-
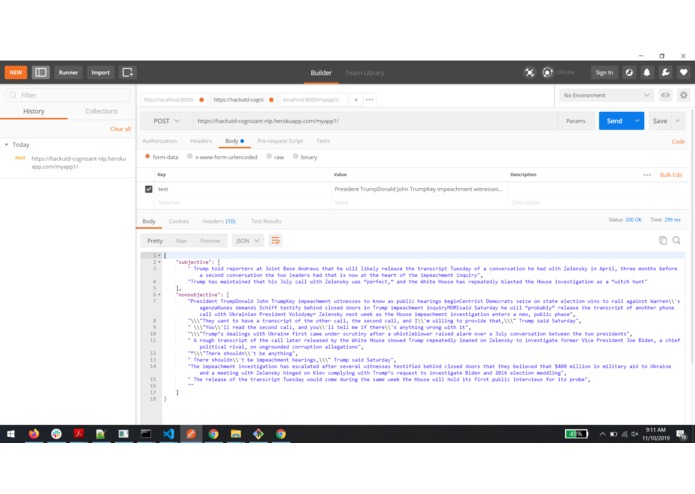
REST API - Response structure
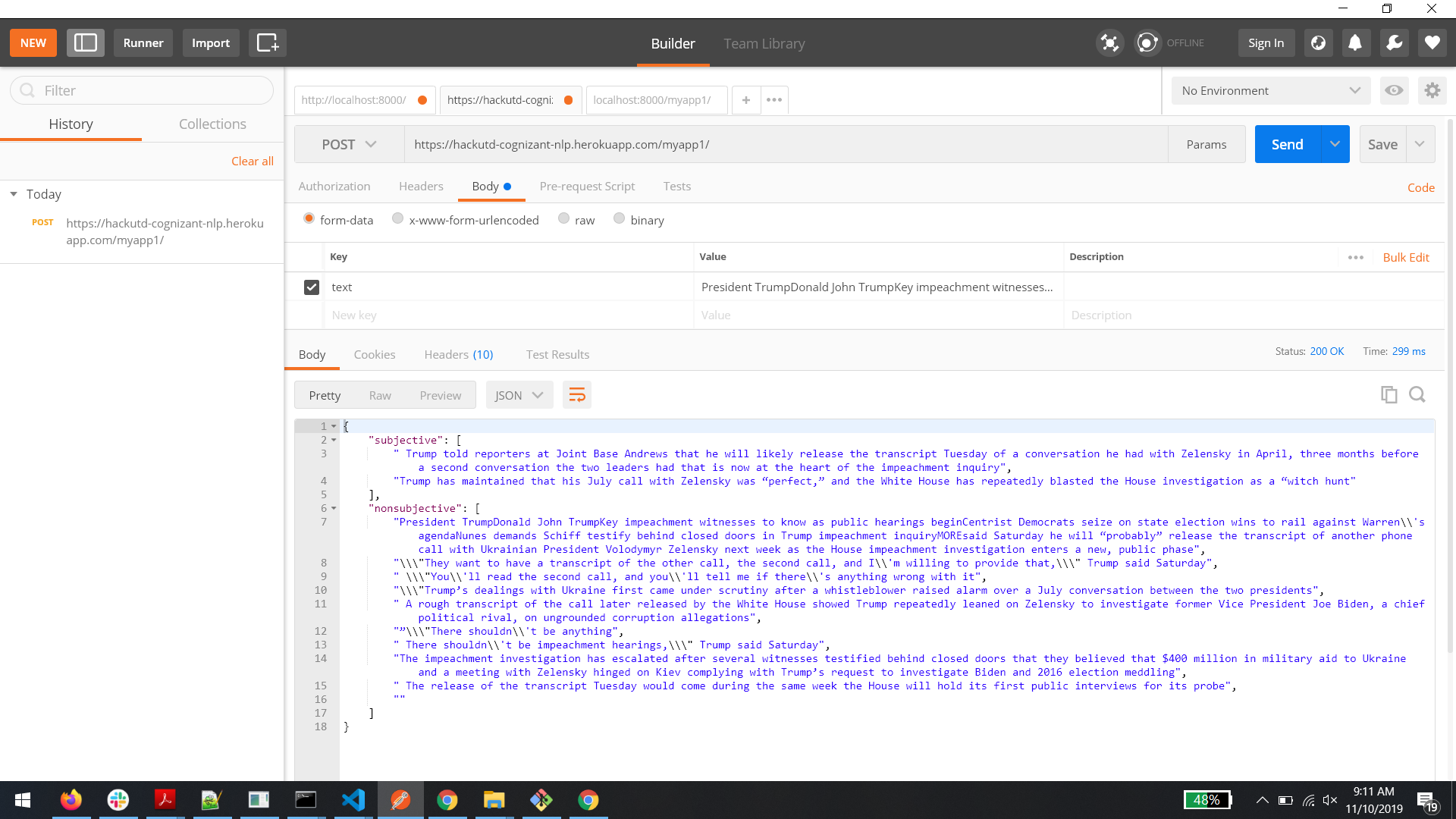
Inspiration
With the elections approaching close, it has become increasingly difficult to convey unbiased information to readers of blog posts. The staggering variety of words and phrases have made it extremely intricate to understand what parts of an article are biased and what parts are not. This project aims to utilize Natural Language Processing techniques to classify various fragments of a post into subjective and non-subjective sentences
What it does
The project provides a web browser extension using which the user can highlight any segment on a webpage and the extension displays the subjective and non-subjective parts in the highlighted segment
How we built it
The project is divided into two major modules
- Browser extension
- REST API for the backend carry out NLP Sentiment Analysis and classifying subjective statements in an article
The Browser extension is implemented using Javascript and HTML and CSS and would call the REST API when a segment of text is highlighted and the mouse cursor is released.
The REST API is developed using Python - Django. Currently, the API has only one endpoint that can be called via a POST request with the following name text in the request body. The extension upon mouseover collects the highlighted text and sends it to the REST API. The API utilizes a model previously trained by leveraging Sentiment Analysis using Naive Bayes to tag each sentence with a subjectiveness level with a certain confidence. The model classifies each sentence in a given paragraph as subjective with a certain degree of accuracy. A threshold is set on the accuracy of the subjectiveness level which filters any non-subjective sentences.
Currently, the API is hosted on Heroku under the url https://hackutd-cognizant-nlp.herokuapp.com/myapp1/
The API expects a POST request with only one field in the body text - The content to be analyzed.
A sample response of the API is attached to this submission.
Challenges we ran into
- Understanding what really "subjective sentence" means in the context of a Politically colored article
- Constructing a workflow to classify a sentence as "subjective" in a long paragraph
- Integrating the individual modules into a full pipeline and deploying it on a cloud-based service (Heroku)
- Unstable internet connection during development.
Accomplishments that we're proud of
- The way the team collaborated and worked towards building a functioning prototype under 24 hours
- Overcoming our technical shortcomings and learning several new things
What we learned
- How to leverage Natural Language Processing(NLP) & Naive Bayes to classify sentences and carry out Sentiment Analysis.
- How to build an end-to-end functioning prototype and deploy it quickly using cloud services.
- Building a web browser extension that can interact with a REST API that uses a Classifier
What's next for ContentAnalyzer
- To implement a reverse feedback mechanism so that the model can learn from it's predicted subjective sentences
- To consider more complex structure such as passive, active voices and figures of speech to train the model
Links to the project source code
- The REST API - https://github.com/harsha993/hackutd-cognizant-nlp-rest.git
- The Chrome Extension - https://github.com/rabindrayadav9596/ChromeExtension.git
Log in or sign up for Devpost to join the conversation.