-
-
CouncilView_Case1
-
GraphView_Case3
-
GraphView_Case2
-
BenchMark
Inspiration
A few years ago, my grandfather was diagnosed with lung cancer. By the time it was found, it was already late. Before that diagnosis, he had been to many doctors, gone through many scans, and answered the same questions over and over. No single specialist saw the whole picture early enough to catch it.
That experience stayed with me. Diagnostic error isn't just numbers in a report. It's families sitting in waiting rooms wishing someone had asked one more question, or looked at one more lab value.
I'm not a doctor, and CONSILIUM won't replace one. But it tries to do something specific: make sure no important angle gets missed. When seven specialist agents look at the same case from seven different perspectives, challenge each other, and have to defend their reasoning with evidence, fewer things slip through.
That's why I built this.
What it does
You give CONSILIUM a patient case — symptoms, labs, history.
Step 1: A triage agent classifies how complex the case is. A common cold doesn't need seven specialists arguing about it. Sepsis does.
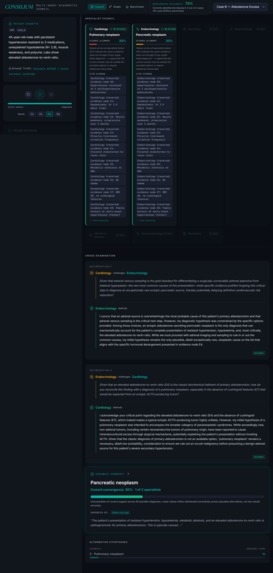
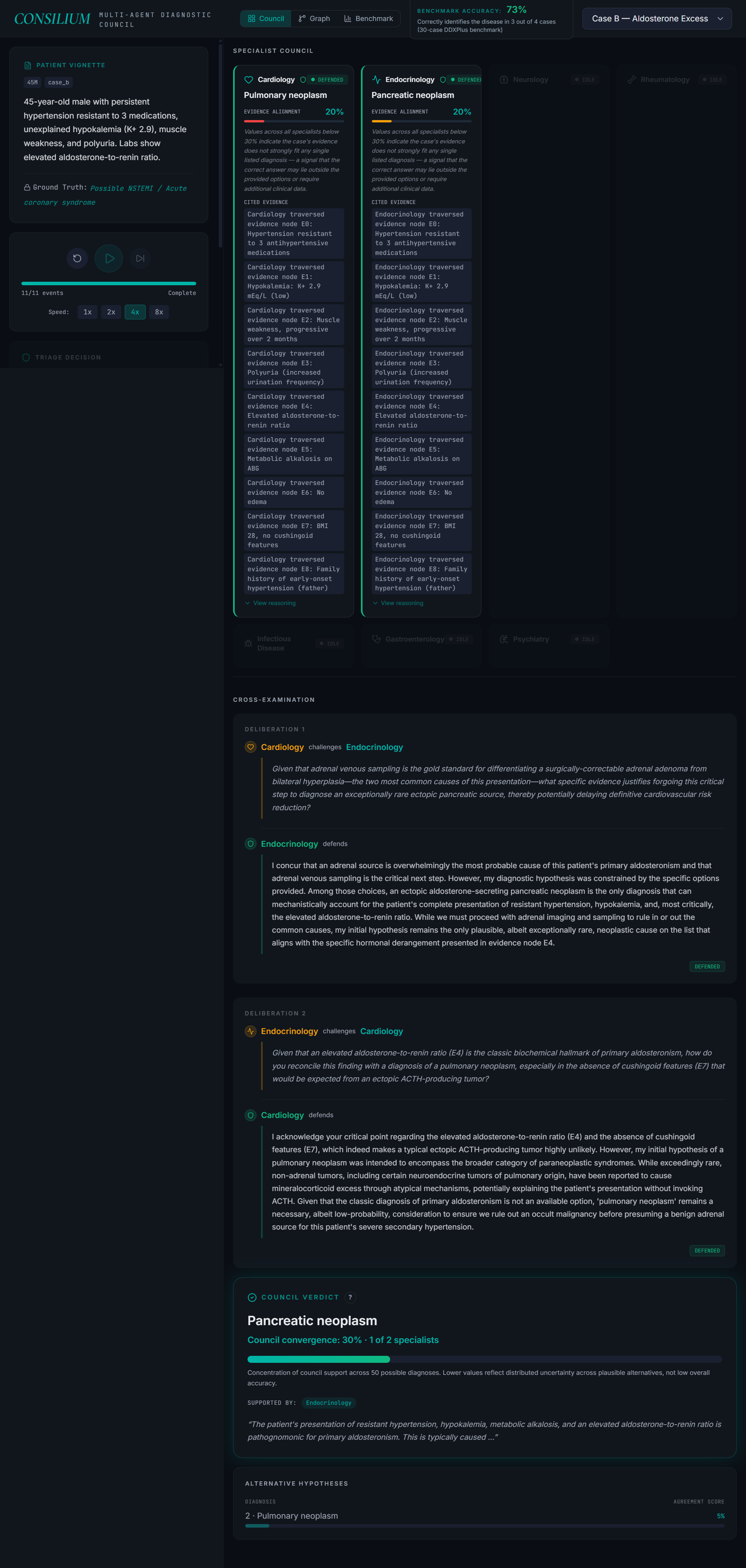
Step 2: The right specialists get invoked. Cardiology, Endocrinology, Neurology, Rheumatology, Infectious Disease, Gastroenterology, Psychiatry. Each one analyzes the case from their own lens and posts their hypothesis with citations to specific patient evidence.
Step 3: The specialists cross-examine each other. If Cardiology proposes one thing and Endocrinology disagrees, they have to defend their position with evidence. They can't just back down because someone challenged them — they need to point to something real.
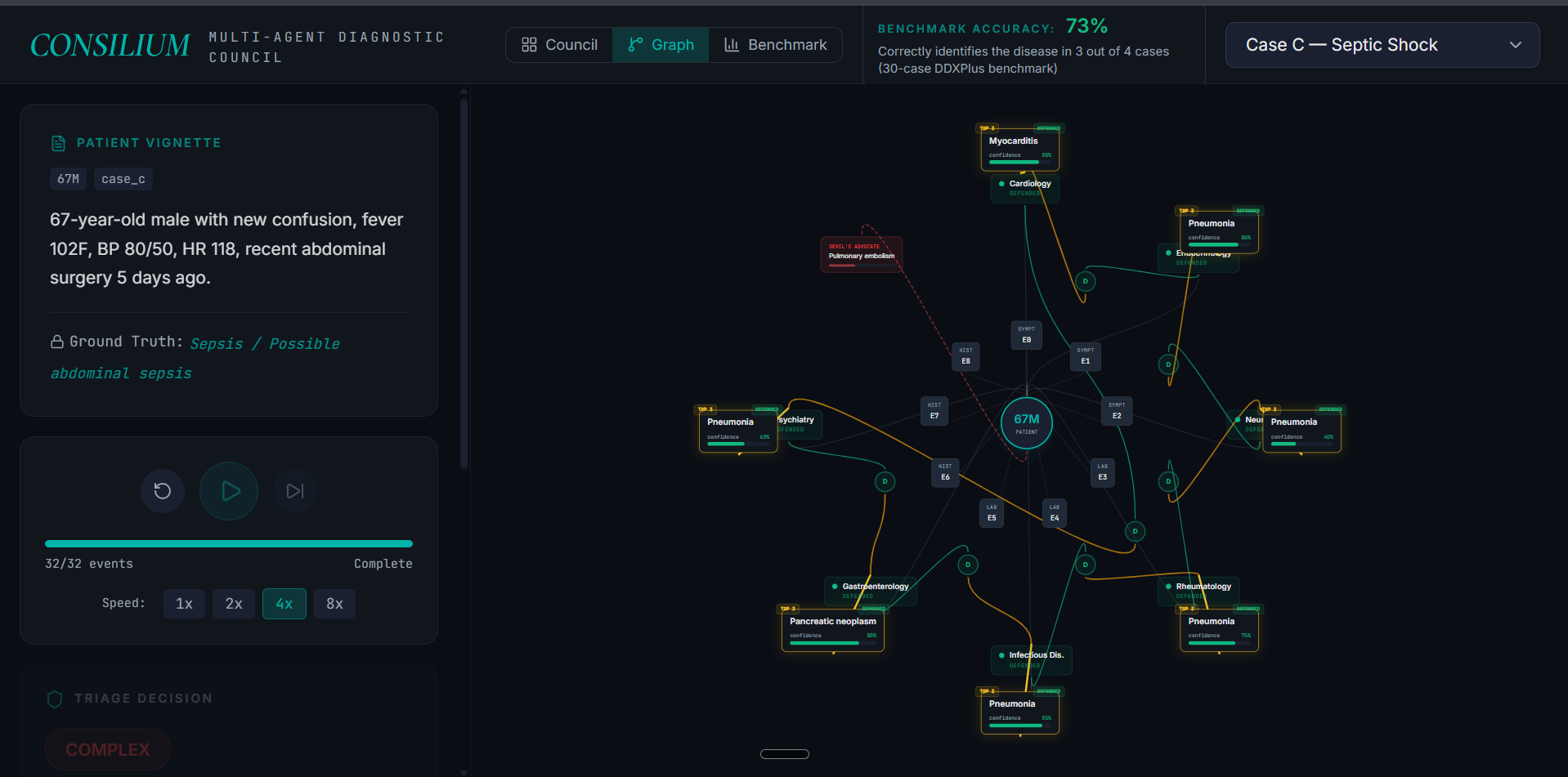
Step 4: For complex cases, a Devil's Advocate agent argues against the leading diagnosis to surface what's being missed.
Step 5: The moderator aggregates everything and returns a ranked top-3 differential.
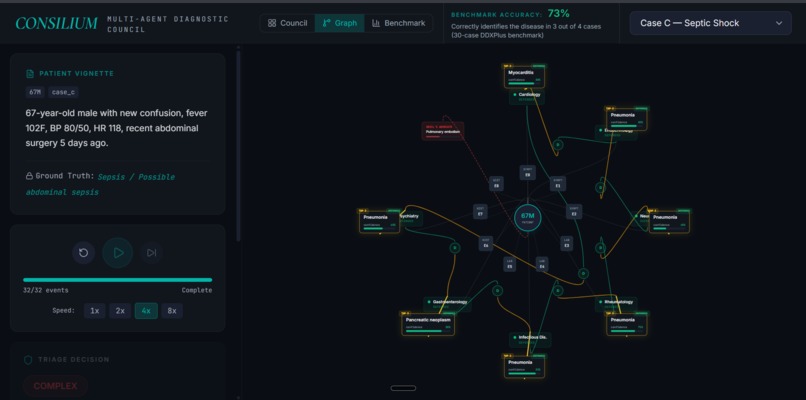
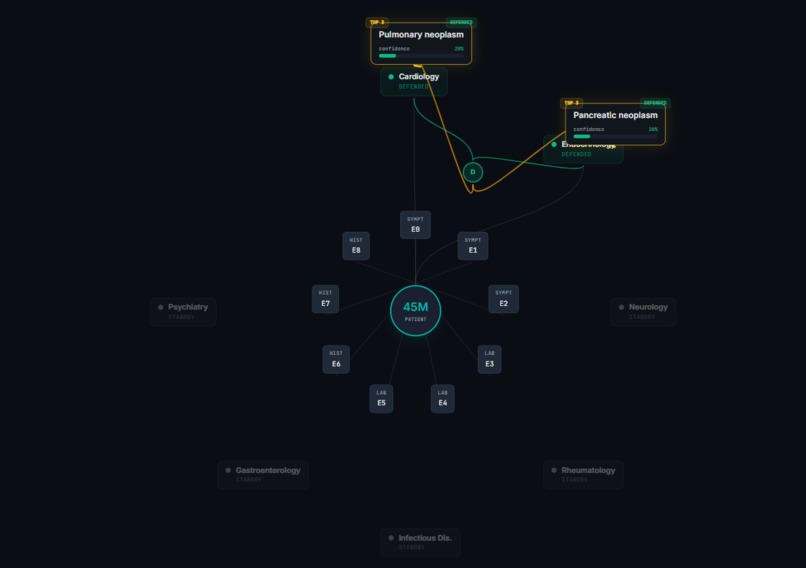
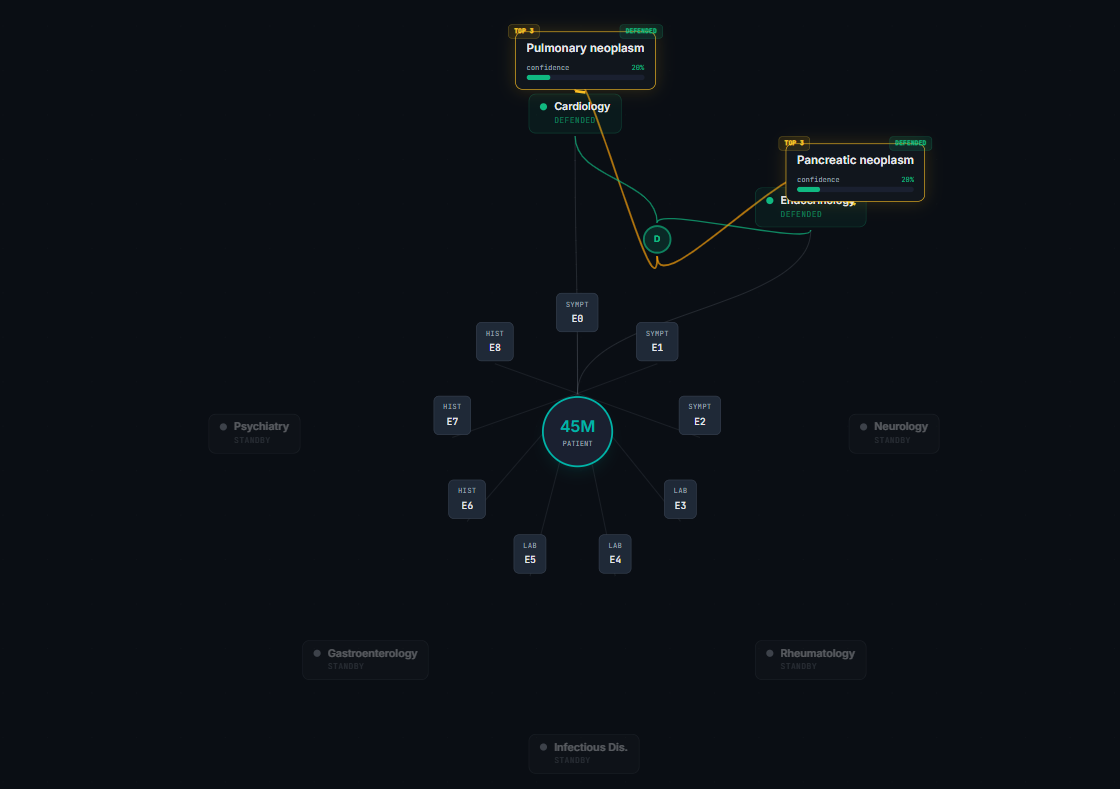
The whole thing runs as a graph. Patient at the center, evidence nodes around them, specialists traversing the graph, hypotheses connected to the evidence they cite. You can actually watch it happen.
How we built it
Language: Jac, the agentic AI language by Jaseci Labs. The whole system is built around walkers traversing a patient graph.
LLMs: Gemini 2.5 Pro for the seven specialists (heavy reasoning) and Devil's Advocate. Gemini 2.5 Flash-Lite for the Triage walker (routing decisions don't need expensive reasoning).
byLLM 0.6.7 plugin for native LLM integration inside Jac walkers.
Frontend: React + Vite + TypeScript + Tailwind + framer-motion. Reactflow for the graph visualization. Two views — a Council view that reads like a deliberation transcript, and a Graph view that shows the agents actually traversing the patient graph in real time.
The frontend uses a spotlight-focus playback engine — as the trace plays back, the UI dims unrelated elements and brightens what's currently happening, so you can actually watch the council think. The Graph view shows the same graph Jac operates on at runtime.
Datasets: DDXPlus for benchmarking (132K synthetic patients across ~50 pathologies). Demo cases are synthesized vignettes spanning SIMPLE / MODERATE / COMPLEX complexity tiers.
Demo playback: Real agent runs are pre-recorded as JSON traces. The frontend replays them at controlled speed so the 3-minute demo can show a full deliberation that actually took 5+ minutes to compute.
Challenges we ran into
byLLM cross-file typed-return bug. Compiler couldn't handle typed return objects across files. Worked around with plain string returns and a safe JSON parser. Filed the issue upstream.
Config A vs Config B. First design called the LLM at every graph node — 60 calls per case, 11 minutes per case, crashed on large cases. A/B tested and rebuilt to a leaner config: 9 calls per case, 3 minutes per case, identical accuracy. Sometimes the right answer is to do less.
Confidence collapse during cross-examination. Specialists capitulated under challenge even when they were right. Fixed by requiring evidence-backed concessions: specialists default to DEFEND unless challenged with specifically stronger evidence.
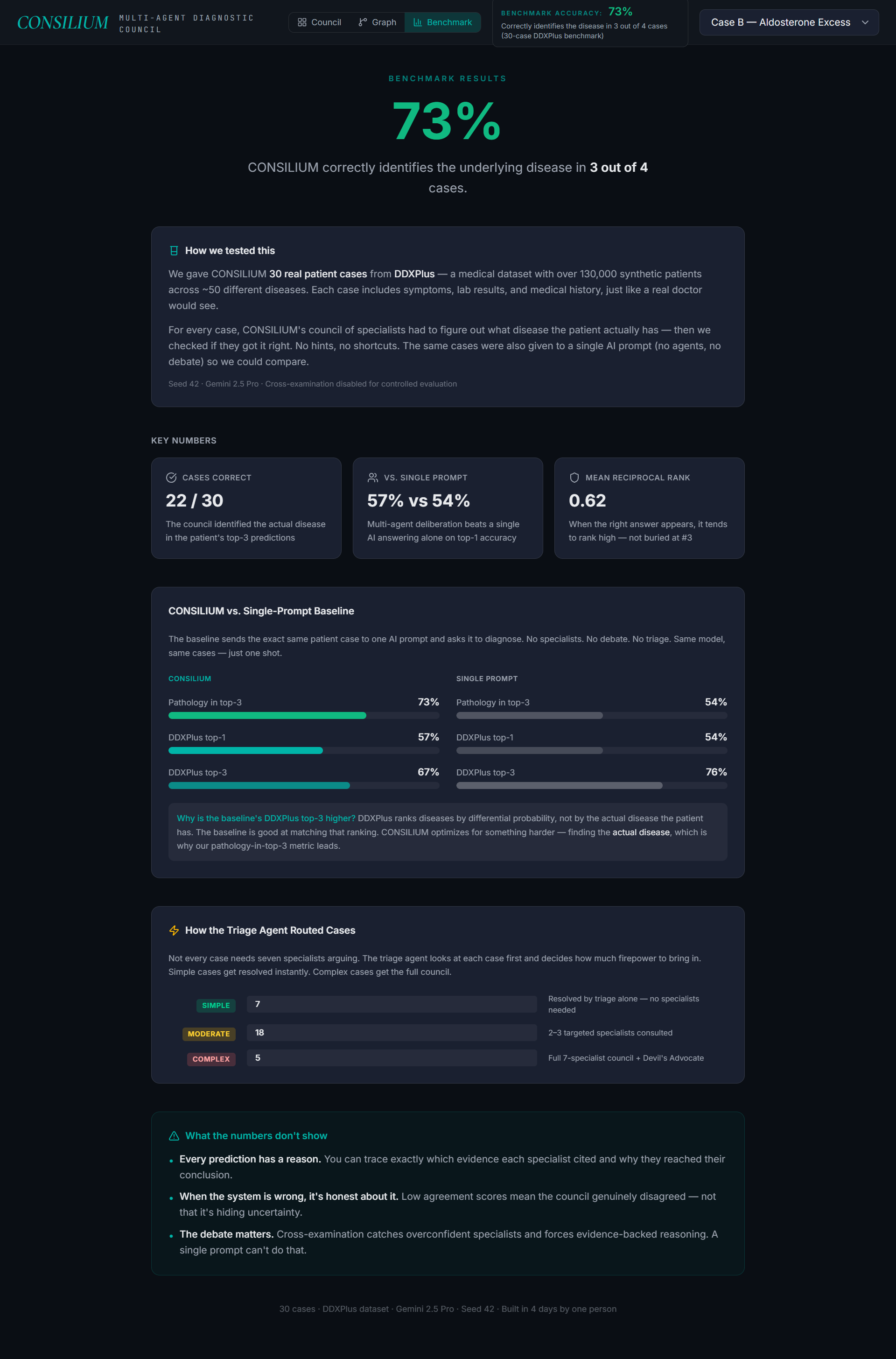
The benchmark wasn't measuring what mattered. DDXPlus's preferred differential ranking sometimes preferred related-but-different labels over the actual disease. We added a second metric — pathology-in-top-3 — that scores against the actual disease. That's the metric we lead with.
Accomplishments
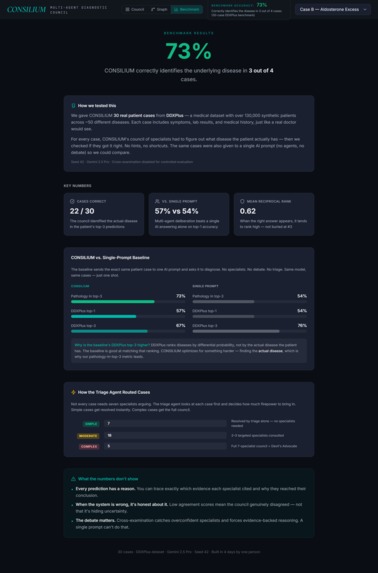
- 73% pathology-in-top-3 accuracy on 30 standardized cases. The system optimizes for identifying the actual disease over matching DDXPlus's preferred differential ranking — every prediction is backed by citations to specific patient evidence.
- Single-prompt baseline scores 54% top-1 on the same dataset. Multi-agent deliberation with triage gatekeeping produces both higher medical correctness and safer routing.
- Triage correctly identifies critical cases. On a sepsis vignette, triage returned 0.0 confidence and forced full council with four red flags — no false confidence on a critical patient.
- SIMPLE cases complete in ~20 seconds vs 3+ minutes for full council. The system doesn't burn compute on routine presentations.
- Every hypothesis is cited back to specific evidence nodes. Auditable reasoning, not a black box.
- All built in 4 days, in a new programming language, by one person.
What we learned
Architecture matters more than prompt engineering. The bigger wins came from adding a Triage walker and forcing specialists to defend their reasoning under challenge — not from prompt tuning.
Honest evaluation matters more than impressive numbers. When the benchmark showed our system was "wrong" on cases where it was medically right, we added a second metric instead of hiding the result.
Multi-agent systems need architectural humility. Sometimes the most useful thing one agent can do is route a case to a different agent and step out of the way.
What's next
CONSILIUM today is a one-shot deliberation. The product I want to ship is a consumer companion that helps families be better patients — not a replacement for doctors.
Pre-appointment preparation. Paste your symptoms and recent labs before a doctor visit. CONSILIUM tells you the three most likely things this could be, the questions to ask, and the tests worth requesting.
Family Health Memory. A graph that grows across visits and years, so when the seventh doctor sees a patient, the system has already noticed the pattern across the previous six visits that no individual doctor saw.
Red-flag escalation. The same triage that prevents over-diagnosis on benign cases catches under-diagnosis on critical ones — sepsis, stroke, cardiac patterns — and tells you to seek immediate care.
WhatsApp-native delivery. Indian families don't install apps. They use WhatsApp every day. Send a voice note, get back a deliberated second opinion with citations and next-step recommendations.
Multilingual. Internal reasoning in clinical English. Explanations back in Hindi, Tamil, Telugu, Bengali. Built for India first.
Trust through transparency. Every recommendation shows which specialist said what, citing which evidence. If the system is uncertain, it says so — and tells you which specialist disagrees and why.
The bet: most consumer health AI either tries to replace doctors (which families don't trust) or just summarizes WebMD articles (which doesn't help). CONSILIUM helps you walk into your real appointment with the right questions and the right context. A companion for families, not a clinical tool.
Built With
- byllm
- ddxplus
- framer-motion
- gemini
- gemini-2.5-flash-lite
- gemini-2.5-pro
- jac
- jaseci
- lucide-react
- medqa
- python
- react
- reactflow
- tailwindcss
- typescript
- vertex-ai
- vite


Log in or sign up for Devpost to join the conversation.