Inspiration
Our Contract Information Extractor website draws inspiration from the need to enhance the principles of accessibility and efficiency within the domain of legal procedures. A vast number of individuals and organizations find it extremely difficult to work with elaborate contract data in an efficient and effective manner, which could also present obstacles in the course of informed decision-making. We have devised a method to make the extraction and structuring of key information as painless as possible, enabling one to handle their legal documents with greater ease. Our goal is to provide a setting that is clear-cut, inclusion, and makes all users confident in their use of contracts.
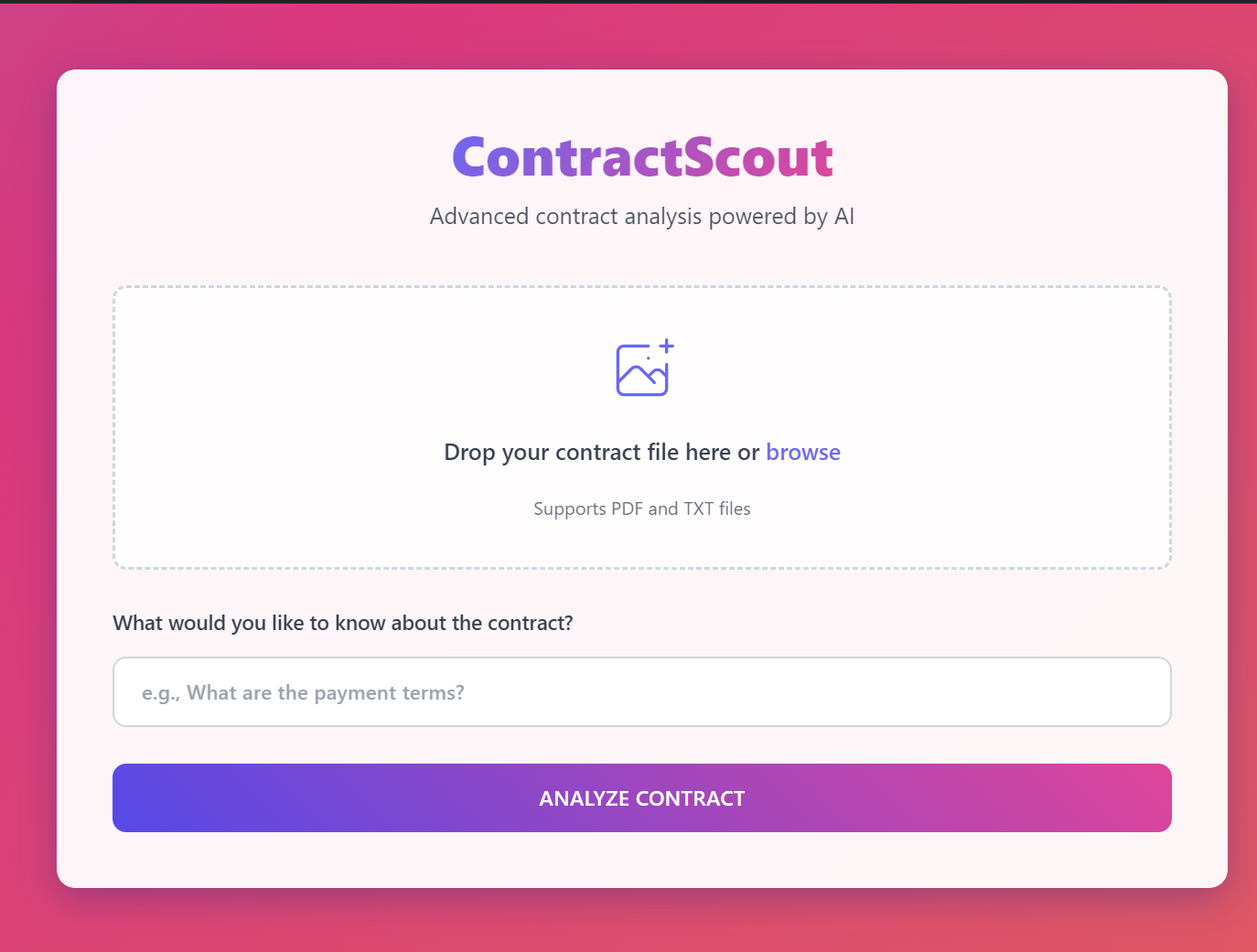
What it does
Our project is aimed at making legal documents more user-friendly by underlining the important sections that the users want to learn about. Furthermore, it locates misleading language or hidden clauses that might cause misunderstandings. This not only saves users from costly misinterpretations, but it is also an extremely useful alternative when representation will not be afforded, a great time- and headache-saver when trying to sort out complicated legal information.
How we built it
Tech Stack
- Python Backend
- HTML, CSS, and JavaScript Frontend
Simple Challenge
For this challenge we mainly focused on identifying if there were any inconsistencies in the code. We focused on identifying if there were duplicates within each individual datasets for both the train set and test set. We did this because having multiple of the same inputs could cause our model to have bias later on. Then we checked if there we duplications between the data sets. This could cause inaccurate accuracy estimation.
Medium Challenge
We tried testing the model on the new test dataset that we made and the normal test set from CUAD. We ran into many problems here because of issues with the model. More on that down below.
Higher Challenge
We made a web page with a HTML, CSS, and JavaScript frontend. The backend was Python and it handled the model and extracting information from the inputted document.
Challenges we ran into
We ran into many challenges like interpreting technical documentation, running the model, running into errors with instillation or processing, etc. During the simple challenge we were trying to implement a function that would use a heatmap to showcase our finding but it was incredible hard to interpret and the axis was getting messed up so we had to switch graphs. We also had trouble with getting some of the code to run because of the way the json file was formatted. We were able to troubleshoot through this. Next thing we ran into was the issue the model not running properly. We spent a lot of time reading about tokens, the HuggingFace docs, and learning but were not able to properly run it in time.
Accomplishments that we're proud of
- Designing UI/UX for the website of a contract information extractor was completed.
- Used appropriate machine learning models to benchmark our results by identifying similar points in data sets during our medium challenge.
- Gained insight into machine learning techniques and their applications.
- Developed a fully functional backend that supported the functionality of the website and its data processing.
What we learned
- Gained a deep understanding of machine learning concepts and their applications in data extraction.
- Enhancing teamwork and collaboration through effectively working with team members to attain project goals.
- Demonstrated problem-solving capabilities through overcoming problems with interpretation and extraction of data.
- Enhanced project management skills through the coordination of tasks and meeting respective milestones on time.
- Learned how to design user-friendly and visually appealing interfaces that enhance the overall user experience.
What's next for ContractScout
For the future we plan to write test and log to debug the issue we are running into right now. We also plan to include TDD into our coding process. We will also be adding a feature that will translate legalize to English so people can read complex sections

Log in or sign up for Devpost to join the conversation.