handles 500+ transcripts with progress tracking, resume capability, and defensive parsing
- Accuracy Metrics: Scikit-learn for MAE, RMSE, correlation, confusion matrices, and within‑1 CSAT accuracy
DevOps
- Git + GitHub; environment variables (.env)
- Tenacity-backed retry strategies with jitter to avoid thundering herd
- Time-windowed caches and explicit invalidation triggers
Key Technical Decisions
Modular Architecture
- Separated concerns across ingestion, analysis, and delivery layers
- Environment-driven config for keys, thresholds, and cache windows
- Pluggable data sources (new subreddits, carriers, or review sites) with minimal changes
Real-Time First + Intelligent Caching
- TanStack Query for server state with per-endpoint
staleTime/gcTimeand background refetch - Optimistic UI and SWR patterns for instant-first experiences
- Exponential backoff and bounded retries to respect Reddit/X rate limits and scraper variability
- TanStack Query for server state with per-endpoint
💡 What We Learned
Technical Mastery
1. The Nuances of LLM + Zero‑Shot Integration
- Schema-constrained prompts improved reliable parsing for transcripts
- Threshold tuning for BART balanced recall/precision on multi-label reviews
- Backoff and pacing kept us within Reddit/X rate limits under bursty loads
2. Data Pipeline Engineering
- Hybrid ingestion: Combining APIs (Reddit/X) with dynamic scraping (Trustpilot/DownDetector) required robust normalization
- Batching patterns: Progress tracking and error isolation prevented cascade failures
- Caching strategy: Time-windowed caches reduced calls while preserving freshness and UI responsiveness
Domain Insights
Understanding Customer Service Metrics
- CSAT vs. Sentiment: Not always correlated—quick resolution can yield high CSAT even with neutral sentiment
- Resolution over politeness: Efficiency matters most
- First-response time strongly correlates with satisfaction
The Power of Multi-Channel Analysis
- Social media sentiment leads support tickets by 24–48 hours
- Reddit discussions predict outage-related call spikes
- Trustpilot long-form reviews surface systemic issues missed in short-form channels
🚧 Challenges We Faced
Challenge 1: Sourcing Social and Outage Signals Reliably
Problem: Fragmented data access—Reddit/X APIs with strict rate limits and pagination; DownDetector without an official API and dynamic, JavaScript-rendered pages; plus the need for historical backfill and timezone alignment.
Solution: Built API-first ingestion with PRAW/Tweepy using query filters, idempotent deduplication (ID- and hash-based), and Tenacity-backed exponential backoff. Implemented headless Selenium with explicit waits for DownDetector, plus 24h time-based cache snapshots and normalized timestamps.
Result: Stable, rate-limit-safe ingest across channels with consistent time series for trends and correlation.
Challenge 2: Zero‑Shot Model Selection and Calibration
Problem: Choosing a zero-shot model with the right latency/accuracy tradeoff, handling multi-label independence, truncation for long reviews, and threshold calibration for churn vs. issue tags.
Solution: Selected bart-large-mnli, engineered label phrasing, applied 512‑token truncation, enabled batched inference, and tuned thresholds (e.g., 0.3) against validation metrics.
Result: High-quality multi-label classification (≈85–95%) and strong churn detection (~95%), with predictable throughput on CPU.
Challenge 3: Multi-Source Frontend State Management
Problem: Four sources (Reddit, X, Outages, Transcripts) with different refresh cadences created loading/error coordination challenges.
Solution: TanStack Query with independent keys, tuned staleTime/gcTime, background refetch, and bounded retries.
Result: Snappy UI, minimal redundant fetches, and resilient behavior under partial failures.
🎯 What's Next
Immediate Enhancements
- Predictive Alerts: Forecast call volume spikes from social/outage deltas
- Agent Coaching: Mine high-performing transcript patterns for training
Advanced Features
- Multi-Language Support: Spanish transcript analysis
- Competitive Intelligence: Benchmark sentiment vs. Verizon/AT&T
🏆 Accomplishments We're Proud Of
- End-to-End AI Pipeline: BART zero-shot for reviews + Gemini transcripts, validated with MAE/RMSE/correlation
- Multi-Source Intelligence: Reddit, X/Twitter, Trustpilot, and DownDetector unified with consistent schemas
- Production-Grade Caching: TanStack Query with background refetch, exponential backoff, and tuned stale windows
- Resilient Scraping: Selenium + BeautifulSoup for dynamic content with pagination and anti-detection tactics
- Beautiful UI: ShadCN + Tailwind, responsive, accessible, and on-brand
- Operational Robustness: Retry policies, cache invalidation, and resumable batches
- Speed: Hundreds of transcripts processed quickly with non-blocking updates
💬 The Impact
This platform transforms how T-Mobile can understand its customers. Instead of reacting to issues days or weeks later through aggregated reports, teams can:
- Spot trends in real-time across all channels
- Proactively address emerging issues before they go viral
- Coach agents more effectively with data-driven insights
- Predict and prevent escalations using sentiment and outage signals
- Measure what matters with automated CSAT and robust validation
We built this in 24 hours. Imagine what it could become with more time.
Built with ❤️ at HackUTD 2025 (Lost In The Pages)
Built With
- beautiful-soup
- fastapi
- gemini-2.5-flash
- numpy
- pandas
- praw
- python
- react
- scikit-learn
- shadcn
- tailwind-css
- tanstack-query
- tweepy
- typescript
- vite






Log in or sign up for Devpost to join the conversation.