-

Graph example
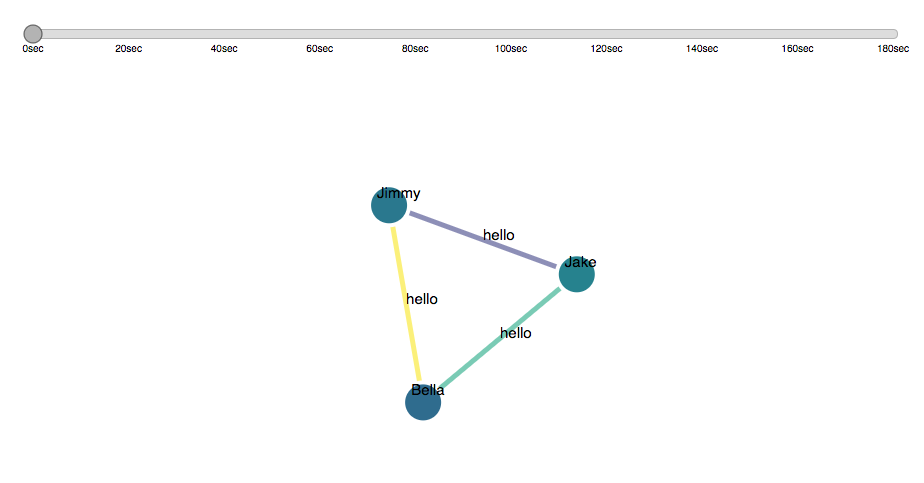
Inspiration
We went to the Microsoft Cognitive Services workshop, and we were inspired by all of the available tools and resources. Audio and language seemed to go well together, so we decided to try and analyze a recording of a conversation.
What it does
Uses the recording of a conversation as well as training recordings from participants to create a network diagram of conversational interactions and emotional analyses among speakers. It serves as a visual representation of the sentiments shared among people in actual spoken dialogue. We hope it would be of use for professional, educational, and research environments.
How we built it
The program was written in python, with intent to host on Azure with Flask. The visualizations were written in javascript with D3, a powerful data-driven documents library. Audio files were collected from youtube, and edited to fit length requirements.
- The file receives a recording of a conversation as well as 30-second training samples for each speaker.
- The recording is split into pieces by silence using the pydub python package.
- The training samples are used to train a Microsoft Speaker Recognition API.
- The pieces are then individually input into the API to recognize their speaker.
- The pieces are also input into the Google Cloud Platform Speech Recognition API to convert them to text.
- The text pieces are input into the Microsoft Text Analysis Sentiment API to receive sentiment interpretation.
- The values are compiled into a JSON and sent to the frontend.
- The frontend parses the JSON with D3.js and creates a dynamic representation.
Challenges we ran into
Some of the problems we ran into were developing a server to host our hack, unreliable API server connections, the steep D3 learning curve, and the processing speed involved with training data and identification data quality.
Accomplishments that we're proud of
We were able to harness a variety of powerful and exciting APIs: we used text-to-speech, sentiment analysis and more in our project. We additionally used D3 to create a beautiful interactive visualization and almost got a web server front-end running.
All of us dove into totally new technologies and learned a lot in the space of 36 hours. We challenged ourselves with steep learning curves and a broad vision. We coded continuously for more than 24 hours.
What we learned
We had to get very familiar with advanced JavaScript to create our visualization and front-end, as well as Python to develop our algorithm and back-end.
Working with a number of APIs required a lot of trouble-shooting and working with documentation, which are valuable skills to rehearse. The sheer number of developer tools we learned about online is pretty impressive.
What's next for Convograph
The incomplete web server component allows users to submit clips of their voices to train the recognition service and conversation clips for analysis and visualization. We were very close to completing this -- sound clip submission and POSTing is functional! Our most immediate step would be to finish the last missing link and finish the connection between the web server and the backend.
We also had a wealth of data -- more than we had time to visualize -- and wanted to display a number of other visualizations presenting different aspects of the conversation and its participants.
Built With
- azure
- d3.js
- google-cloud
- javascript
- jquery
- microsoft-cognitive
- python

Log in or sign up for Devpost to join the conversation.