-
-
AdaptLM Cover
-

AdaptLM with VAPI
-
AdaptLM with Agents
-
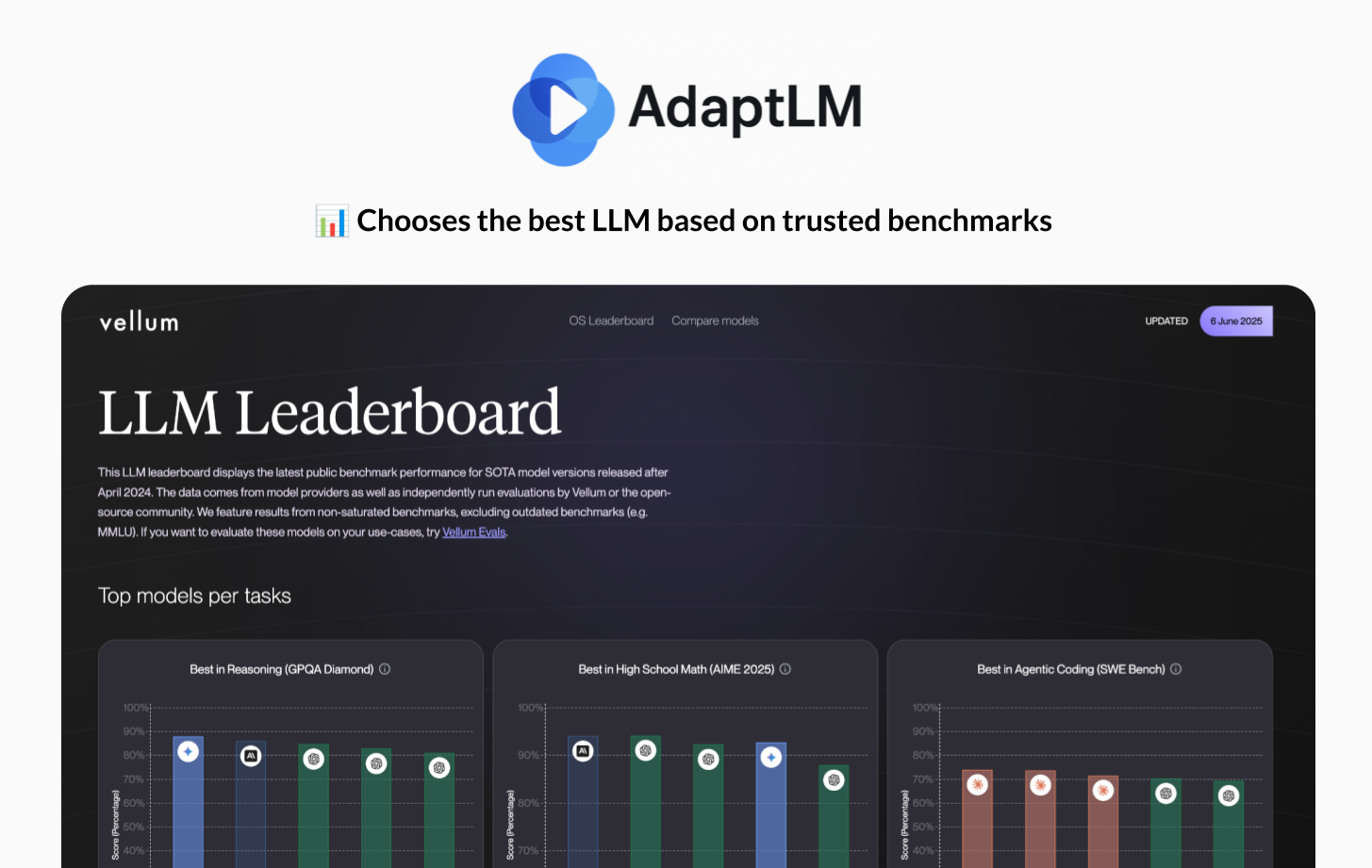
AdaptLM Benchmark
-
AdaptLM Architecture


🚀 Inspiration
What’s your favorite LLM to use?
✨ Mine is Claude — I love how well it handles coding.
✨ Sometimes I switch to Groq — it’s just so fast.
But juggling between LLMs means:
- Opening multiple tabs
- Copy-pasting between models
- Refeeding prior context over and over
💡 No more. That’s why we built AdaptLM.
⚡ What it does
AdaptLM is an intelligent LLM orchestrator that:
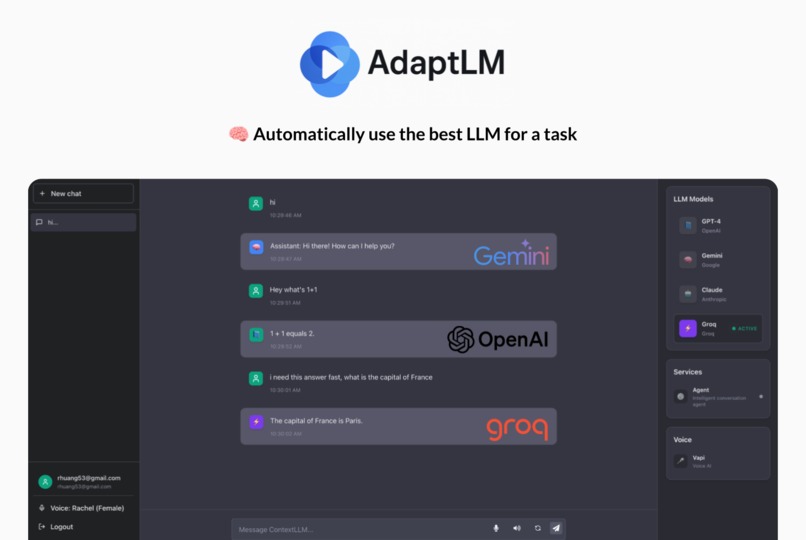
- Automatically selects the best LLM for your prompt based on context and task
- Seamlessly integrates multiple LLMs in a single session — with shared context and no manual switching
- Uses RAG to share context across models, so every LLM stays informed
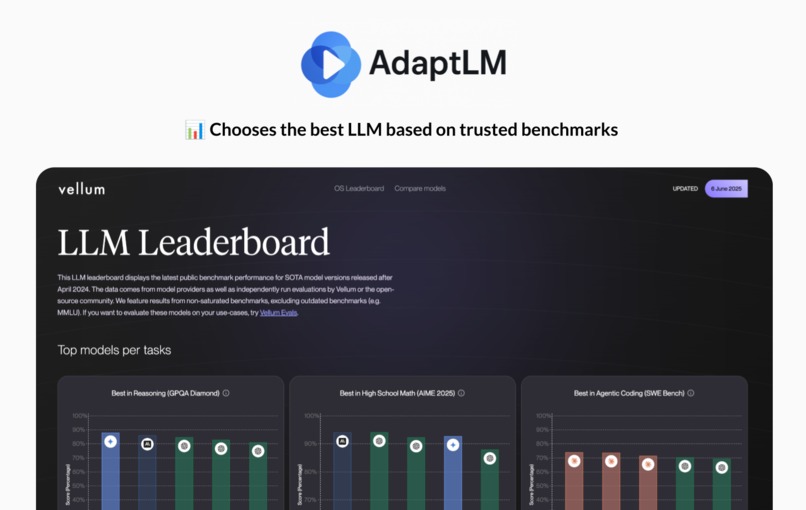
- Routes prompts using Vellum AI benchmarks and advanced NLP, matching intent to the ideal model
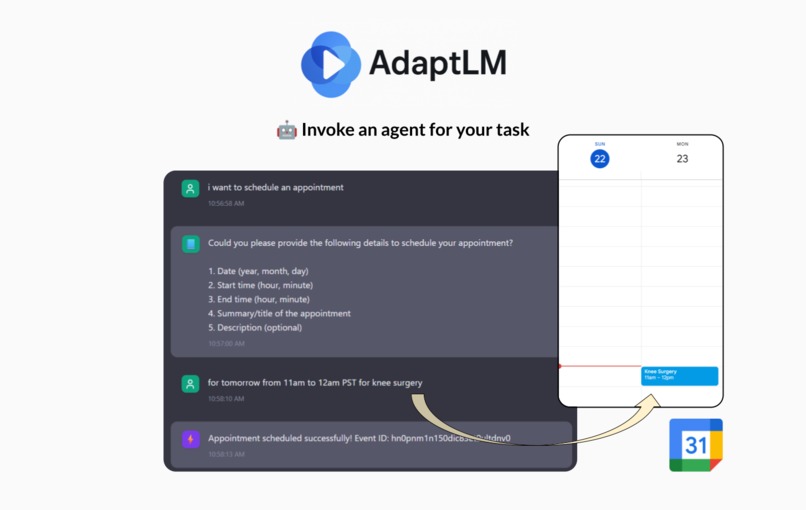
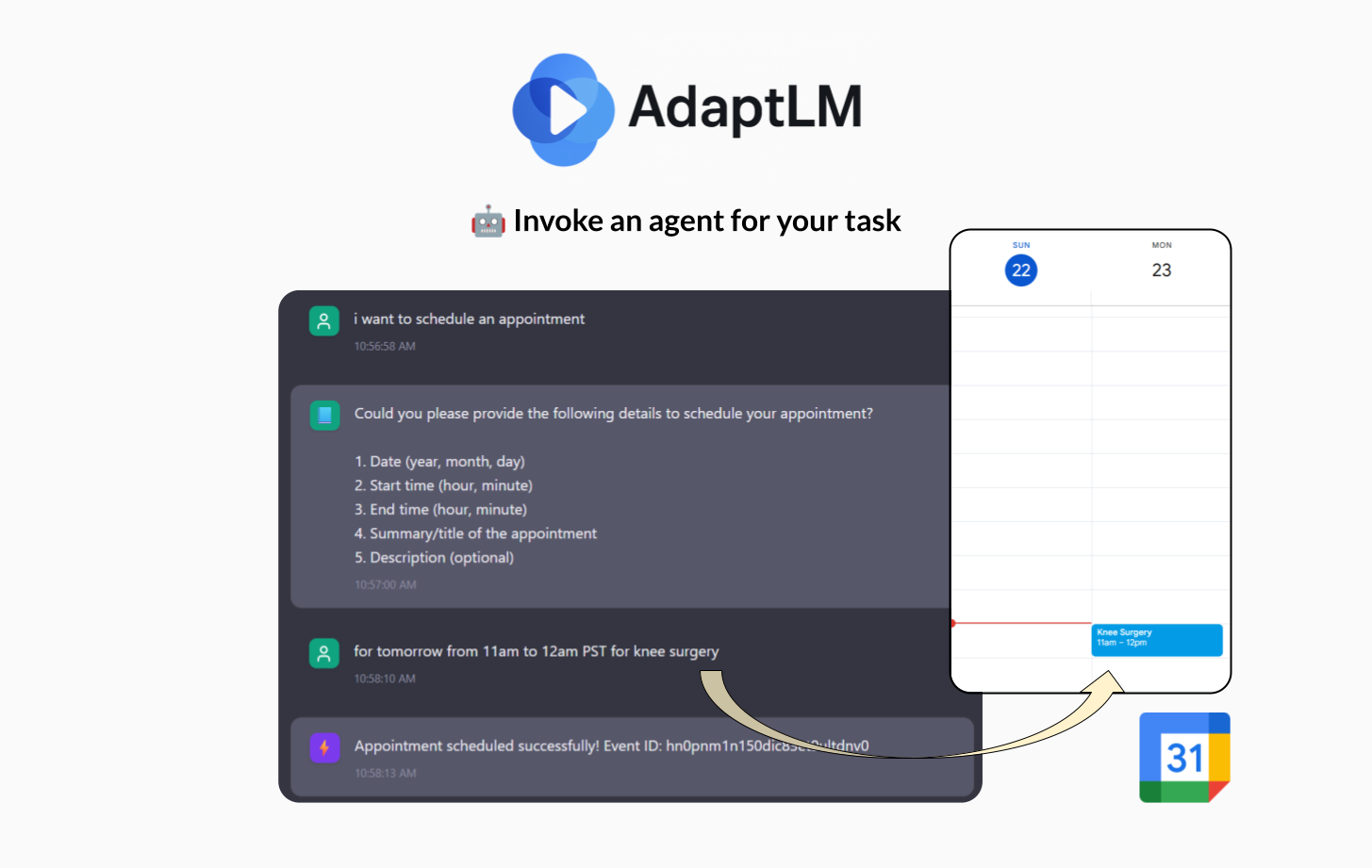
- Provides agentic tools to handle tasks like emailing and calendar setup — all within the same flow
- Supports voice interaction via Vapi, so you can speak directly to your AI assistant
✨ Key Enhancements
- Built-in tools for:
- Sending emails
- Creating Google Calendar events
- Sending emails
- All handled within the same session, with no extra setup
🎤 Voice Control
Too busy to type?
✅ Simply enable voice via Vapi and interact with the selected LLM hands-free.
🛠️ How we built it
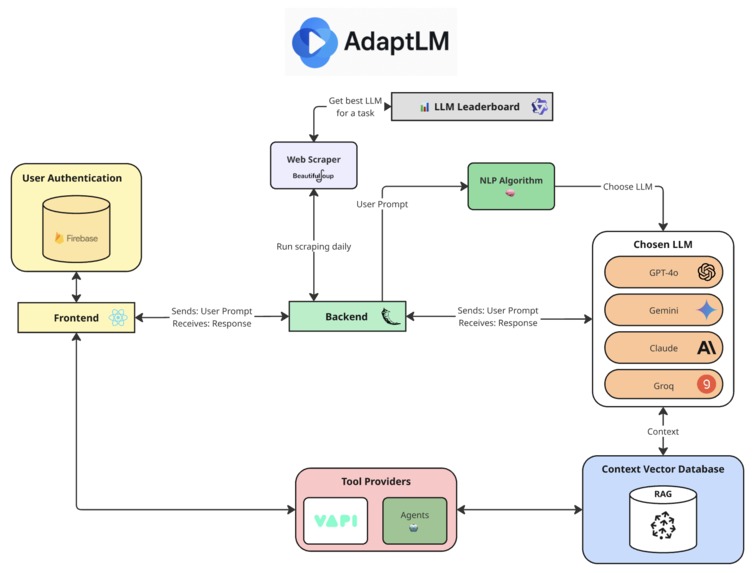
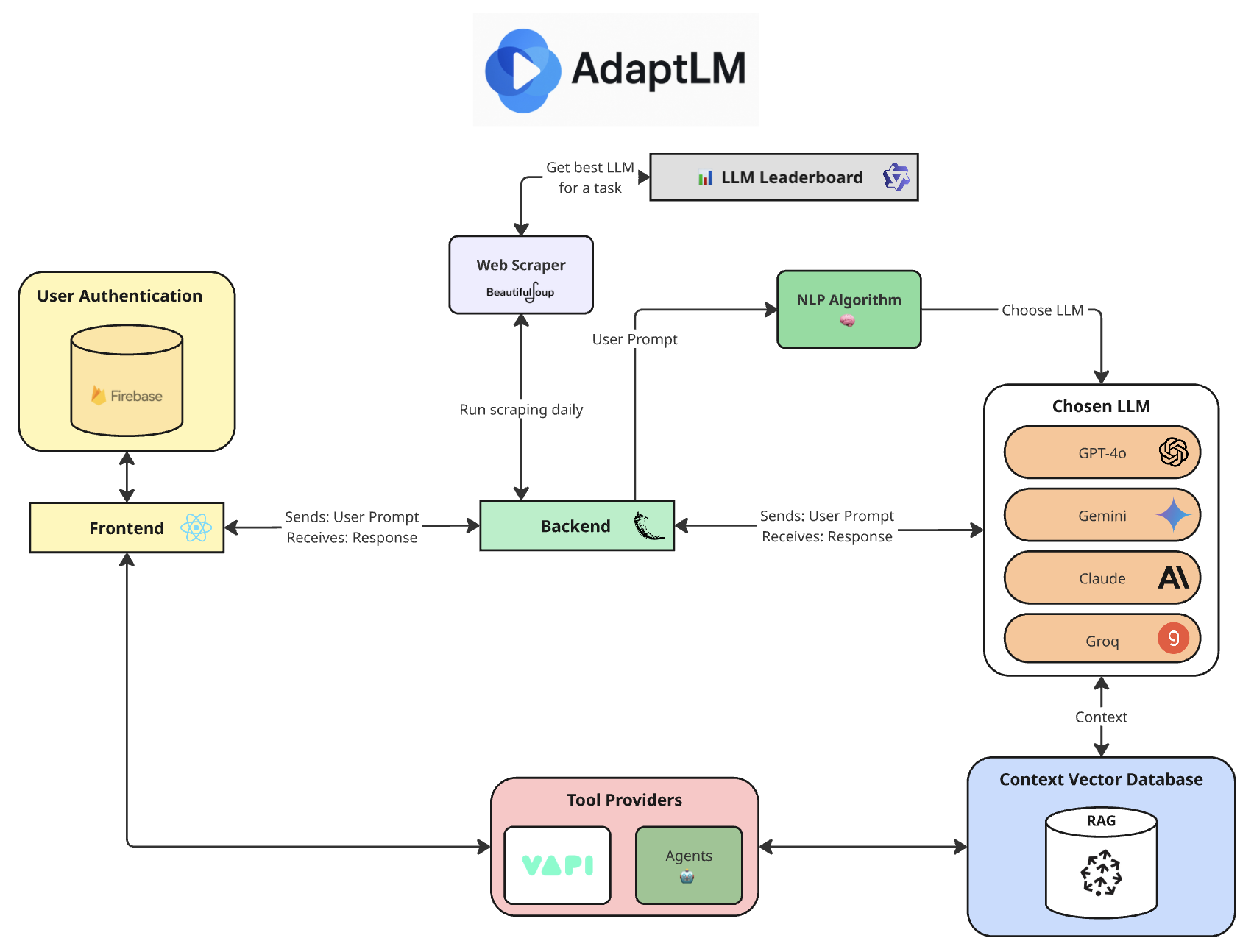
A visual diagram can be represented below:

Frontend
- React 19.1.0 with Vite 6.3.5 for fast, modern development
- Firebase 11.9.1 for authentication and backend services
- Vapi AI Web SDK 2.3.6 for voice AI capabilities
- ESLint for maintaining code quality
Backend
- Flask 2.3.3 as the core web framework
- Multiple LLM APIs: OpenAI (GPT), Anthropic (Claude), Google (Gemini), Groq
- Pinecone 7.2.0 as the vector database
- Sentence Transformers 4.1.0 for generating text embeddings
- Google APIs for Calendar and Gmail integrations
Key Architecture Features
- LLM Router using advanced NLP techniques for intelligent model selection
- RAG pipeline for context sharing across multiple LLMs within a session
- Voice AI integration with speech-to-text and text-to-speech via Vapi
⚠️ Challenges we ran into
Capturing the semantics and intent of the prompt
Designing an NLP-based router that accurately understands both the task and subtle intent behind a prompt — and maps it to the right LLM — required significant fine-tuning and experimentation.Addressing the bottleneck of vector embedding ingestion
Ingesting embeddings into a vector database can introduce latency — but users still need instant access to context. We tackled this by designing a solution that keeps the user experience smooth while embeddings process in the background.Integrating Vapi for voice control
Ensuring smooth speech-to-text and text-to-speech conversion, while maintaining accurate model selection and context continuity, was a complex task involving both frontend and backend coordination.
🏆 Accomplishments that we're proud of
Innovative solution for dynamic LLM selection
We successfully designed and implemented an architecture that tackles the challenge of choosing the right LLM for the task — without user intervention.Seamless handling of multiple LLMs with shared context
AdaptLM can switch between models while maintaining context awareness, thanks to our RAG-powered pipeline.Integrated agentic services without extra steps
Users can send emails, create calendar events, and more — all within the same flow, no manual setup or switching required!
📚 What we learned
Model selection is harder than it looks
Understanding the true intent of a prompt and matching it to the best LLM requires more than just keywords — it demands careful NLP design and real-world testing.Context sharing across models is critical
Without seamless context transfer (via RAG), switching between models breaks the user experience. We learned how vital it is to maintain continuity for a smooth workflow.Voice and agentic integration add huge value — but also complexity
Combining voice interfaces and agentic services with multi-LLM orchestration taught us a lot about managing asynchronous systems and delivering a consistent, responsive UX.
🌟 What's next for AdaptLM
Scale to more LLMs
We plan to expand support to additional models, giving users even greater flexibility and performance options.Universal API
Our goal is to build a single API layer that lets developers access multiple LLMs through one unified endpoint — no more juggling different APIs.Define a prompt taxonomy for smarter routing
We aim to create a clear taxonomy for prompt types (e.g. cost-efficient, reasoning-heavy, simple language tasks) to enable faster, smarter, and more cost-effective model selection.
Built With
- claude
- gemini
- groq
- javascript
- openai
- pinecone
- python
- react



Log in or sign up for Devpost to join the conversation.