-
-
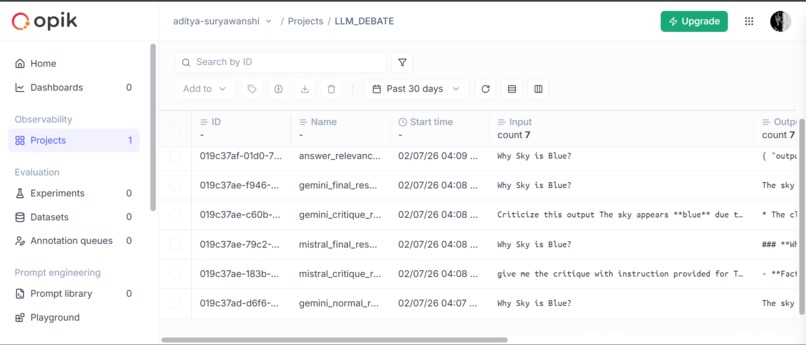
Comet Opik Tracing
-
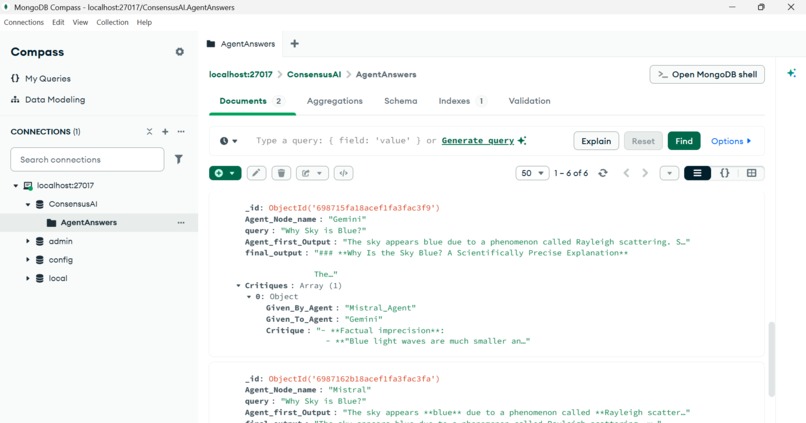
Central Authority
-
A2A and Server
-
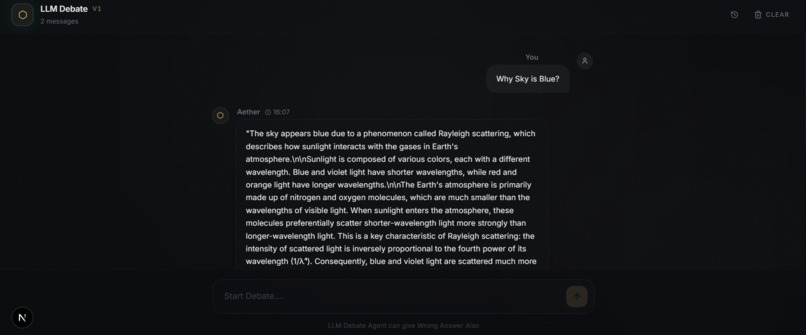
Frontend and Final Answer
🧠 LLM Debate Agent
🧩 Problem Statement
Large Language Models (LLMs) are powerful, but they suffer from hallucinations, shallow reasoning, hidden assumptions, and overconfidence.
In real-world usage, users often rely on a single model’s answer, which can be:
- Factually incorrect but confidently stated
- Incomplete or oversimplified
- Biased by one model’s training data
- Missing edge cases or implicit assumptions
Today’s AI systems lack a structured, automated mechanism to challenge, verify, and stress-test LLM outputs before presenting them to users.
Humans solve this problem through peer review and debate.
LLMs don’t — unless we design it.
🎯 Core Idea
What if LLMs could debate each other like experts on a review panel before answering the user?
Instead of trusting a single model:
- Multiple LLMs independently answer the same query
- Each model critiques the others
- Weaknesses, gaps, and assumptions are exposed
- The most robust answer is selected or synthesized
This project builds a multi-agent debate and orchestration system to do exactly that.
💡 Solution Overview
The system implements a multi-level orchestration architecture where:
- A Supervisor Agent receives the user query
- The same query is dispatched to multiple LLM agents (Gemini, Mistral, OpenAI, etc.)
- Each agent produces an independent answer
- A Central Authority:
- Stores all answers
- Coordinates critique rounds
- Ensures agents critique other agents, not themselves
- Stores all answers
During critique rounds, agents analyze responses for:
- Factual inaccuracies
- Missing assumptions
- Logical gaps
- Unsupported claims
After a bounded number of debate rounds, the system either:
- Allows the Supervisor to select the best answer, or
- Presents multiple debated answers to a human-in-the-loop for final selection
This closely mirrors real-world peer-review workflows, but in a fully automated system.
✨ Key Features
✅ Multi-LLM Debate
- No single-model dependency
- Significantly reduces hallucination risk
✅ Structured Critique
- Rule-based critique, not casual feedback
- Enforced through strict prompt design
✅ Bounded Debate
- Fixed number of debate rounds
- Prevents infinite loops
✅ Asynchronous Agents
- Agents do not block or wait
- Scales efficiently as more models are added
✅ Model-Agnostic
- Easily add or remove LLMs
- Future-model friendly
✅ Optional Human-in-the-Loop
- User can choose the final answer
- Ideal for high-stakes or sensitive decisions
🧠 Why This Is Different (and Real)
This is not just a fancy chatbot.
It addresses a real and recurring question:
“How do I trust an AI answer?”
Instead of relying on:
- Prompt tricks
- RAG band-aids
- Model fine-tuning
This system applies a proven human strategy:
peer review and debate.
🏗️ What I Built
I have created the LLM Debate Agent, a multi-agent reasoning system designed to improve the reliability, transparency, and trustworthiness of Large Language Model outputs by replacing single-response AI with a structured debate architecture.
The system orchestrates multiple independent LLM nodes (including Gemini and Mistral) that reason from different perspectives, critique each other’s responses, and produce refined final answers. A Supervisor Agent evaluates all outputs and returns the most relevant and defensible response to the user.
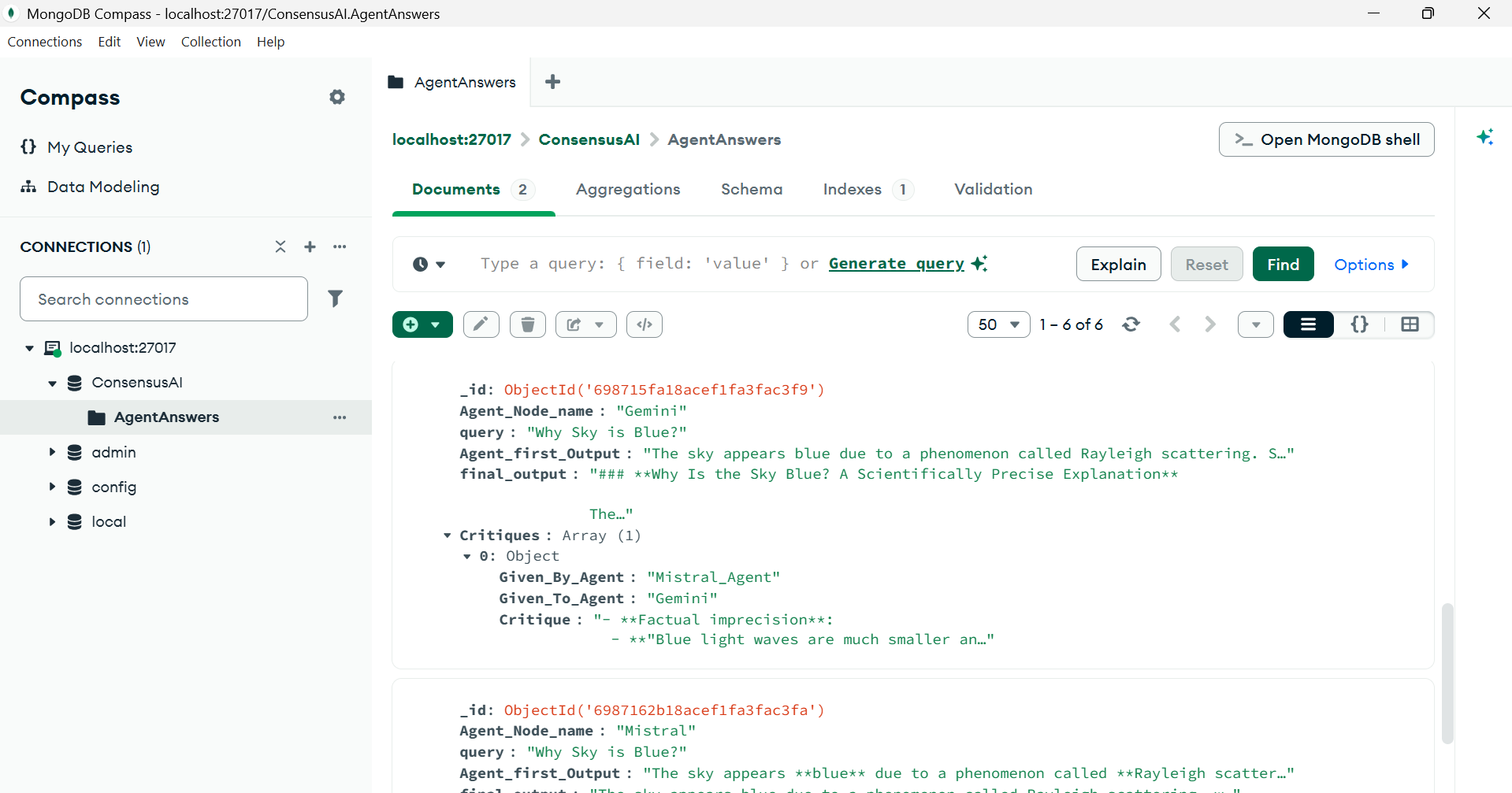
A Central Authority (debate state manager) tracks which model generated each answer and critique, ensuring structured execution and explainable reasoning flow.
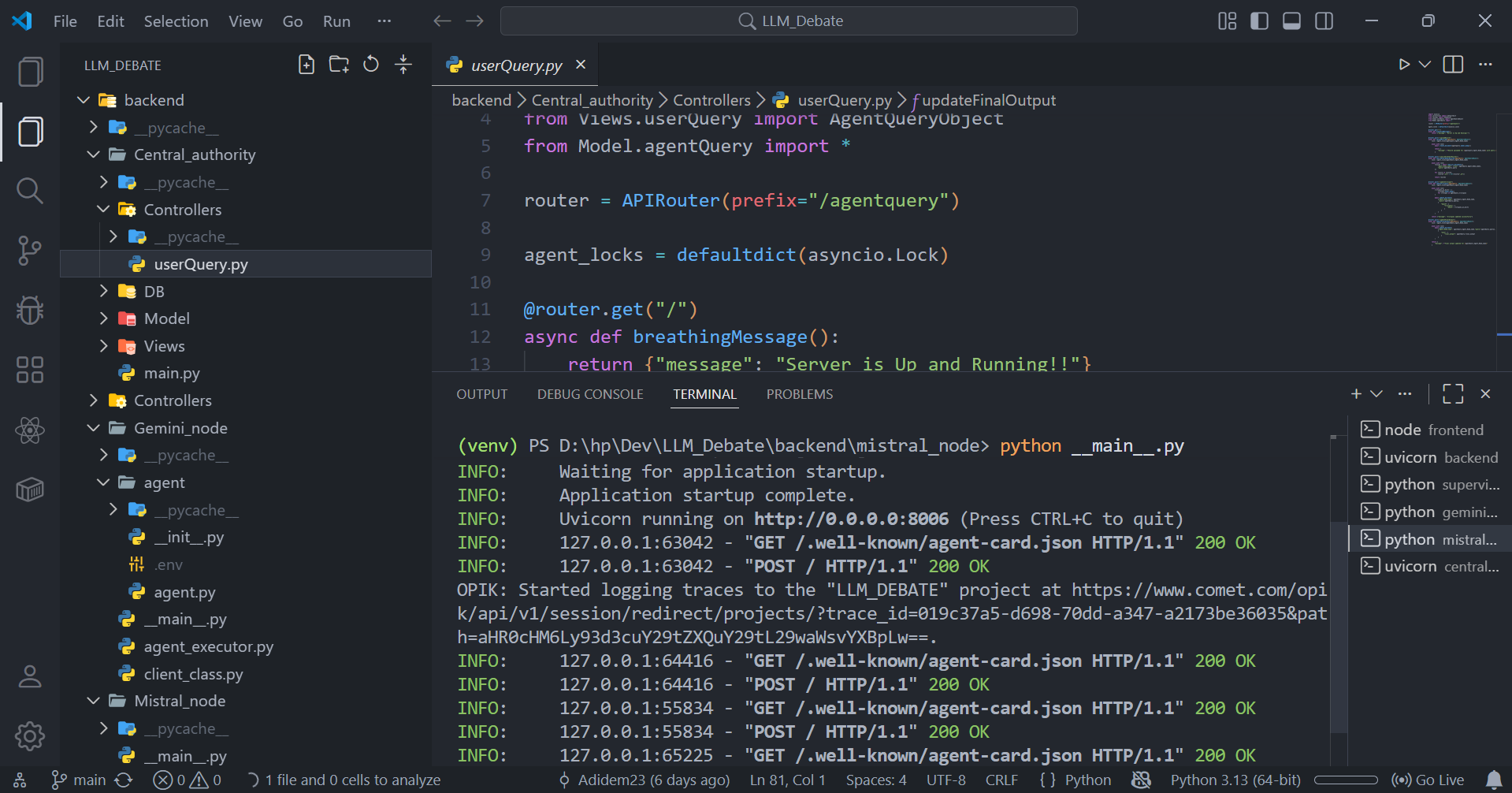
The backend is built using Python and FastAPI with Pydantic-based validation, LangGraph for agent orchestration, and the A2A protocol for agent communication.
The frontend is implemented in Next.js, and all LLM interactions are fully traced using Comet Opik for observability, evaluation, and debugging.
🔄 How a Single Query Is Processed (End-to-End)
When a user submits a query, the system does not generate a single direct answer. Instead, it follows a structured multi-agent reasoning pipeline.
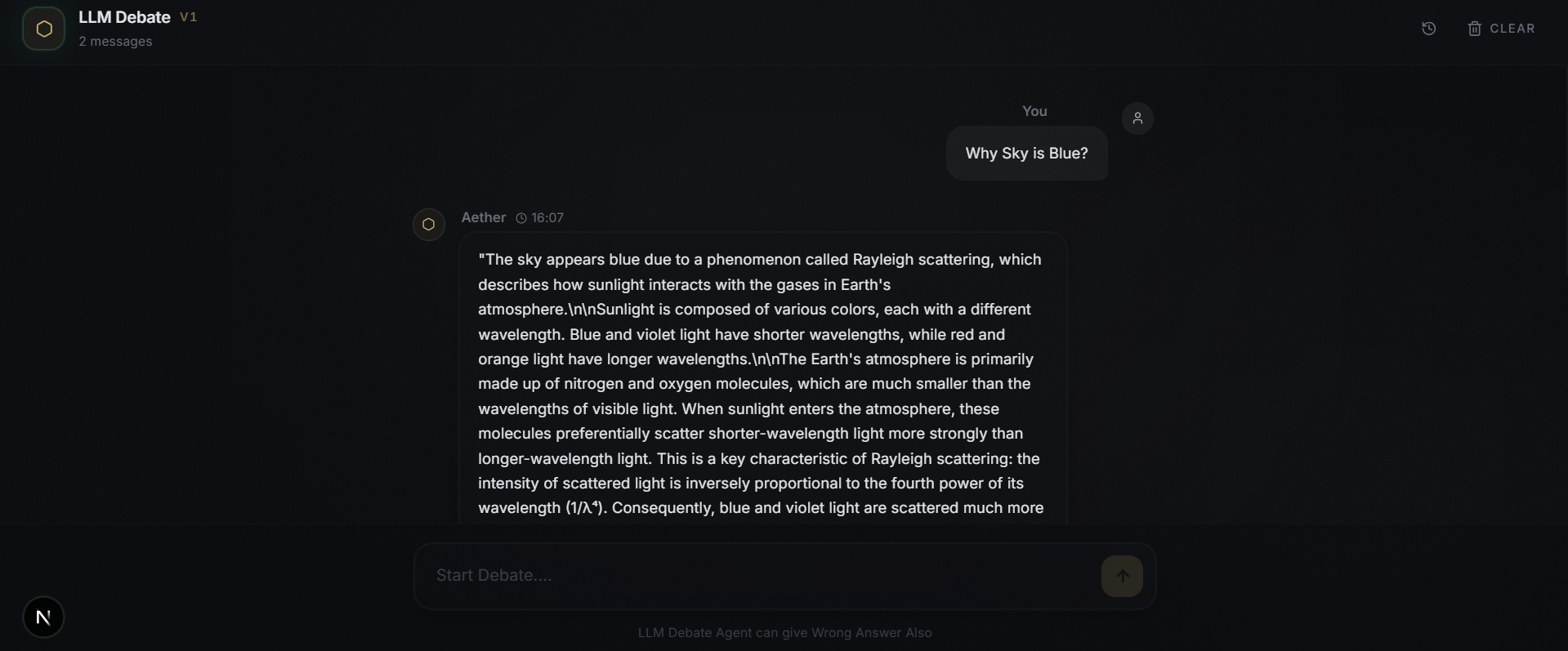
1️⃣ User Request (Frontend – Next.js)
- User submits a query via the web UI
- Frontend only handles input and output rendering
- All reasoning complexity is hidden from the user
2️⃣ API Entry Point (FastAPI Backend)
- Query hits a FastAPI endpoint
- FastAPI enables high-performance async handling
- Pydantic validates request structure and safety
3️⃣ Supervisor Agent Initialization
- Query is passed to the Supervisor Agent
- Supervisor:
- Registers the query with the Central Authority
- Delegates the same query to all LLM nodes
- Registers the query with the Central Authority
4️⃣ Central Authority (Debate State Manager)
- Tracks which agent receives which task
- Stores intermediate responses and critiques
- Maintains execution order and agent roles
- Ensures determinism, traceability, and debuggability
5️⃣ LLM Nodes – Independent Reasoning
- Each LLM reasons independently
- No shared memory or bias
- Each response is treated as a hypothesis
6️⃣ Critique & Refinement Phase
- LLMs receive anonymized outputs from peers
- Each agent critiques weaknesses and assumptions
- Agents refine their own answers
- One final defended answer per agent is produced
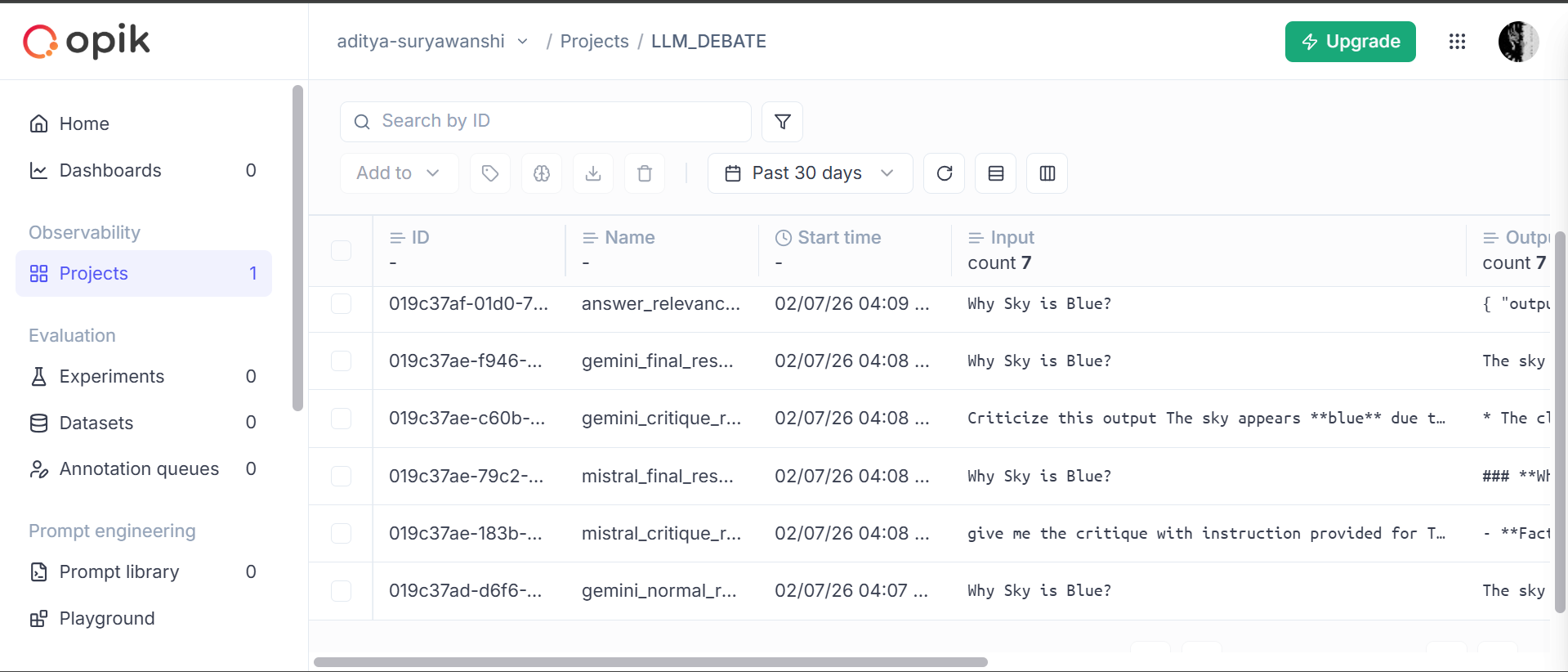
7️⃣ Tracing & Observability (Comet Opik)
- Every LLM call is traced
- Inputs, outputs, timing, and metadata are logged
- Enables offline analysis and evaluation
8️⃣ Final Evaluation (Supervisor Agent)
- Supervisor evaluates answers based on:
- Relevance
- Logical consistency
- Edge-case coverage
- Strength after critique
- Relevance
- Selects the most defensible answer
9️⃣ Response to User
- Final answer is returned via FastAPI
- User receives a high-confidence response
- Internally backed by debate and evaluation
🧰 Tech Stack Used (Why Each Tool Exists)
🖥️ Frontend
- Next.js
Fast, modern UI for query submission and result display.
⚙️ Backend & APIs
- Python – Core orchestration and agent logic
- FastAPI – Async API handling for LLM workloads
- Pydantic – Strict schema validation
🧠 Agent Orchestration
LangGraph
Defines the debate workflow as a graph: Supervisor → LLM Nodes → Critique → SupervisorA2A Protocol
Structured agent-to-agent communication
🤖 LLM Providers
- Gemini – Deep reasoning and structured outputs
- Mistral – Concise logic and alternative perspectives
Using multiple models reduces vendor bias and hallucinations.
🗂️ Data & State
- MongoDB
Stores debate states, responses, and metadata
📊 Observability & Evaluation
- Comet Opik
- Traces every LLM call
- Logs inputs, outputs, scores, and timing
- Enables dataset creation and evaluation
This makes the system an LLM evaluation framework, not just an app.
🧠 Why This Architecture Matters
This system transforms LLMs from:
“Answer generators”
into
“Reasoned decision-making systems”
By combining:
- Multi-agent debate
- Critique-driven refinement
- Supervisor-based evaluation
- Full observability
The LLM Debate Agent produces outputs that are reliable, explainable, and enterprise-ready.


Log in or sign up for Devpost to join the conversation.