-

Promo
-
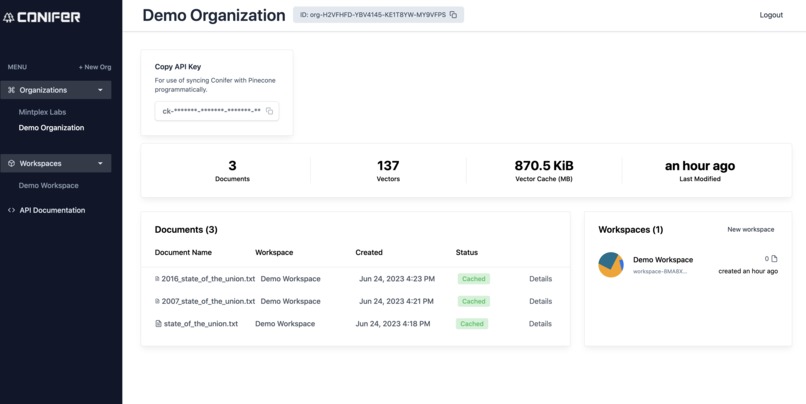
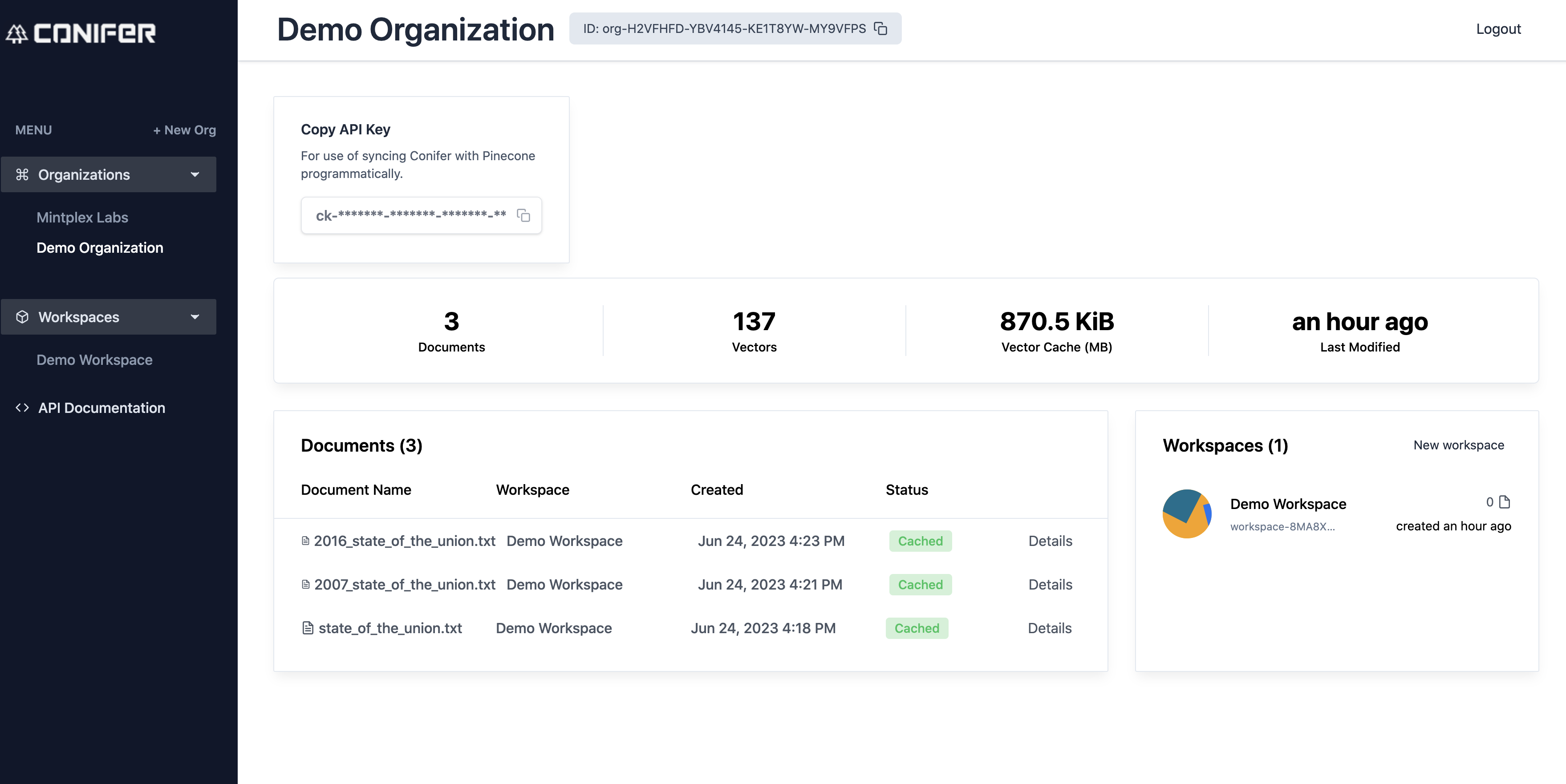
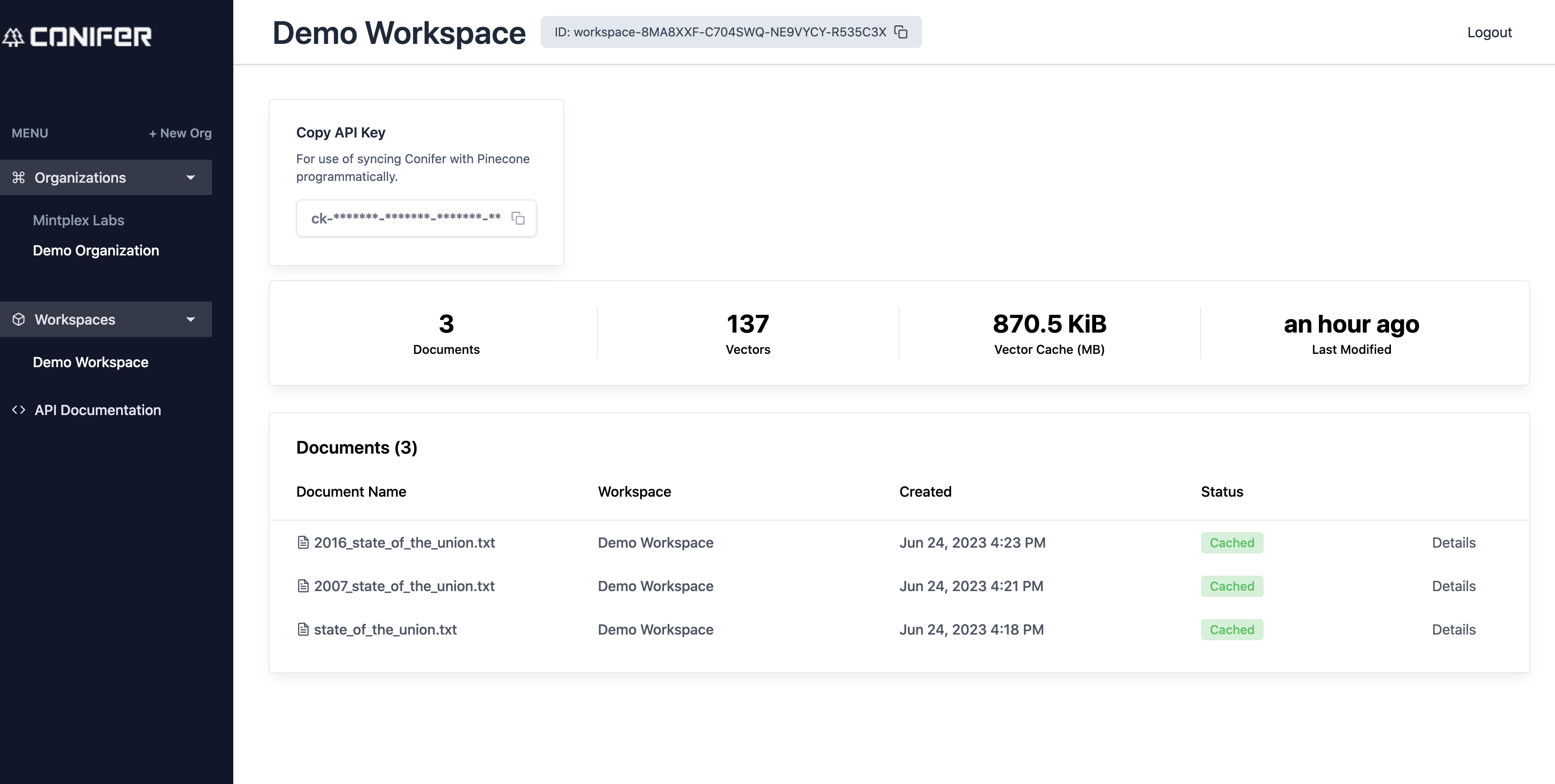
Organization Dashboard
-
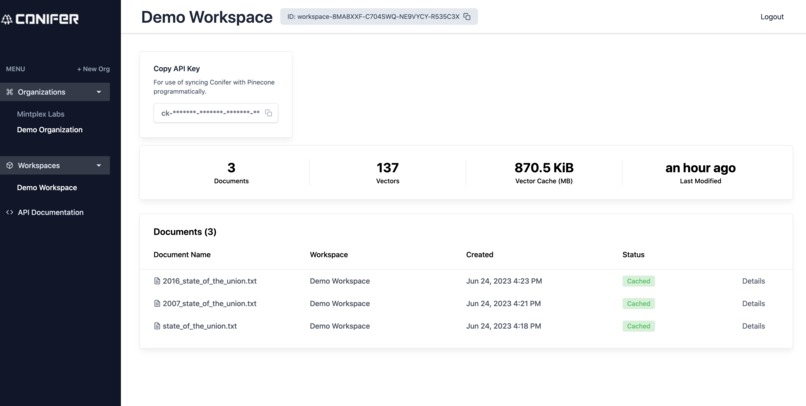
Workspace Dashboard
-
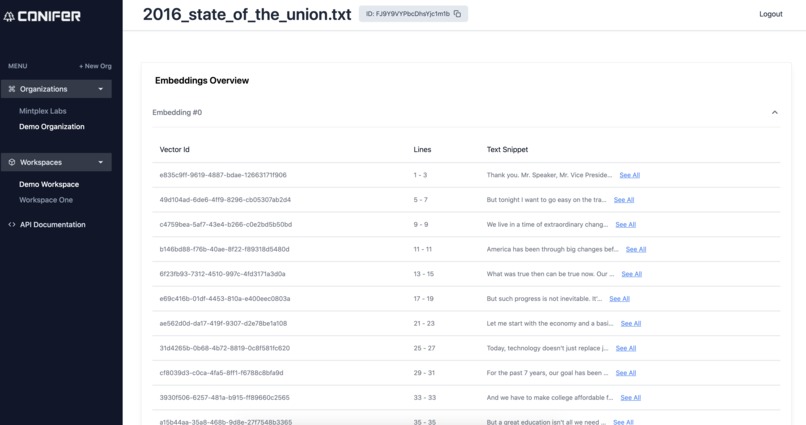
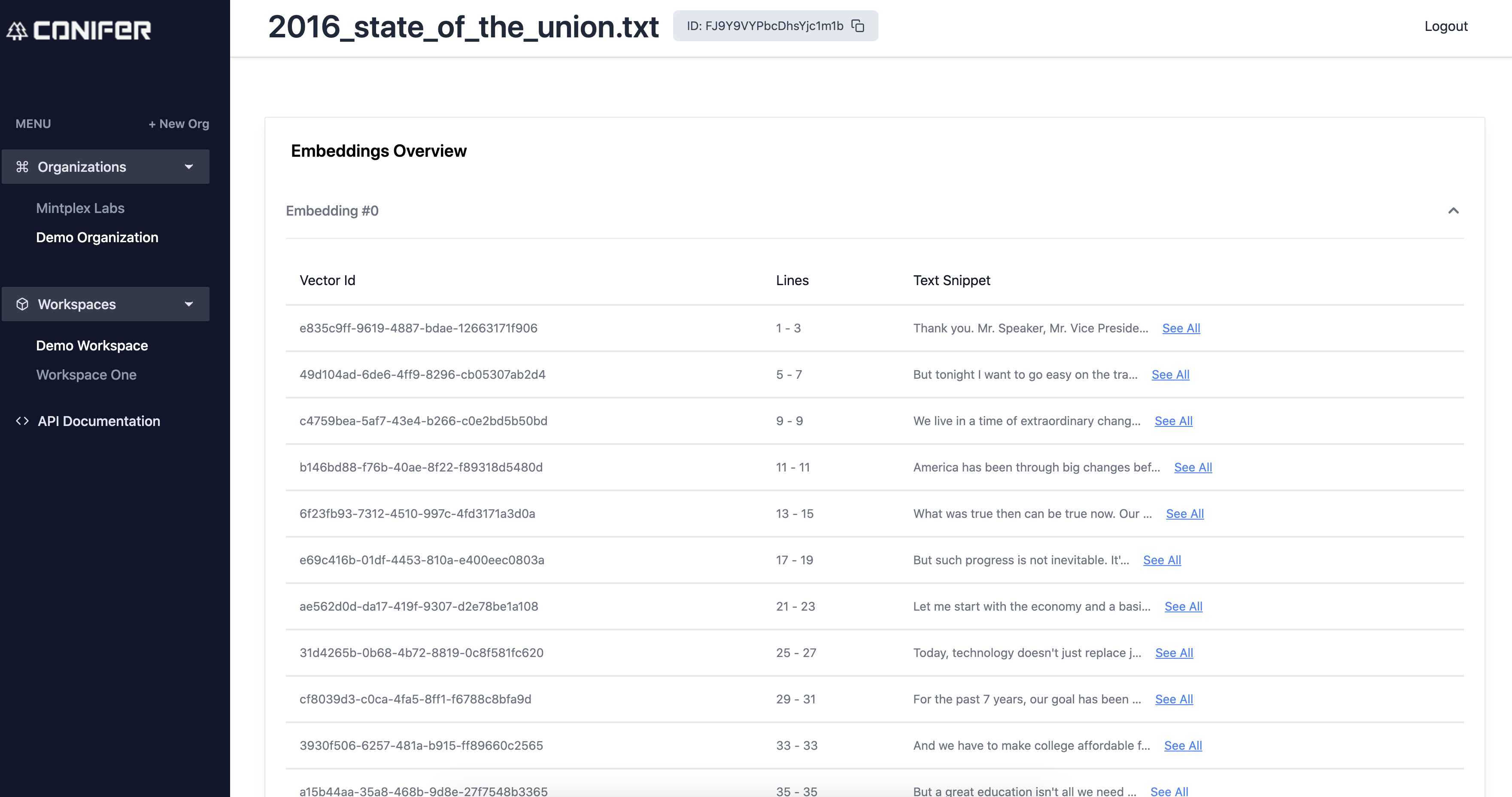
Document Embedding Viewer

Inspiration
We have built many consumer LLM applications using Pinecone and LangChainJS, but a couple of problems kept coming up over and over in our developments but also across the Lanchain and Pinecone Discords.
How do I manage my documents in Pinecone with Langchain
This seems like something that would be done out of the box, but that's not really the core focus of LangChain (who are bridging LLMs and VectorDB among hundreds of other tools in the AI stack) or Pinecone (who are building scaleable vector database infrastructure) - so right now the status quo is you can add vectorized content easily, but not really manage it.
That is why we made Conifer, it's a tool that solves our problem as well as other developers but also allows all the non-technical people on your team to see what is in the vector database.
What it does
Conifer could do a lot more, but we only had a few days to really make it work, so here is what we are submitting.
An extension of a new model in
langchainJScalledVDBMS(vector database management systems) that allows you to still use all the amazing features and conveniences of langchain, but this time you get to see what exactly got stored. Link to added fileA full UI so anybody can see what exactly got stored in your Pinecone database. Developers dont even have to lift a finger - its all tracked for you in the cloud.
Conifer implements a new game-changing cache system that allows you to duplicate embeddings across multiple pinecones indexes or namespaces without having to pay OpenAI to re-embed a document. At scale, this could save hundreds of thousands of dollars in embedding costs. Embed once and then only pay for vector storage going forward.
From the library you can copy entire documents across Pinecone namespaces or indexes without having to pay to re-embed. This is awesome.


How we built it
ConiferUI is built using ViteJS, React, Firebase. The conifer library is built using Pinecones NodeJS client and a fork of the LangchainJS client.
Challenges we ran into
We found that Langchain creates a unique ID for each vector it adds, but the issue if you can never figure out what the ID was - so we found ourselves having to fork the entire langchain library and then just make some hacks to expose a new fromDocumentsVerbose method on the langchain pinecone implementation so that we can hook into and sync this with the Conifer API.
Additionally, being able to do this without massive performance issues is a challenge so a lot of time was spent figuring out how to parallelize the sync'd chunks so that it wouldn't take a long time to sync documents.
Accomplishments that we're proud of
The quickness of being able to build the entire UI and custom library extension in the given timeframe
Had an emergency during the hackathon so really only had 3 days, because why not play on hard mode?
Effective cache storage via document compression. So while the end user gets the benefit of cached data the true file storage cost of this embedded information is much less than the original document size.
What we learned
Dont have an emergency during a Hackathon
Timeblock tasks because it's really easy to find yourself affected by feature creep - which you cannot afford during a hackathon.
What's next for Conifer
Make this open source and dockerized so that you don't have to use Firebase to run the full-stack application. Have it to where it is a truly open-source project that then has a hosted solution if you don't want to deal with the headache of setup. This strikes the balance of data privacy but with the compromise of cloud storage of embeddings.
Be able to directly manage your Pinecone vectors from the UI without the library for those who want a more traditional UI-focused experience instead of having to write code to do it.
Right now Conifer is essentially read-only when using only the UI. Ah well, got crunched for time.
Built With
- conifer
- express.js
- firebase
- javascript
- langchain
- node.js
- openai
- pinecone
- react
- typescript



Log in or sign up for Devpost to join the conversation.