-
-
Start/login page
-
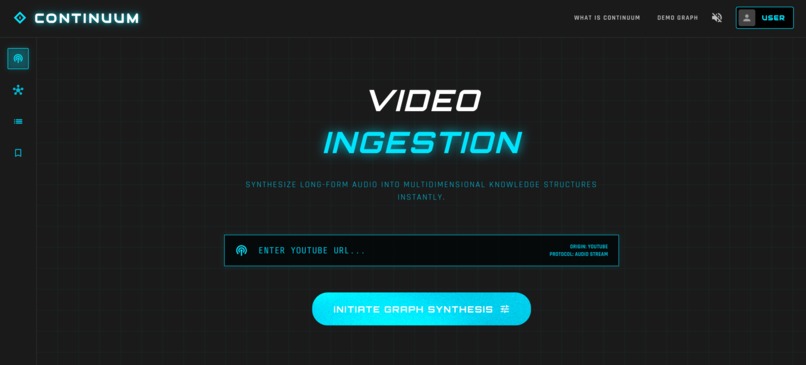
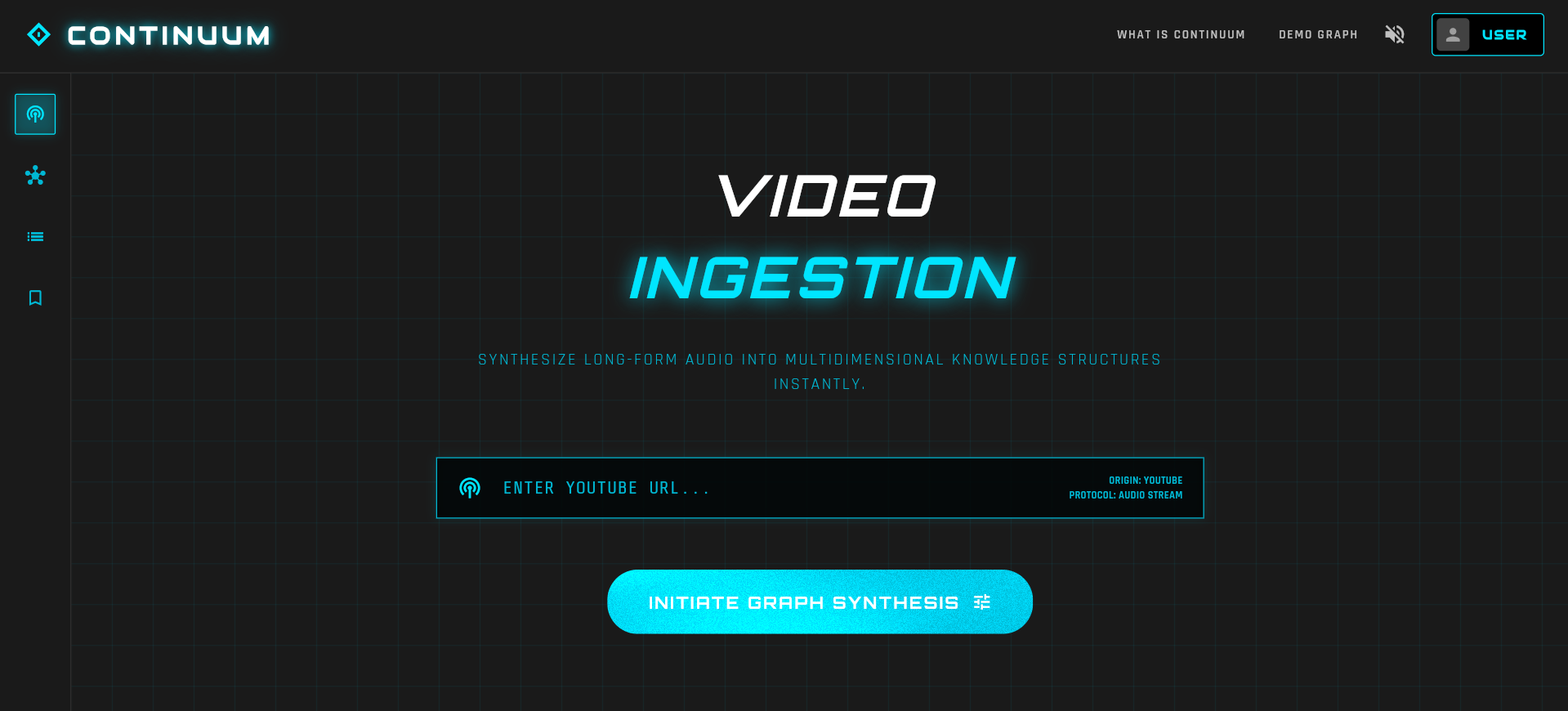
video ingestion page - just enter youtube url and see the agent build the nodes in real time
-
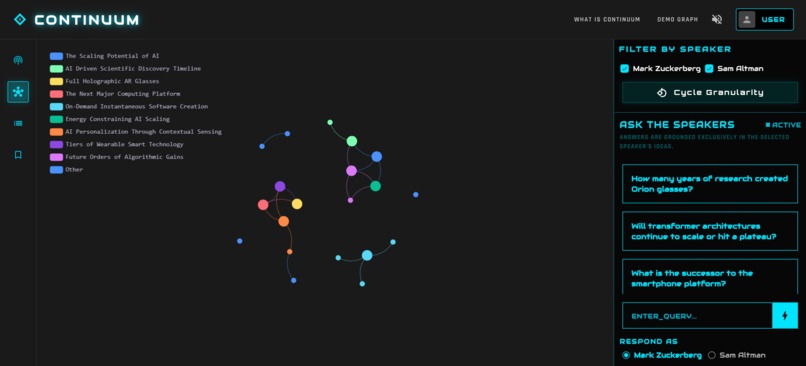
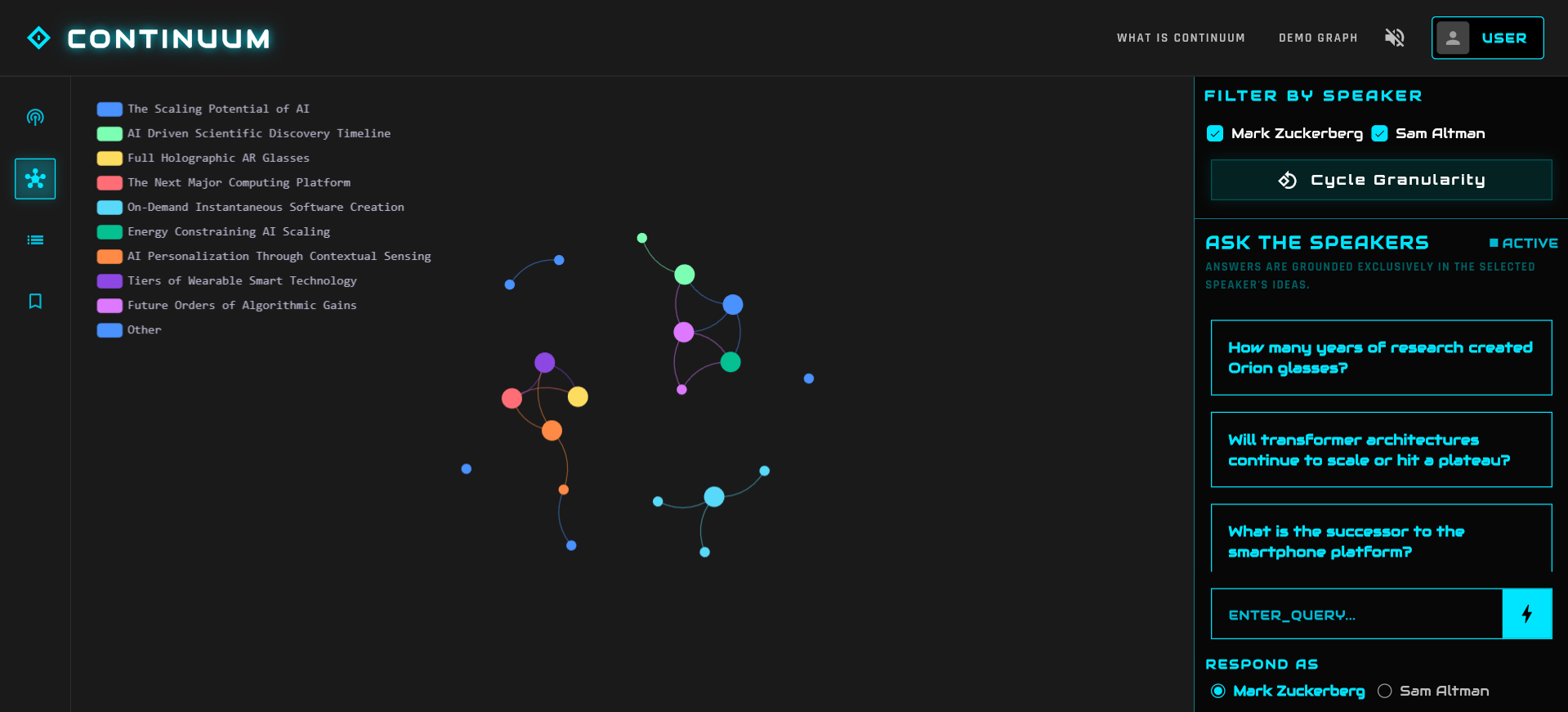
force-directed graph to explore the ideas
-
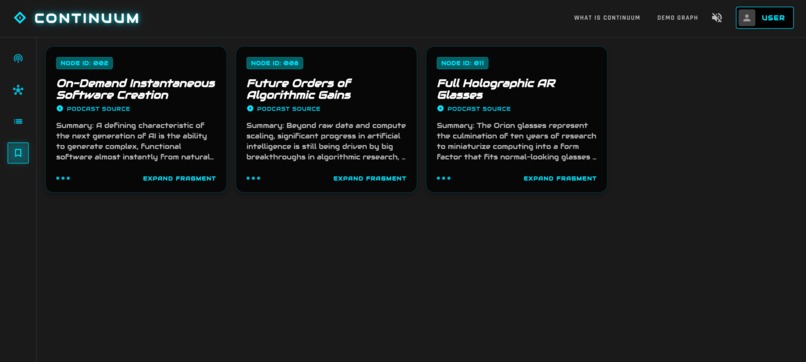
bookmarked nodes page
-
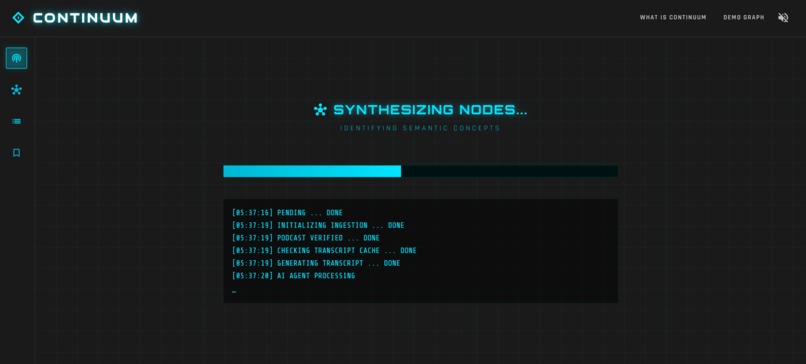
view the Agent's thought process as it build the nodes in real time
Inspiration
We all consume hours of long-form content every week—Lex Fridman podcasts, university lectures, deep-dive interviews. But 90% of that information evaporates the moment we stop listening. We remember that they talked about "dopamine" or "Post-Keynesian economics," but the nuance, the connections, and the specific arguments are lost.
Current AI tools fail us here. Chatbots have no long-term memory. Summarizers give us a shallow bulleted list. RAG (Retrieval Augmented Generation) often retrieves fragmented, out-of-context chunks.
We wanted to build something that reflects how humans actually learn: by connecting ideas. We wanted a system that doesn't just "process" a video, but understands it, remembers it forever, and helps us explore the web of connections between ideas over time.
What it does
Continuum is an agentic knowledge system that turns ephemeral YouTube videos into a persistent Knowledge Graph.
- Agentic Ingestion: You paste a YouTube URL. A background agent (powered by Gemini 3.0 Pro) watches the video, reads the transcript, and extracts atomic "semantic ideas" instead of just text chunks.
- Autonomous Curation: The Knowledge Curator Agent takes these ideas and actively "weaves" them into your existing graph. It checks for duplicates, resolves speaker identities (knowing that "Lex" is "Lex Fridman"), and creates semantic links to related concepts from videos you watched months ago.
- Visual Exploration: On the frontend, you get an interactive Force-Directed Graph. You can see how "Neuroscience" from Huberman connects to "AI Alignment" from Hinton. You can toggle granularity to see the big picture or dive into the weeds.
- Grounded Chat: You can ask questions like "What do a certain speaker think about the future of AGI?". The agent plans a path through the graph, gathers evidence, and constructs an answer with timestamped citations that jump directly to the exact second in the video.
How Continuum leverages Gemini 3.0
We utilized Gemini 3.0 Pro to build a truly autonomous knowledge curator. Here is how we used its specific features:
- Multimodal Reasoning: We pass the raw caption files as
application/jsonattachments directly to Gemini's multimodal interface. This allows the model to "see" the time-structure of the video, enabling it to extract exact second-level timestamps for every citation. - Semantic Embeddings & Link Processing: We use
gemini-embedding-001to vectorize every atomic idea. The agent uses these embeddings to perform semantic searches across the graph, autonomously identifying and creating meaningful links between concepts discussed in completely different videos. - Agentic Speaker Diarization: Leveraging the massive token context window, Gemini processes the entire video with transcript at once. It infers speaker identities from context and correctly attributes quotes throughout the episode, solving a problem that usually requires specialized audio models.
- Multi-Step Orchestration with Tools: We provide tools to the agent to interact with the knowledge graph. The agent autonomously decides when to use these tools to answer the user's question or generate/link new nodes. It uses Gemini's thought signatures behind the scenes to maintain its train of thought. We enable
enableThinking: trueto give our Knowledge Curator a "Stream of Consciousness". You can see it in action as it decides: "I found a node for 'Dopamine', but this video discusses it in the context of 'Addiction'. I should check if a link exists before creating a new node."
How we built it
Continuum is a full-stack Dart application, leveraging the power of Serverpod for a seamless end-to-end type-safe experience.
The Brain (AI & Logic):
- We used Gemini 3.0 Pro for its massive context window and reasoning capabilities.
- We implemented a Cognitive Architecture (Plan-Observe-Act loop) rather than a simple prompt chain. The agent has tools like
searchSimilarNodes,createGraphNode, andcheckSpeakerIdentity. - PostgreSQL + pgvector handles the storage and semantic similarity search.
The Backend:
- Built with Serverpod. It orchestrates the ingestion pipeline, manages the background jobs, and serves the graph data live to the client.
The Frontend:
- Built with Flutter.
- We used a custom integration of Graphify to create the high-performance force-directed layout.
- Riverpod handles the reactive state of the graph and chat sessions.
Challenges we ran into
- Speaker Diarization: Finding out who is speaking in a podcast is a hard problem. Gemini 3.0 Pro is very good at analyzing youtube videos and identifying speakers. We used it to extract the speaker information and store it in our knowledge graph.
- Exact Citations: Although Gemini 3.0 Pro is very good at analyzing youtube videos and identifying speakers, it is not very good at providing exact citations. We used multimodality of Gemini 3.0 Pro here to pass the transcript as a json file which helped provide accurate timestamps.
- The Infinite Loop of Curiosity: Early versions of our agent would get "distracted" by its own searches, endlessly traversing the graph without answering the user. We had to implement strict "Plan-Observe-Act" protocols to keep it focused.
- Defining "Same": Teaching an AI to decide if two ideas are "duplicates" or just "nuanced variations" is incredibly hard. We tuned our vector similarity thresholds and added an explicit reasoning step for the agent to justify its decision before merging nodes.
Accomplishments that we're proud of
- True Agentic Behavior: Seeing the backend logs where the agent says "I found a similar node regarding 'Dopamine', I will link to it instead of creating a duplicate" was a magic moment. It felt like the system was actually thinking.
- The "Wow" Factor: The graph visualization is not just a gimmick; it genuinely helps visualize the density of information in a podcast.
- Exact Citations: Providing exact citations for the video content is an achievement in itself. It helps users to verify the information and trust the system, and prevents manual scrubbing of videos to find the exact timestamp.
What we learned
- Agents need Tools, not just Prompts: Giving the LLM crisp, typed tools (via Serverpod) made it exponentially more reliable than asking it to output structured JSON directly.
- Context is King: Gemini 3.0 Pro's large context window allowed us to process entire podcast segments at once, preserving the narrative arc that is usually lost in standard RAG chunking.
What's next for Continuum
- Multi-Modal Ingestion: Support for PDFs, research papers, and technical documentation.
- Collaborative Graphs: Allow teams to build a shared "Brain" for their company or research group.
- Personalized Insights: An agent that wakes up and says, "Hey, this new video connects to that paper you read three weeks ago."




Log in or sign up for Devpost to join the conversation.