-
-
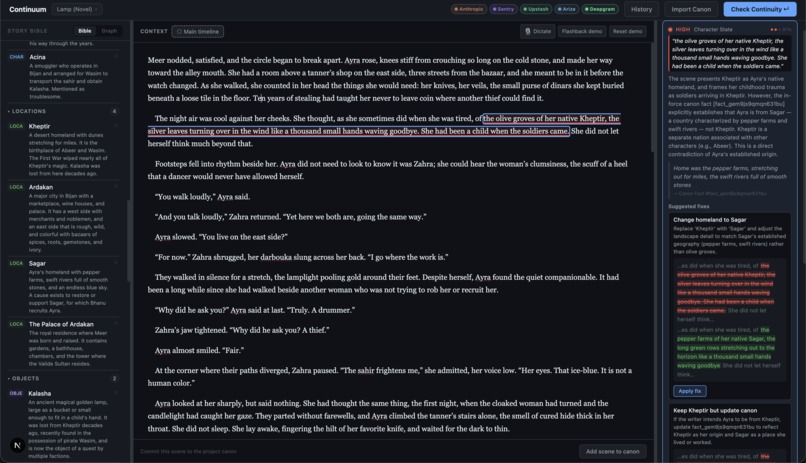
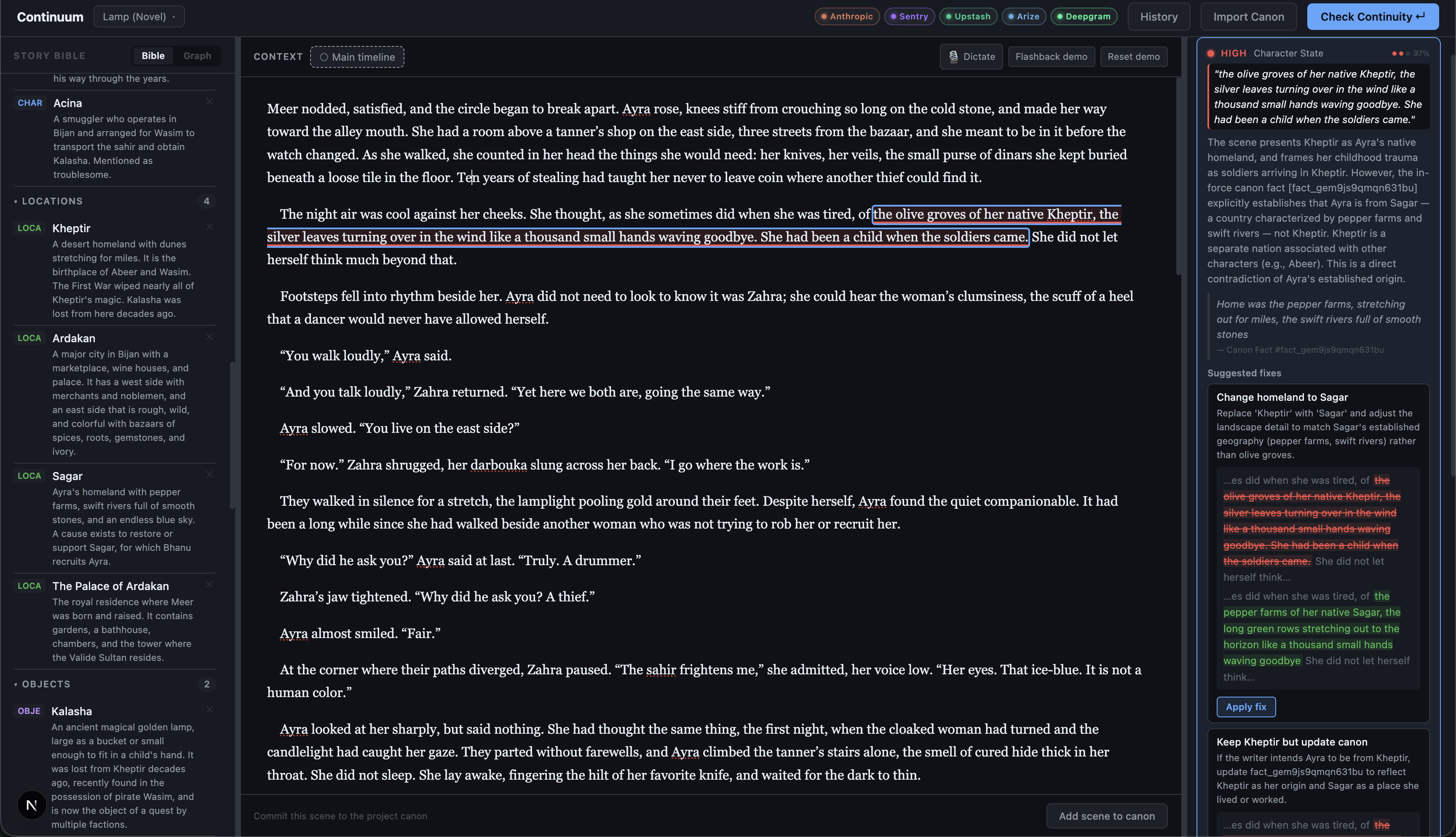
Demo on a new scene for Lamp, a novel authored by one of our team members. The agents work together to identify and flag contradictions.
Inspiration
Every long-running knowledge system is a giant pile of mutable state. Who's alive, who has the sword, who's at war, who knows the secret. Writers and show runners track it in bibles that rot the moment writing outpaces note-taking. Long-running AI agents have the same problem — they accumulate facts across sessions that drift, contradict, and branch with no one checking.
Generic AI makes it worse. It generates more content with no model of your established state. It'll happily write a one-handed knight gripping with both gauntlets and never notice.
We wanted to build something that doesn't generate — it checks. A tool that turns accumulated knowledge into queryable, verifiable state, then reads every new claim against it with evidence and a verified fix. Grammarly catches grammar. Continuum catches broken canon.
We picked fictional worlds as the proving ground deliberately. They have the most adversarial consistency problem: nonlinear timelines, branching paths, hidden knowledge, character state, world rules, knowledge asymmetry. If the engine works on Westeros, it works on AI agent memory and product specs. We proved it on the hardest case first.
What it does
Continuum is a live consistency engine for evolving knowledge systems, demoed on a preloaded Game of Thrones world.
Load a source of truth — upload notes, paste text, or use the preloaded GoT demo world. Write a new scene. Hit Check Continuity. Every phrase that contradicts established canon lights up inline, with the exact evidence quote it conflicts with, the severity, and a one-click fix that gets verified before it's applied.
The demo run:
Paste this into the editor on the main timeline:
"Jaime tightened the straps on both gauntlets before drawing his sword. He had ridden from Winterfell at first light and reached King's Landing by sunset. Over the capital, three dragons wheeled in formation — a sight every lord had grown up seeing. In the branch where Robb Stark survived the Twins, his mother Catelyn was already dead in the great hall."
Four high-severity contradictions surface in under 8 seconds, each with the canon evidence it breaks:
- "both gauntlets" → Jaime lost his right hand after capture
- "reached King's Landing by sunset" → Winterfell to King's Landing takes weeks
- "dragons wheeled … every lord had grown up seeing" → No living dragons existed until Daenerys hatched hers; no one grew up knowing them
- "Robb survived … Catelyn was already dead" → In the Robb-lives branch, Catelyn also survived
Then the smart part: flip the context chip to Flashback — before Jaime's capture
and type "Jaime caught the wine cup with both hands." Zero warnings. The
lost-hand fact isn't in force yet. The timeline visualization shows "you are here"
before the event and greys out the fact. The model never sees the conflicting fact
— the filtering happens in TypeScript before any LLM call.
Apply a fix: the repair agent patches the text, re-runs the check on the patched
span, and only returns verified ✓ if the original contradiction is gone with no
new issues introduced.
How we built it
The architecture bet: separate a platform-agnostic consistency engine
(lib/engine/checkScene.ts) from every UI surface. The engine has no Next.js
dependency. A browser extension, Google Docs add-on, or agent runtime calls the
same /api/check endpoint and gets back ContinuityIssue[]. Build the engine
once; bolt surfaces on.
The 2-call hot path (not agentic):
extractClaims(sceneText)— Claude Haiku extracts structuredClaim[]+inferredContextvia tool use. Fast, bounded, cheap.filterFacts(claims, position, branch)— pure TypeScript. EveryCanonFacthas two nullable validity event IDs. A scene's chronological positionp(resolved from context chips) filters to only facts in force:start ≤ p < end. The model never sees filtered-out facts. This is the false-positive killer — no temporal reasoning in the prompt.detectContradictions(claims, filteredFacts)— Claude Sonnet with extended thinking returnsContinuityIssue[]via structured tool output, validated through Zod. This is the reasoning step; extended thinking earns its cost here.mapSpans(issues, sceneText)— server maps model-returned verbatim quotes to character offsets viaindexOf+ whitespace-normalized fuzzy fallback. The model is never asked to produce offsets.
Two real agents:
The canon-builder agent (lib/agents/canonBuilder.ts) runs a tool-using loop
(up to 15 turns) converting raw text into structured entities, facts, events, and
branches via add_entity, add_fact, add_event, add_branch, and
search_existing_canon. It self-reviews validity windows and branch tags before
committing. Working memory lives in Redis across tool turns.
The repair verify-loop agent (lib/agents/repairVerify.ts) patches the scene
text, re-runs checkScene scoped to the patched span, and confirms the original
contradiction is resolved with no new high-severity issues before returning
verified: true.
The time model: integer event order + two nullable validity event IDs per fact.
No interval trees, no temporal logic solver. Main timeline → p = +∞. Flashback
before event X → p < order(X). Branch facts filter by branchId with per-claim
scoping when prose names an alternate branch inline.
TipTap (ProseMirror) handles inline decorations — contradiction spans get
colored underlines by severity, clickable to expand issue detail. A custom
decoration plugin reads ContinuityIssue[] from Zustand and maps plain-text
character offsets to ProseMirror positions.
Stack: Next.js 16 App Router · TypeScript · Tailwind v4 · TipTap · Zustand · Anthropic SDK (extended thinking) · Upstash Redis + Vector · Arize (OpenTelemetry) · Zod v4
Challenges we ran into
Branch scoping across a single detection call. When prose names an alternate branch inline ("in the branch where Robb survived…"), the claim needs to be checked against facts from that branch, not the scene-level branch. Running a separate detection call per claim was too slow. The solution: pass each claim with its applicable fact subset as a labeled block in one prompt — the model sees claims and their branch-filtered facts together, never mixed.
Span mapping without trusting the model. Asking Claude to return character
offsets is fragile — models hallucinate positions, especially across paragraph
boundaries. Instead we ask for the exact verbatim offending substring
(highlightedText) and locate it server-side with indexOf, falling back to
whitespace-normalized token matching. If a quote still isn't found, the issue
degrades to a card without a highlight rather than crashing.
TipTap decoration stability. ProseMirror positions shift as the user edits. We had to maintain a paragraph-offset table and remap plain-text character positions to ProseMirror positions on every check rather than caching them. Keeping the editor schema minimal (paragraphs + text, no nested marks) made this tractable.
Zod v4 + tool use. Zod v4 broke zod-to-json-schema (the standard way to
turn Zod schemas into Anthropic tool input_schema). We hand-wrote JSON Schema
objects for all tool schemas, sharing them as both the Anthropic tool definition
and the server-side validation layer.
Extended thinking + structured output. Extended thinking doesn't compose cleanly
with tool use in all model versions. We used the
interleaved-thinking-2025-05-14 beta, which allows the model to think, then call
a tool, giving us both reasoning quality and structured output in one call.
Accomplishments that we're proud of
The flashback suppression working cleanly. The core architectural bet — filter facts in code before the model sees them — produces correct behavior without any temporal reasoning in the prompt. The model can't hallucinate a false positive on a flashback because the conflicting fact literally isn't there. Seeing it work the first time on the Jaime/wine-cup case was the moment the design proved itself.
Four high-signal contradictions on the GoT draft, every time. The combination of per-claim branch scoping, time-filtered facts, few-shot detection prompt, and extended thinking produces consistent results at low temperature. No random false positives; all four expected issues fire reliably.
A verified repair loop. "Apply fix" doesn't blindly swap text. The agent
patches, re-checks the exact span, and only surfaces verified ✓ when the
contradiction is gone and no new issues appeared. That's a non-trivial pipeline
to make reliable under time pressure.
The generalization claim is structural, not marketing. The engine primitives
(Entity, CanonFact, Claim, Branch, ContinuityIssue) contain no
fiction-specific logic. The checkScene interface is:
(claims, facts, context) → issues. Swap seed data and prompts and the same
pipeline checks AI agent memory. That's a real architectural seam, not a slide
bullet.
What we learned
Pre-filter ruthlessly; prompt conservatively. Every fact we cut from the context window before the detection call is a false positive we don't have to explain away. Giving the model only the facts that are actually in force for this scene's position and branch is the single highest-leverage accuracy improvement — higher than prompt engineering alone.
Separate the hot path from agents. The first instinct is to make the consistency check agentic — loop until confident. That's the wrong call for a live editor. Two bounded LLM calls with hard timeouts, a pre-warmed cache, and a canned fallback beat one agentic loop that might take 30 seconds or fail mid-stream on stage.
Observability from day one. Instrumenting every AI step as a named OpenTelemetry span (extract → infer → detect → repair.propose → repair.verify) let us see exactly where over-flagging came from in Arize traces. The before/after prompt improvement is a story we could only tell because we were tracing from the start.
Fiction is a legitimate proving ground for agent memory tooling. The hardest consistency problems — branching history, epistemic asymmetry, validity windows, per-claim context — all appear in serial fiction before they appear in production agent systems. Building on the fiction case first meant the primitives were already stress-tested when we reasoned about the broader use case.
What's next for Continuum
AI agent memory as a first-class surface. The engine already handles the right primitives: facts with validity windows, branching state, claim extraction from new output, contradiction detection with evidence. Wiring it to an agent's session store — where each new action is a "scene" checked against accumulated "canon" — is the most direct generalization and the one we're most excited about.
Redis vector retrieval at scale. The current demo uses in-memory fact filtering
over 8 facts. The Redis vector index and RedisRetriever are designed and partially
built — promoting them to the primary retrieval path means the engine scales to
thousands of facts without changing the check interface.
Browser extension and editor integrations. Because the engine is a clean API
(POST /api/check → ContinuityIssue[]), a browser extension that sends selected
text is a thin wrapper. Google Docs and Obsidian integrations follow the same
pattern — the core doesn't change, only the surface.
Arize-driven prompt improvement loop. The tracing infrastructure is in place. The next step is closing the loop: when Arize shows a pattern of over- or under-flagging on a specific issue type, the detection prompt gets a targeted few-shot addition, measured against the golden test suite, and shipped as a new prompt version. Observability as a development workflow, not just a dashboard.
Built With
- anthropic
- arize
- css
- deepgram
- next.js
- openai
- opentelemetry
- react
- redis
- sentry
- tailwind
- tiptap
- typescript
- upstash
- vercel
- zod
- zustand



Log in or sign up for Devpost to join the conversation.