-
-
User Interface for Scryber
-

Project Logo
-

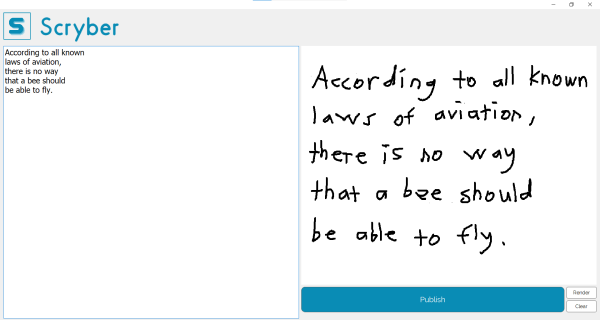
Scryber Example

Inspiration
Having to read handwritten notes can be difficult as individuals all have distinct writing styles. Whether it's borrowing a friend's notes or simply trying to interpret a teacher's messy handwriting, an interpreter system would make everyone's lives easier.
What it does
Scryber implements a machine learning model (Tesseract OCR) to identify characters and letters. Users can handwrite text into Scryber, using either a stylus or their mouse. The program will then take the line of handwritten text and converts it to digitized form. If the program made any interpreting mistakes, Scryber allows the user to edit the text, fixing any errors involved. Users can then export the text as a .txt file.
How we built it
We first started off by trying to train a machine learning model to identify characters and symbols and converting these to LaTeX; however, we soon realized that creating and training a brand-new, highly complex machine learning model simply wasn't feasible given the time constraints. Instead, we opted to use the open-source Tesseract optical character recognition engine. We built around Tesseract by developing a backend script that converts user-written data into images --- each image is converted into a tensor. Tesseract takes the tensor and gives a prediction of the letter/character, outputting it. Through a combination of PyQt5 and CSS, an interactive window is created which allows the user to input handwriting, which is then interpreted by Tesseract and can be exported into a file.
Challenges we ran into
Throughout the course of development, we experienced multiple setbacks. The primary challenge was working around the failure of our original machine learning model, which was primarily designed for mathematical symbols. While we expected, in theory, for the network to function properly, it failed when put to test on a sample data set, being unable to reach an acceptable accuracy. Through a series of rapidly made decisions, the team improvised on our original idea, deciding to opt for an existing engine. As a result, the direction of the project changed; our focus shifted from creating a model to implementation.
Accomplishments that we're proud of
As a team, we are proud of our ideation, creation and successful implementation of a fully functioning project within the short span of Hack The North. Despite serious setbacks, being forced to change directions midway through the event, we still managed to build upon existing ideas and develop a satisfactory project. The dedication and perseverance of our team members shone through, applying ourselves to the refinement of our UI and development in both the front-end and back-end. For our first hackathon, we're very proud of ourselves.
What we learned
In the past 36 hours, our team explored new facets of coding such as developing a machine learning model, GUI building in Python, and CSS styling. Furthermore, our experience with the failure of our initial plan taught us important lessons in time management and improvisation. We learned to stay on our toes, be flexible, and work cohesively as a team even when faced with tough decisions and difficult deadlines
What's next for Scryber
We want to work toward the initial goal of our project: the recognition of mathematical symbols and equations through a machine learning model and compilation into LaTeX. Although this task proved to be insurmountable for us in this short period of time, we hope to encounter future opportunities to train a better neural network and succeed in our original goal.

Log in or sign up for Devpost to join the conversation.