-
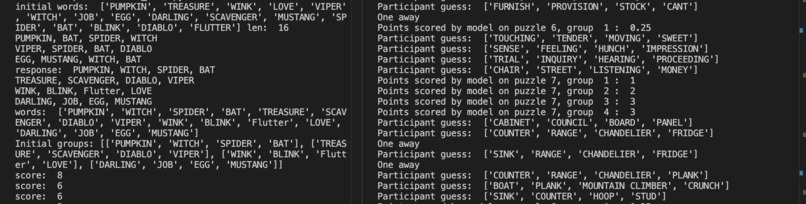
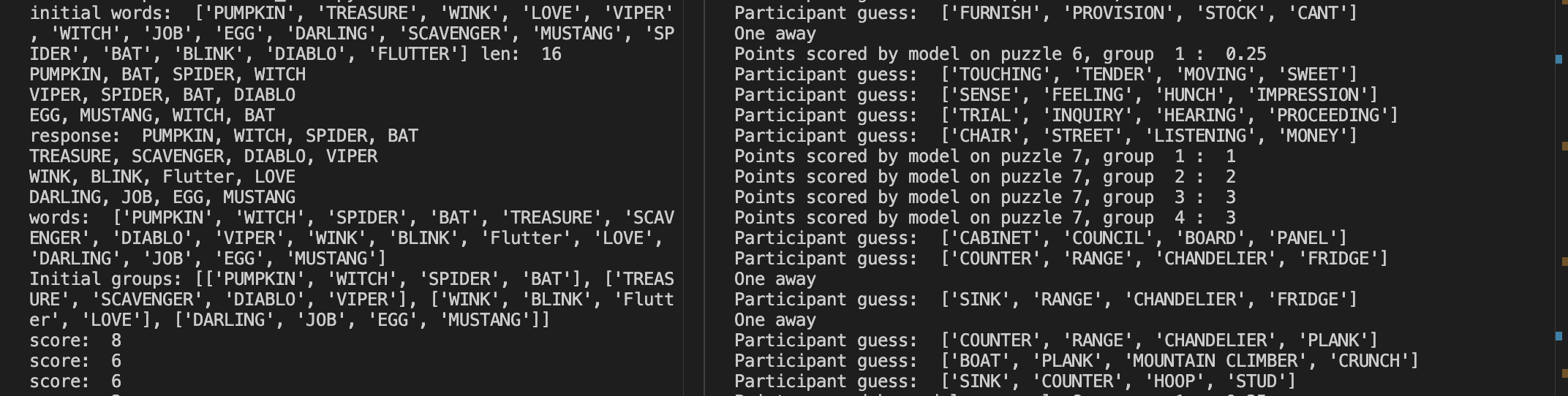
The algo with an iterative checking system
Inspiration
We are highly curious about how AI can tackle complex linguistic problems such as the Connections game. So we decided to try and solve it with subtle LLMs and NLP algorithms.
What it does
The system uses multiple layers of LLMs & NLP algorithms to validate a group of 4 words from a list of words. It tries to guess the best group of 4 words (that are related somehow) out of the existing list of words.
How we built it
The algorithm is a multi-block system, with each block having two LLM Layers and one NLP Layer. The LLM layers guess the initial group of words and are then validated by the NLP layer, followed by another LLM Layer using scoring and similarity mechanisms. We initially tried to run a Llama LLM from Groq, which used to fail sometimes due to rate limits. We then shifted to using local Ollama models. Since we couldn't host a Llama 3 70b model on our device, we used CloudFlare to host our LLM where all the training, fine-tuning and requests go through. The model is used to guess the initial clusters which are further refined using NLP techniques. The refined clusters are again given to the LLM for a validation and score and the best cluster from all the techniques is combined and given as an output.
Challenges we ran into
The given sample data was so weird. But I guess that is how the game is supposed to be. There are many misclassified labels caused by the LLM and NLP layers because of semantic similarity and hence they do not predict some of the complex groupings needed for completing the game. Some word groups don't usually occur, so it was harder to classify them with other similar words. We were restricted to free LLMs as we did not have access to powerful reasoning LLMs like GPT-o1-preview. So we made it happen my hosting a Llama 3.1 70b model on CloudFlare.
Building this LLM x NLP system was challenging because of the given sample data. The model works wonders on slightly less difficult-looking data.
Accomplishments that we're proud of
We are proud of thinking of such a system and getting it to an implementation level.
What we learned
We learned how to find similarities between complex words that usually don't occur. Other than that, we mostly explored every possible way to cluster similar words into groups of 4 words.
What's next for Connections AI
We want to achieve a higher accuracy and success rate in this problem, using a sophisticated algorithm system of LLM layers and NLP methodologies. Maybe we can combine more complex embeddings or scrape data to get word proximities. This gives us room to explore more complex algorithms like reinforcement learning and it's use cases into this problem.



Log in or sign up for Devpost to join the conversation.