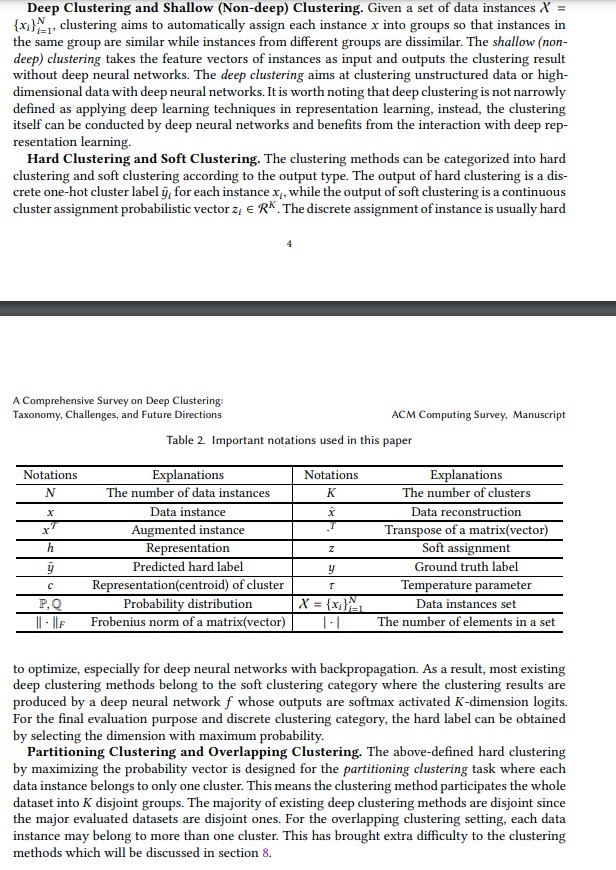
Inspiration The inspiration for this project came from the opportunity to explore unsupervised machine learning techniques, particularly in the context of semantic clustering. The task of grouping words into meaningful sets was an ideal challenge to apply large pre-trained models (like Llama) and leverage their understanding of language without the need for fine-tuning. The idea was to use these models to identify patterns and relationships between words based purely on semantic meaning.
What it does This project groups a set of 16 words into 4 groups of 4 based on semantic similarity. Instead of training a custom model, we utilized the knowledge embedded in a pre-trained language model (Llama 70b-8192) to understand the contextual relationships between words. These relationships were then used to form clusters by calculating cosine similarity between words and iterating on the results to find the most cohesive groups.
How we built it Our process involved using Llama purely for semantic extraction and grouping, rather than training the model. Here’s how we approached it:
Pre-processing the Words: We first processed the input list of 16 words into a suitable format for the model. Each word was represented as a vector embedding, where the model understood the contextual meaning of the word based on its training.
Semantic Embedding with Llama: Instead of fine-tuning the model on our task, we directly used Llama's pre-trained knowledge to embed the words into a vector space. Each word was transformed into a high-dimensional vector that captured its semantic meaning.
Cosine Similarity: With the word vectors in place, we computed cosine similarity between all pairs of words. Cosine similarity is a widely used metric for determining how similar two vectors are in a high-dimensional space. This metric was used to group words that were closer together in meaning.
Iterative Grouping: Initially, words were loosely grouped based on the cosine similarity, but we noticed that some words still didn’t fit neatly into their groups. To resolve this, we iterated on the groupings by resubmitting the words for filtering and re-grouping until we found the best matches. The key idea was to allow the model to suggest groupings based on semantic relevance, but then refine the output with a feedback loop to ensure the groups made sense.
Final Grouping: After several iterations, we achieved a set of groups where each word had been placed with other words that were highly contextually related.
Challenges we ran into Model Integration: Initially, we had issues with integrating Llama with the necessary dependencies and handling large model sizes. Once we resolved these, the next challenge was ensuring that the word embeddings were accurate enough for grouping. The semantic extraction process depended on how well the model understood each word’s meaning.
Non-English Words: Another challenge was the presence of words from different contexts and languages. While the Llama model is trained primarily on English, some words outside of typical English usage caused some issues. The semantic embeddings didn’t always align perfectly, especially for words that might have multiple meanings or cultural contexts.
Cluster Refinement: We had to overcome some "one-off" errors, where words were incorrectly clustered due to subtle differences in meaning or ambiguity in the vector space. This required us to iterate multiple times on the groupings, adjusting and resubmitting words for re-grouping based on their similarity scores.
Accomplishments that we're proud of Semantic Clustering Using Pre-Trained Models: We were able to group words semantically using Llama's pre-trained embeddings without the need for additional training or fine-tuning. The results demonstrated that pre-trained models can effectively understand word relationships and be used for unsupervised tasks like grouping.
Iterative Grouping for Improved Results: The ability to filter and refine the results through an iterative process was a key accomplishment. Each iteration brought us closer to accurate groupings, and we were able to achieve meaningful clusters without having to manually specify the criteria.
Handling Diverse Word Sets: The project also involved grouping words that varied widely in context (from "types of pickles" to "things with feet"), and we were able to manage these diverse word sets effectively using semantic extraction. The pre-trained model handled this diversity well, showing the power of large models in unsupervised clustering tasks.
What we learned Semantic Extraction is Powerful: Even without fine-tuning, the ability to extract meaning from words using pre-trained models like Llama was impressive. These models are trained on vast datasets, which allows them to understand complex semantic relationships, even between words from different domains.
Iterative Refinement is Key: The clustering task required some iteration. The first pass often didn’t result in perfect groups, and through iterative filtering and regrouping, we were able to improve the clustering results significantly. This process demonstrated the importance of feedback loops in unsupervised learning.
Model Limitations: While Llama performed well in many cases, we also learned that it is not perfect. Certain words with ambiguous meanings or those in languages less well-represented in the model's training data needed extra attention.
What's next for Connector Scaling to Larger Datasets: Moving forward, we would like to explore how this method can be scaled to handle larger word sets and more complex groupings. This could include working with a wider range of word categories, or even phrases, to see how well the method generalizes.
Multi-Language Clustering: We plan to expand the project to support multi-language clustering. While Llama is primarily trained on English, we want to explore how it handles other languages and see if we can adapt it for clustering tasks involving multilingual datasets.
Integration with User Tools: A potential next step is integrating this model into an accessible tool for users, allowing them to input their own word sets and receive semantic groupings. This could be useful in various applications, such as content categorization, keyword clustering, or natural language processing tasks.
Exploring Other Models: We are interested in exploring how other models like GPT-3 or T5 might perform in a similar task, especially in cases where a larger or more diverse set of words is involved. Comparing multiple pre-trained models might yield better results in certain cases.
Conclusion This project successfully demonstrated the use of semantic extraction with pre-trained models like Llama for unsupervised word clustering. By leveraging cosine similarity, we were able to group words based on their contextual meaning without the need for fine-tuning or extensive training. While there were challenges, such as handling ambiguous words and non-English input, we overcame them through iterative refinement. We are excited to continue refining the process and expanding the capabilities of this semantic grouping approach.
Built With
- https://github.com/retrospek/2projcrazy
Log in or sign up for Devpost to join the conversation.