-
-
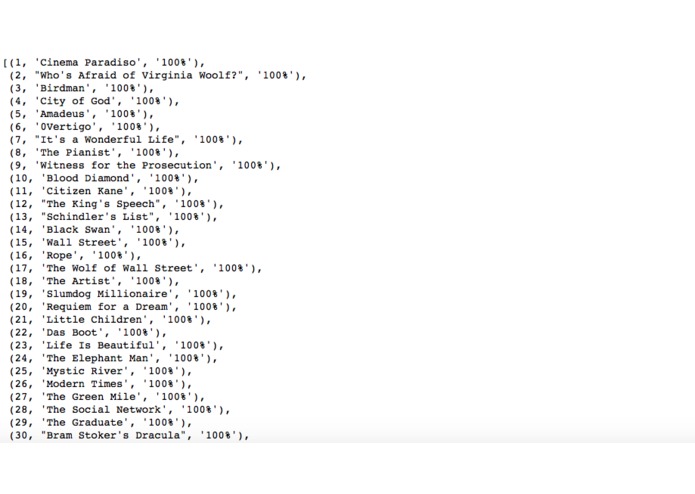
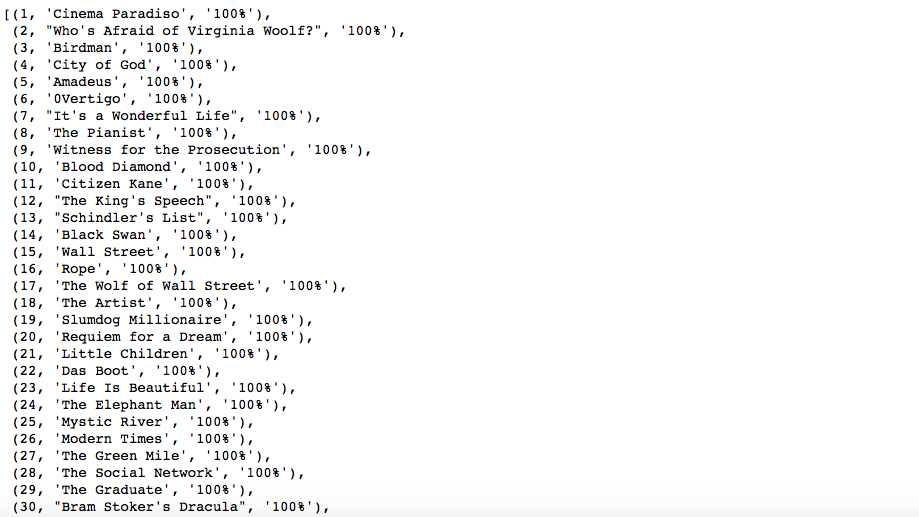
Rank of drama movies based on small datasets. The percentage represent the relative value of the rank. They normalise given enough data.
Inspiration
We were thinking about how critic bias heavily affects ratings for movies, and we wanted to look for a definitive, algorithmic method of ranking movies that would factor in crowd sourced data and eliminate bias.
What it does
The application collects a movie from the user that is searched for in our database using the BoyerMooreHorspool Algorithm, and compares it to a movie generated randomly from our database, which we have web-scraped. The user selects one movie over the other, and we use this binary system to create an adjacency matrix for a graph where each movie is a node. Using the Kendall-Wei Algorithm in a data abstraction of a graph. We find the largest eigenvector by computing the corresponding eigenvalues, and rank the movies using this algorithm. The application contains profiles for different users and stores which movies they follow, providing their calculated rankings. The same system exists for albums and books. The user can also enter a list of his own objects which he wishes to rank.
How I built it
We used lxml to web-scrape my data from various webpages. The data was stored in a dictionary to make searching more efficient bold(Θ(n log(n)))bold average time. We then implemented a data abstraction of graphs where we created classes for different categories of films and entertainment. This was combined with a function that took a parameter as the user's choice of movie/album/book, and stored that in a list to ensure no two movies were compared more than once. The matrix value was assigned a value of 1 if the movie was selected and 0 otherwise. This created the adjacency matrix. We computed the eigenvalues and eigenvectors using our knowledge of linear algebra and the maximum eigenvector gave us the ranking, which we outputted.
Challenges I ran into
Determining which algorithm to implement, including Hamiltonian Paths and Probabilistic methods to compute eigenvalues for large matrices. Integration of front-end and back-end web-development.
Accomplishments that I'm proud of
Learning to implement Graph Theory,Data Abstract Classes! Effectively employ numerous sorting algorithms to minimise computing time.
What I learned
Web-Scraping, Ranking Algorithms in Graph Theory(Hamiltonian Paths, Kendall-Wei Algorithm), String searching algorithms such as BoyesMooreHorspool, working with multiple classes, representation of Graphs, Edges and Nodes in Python.
What's next for Consensus
Integrating the back-end and front-end to make it an official web-application. Offering real time updates for newly released movies and their latest ratings.

Log in or sign up for Devpost to join the conversation.