-

data flow diagram
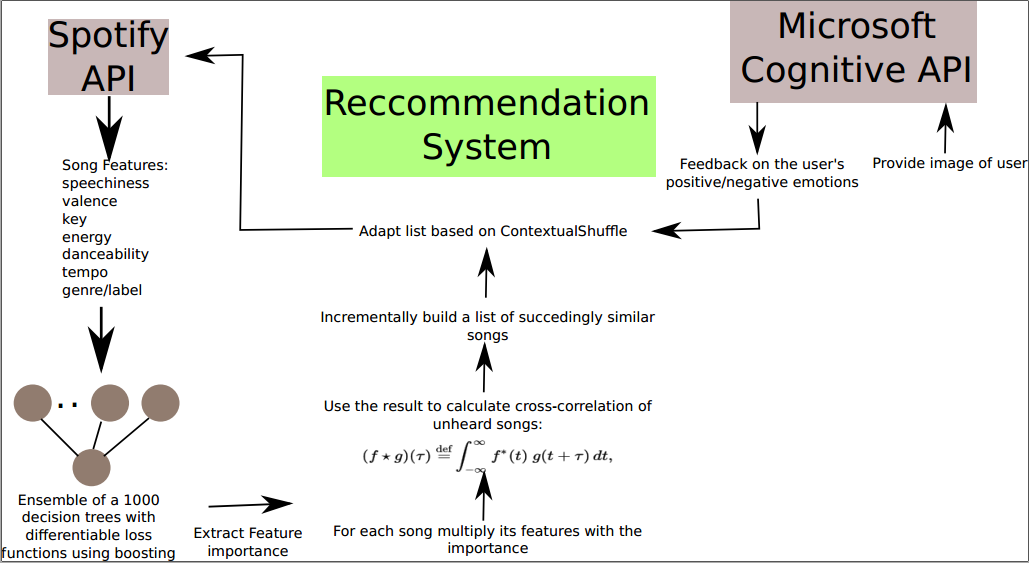
Contextual Shuffle
Inspiration
Whilst people can have large collections of music they enjoy, these often can conflict with each other's mood if improperly ordered. For example, a playlist containing both classical and hip hop music, of which the user enjoys both of, may not flow well in the wrong environment or mood. It may also be displeasing for the user to hear such a wide varation in songs.
What it does
ContextualShuffle loads the entirety of your music library and learns associations between specific categories of music. Using these categories and other song-specific features such valence, tempo, and genre, similarities are identified between other songs in your library, without any intervention on your part. Similar songs are then queued (shuffled) such that the genre or other features of importance does not vary too much from song to song. By monitoring the user's facial expressions, the efficacy of the queuing system is further adapted and improved each iteration.
How we built it
Starting with the initial aim of identifying similar songs, a large music dataset was required. We sought to acquire features and labels that were most relevant for every track in the dataset. We identified the following features as critical in classification of each track:
- Valence
- Speechiness
- Key
- Energy
- Danceability
- Tempo
- Genre.
An ensemble of a 1000 decision trees was trained with boosting to extract feature importance, corresponding to the above features. The features were then normalized between -1 and 1 to allow for an easier evaluation. Using the resulting features we calculated, the cross-correlation between different songs was calclated and an incrementally built list of succeedingly similar songs was continually adapted using positive and negative emotions determined by Microsoft's Cognitive API service.
Following this, when a user plays a given song from their library, the most similar songs to each corresponding song are played successivelly. This means the first song's nearest neighbour is played. The neighbour then becomes the root from which calculations are considered, and it's nearest neighbour is played and so on. This provides a good balance of variation and consistency between tracks.
Challenges we ran into
OpenCV has posed multiple difficulties due to version compatibility and limited support for python 2.7. Even after installing it for Python3 a large amount of time was needed for everythin to work as intended. The Spotify API download rate has posed a significant problem due to the large amount of training data that was required by our algorithms. The Azure API examples could improve in terms of documentation. Running Webcams through virtual machines was nearly impossible, so we had to resort to communicating to external mobile devices. Labelling of genres, and appropriate mining of data was difficult to achieve due to Communication between different technologies was difficult and rather consuming.
Accomplishments that we're proud of
We believe this product is workable, usable, and performs in-line with our initial aims and goals The large amount of different technologies into the product has given us a brief but enjoyable experience with each of them. Generating and creating workable training and testing datasets given the large amonut of variables in a given track.
What we learned
Avoid OpenCV if possible. Learning about different APIs and libraries in order to achieve a niche task. Keep your front and back end separated if possible.
What's next for ContextualShuffle
We'd love to reach out to the team at Spotify and discuss how our findings could help them improve their technologies and how additional features in their APIs could assist developers

Log in or sign up for Devpost to join the conversation.