-
-

Upload page
-
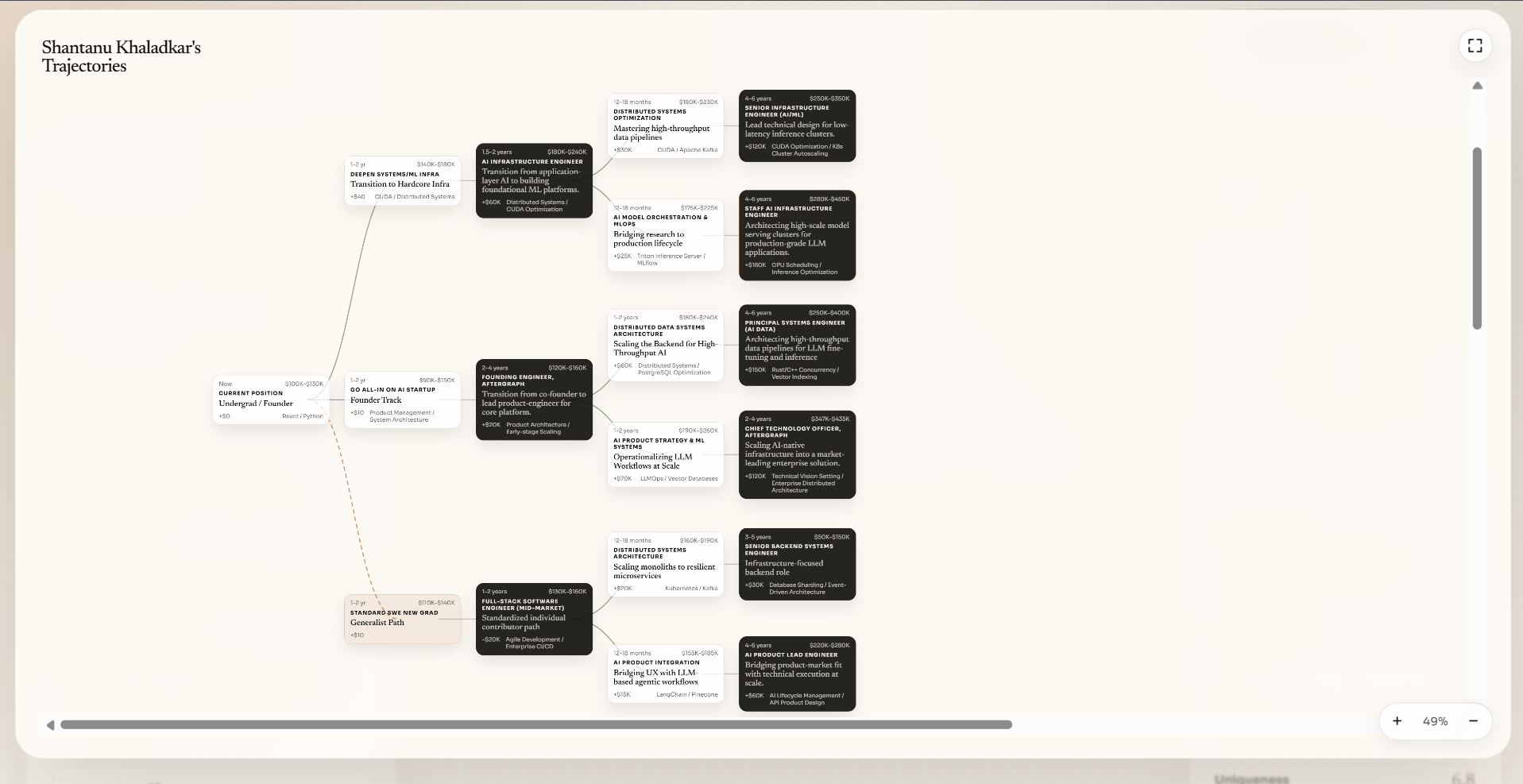
Future tree expanded
-
Job listing details
-
GitHub analysis
Inspiration
Career planning is one of the most consequential decisions people in any community face, yet the tools available are surprisingly poor. Job seekers upload a resume to a portal, get a list of openings, and are left to guess which paths actually fit their trajectory. We wanted to answer a harder question: given who you are today, what are the realistic futures you could reach, and what would it take to get there? The idea was to turn a static document into a living, branching map of possibility -- something that makes the invisible structure of career mobility visible.
What it does
AfterGraph takes an uploaded resume (PDF, DOCX, or plain text) and produces a multi-layered career analysis:
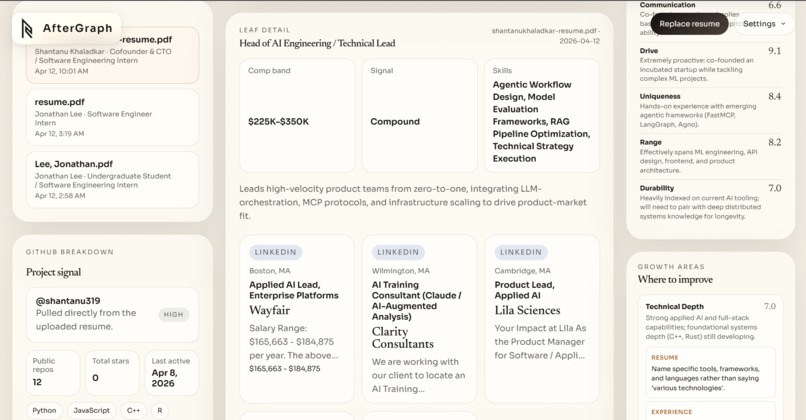
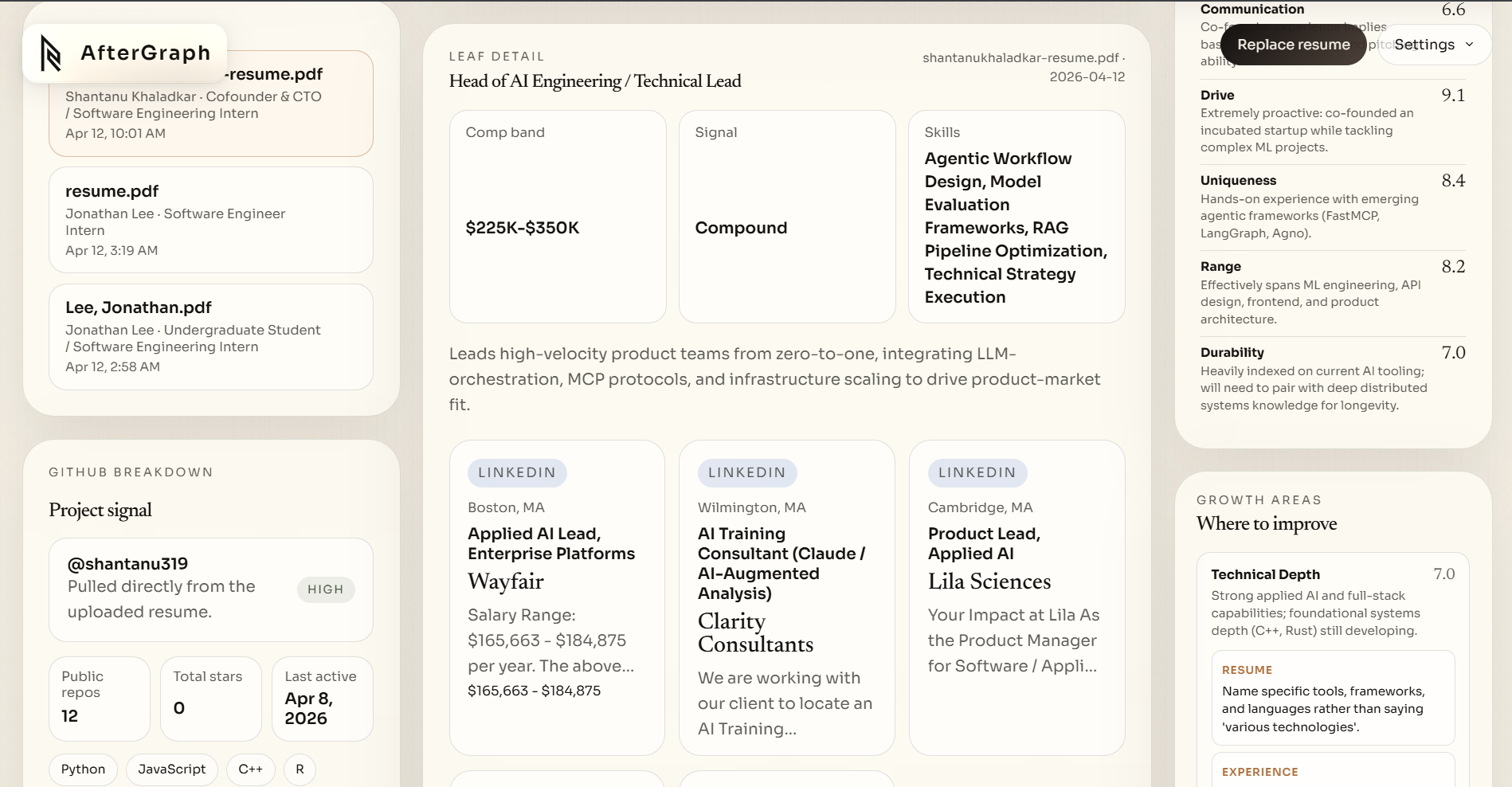
- Profile extraction. It parses the resume text, pulls out highlights, strengths, and focus areas, and builds a candidate profile with a sharp analytical narrative.
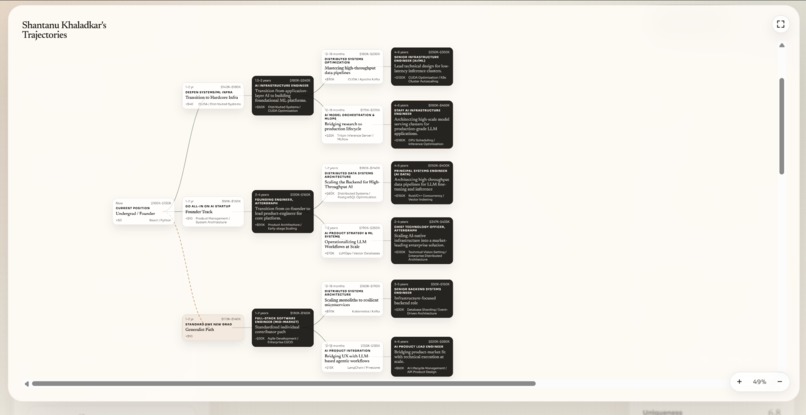
- Career tree. It generates an interactive branching tree of future career nodes -- starting from the user's present position, expanding through skill investments and role transitions out to depth 4. Each node includes salary bands, timeframes, and a delta signal indicating upward trajectory or stagnation. A "hold" branch explicitly models what happens if the candidate stays put.
- Skill radar. Six dimensions -- technical depth, communication, drive, uniqueness, range, and durability -- are scored on a $[0, 10]$ scale and rendered as an animated orbital chart. Each dimension comes with a specific insight and actionable growth tips.
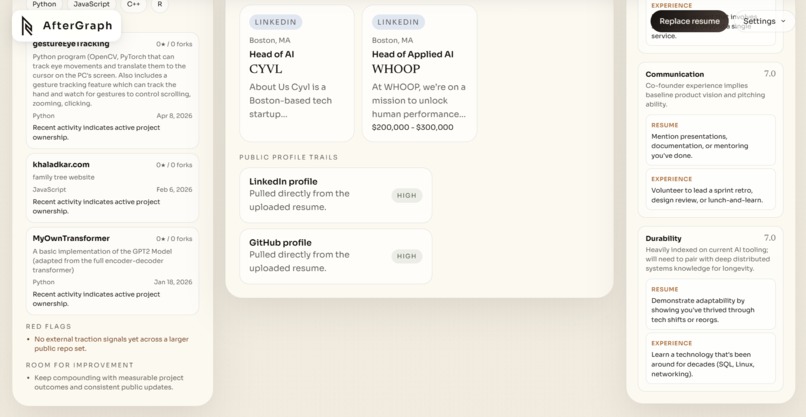
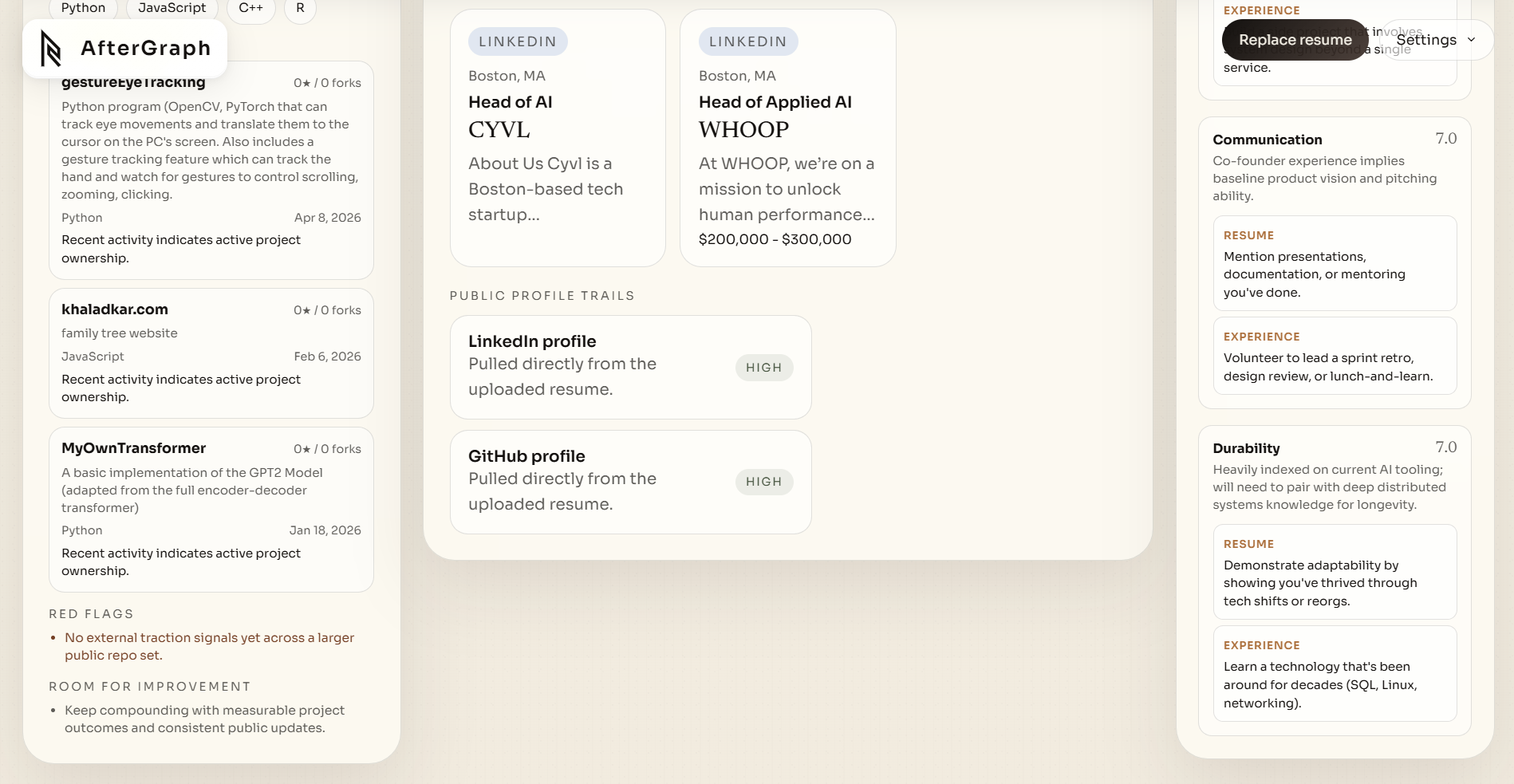
- GitHub portfolio audit. If a GitHub link is found on the resume (or inferred via search), AfterGraph hits the GitHub API, ranks repositories by a composite strength score $S = 2.5s + 1.2f + b_r + b_d - p_i - p_a$ (where $s$ = stars, $f$ = forks, $b_r$ = recency boost, $b_d$ = description boost, $p_i$ = issue penalty, $p_a$ = archive penalty), surfaces the top projects, and flags red flags like stale repos or fork-heavy portfolios.
- Live job listings. Career nodes are enriched with real job postings scraped from LinkedIn's public guest API, giving each branch of the tree concrete, current openings.
- Persistence. Users get a local account ID, and their resume analyses are stored in Supabase (with a local JSON fallback), so they can return, compare resumes over time, and track how their profile evolves.
How we built it
The frontend is a React 19 single-page app built with Vite, using no component library -- every panel, the orbital skill chart, the interactive tree layout, and the drag-to-pan career visualization are hand-rolled SVG and CSS. The backend is an Express 5 server written in TypeScript, running on Node via tsx.
The core analysis pipeline is a streaming NDJSON architecture. When a resume is uploaded:
- The server extracts text using
pdf-parse(for PDFs) ormammoth(for DOCX), with a supplemental URL extraction pass that handles OCR artifacts, Unicode escapes, and obfuscated hyperlinks. - Call 1 hits Gemini 3.1 Pro Preview with the full resume text and a set of benchmark profiles (real resumes from people who landed roles at Citadel, OpenAI, and SpaceX) to calibrate scoring. This returns the profile, skill dimensions, narrative, and depth 0-1 tree nodes.
- Calls 2-N use Gemini 3.1 Flash Lite to expand the tree depth-by-depth. At each depth, all frontier nodes are expanded in parallel via
Promise.allSettled. The client receives streamed node batches and renders loading placeholders that resolve into real nodes with animation. - Concurrently, the GitHub overview and LinkedIn job search run in parallel with tree expansion, so the total latency is the max of the slowest branch rather than the sum.
Data is persisted to Supabase with a service-role client, falling back to a local .data/ JSON store when credentials are unavailable.
Challenges we ran into
Resume parsing fidelity. PDF text extraction is notoriously unreliable. URLs embedded in resumes were broken by OCR artifacts, Unicode escape sequences (\u0068\u0074\u0074\u0070), fullwidth characters, and zero-width joiners. We had to build a normalization pipeline that handles NFKC normalization, slash-escape decoding, percent-encoded dots, and even space-stripped fallback matching for OCR that inserts whitespace inside URLs.
Structured output from LLMs. Even with responseMimeType: "application/json", Gemini occasionally returned markdown-wrapped JSON, nested wrapper objects, or arrays when we expected objects. We had to write fallback parsing that unwraps code fences and single-key wrappers, plus runtime validation for every field.
Streaming tree expansion. Getting the NDJSON streaming pipeline right -- where the client renders partial trees with loading placeholders that get replaced by real nodes at each depth -- required careful state management. Race conditions between streamed events and React re-renders caused ghost nodes and orphaned placeholders until we tracked loading node IDs as explicit state.
LinkedIn rate limiting. The public LinkedIn jobs guest API is aggressive about rate limiting. We implemented staggered delays, per-node retries, and a concurrent job search service that runs in the background while the tree is still expanding, but tuning the timing to stay under limits while keeping latency acceptable was a constant balancing act.
Accomplishments that we're proud of
- The streaming architecture means users see their career tree grow in real time rather than staring at a spinner for 15 seconds. The initial profile appears within a few seconds, and branches fill in progressively.
- The skill orbit visualization is entirely hand-built SVG with staggered cubic-ease animations and deterministic seeded jitter, so the same resume always produces the same visual fingerprint.
- The GitHub portfolio audit is a genuine signal -- it calculates a composite repo strength score, identifies red flags, and generates improvement recommendations, which is more useful than just listing repos.
- Benchmark-calibrated scoring. By embedding real elite resumes into the prompt, the skill scores are grounded against actual top-tier profiles rather than being inflated by default LLM positivity.
- The entire app -- frontend, backend, resume parsing, LLM orchestration, GitHub integration, job scraping, and persistence -- was built from scratch during the hackathon with zero UI libraries.
What we learned
- LLM orchestration is an engineering problem, not a prompting problem. The hard part was not writing prompts; it was building a reliable streaming pipeline that handles partial failures, validates structured output at every stage, and degrades gracefully to deterministic fallbacks when any call fails.
- Resume text is adversarial input. Between PDF encoding quirks, Unicode normalization issues, and OCR artifacts, extracting clean structured data from resumes required more defensive code than the entire LLM integration.
- Parallel-by-default changes the architecture. Running GitHub lookup, tree expansion, and job search concurrently rather than sequentially cut perceived latency dramatically, but it forced us to think about every piece of state as eventually-consistent rather than sequentially-built.
- Benchmarking matters for LLM scoring. Without the benchmark profiles, Gemini defaulted to giving everyone 7-8/10 on every dimension. Anchoring against real elite profiles forced honest, differentiated scoring.
What's next for AfterGraph
- Multi-resume diffing. Let users upload multiple versions of their resume over time and visualize how their career tree, skill scores, and salary projections shift as they gain experience or pivot.
- Community aggregation. Aggregate anonymized career trees across a campus or community to surface which skill investments yield the highest real-world returns for people with similar starting profiles.
- Interactive path editing. Let users prune or extend branches of their career tree manually, then re-run the analysis with those constraints to explore "what if I pursued this instead" scenarios.
- Richer job matching. Move beyond LinkedIn scraping to integrate structured job board APIs, and use the career tree nodes to rank openings by alignment with each specific branch rather than generic keyword matching.
Built With
- express.js
- github-api
- google-gemini-api
- linkedin-jobs-api
- node.js
- pdf-parse
- react
- supabase
- typescript
- vite

Log in or sign up for Devpost to join the conversation.