-

Poster
-
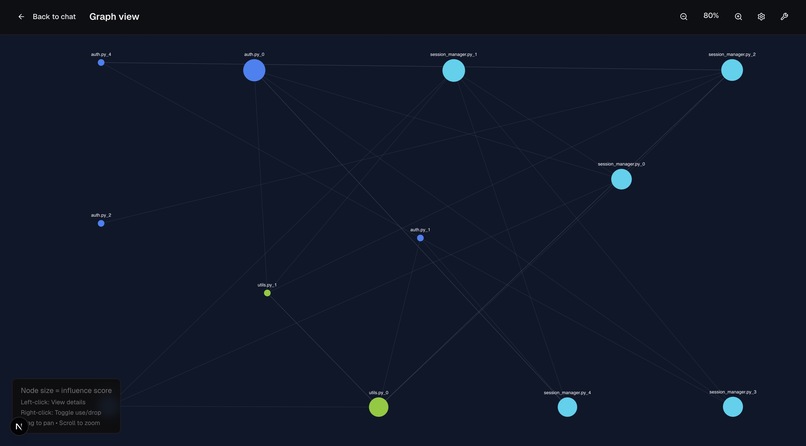
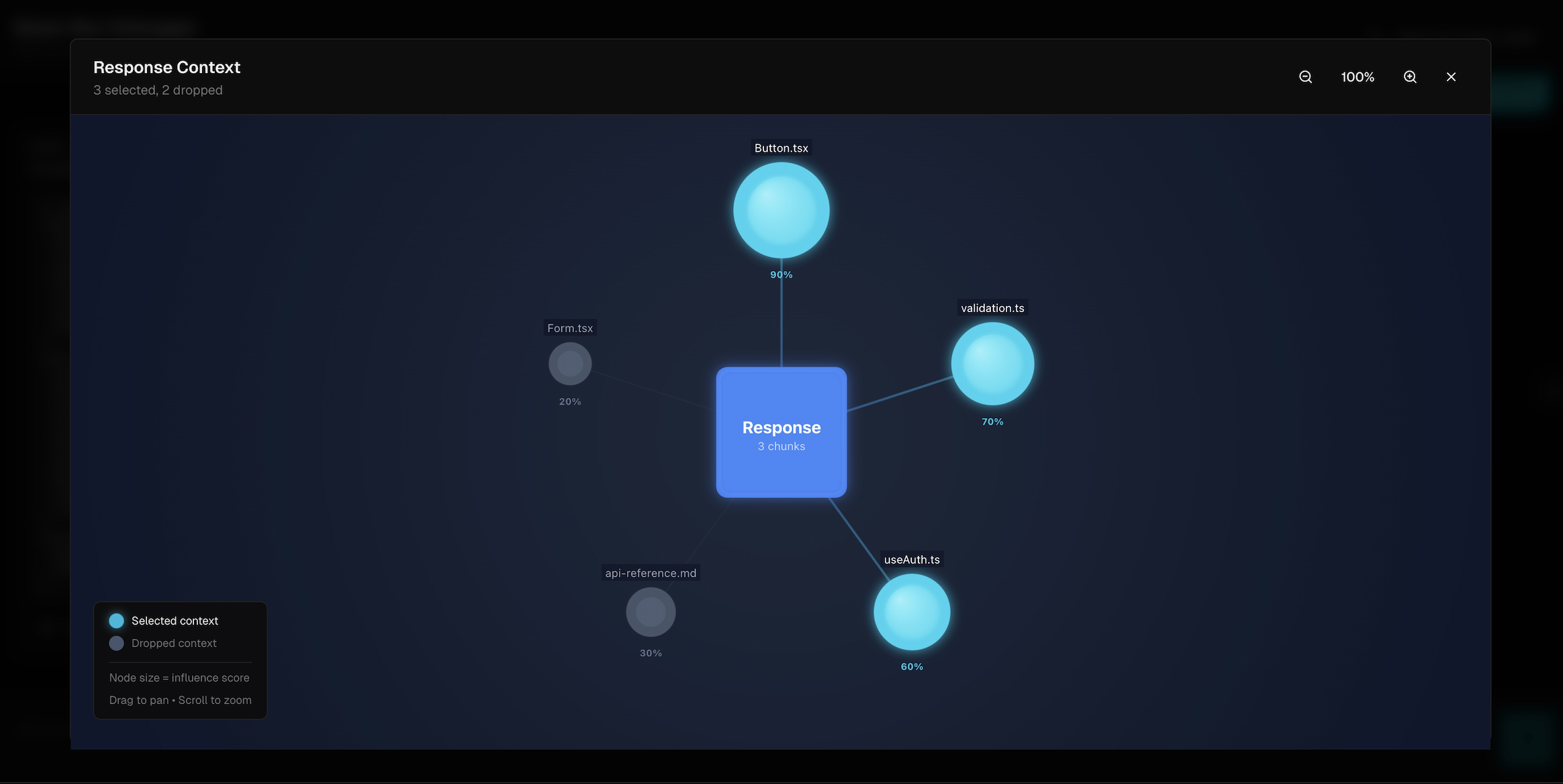
Graph view showing all the context chunks and their relations
-
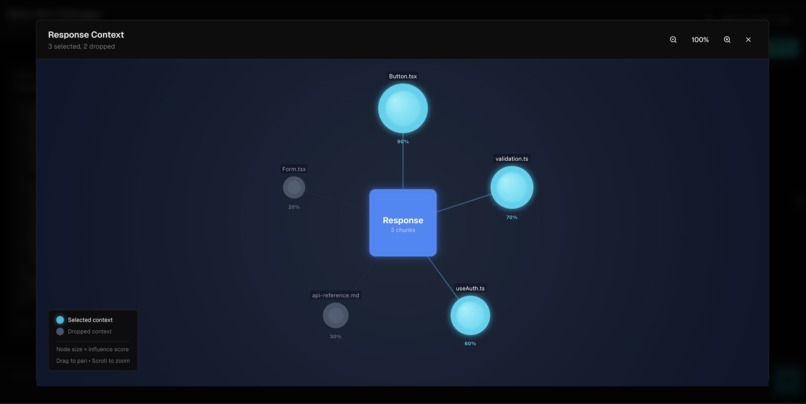
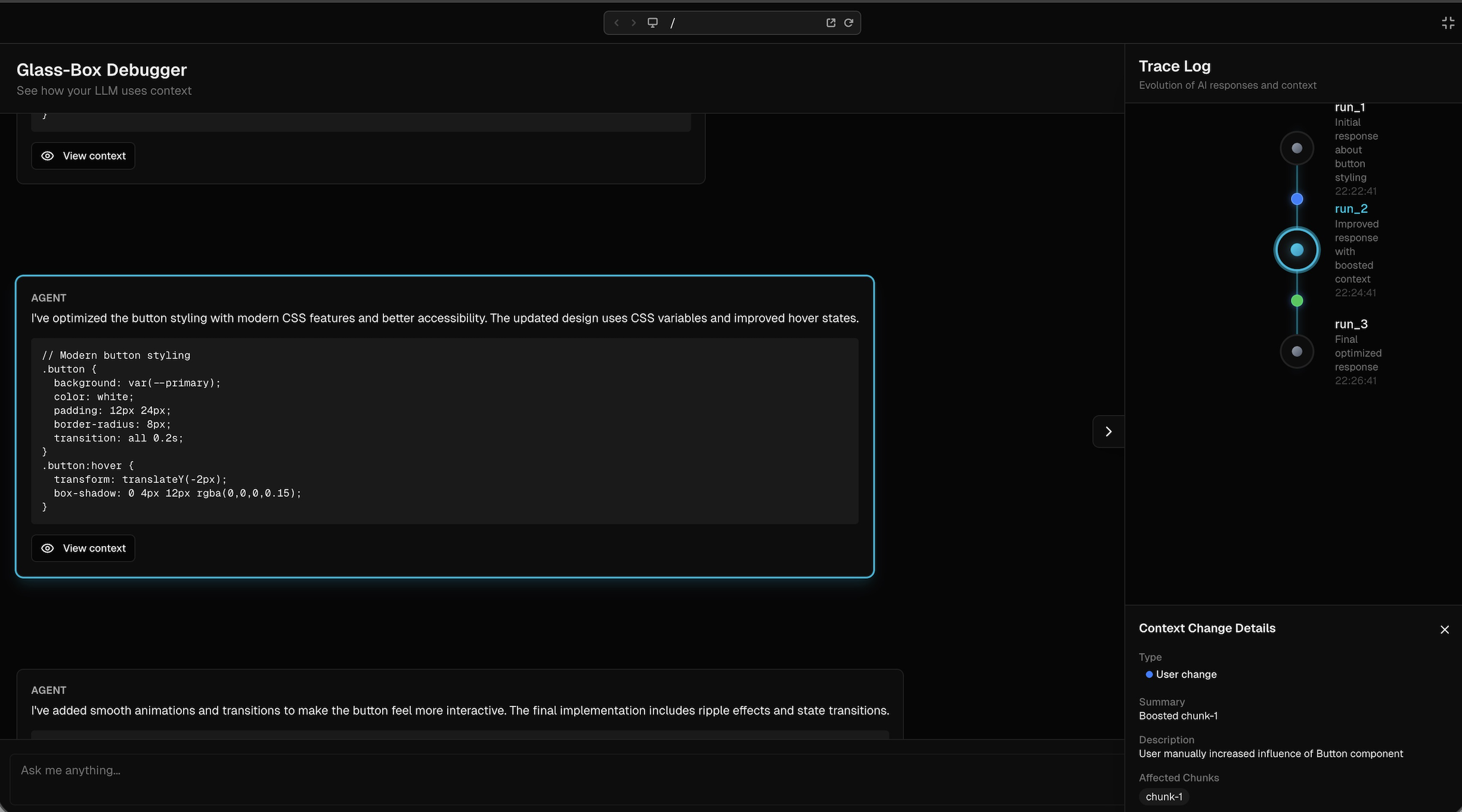
Showing the contribution of each chunk to the model response
-
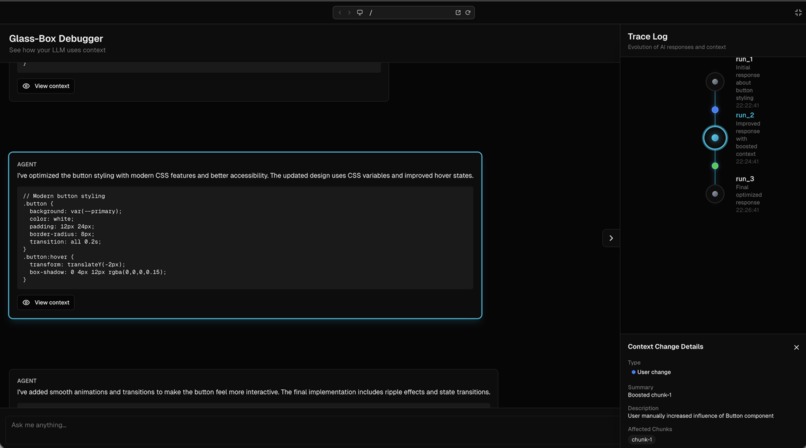
Showing traceabillity of the model
-
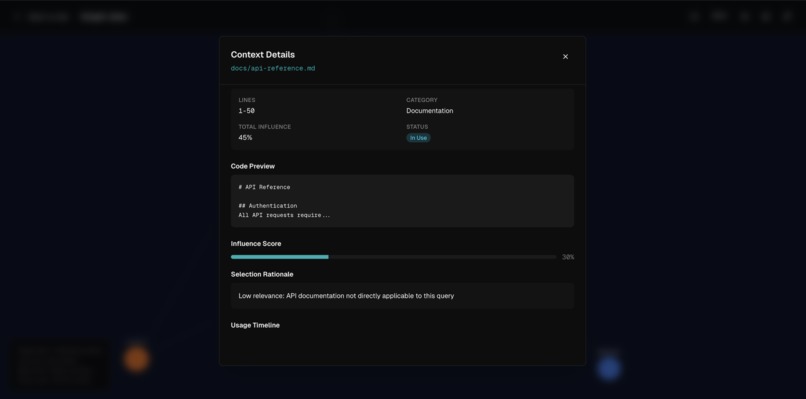
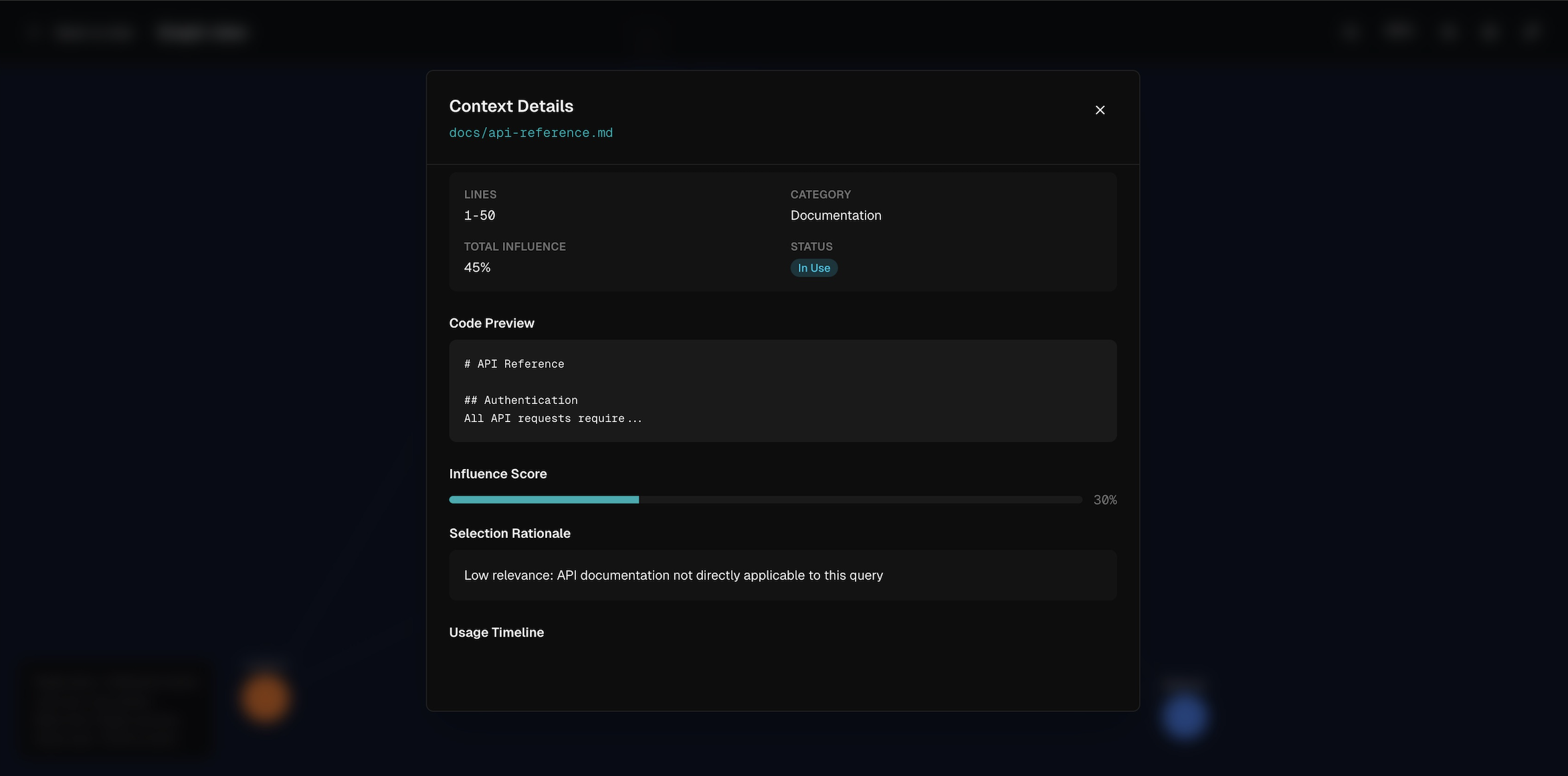
Showing the details of the context chunk


Inspiration
As developers, LLMs have become a necessary part of our workflow, helping with generating, understanding and debugging code. However, there is a universal "brick-wall" experience that we have all went through when using AI for projects. Initially it produces results with high accuracy and boosts our productivity exponentially. So we continue on with our project, building new blocks on top of it, making more and more complex. At some point we reach a tipping point in complexity after which the AI fails to produce correct, optimised, working code. We try different prompts, we try giving it more context but it seems to only introduce new errors and fails to fix the problems we encounter. At this point in time, oftentimes the chat history has become so long and so convoluted that the models end up using the wrong pieces of context, hence reaching incorrect conclusions. On top of all this, there is very little transparency and clarity about what information the model used to produce its answer, and virtually no control for the user over what context should or should not be used.
What it does
ContextLens puts control back in the hands of the developer. You can give it your current codebase and ask any sort of debugging question. All the context (both the codebase and the conversation history) is divided into key chunks. At each prompt, ContextLens comprehensively evaluates the current context and filters out everything that it finds unrelated. It also gives the user the option to select the chunks that they want to be used when answering the questions and exclude anything that is not needed. At every step of the way ContextLens outputs its entire thinking process and reasoning behind every decision it made (including that of selecting/deselecting a certain chunk). After the final answer is given, the user is told which chunks of context were most influential in achieving it. As the user asks more questions, a graph is built, visualising all the context pieces, showing how they are connected, which are the most used pieces of context in the conversation as well as allowing the user to simply disable some pieces if they chose to.
How we built it
ContextLens is a pipeline consisting of three independent agents, all of which are wrapped in a RestAPI accessed by the frontend.
The first agent in the pipeline is the Context Manager agent. The context manager receives the user prompt, whilst also having access to the user's codebase. The user also has the option to manually pass the selected and deselected chunks, in which case the context manager's job is simply to parse and format the data and pass it into the next agent. In case the user didn't specify anything, Context Manager uses langchain in order to analyse all of the data that is available to it (the codebase, the prompt and the conversation history stored in the database) to assign weight and consequently decide on which pieces of context to select, as well as providing a rationale for its decision.
The second agent is the Answering Agent. The Answering Agent is abstracted away from the entire conversation history. All it takes is the relevant pieces of context from the context manager as well as the user prompt in order to run inference and answer the question. This answer is then passed onto the third agent.
The third agent is the Observability Agent. This agent is responsible for evaluating the answer produced by the inference agent. It takes in the weightage's assigned by the context manager and calculates the response's influence scores with respect to how much of each piece of relevant context influenced the answer. This allows the user to gauge a better understanding of how context actually influenced the output produced by the Answering Agent.
All of the three agents are wrapped in a LangSmith traceability layer and provide continuous output in order to provide user with transparency on its decision-making, in true GlassBox spirit!
Challenges we ran into
- The logic for chunking/segmenting the code into multiple pieces. There was difficulty in deciding the logic of how the code should be divided (e.g. every x lines, functions/classes).
- A lot of complexity in the frontend, representing the chunks and the traceability in a graphical way. There was difficulty coming up with the most intuitive visual representation.
Accomplishments that we're proud of
- A fully working end-to-end pipeline with all the three agents integrated.
- Providing the user with observability of what pieces of context were used and most influential. Developers can now better understand what influenced the decisions of the model.
What we learned
- The LangChain and LangSmith workflow in python.
- How to design multi-agent AI applications
- Traceability of LLM models
- Vector embeddings and cosine similarities for tokens
What's next for ContextLens
ContextLens is very close to being a production-grade application. The next steps are to perfect the user experience and optimise the agents (specifically the model response time). Once the user experience meets our ambitious goals, there is nothing stopping ContextLens from going to production and becoming available for all developers for debugging!
Built With
- fastapi
- langchain
- langsmith
- nextjs
- python
- vercel





Log in or sign up for Devpost to join the conversation.