-
-

cookie-oxide
-
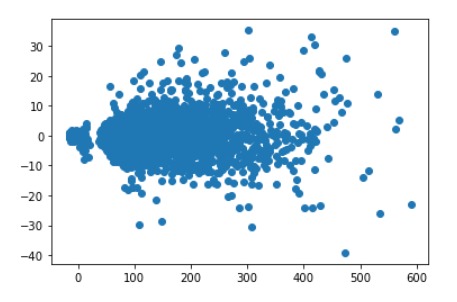
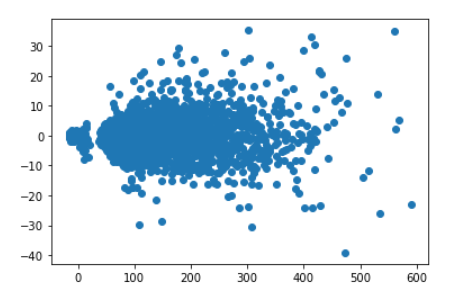
เปรียบเทียบค่าความคาดเคลื่อน(ผลต่างระหว่างความจริงกับผลการทำนาย) ต่อความจริง
-
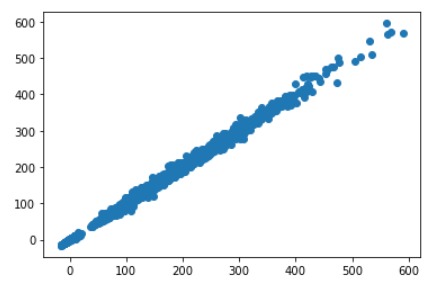
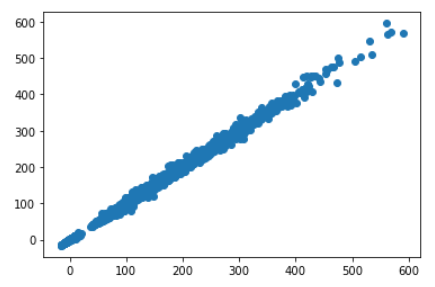
เปรียบเทียบค่าที่ทำนายได้ต่อความจริง

Inspiration
สวัสดีครับพวกเรามากันห้าคน ช่วยกันเทรนโมเดลด้วยสมองอันแยบยล มาTMLCCเพราะอยากลองฝีมือตน แม้ไม่มีความรู้แต่พวกเราก็สู้ทน ตอนสมัครเข้ามาพวกเราหวังเงินรางวัล พอเจอโจทย์เข้าจริงเหมือนพวกเรามาดึงดัน ต้องขอบคุณความรู้จากคุณพี่รังสิมันต์ กัดฟัน พัลวัน แล้วมาสู้ไปด้วยกัน!
What it does
โมเดลของเรา ใช้ Basic Models ต่างๆ ซึ่งประกอบด้วย Linear/PolynomialRegression, KNN,RandomForestและ NeuralNetwork มารวมกับ XGBoost เพื่อทำนายค่าความสามารถในการ กักเก็บแก๊สคาร์บอนไดออกไซด์ ของโครงข่ายโลหะอินทรีย์หรือMOFs
How we built it
ทีมเราใช้ภาษาPython3ในการสร้างโมเดล โดยใช้ไลบรารี่ดังต่อไปนี้ 1.XGBoost (สร้างโมเดลหลัก ด้วย XGBRegressor) 2.Sci-kit learn (สร้างโมเดลรอง เช่น KNN,SVM,LinearReg รวมถึงเอ็นโค้ด/สปลิทข้อมูล) 3.Tensorflow (สร้างโมเดลด้วยNeuralNetwork) 4.numpy (ทำงานเชิงลึกกับข้อมูลตัวเลข) 5.pandas (อ่านและจัดการข้อมูล) 6.matplotlib (พล๊อตกราฟเพื่อให้สามารถเข้าใจจ้อมูลได้มากขึ้น) เริ่มแรก พวกเราพยายามใช้ข้อมูลที่ทางTMLCCให้มาอย่างเป็นประโยชน์ที่สุด โดยการดึงข้อมูลมาให้มากที่สุดเท่าที่จะทำได้ โดยจะดึงข้อมูล โครงสร้าง เช่น ความยาวและค่ามุม จากไฟล์ CIF แล้วยังนำไฟล์CIFมาแปลงเป็นXYZเพื่อดึงข้อมูลอะตอมเพิ่มเติม นอกจากนี้ เรายังดึงข้อมูลอะตอมของLinkerต่างๆ จาก ไฟล์Linker.XYZ ที่มีมาให้ ซึ่งเรายังสนใจจำนวนของอะตอมบางตัว คืออะตอมที่ปรากฎอยู่ในทุกๆโมเลกุล ได้แก่ C,O และ H เป็นต้น หลังจากนั้น จึงมาทำการซ่อมดาต้าที่เสีย เช่น ติด0,ติดลบ,หรือติดNaN โดยการใช้RandomForestในการทำนายค่าเหล่านั้น เมื่อเสร็จขั้นตอนนี้ เราจะใช้ประโยชน์สูงสุด จากข้อมูลที่เราทำการดึงมาแล้ว โดยมีการสร้างฟีเจอร์เพิ่มเติมที่เกิดจากการนำฟีเจอร์อื่นๆ มาคำณวนกัน เช่น ความหนาแน่น = มวล/ปริมาตร และ จำนวนอะตอมอื่น = จำนวนอะตอมทั้งหมด-จำนวนอะตอมC+O+H และมีการดัดแปลงข้อมูล เช่นการ One-Hot Encoding ให้กับ Topology, MetalLinker, OrganicLinker และ FuntionalGroups และนำมาสร้างเป็นโมเดล ซึ่งเกิดจากBasicModels หลายๆตัวรวมกัน คือ ใช้PolynomialReg,KNN,RandomForest ในการทำนายค่าCO2 Working Capacity ก่อนตามลำดับ และนำค่าที่ทำนายได้ ไปใช้ในเป็นฟีเจอร์ในการทำนายด้วยXGBoost ซึ่งทำให้ได้ผลลัพธ์ที่ดีกว่าการใช้โมเดลใดเพียงโมเดลเดียวอย่างมาก
Challenges we ran into
เนื่องจากพวกเราเป็นเพียงเด็กมัธยมที่มีความรู้เกี่ยวกับ Machine Learning น้อยมาก และไม่มีความรู้เกี่ยวกับMOFsเลย จึงมีข้อจำกัดอย่างมากในการทำความสะอาดและคัดเลือกข้อมูล รวมถึงการนำข้อมูลมาเทรนโมเดล
Accomplishments that we're proud of
สิ่งที่เราภูมิใจมากที่สุดในการแข่งขันครั้งนี้ คือการที่เด็กมัธยมอย่างเราๆ ที่มีพื้นฐานทางด้านAIและเคมีน้อยมากๆ สามารถ ศึกษาข้อมูลและสร้างโมเดลMachineLearningที่มีประสิทธิภาพค่อนข้างดีได้ แม้จะไม่ใช่โมเดลที่ดีที่สุด หรือแม้จะมีบางอย่างที่อาจจะทำผิดพลาดไปบ้าง แต่ผลลัพธฺ์ที่ออกมาก็เกินความคาดหมาย และเป็นความภูมิใจของพวกเราทุกคน
What we learned
ได้เรียนรู้การจัดการข้อมูลและการใช้ไลบรารี่เกี่ยวกับ MachineLearning มากขึ้น โดยก่อนหน้านี้เรามีความรู้เกี่ยวกับ AI และ MOFs น้อยมาก แต่หลังได้ผ่านการอบรมและได้ลอง ทำงานกับสิ่งเหล่านี้เป็นเวลา1เดือนเต็มแล้ว ก็เหมือนได้ทำความรู้จักสร้างความสนิทคุ้นเคยกับศาสตร์ของ AI,MachineLearning และ MOFs มากขึ้นอย่างมาก
What's next for cookie-oxide
TMLCC2022
Built With
- deepnote
- numpy
- pandas
- python
- scikit-learn
- tensorflow
- xgboost











Log in or sign up for Devpost to join the conversation.