-
-

Landing Page
-

Workflow
-
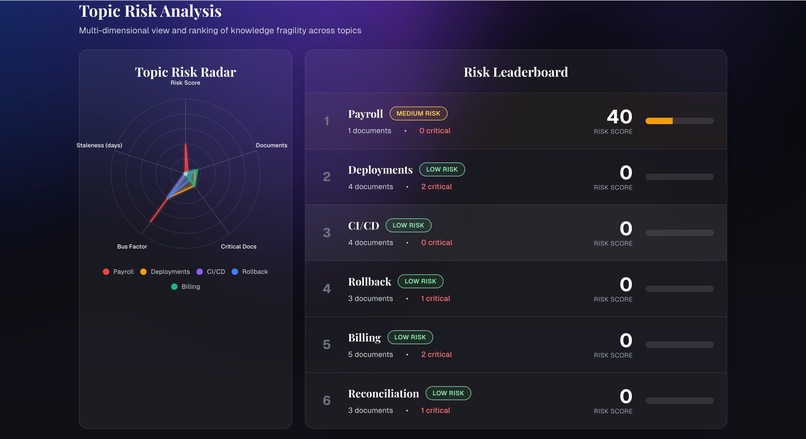
Team Info Risk Analysis Dashboard
-
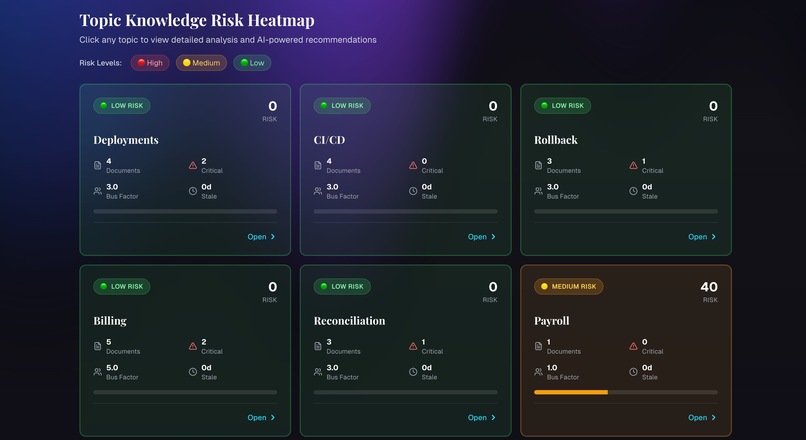
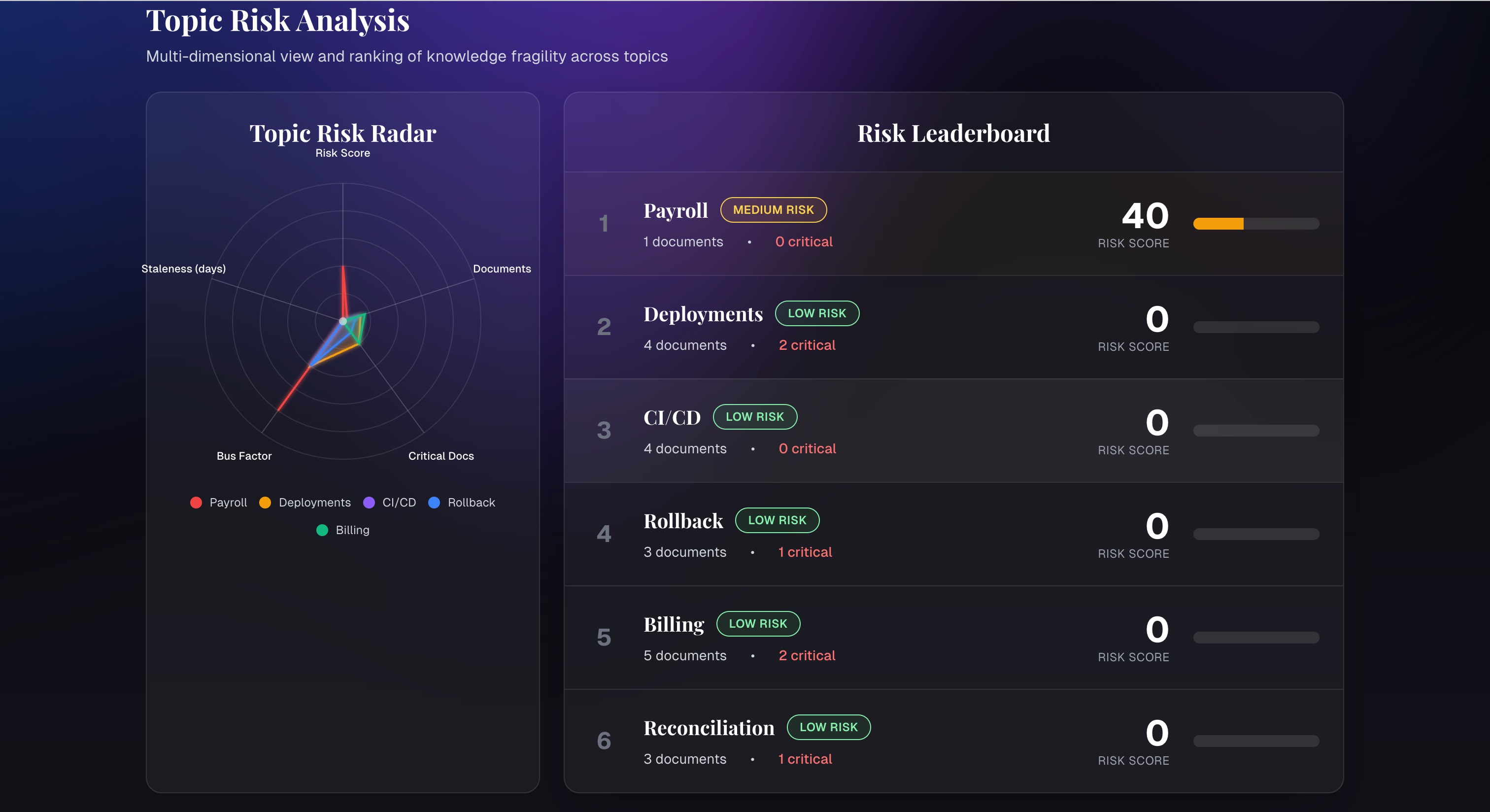
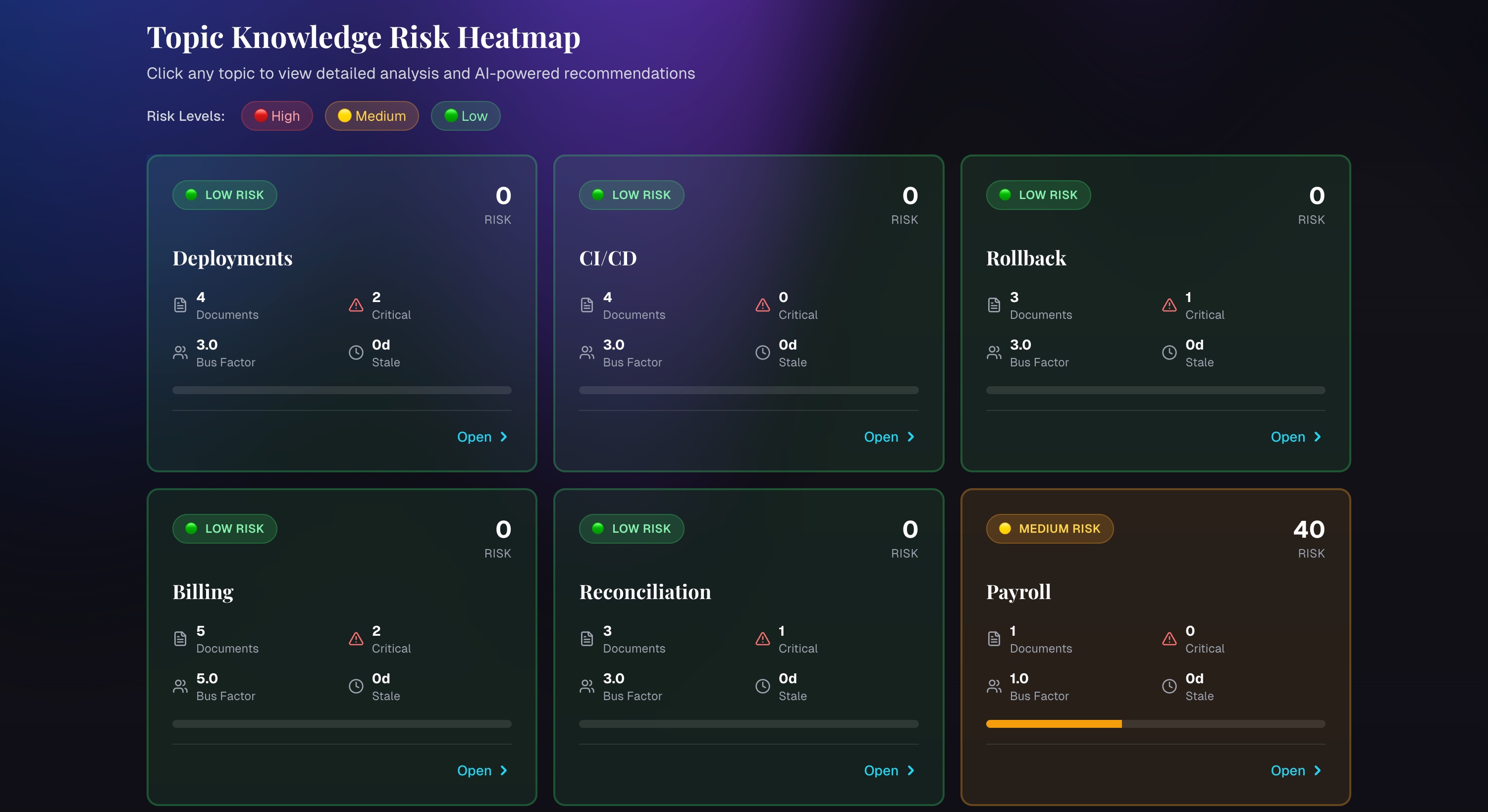
Topic Risk Analysis
-
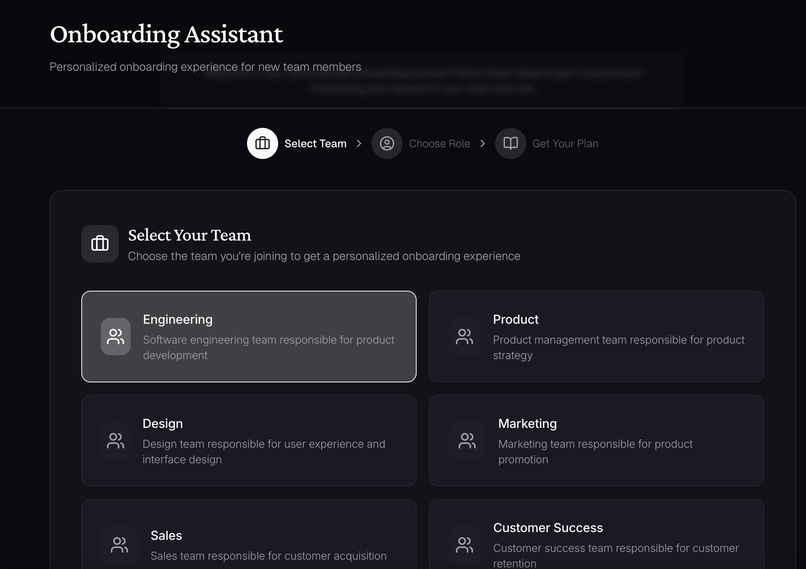
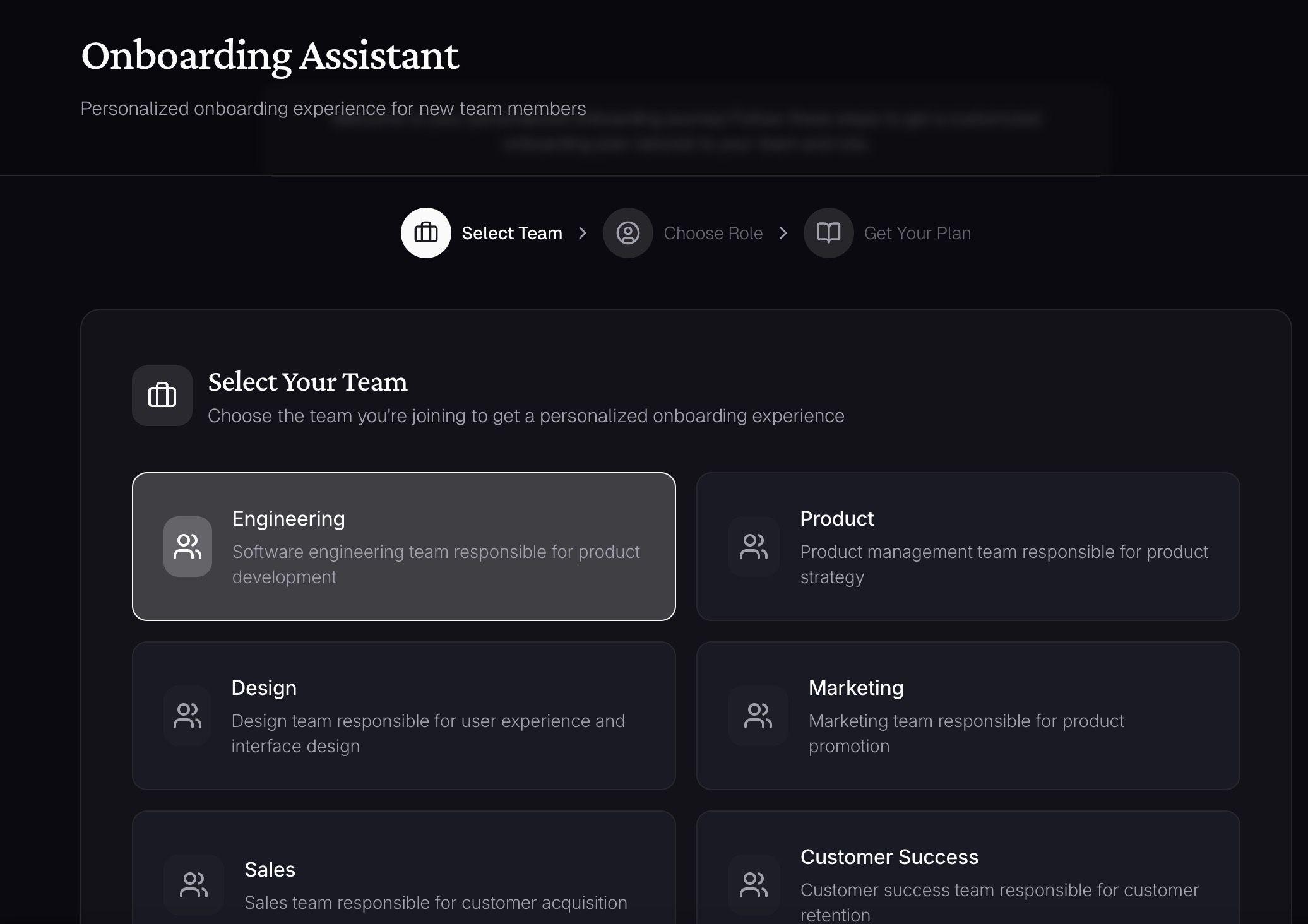
Onboarding Assistant


Continuum: AI for Organizational Memory and Knowledge Resilience
Inspiration
Teams depend on written knowledge, but most organizations quietly lose it. People leave, documents go stale, and critical workflows live in one person’s head. Tools like Confluence and Notion store information, but they do not show which knowledge is fragile, out of date, or shared by only one owner. Continuum exists to close that gap and reduce corporate amnesia.
What it does
Continuum analyzes internal documentation and builds an organizational memory graph that links people, topics, and systems. It:
- Detects single points of failure where only one person owns a topic or workflow
- Highlights fragile or outdated processes
- Surfaces systems that are poorly or never documented
When someone is about to leave, Continuum simulates their departure, recomputes bus factors, and produces a structured handoff plan with successor assignments and missing documentation alerts.
Continuum also supports querying and onboarding. Users can ask questions such as “How do deployments work,” and it retrieves relevant documents, synthesizes an answer, and reports a resilience score for that knowledge. New hires can request team-specific onboarding guides, and Continuum compiles core docs, key systems, and people to meet, while pointing out areas where documentation is weak.
How we built it
We used FastAPI for the backend and a Postgres schema modeling people, documents, topics, and systems. Claude handles topic extraction, explanation of risk, and handoff or onboarding plans. Bus factors, risk levels, and resilience scores are computed from document ownership, criticality, and staleness. For retrieval, we use a lightweight RAG flow: Claude ranks relevant documents from summaries, then synthesizes answers from the chosen texts instead of relying on a heavy vector database.
Challenges we ran into
Real-world documentation is inconsistent and incomplete. Designing a schema that could express topics, systems, and ownership while still being easy to query was a key challenge. Another was defining a risk model that combined bus factor, staleness, and criticality in a way that felt meaningful to humans without overcomplicating the scoring.
Accomplishments
We shipped a working system that goes beyond traditional documentation search. Continuum does not just store information; it evaluates its health and helps organizations act before knowledge is lost. The continuity simulator and resilience-aware Q&A are the signature features that make the product feel both practical and technically grounded.
What we learned
We saw how quickly organizational memory decays and how rarely teams can see documentation risk in advance. We also learned how well LLMs complement deterministic logic: using Claude for extraction, synthesis, and planning on top of a clear data model and risk engine produced better results than relying on either approach alone.
What's next
Next steps include integrating directly with Notion, Confluence, GitHub, and Slack; sending alerts when topics drift into high-risk territory; and improving visualizations of the knowledge graph. Over time, we want Continuum to function as a continuous monitoring layer for organizational memory so that critical knowledge survives personnel changes.
Built With
- fastapi
- next.js

Log in or sign up for Devpost to join the conversation.