-
-
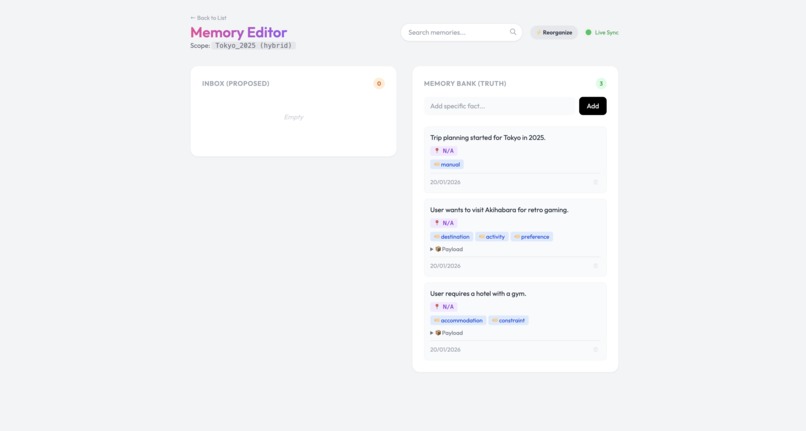
Memory Dashboard
-
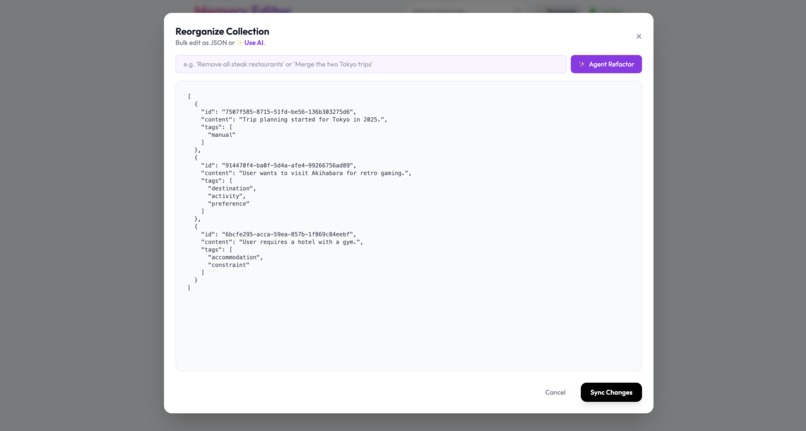
Magic Refactoring tools
-
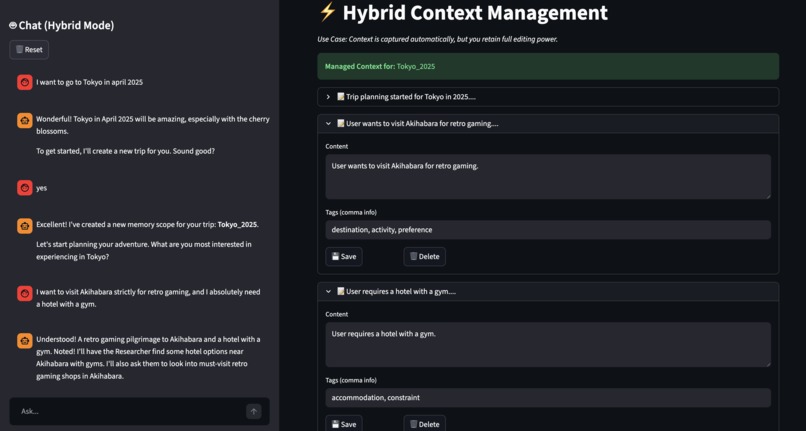
The Hybrid Architecture
-
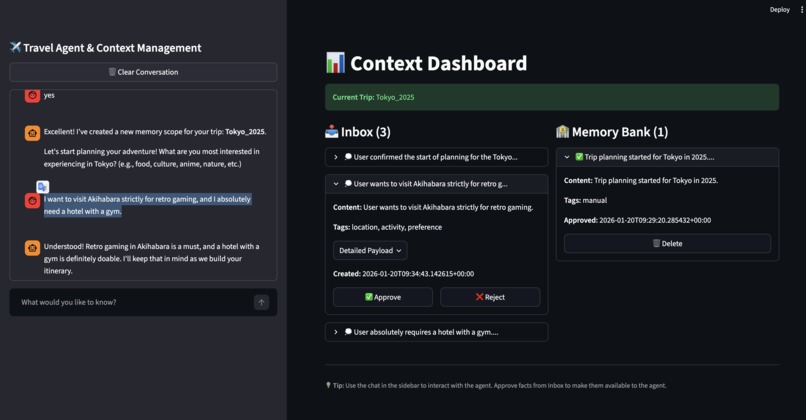
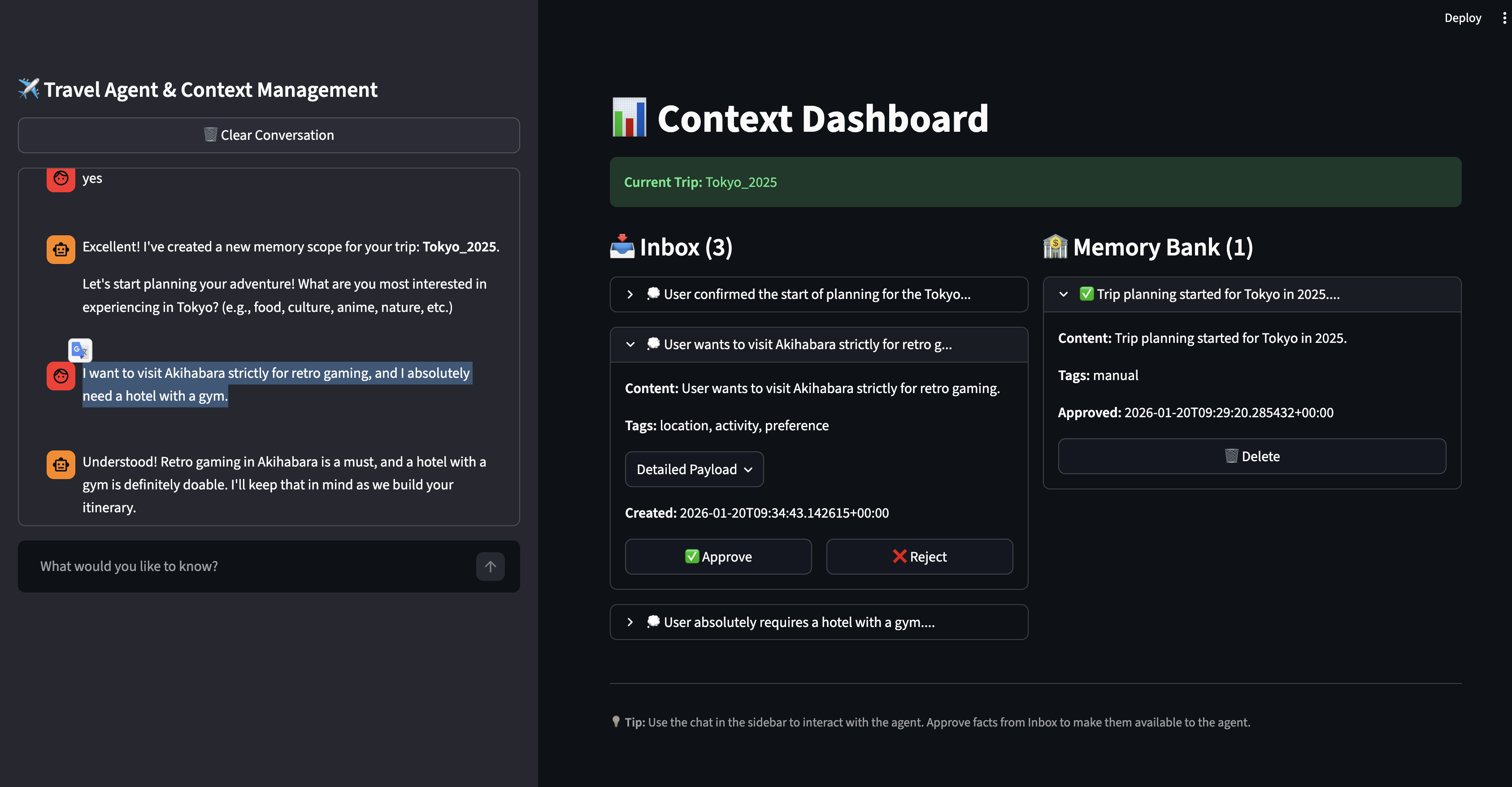
The User-Controlled Architecture
-
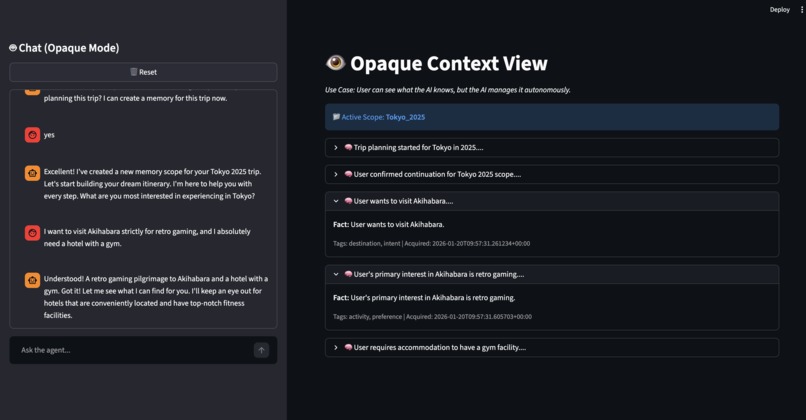
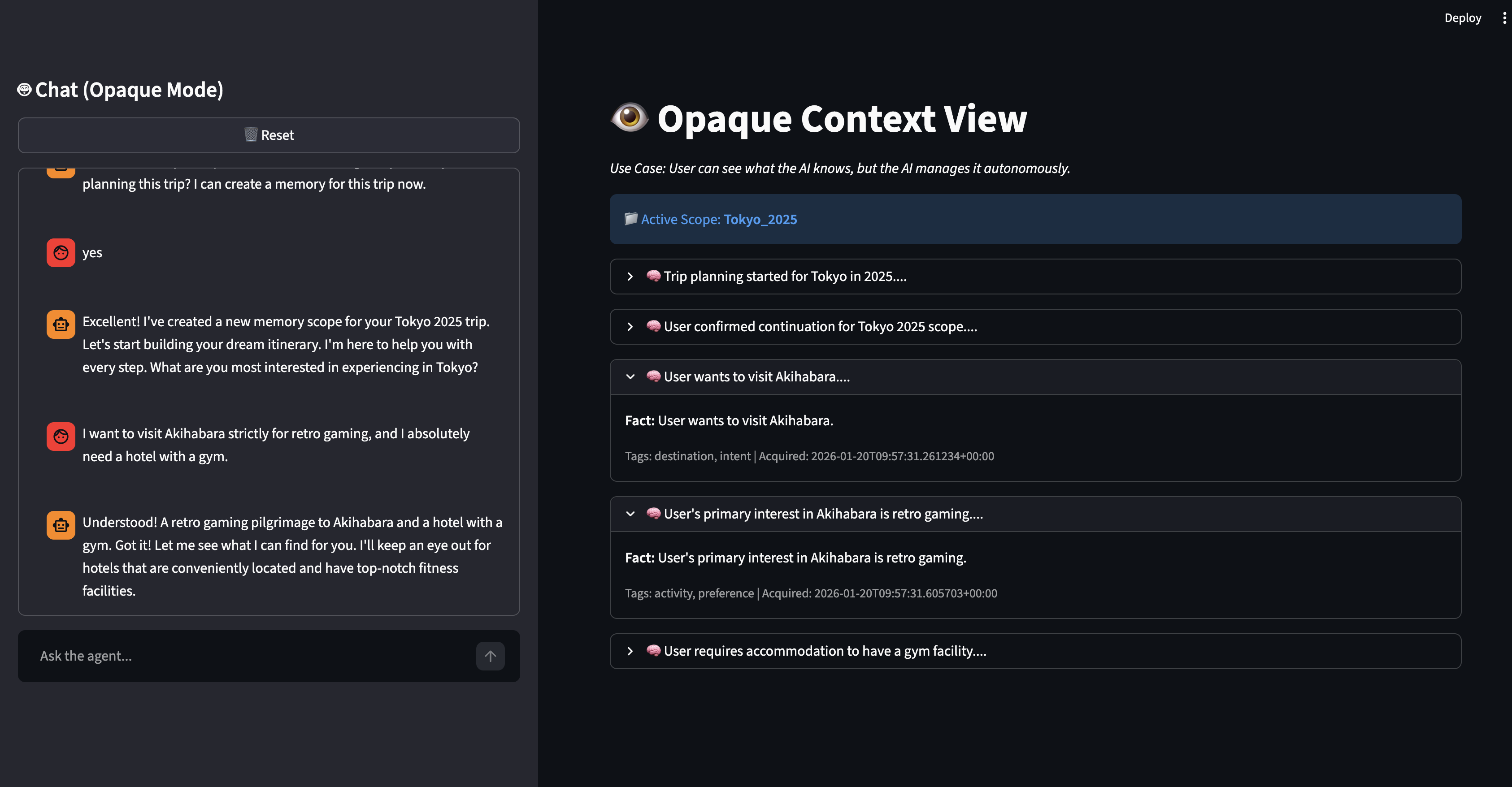
The Opaque Architecture
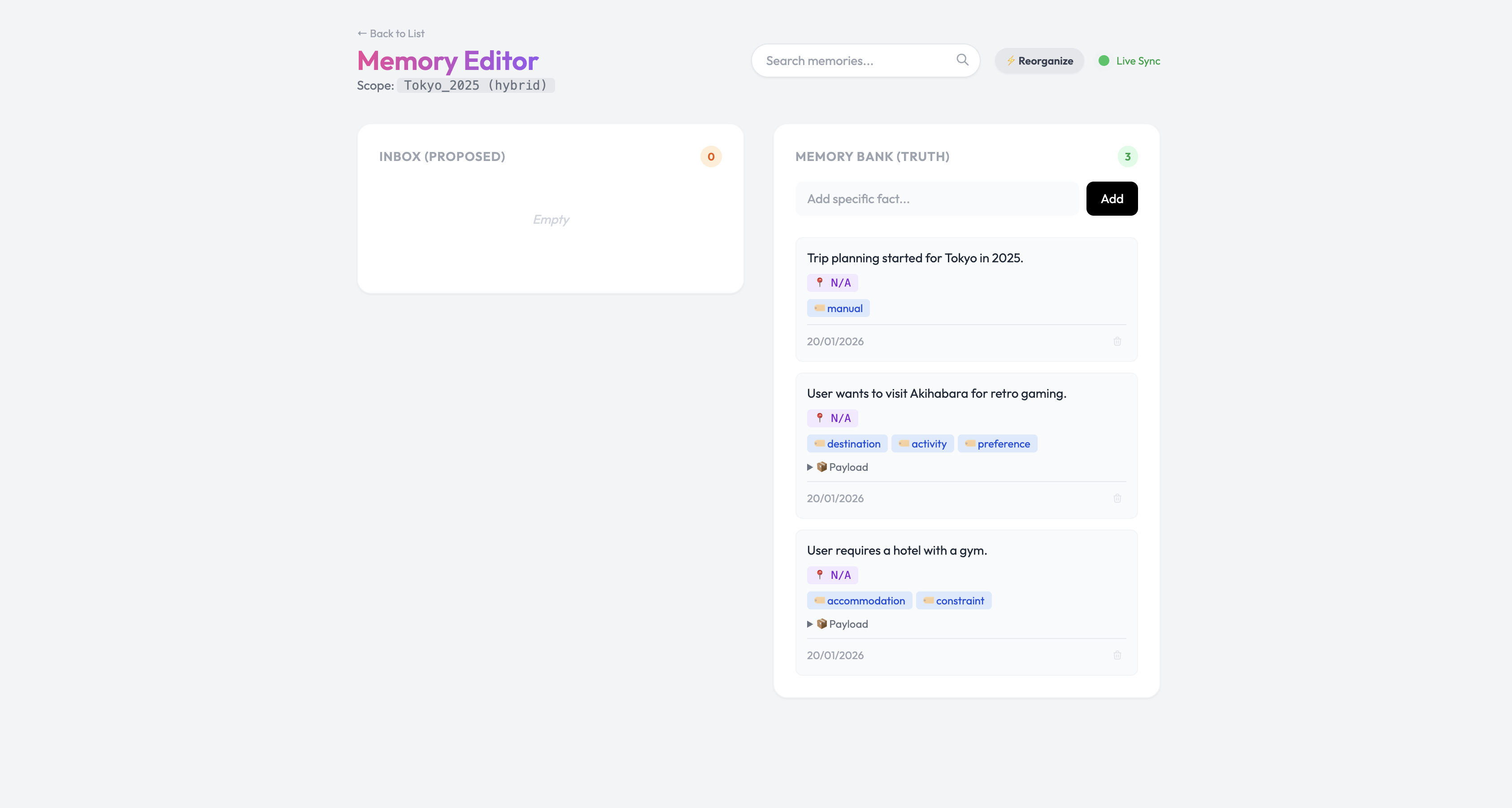
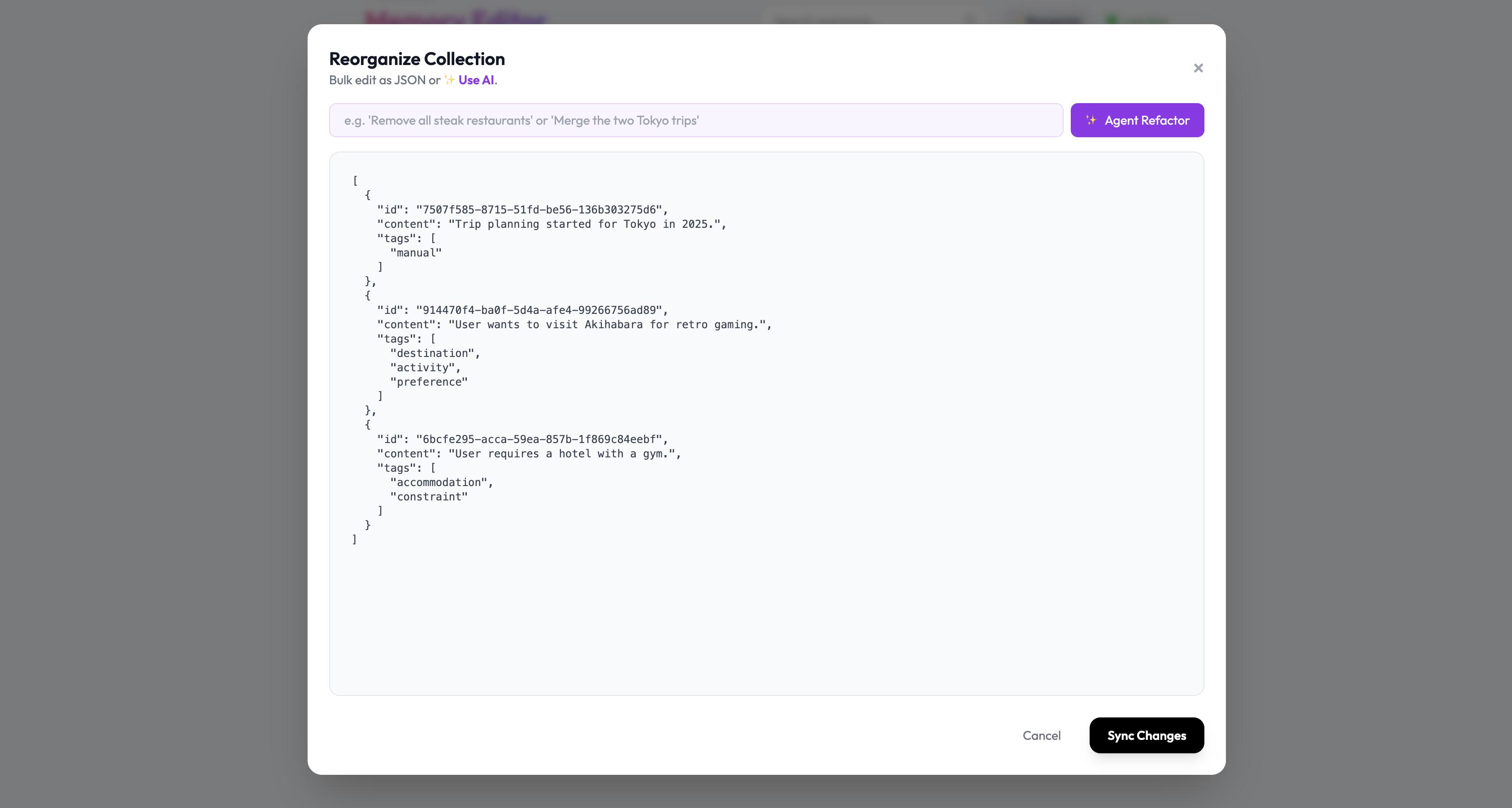
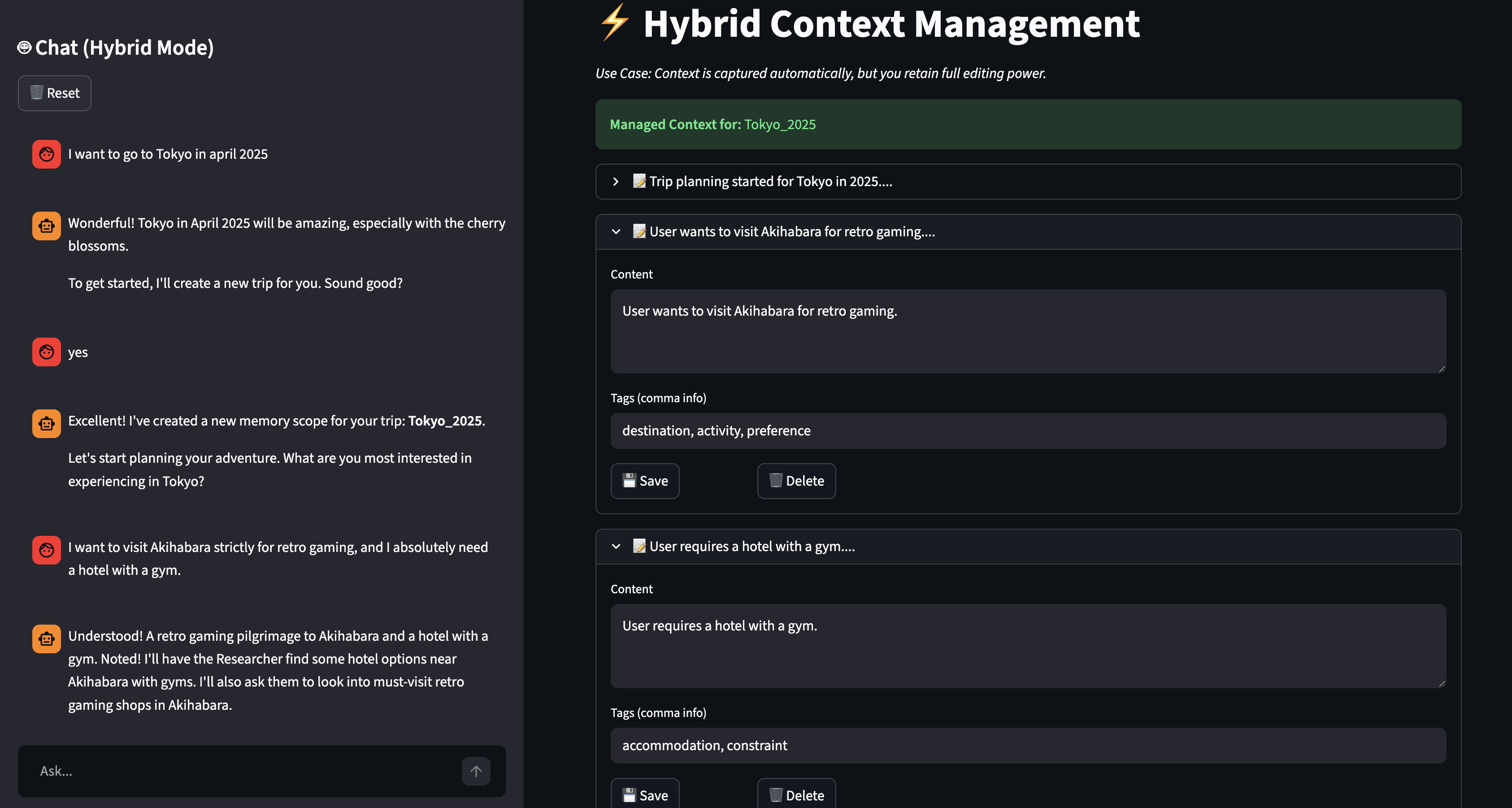
Inspiration
The inspiration for Context Engineering came from a critical observation of the current AI landscape: while everyone is focused on "bigger context windows" or "faster vector databases," almost no one is addressing the User Experience of Memory.
We realized that treating Long-Term Memory (LTM) as a hidden "dump" (the standard RAG approach) leads to a phenomenon we call "Context Poisoning"—where an AI remembers temporary preferences (e.g., "I want a vegan meal for this specific wedding") as permanent facts ("User is vegan"), creating a degraded experience over time.
Memory stops being an add-on and starts behaving like infrastructure. A pragmatic memory system needs to decide what to keep, what to compress, and what to forget. We built this project to prove that this specific decision-making process shouldn't be left solely to algorithms—it requires Human-in-the-Loop governance.
What it does
Context Engineering is a comparative research platform and a proof-of-concept application that demonstrates three distinct paradigms for AI Memory Management:
The Opaque Architecture ("The Black Box"):
- This represents the current industry standard. The AI autonomously saves everything to a vector database without user visibility.
- Result: High friction, low trust, and high susceptibility to "Context Poisoning."
The User-Controlled Architecture ("The Gatekeeper"):
- A "Zero Trust" approach where the AI cannot write to its long-term memory without explicit approval. It proposes facts to an "Inbox," and the user must validate them via a dashboard.
- Result: 100% clean memory, but high cognitive load for the user.
The Hybrid Architecture ("The Gardener"):
- Our proposed solution. The AI ingests memory optimistically to maintain conversation flow but provides "Magic Refactoring" tools. Users can issue natural language commands like "Forget all my budget constraints from last year" to clean up their graph.
- Result: The perfect balance between automation and control.
How we built it
We built a monorepo containing three independent AI agents to strictly isolate and compare the architectures:
- Core Logic: Python 3.10 with LangChain and LangGraph for orchestrating the agentic loops.
- Memory Backend: Weaviate (Vector Database) for storing semantic facts (documents) and the memory graph.
- LLM: Google Gemini Pro and Flash for the reasoning and extraction engines.
- Frontend: Built with Streamlit to rapidly prototype the "Memory Dashboard" and "Inbox" interfaces necessary for the User-Controlled demos.
- Testing: We developed a custom unit testing suite ("The Vegan Wedding Scenario") to simulate conflicting user constraints and mathematically measure "Memory Drift."
Challenges we ran into
The biggest technical challenge was "The Illusion of Autonomous Correction." During our stress tests (the "Vegan Wedding" scenario), we tried to give the Opaque Agent tools to "fix its own memory." We found that instead of surgically deleting the incorrect memory (e.g., "User loves steak"), the LLM would often just add a new memory saying "User doesn't want steak right now." This resulted in a vector database cluttered with contradictory layers of "corrections," doubling the token usage and confusing the retrieval system. This failure proved our hypothesis: Algorithmic memory management works for ingestion, but fails at curation.
Accomplishments that we're proud of
- Defining "Context Poisoning": We successfully demonstrated and reproduced a flaw where temporary context becomes permanent noise in standard RAG architectures.
- The "Inbox" Pattern: We successfully implemented a "Memory Inbox" (similar to a code pull request) which proved to be the only reliable way to prevent memory degradation in critical applications.
- Weaviate Integration: We went beyond simple vector storage and used Weaviate's strict filtering and metadata to implement "Scoped Memory" (isolating facts by project/context).
What we learned
Our study concludes with a strong thesis: Long-Term Memory is not just a backend optimization problem; it is a Tier-1 UX Challenge. Trust requires visibility. Users will not trust an agent that claims to "know them" unless they can see, edit, and delete what the agent knows. The solution to AI hallucinations in personalized agents isn't just a better database—it's a better Frontend for Memory Management.
What's next for ContextEngine
- Implement Graph RAG to improve the relational understanding between facts (e.g., understanding that "Budget" validates "Project A" but conflicts with "Project B").
- Use this logic in real-world scenarios to see it in action and improve it.


Log in or sign up for Devpost to join the conversation.