-
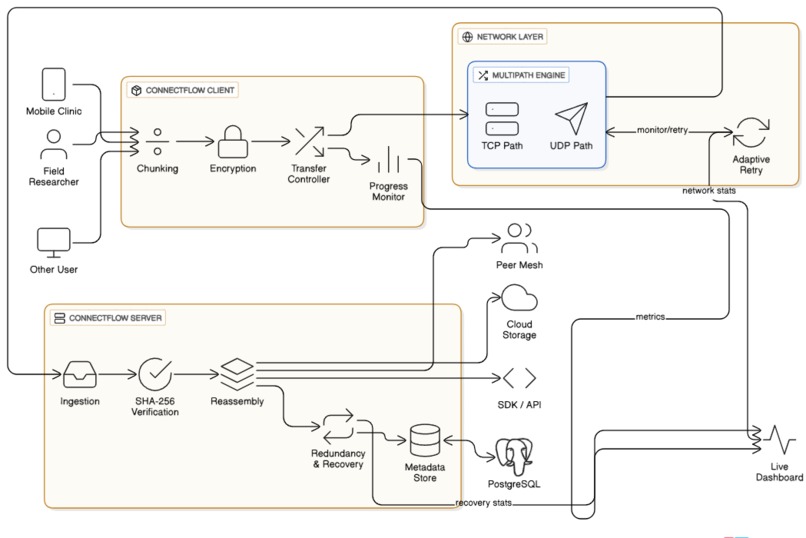
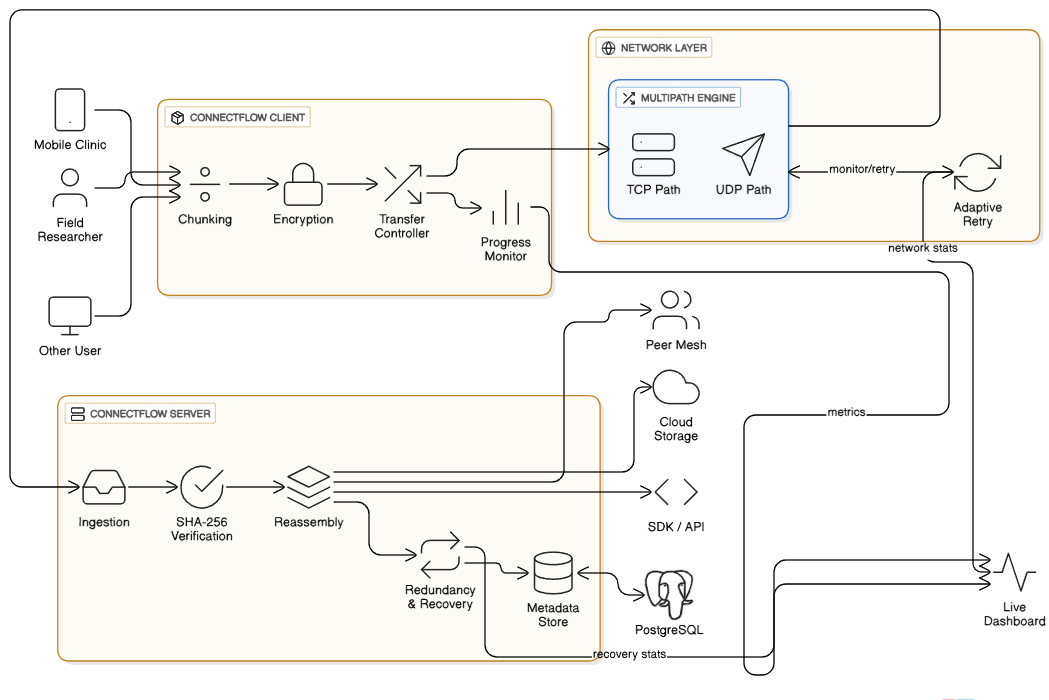
This is the System Architecture of our project
ConnectFlow: Adaptive File Transfer for Unstable Networks
"Your files. Always delivered."
Inspiration
Picture this: You're a field researcher in the mountains, finally uploading weeks of critical data. You're at 87% when — connection lost. Start over.
Or imagine a mobile clinic trying to send patient records back to headquarters, only to see the transfer fail three times in a row. Frustrating? Absolutely. Preventable? We think so.
In many remote or unstable environments, from rural research labs and field engineers to mobile medical units, reliable file transfer remains a common issue. Interrupted or unstable network connections often lead to incomplete, corrupted, or lost data.
In a world where we can land rovers on Mars, why does sending a file feel so complicated when the WiFi drops? We kept asking ourselves this question, and ConnectFlow is our answer.
We want to create a solution that ensures data integrity and continuity, no matter how unreliable the connection may be. Whether you're in a remote village, a moving vehicle, or just dealing with your apartment's poor internet, your files deserve better.
What it does
ConnectFlow is a smart file transfer system that is designed to work well, even with poor network conditions.
Think of it as a loyal friend who never gives up on you; it remains committed to overcoming bad networks.
Here's how it works:
Splitting files into encrypted chunks: Files will be divided into smaller, secure pieces, so if one chunk fails, you don't lose everything.
Transmitting across multiple network paths: We will use both TCP and UDP at the same time, combining TCP's reliability with UDP's speed, similar to having backup routes on your GPS.
Verifying integrity: Each chunk will be checked using cryptographic hashes (SHA-256) to ensure that what arrives is exactly what you sent.
Automatically resuming transfers: If the connection drops, no problem. ConnectFlow will remember where it left off and continue from that point.
Adaptive retry mechanisms: The system will improve over time, learning which network paths work best and adjusting automatically.
ConnectFlow will prioritize critical files, support real-time progress monitoring, and ensure zero data loss through redundancy-based recovery.
It's like having a postal service that divides your package into multiple shipments, sends them through different carriers, tracks each piece, and reassembles everything perfectly at the destination, even if part of the delivery process fails.
How we built it
We're planning to build ConnectFlow with proven tools and some inventive engineering.
Backend: Go (Golang): We chose Go for its ability to handle multiple tasks at once, its strong networking features, and its efficient performance. When thousands of file chunks need to move across unstable networks at the same time, Go's goroutines and channels will help manage parallel transfers smoothly.
Networking Layer: Custom Multipath Engine: We will create a traffic controller that handles both TCP and UDP transmissions at the same time. It will keep an eye on which "roads" (network channels) are open and reroute data instantly, adjusting to changing bandwidth.
Storage: PostgreSQL: This will act as the main storage for file chunks, transfer sessions, and verification logs. It will be our careful organizer that keeps track of every chunk, every attempt, every success, and always knows where everything is and what state each transfer is in.
Monitoring: Live Dashboard: We plan to create a system for visualizing transfer progress, retry data, and performance metrics in real time. This will provide real insights, not just a spinning circle of uncertainty.
The architecture will use chunking algorithms that change size based on network conditions, cryptographic hashing for verifying integrity, and a smart retry system with increasing delay.
Challenges we ran into
Building ConnectFlow will involve solving some genuinely tough problems:
Designing an efficient multipath scheduler: Creating a scheduler that can adjust to changing bandwidth will be difficult. Deciding which data goes where, when, and how fast, while the network keeps changing, will need advanced algorithms. We will have to balance aggressive retries with not overwhelming connections that are already struggling.
Implementing packet loss simulation: We will need to intentionally create issues like packet loss, latency spikes, and random disconnects in controlled settings that accurately reflect real-world conditions. Developing realistic network failure scenarios and error recovery systems will be more challenging than we expect.
Maintaining data integrity and synchronization: Imagine a jigsaw puzzle where pieces arrive out of order, some get lost, and you have to check that the picture is complete before you can say it's done. Managing partial transfers, retries, and ensuring everything stays in sync will be a constant battle. We will need to pay careful attention to race conditions and state management.
Memory management at scale: Managing thousands of concurrent chunks without memory leaks or a drop in performance will need thorough profiling and optimization.
These challenges will help us better understand the complexities of network resilience and fault-tolerant systems.
Accomplishments that we're proud of
Research and design: We have researched network protocols, error correction algorithms, and existing solutions like BitTorrent and QUIC to shape our architecture.
Architectural planning: We have created a system that solves real-world problems with practical solutions. Our multipath approach and chunking strategy are based on known networking principles.
Problem identification: We have found a real issue that affects researchers, healthcare workers, and field professionals around the world. We also have a solid plan to address it.
Technical feasibility: We have confirmed that our tech stack, which includes Go, PostgreSQL, and multipath networking, can handle the challenges we have identified.
Vision for impact: We are not just building technology for the sake of it. We understand who will benefit from our work and how it will improve their jobs.
Most importantly, we are addressing a problem that truly matters. Our solution is both technically sound and practically useful.
What we learned
How network reliability protocols work: We explored how TCP, UDP, QUIC, and BitTorrent handle retransmission and chunking. Learning how BitTorrent manages swarms, how QUIC recovers from packet loss, and what makes TCP both reliable and sometimes frustratingly slow has given us important insights into creating resilient networks.
The impact of Forward Error Correction (FEC): We found that sending a bit more data can make the difference between success and failure. Small redundancy costs (5-10%) can greatly improve success rates on unstable networks. The calculations behind the best levels of redundancy are interesting.
Balancing speed, reliability, and redundancy: The art of trade-offs in designing resilient systems is like tuning a musical instrument; every adjustment is crucial. Sometimes going slower is actually faster when you consider retries. Success is not only about throughput, but also about completed transfers.
Concurrency patterns in Go: We discovered how Go's goroutines and channels can provide elegant solutions to parallel data transfer issues. We also recognized the importance of proper synchronization to prevent race conditions.
Real-world constraints matter: Designing for unstable networks involves more than technical skill; it requires understanding the actual conditions field workers encounter and creating solutions that work in those settings.
What's next for ConnectFlow
This is just the beginning. Our development plan includes:
End-to-end encryption: We will provide military-grade security for enterprise transfers. We plan to implement AES-256 with perfect forward secrecy because your data should be secure and delivered reliably.
AI-driven network prediction: Our machine learning models will optimize channel and route selection. These models learn from patterns to choose the best paths before problems arise, predicting congestion and routing around it in advance.
Mobile-first client: We are creating native iOS and Android apps for field workers and on-the-go data exchange. One-tap transfers will have full background operation support, since the people who need this most are often mobile.
Peer-to-peer mesh networking: Nearby devices will help each other transfer data faster in distributed environments, like a digital bucket brigade. This is especially useful for disaster relief situations or areas with limited infrastructure.
Cloud integration: We will ensure seamless transfers to and from AWS S3, Google Cloud Storage, and Azure Blob Storage with the same reliability guarantees.
SDK and API: We will make ConnectFlow's resilience available to other developers who are building applications for challenging network environments.
Impact
Once developed, ConnectFlow will enable reliable and secure file transfers even under the most unstable network conditions.
It's about the field biologist who can finally share endangered species data from the rainforest without hiking to the nearest town.
It's about the rural doctor who can send critical patient scans knowing they'll arrive complete and uncorrupted.
It's about the disaster relief coordinator whose communication systems keep working even when infrastructure fails.
It's about the journalist in a conflict zone who can safely transmit evidence despite throttled and monitored networks.
It's about helping researchers, healthcare workers, and businesses share data safely, completely, and efficiently; everyone deserves reliable access, no matter where they are or what their network looks like.
Because in 2025, your connection might be unstable. Your data transfer shouldn't be.
Tech Stack
- Backend: Go (Golang)
- Database: PostgreSQL
- Networking: Custom Multipath Engine (TCP & UDP)
- Encryption: AES-256, SHA-256 Hashing
- Monitoring: Real-time Dashboard (HTML5, CSS3, JavaScript)
- Testing: Network simulation tools, Chaos engineering frameworks
ConnectFlow: Built for the real world, where networks are messy and data matters.

Log in or sign up for Devpost to join the conversation.