Inspiració
Aportar a la recerca de la medicina sempre és inspirador i en aquest cas encara més, sabent la importància que té el càncer a la nostra societat. Poder dedicar el nostre esforç a un tema tan important és el que ens ha motivat.
Que fa:
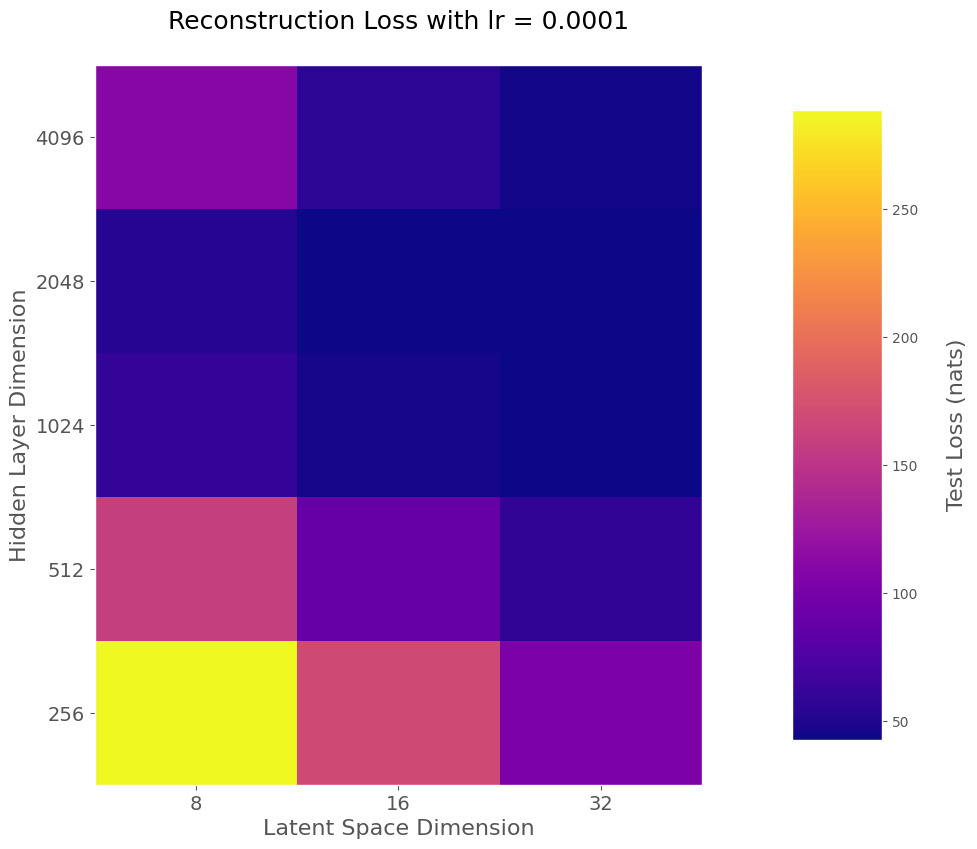
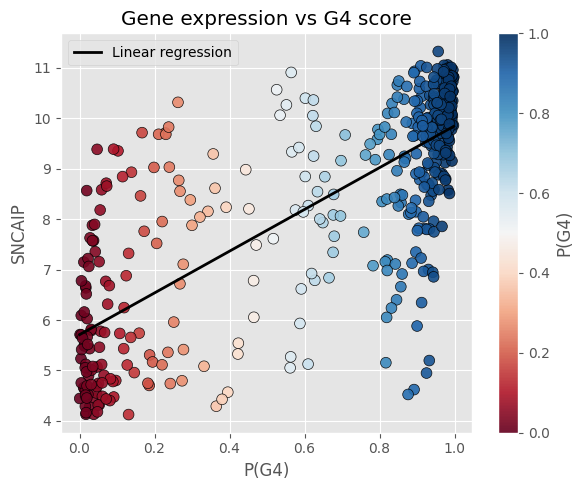
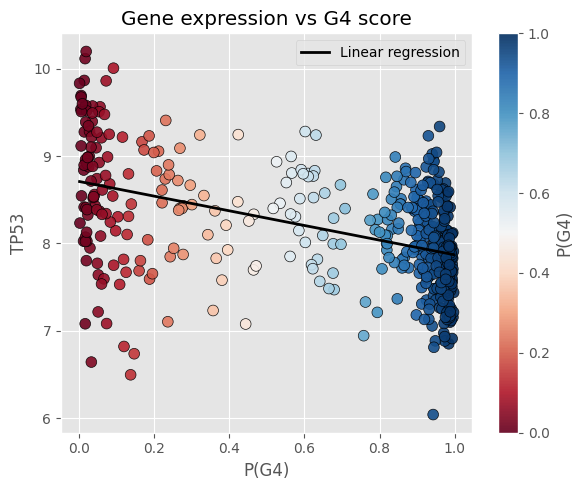
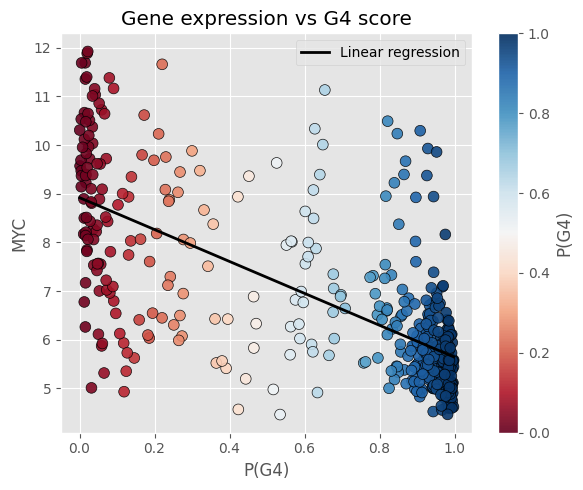
Els nostres esforços s'han centrat en generar dos models, el categoritzador continu i el generador de dades. El primer d'ells utilitza la Regressió Logística (LogisticRegression) usant diferents valors que s'han obtingut del VAE per acabar de concretar els hiperparàmetres del mateix model, per aconseguir el menor error possible. S'han verificat les prediccions obtingudes amb la Logistic Regression amb les proteïnes MYC, TP53 i SNCAIP i hem pogut veure com els resultats s'ajustaven correctament als valors esperats. Per la part de la generació de dades, s'han implementat dos models diferents per a la generació d'aquestes dades sintètiques, concretant per només generar valors plausibles per als pacients de tipus G3 i G4, aconseguint un resultat sense etiquetes (labels). Aquest model s'ha utilitzat per generar les dades de freqüència de gens. Aquest es va implementar per a la generació d'un subconjunt en concret de gens, a causa que realitzar-ho en la totalitat dels gens va resultar massa complex. Una altra implementació que es va tenir per plantejar aquest problema va ser la de, en comptes de generar la totalitat dels gens com a sortida (output) del GAN, es podria utilitzar l'espai latent per només haver de ser entrenat i generar elements de 32 valors.
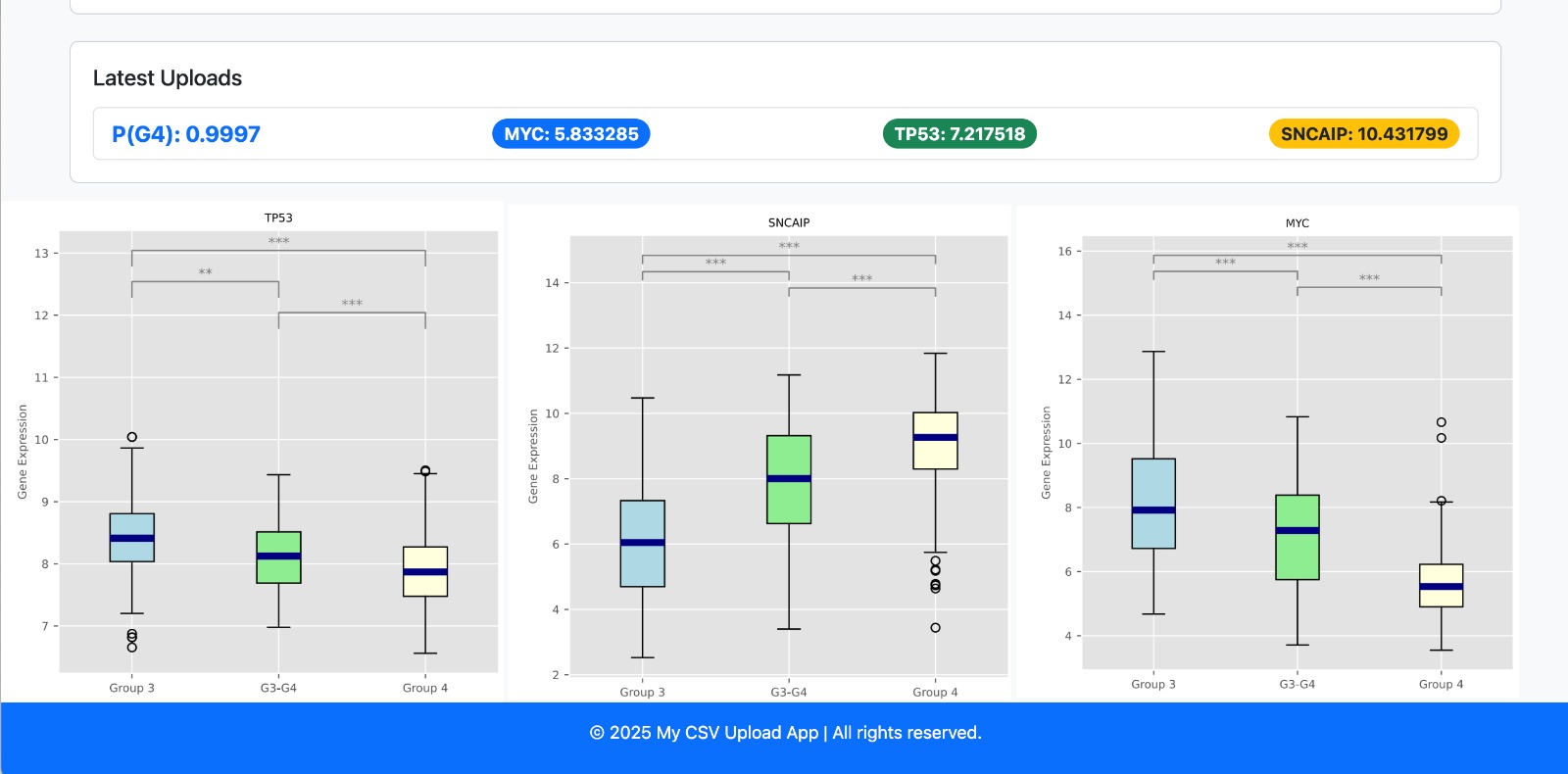
Finalment, per interactuar amb aquest model, es va desenvolupar un web per, donat un fitxer .csv, retornar la predicció contínua aconseguida amb el primer model. Addicionalment es retornen els valors de les proteïnes MYC, TP53, SNCAIP per validar de forma ràpida la coherència dels resultats.
Problemes que hem afrontat
Un dels problemes que més ens ha afectat ha sigut en el procés de generar dades sintètiques. Un dels conjunts de dades dels quals estàvem partint, havia estat filtrat i tenia molt poques característiques (2886), això va fer que el nostre plantejament inicial que era partir d'una assignació aleatòria fins a les 2886 característiques funciones correctament, però a l'hora d'usar el conjunt de dades final amb moltíssimes més característiques i poques entrades, fent que els resultats no fossin correctes. Per mitigar aquest error va caldre incorporar l'espai latent del VAE usat per classificar, cosa que va fer que el generador no crees tantes dades incorrectes.
Assoliments dels quals estem orgullosos
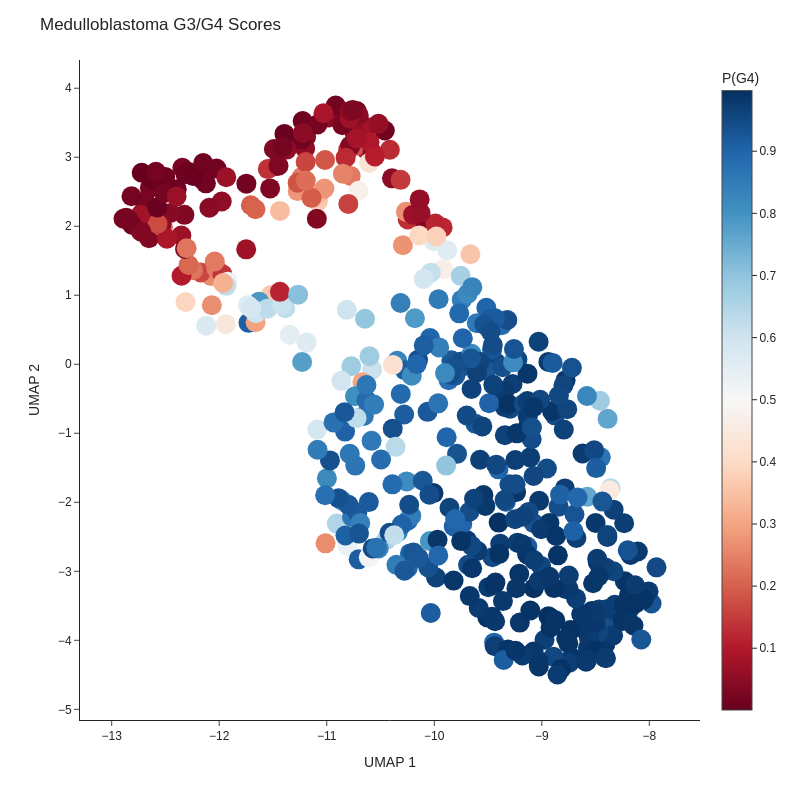
Hem aconseguit definir un continu, que es comporta de la mateixa manera que s'havia predit. Hi ha pacients que es troben entre els grups 3 i 4, aquests es pot veure clarament com la probabilitat de formar part d'un o l'altre és ambigua. A més hem pogut validar aquests resultats comparant-ho amb els valors de les proteïnes MYC, TP53 i SNCAIP, on podem veure com a mesura que la probabilitat de formar part del grup 3 augmenta els valors d'aquestes proteïnes també go fan.
A més també hem pogut crear una web per poder entrar informació dels pacients i obtenir la seva probabilitat de formar part del grup 4, juntament amb els seus valors de MYC, TP53 i SNCAIP.
Finalment, estem molt contents de també haver pogut generar dades de pacients de manera sintètica fent ús d'una xarxa GAN.


Log in or sign up for Devpost to join the conversation.