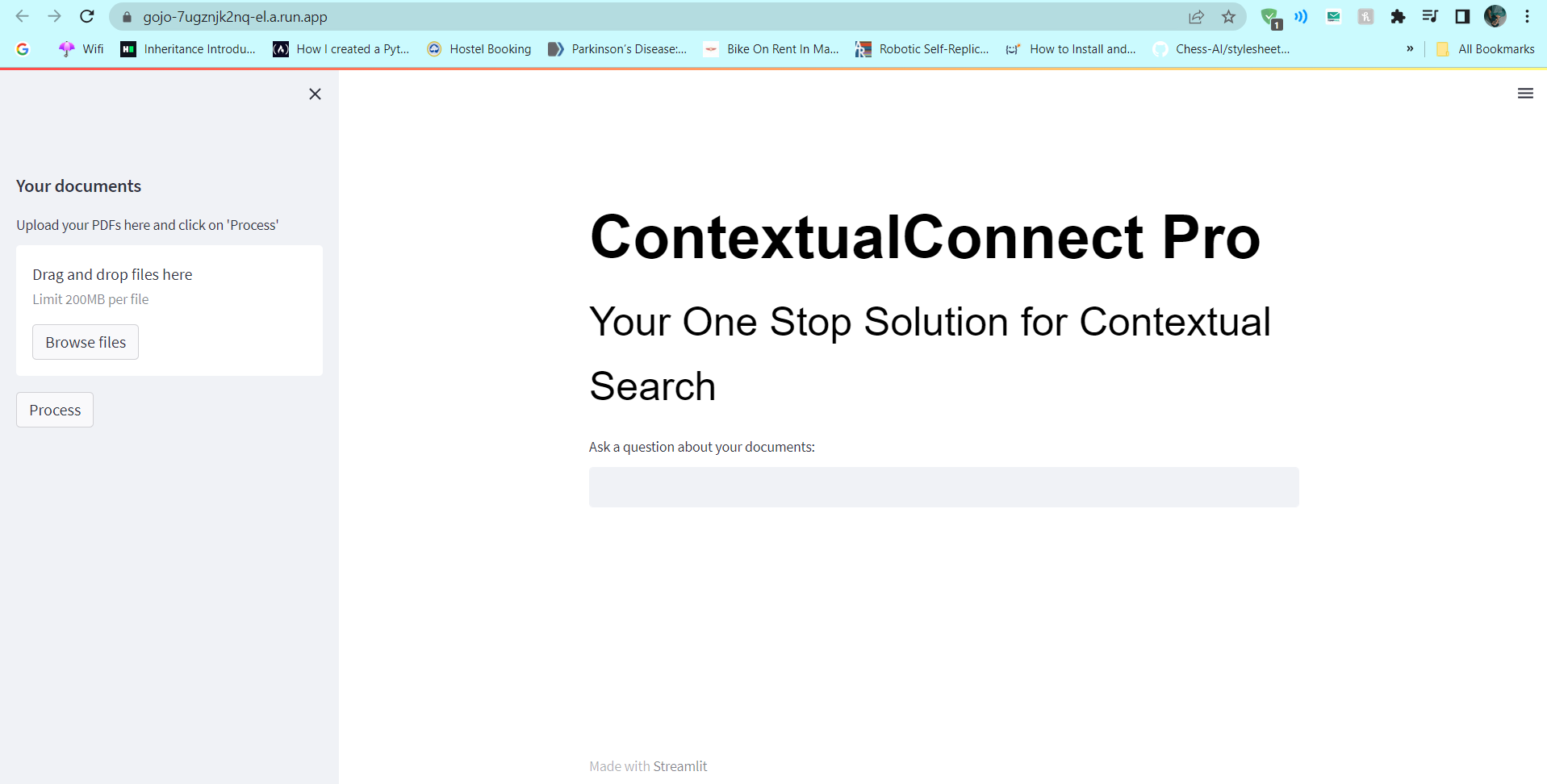
Introduction
The ContextualConnect Pro project is a Natural Language Processing (NLP)-based initiative that delivers precise and informative responses to a wide range of queries across different domains. It leverages Large-Language Models (LLMs) to provide detailed and personalized responses, unlike search engines and generic websites that often lack context and personalization.
LLMs and Their Role
LLMs are trained on massive amounts of text data, enabling them to understand and respond to complex queries in an informative way. ContextualConnect Pro leverages this capability to provide users with accurate and helpful information on a variety of topics.
Inspiration and Motivation
The ContextualConnect Pro project was inspired by the increasing need for accurate and personalized information. In today's world, we are constantly bombarded with information from a variety of sources. However, not all of this information is accurate or relevant to our needs. This can be frustrating and time-consuming, especially when we are trying to find information on a specific topic.
ContextualConnect Pro was designed to address this problem by providing users with a way to access accurate and personalized information on a variety of topics. The project's NLP model is able to understand the context of a query and provide relevant and helpful information. Additionally, the system can personalize its responses based on the user's individual needs and preferences.
Learning and Discovery
The development of the ContextualConnect Pro project was a journey of learning and discovery. The team behind the project learned a great deal about NLP, LLMs, and the challenges of building a system that can provide accurate and personalized information.
Building and Implementation
The ContextualConnect Pro project was built using a variety of open-source tools and libraries. The team used PyTorch to train the NLP model and Streamlit to build the web application. The team also utilized a number of other tools and libraries, such as FAISS, HuggingFace, OpenAI,etc.
Docker Deployment
In the Docker deployment phase, we begin by creating a Dockerfile, which acts as a blueprint for packaging the ContextualConnect Pro application and its dependencies into a Docker container. The Dockerfile specifies the base image, installs necessary tools and libraries, and defines the command to run the application.
Once the Dockerfile is ready, the next step involves building the Docker container. This process creates a self-contained environment that ensures consistent and reliable execution across various settings. The container is assigned a unique tag, often labeled "contextualconnect-pro."
To validate the Docker deployment, it's essential to run the container locally on a developer's machine. This controlled testing environment confirms that the project operates correctly within the container, ensuring it's prepared for broader deployment and scaling, much like the learning and discovery journey of the ContextualConnect Pro project.
Cloud Deployment
Cloud Console and Project Setup: The deployment process commences with setting up a GCP project and navigating through the Cloud Console. Within the Cloud Console, key services like Google Container Registry are employed.
Docker Image Creation and Container Registry: A Docker image is constructed for the ContextualConnect Pro project using a Dockerfile. This image is then pushed to the Google Container Registry, a managed Docker image storage service. It provides a secure and accessible location for hosting Docker images.
Challenges Encountered
The development of the ContextualConnect Pro project was not without its challenges. The team faced a number of technical challenges, such as training the NLP model and optimizing the web application for performance. Additionally, the team had to carefully consider the ethical implications of using NLP technology.
Conclusion and Future Directions
Fine-Tuning and Model Optimization: Periodically fine-tune the NLP model to enhance its performance, accuracy, and response quality.
Enhanced Data Ingestion and Processing: Develop capabilities for ingesting and processing various types of complex data, including structured and unstructured data, audio, images, and video.
Multilingual Support: Extend the NLP model's capabilities to support multiple languages, enabling users worldwide to interact with the system. - Implement language detection and translation features to facilitate cross-language communication.
References
[1] Vaswani, A., et al. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008. [2] Devlin, J., et al. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. [3] Radford, A., et al. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8).
Github Repository Link
https://github.com/AagamChhajer/ContextualConnect-Pro/tree/master
Built With
- docker
- dockerimage
- embeddings
- faiss
- gcp
- google-cloud
- huggingface
- langchian
- minilm
- openai
- python
- pytorch
- streamlit



Log in or sign up for Devpost to join the conversation.