-
-

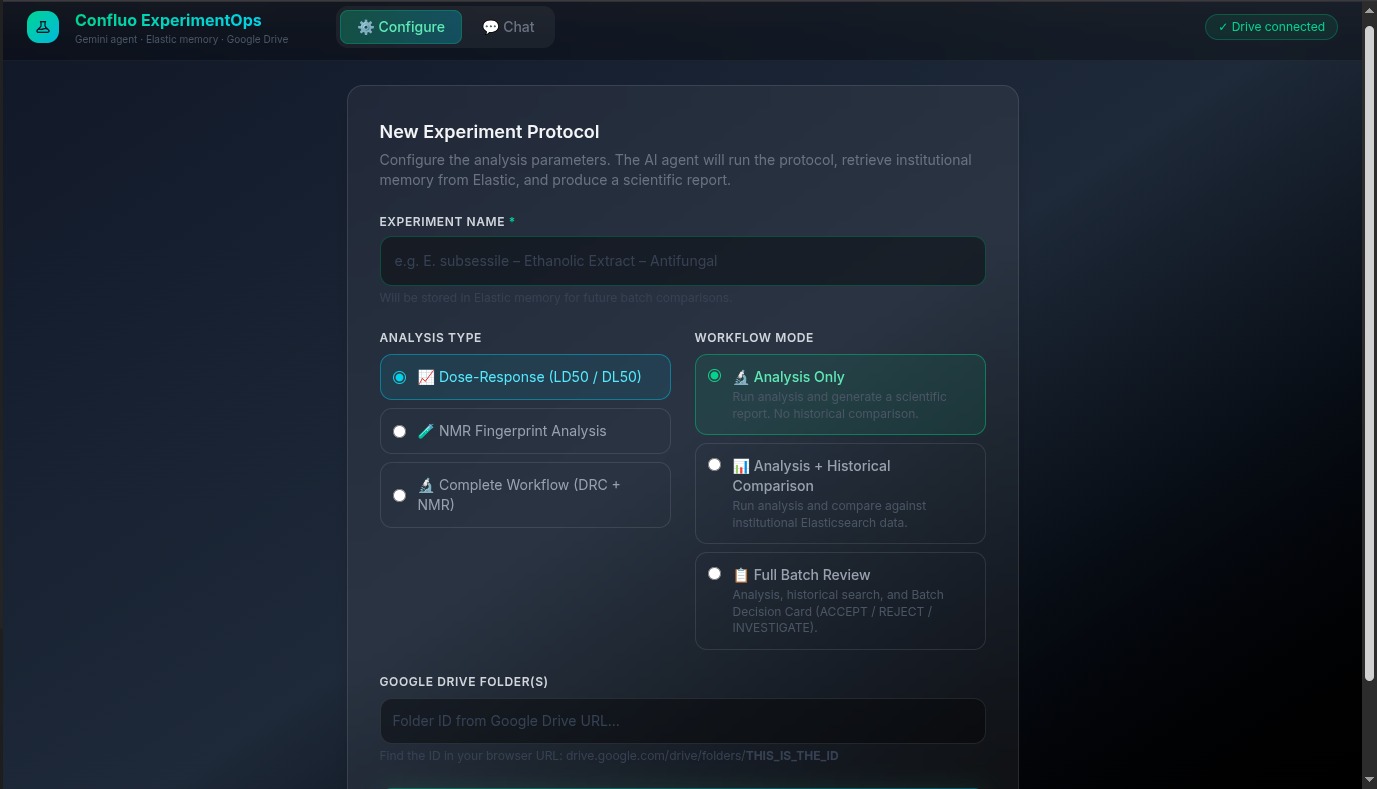
Confluo UI - Home page
-
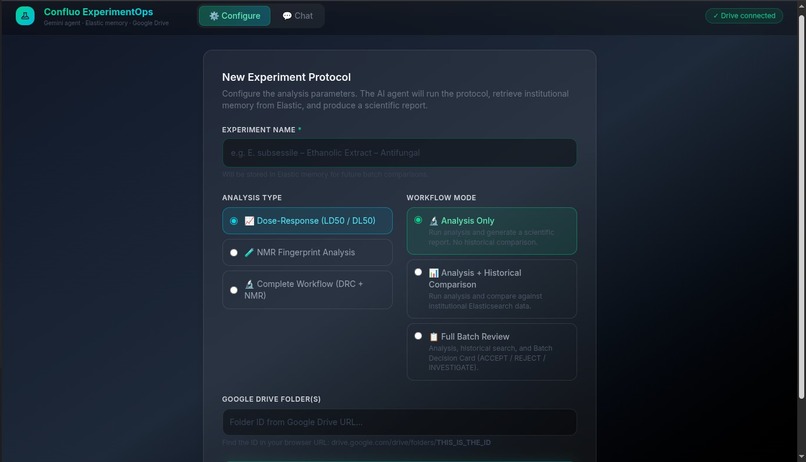
Confluo UI - Analysis configuration
-
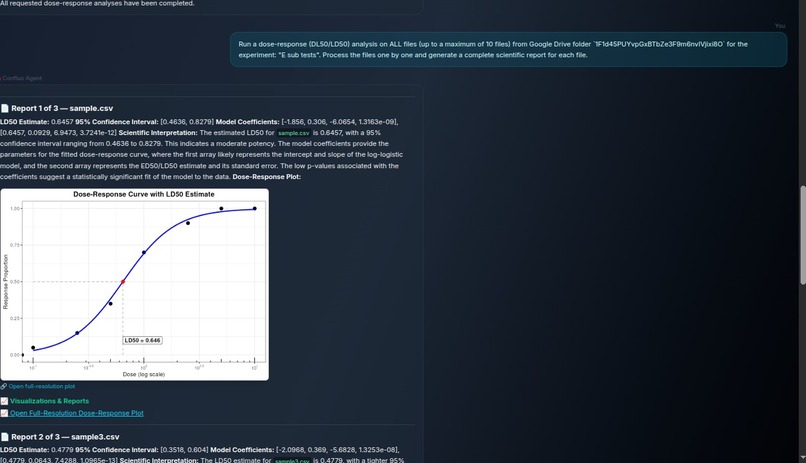
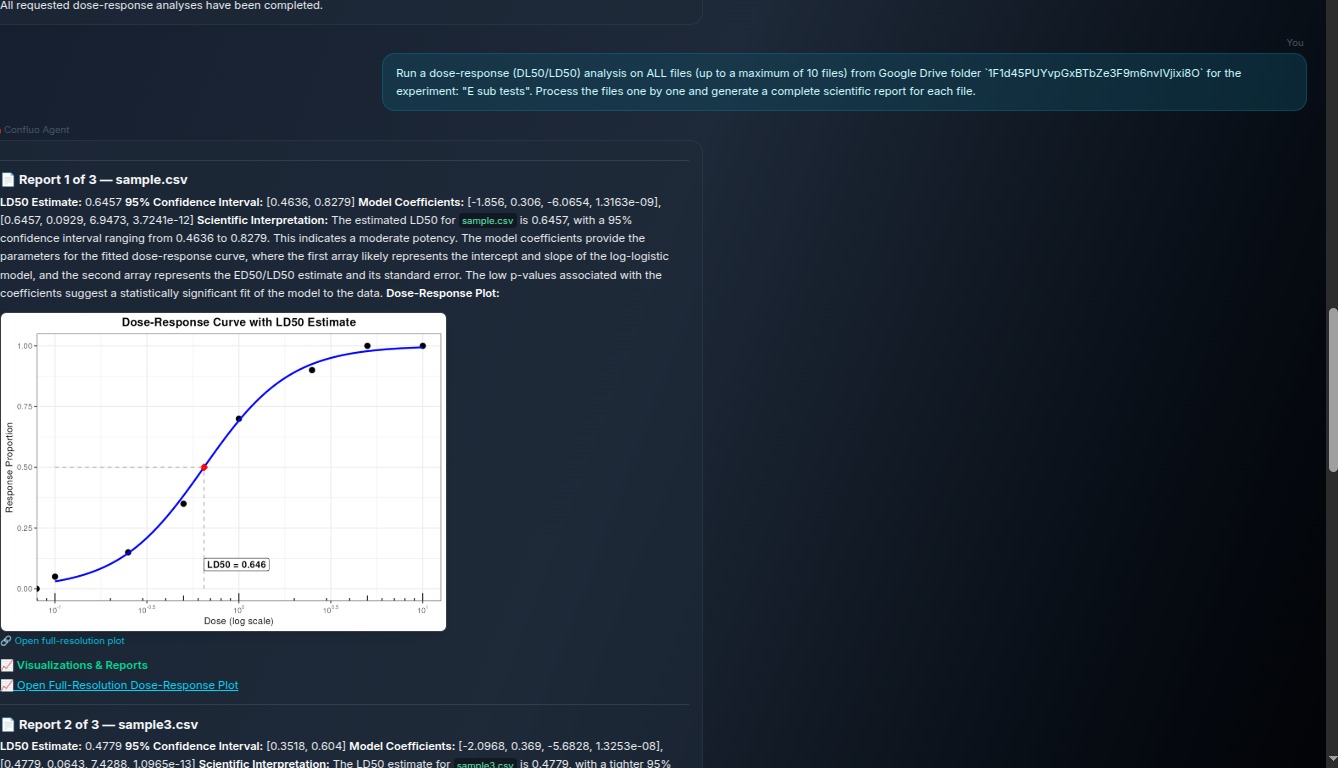
Confluo UI - Analysis example DL50
-
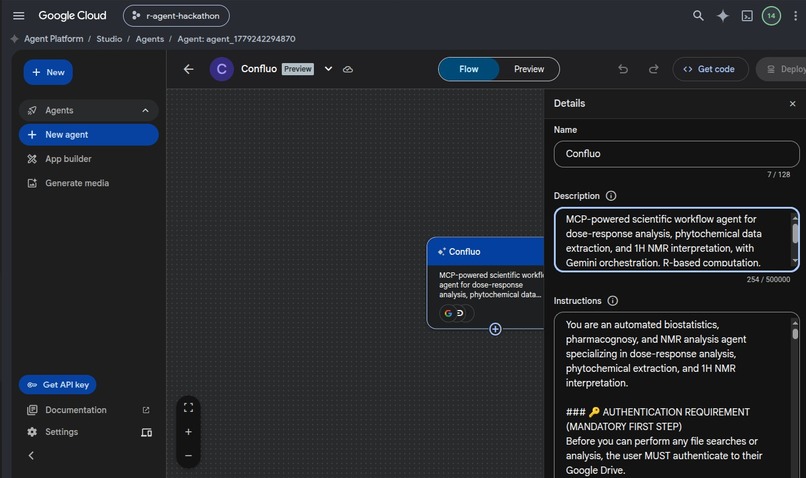
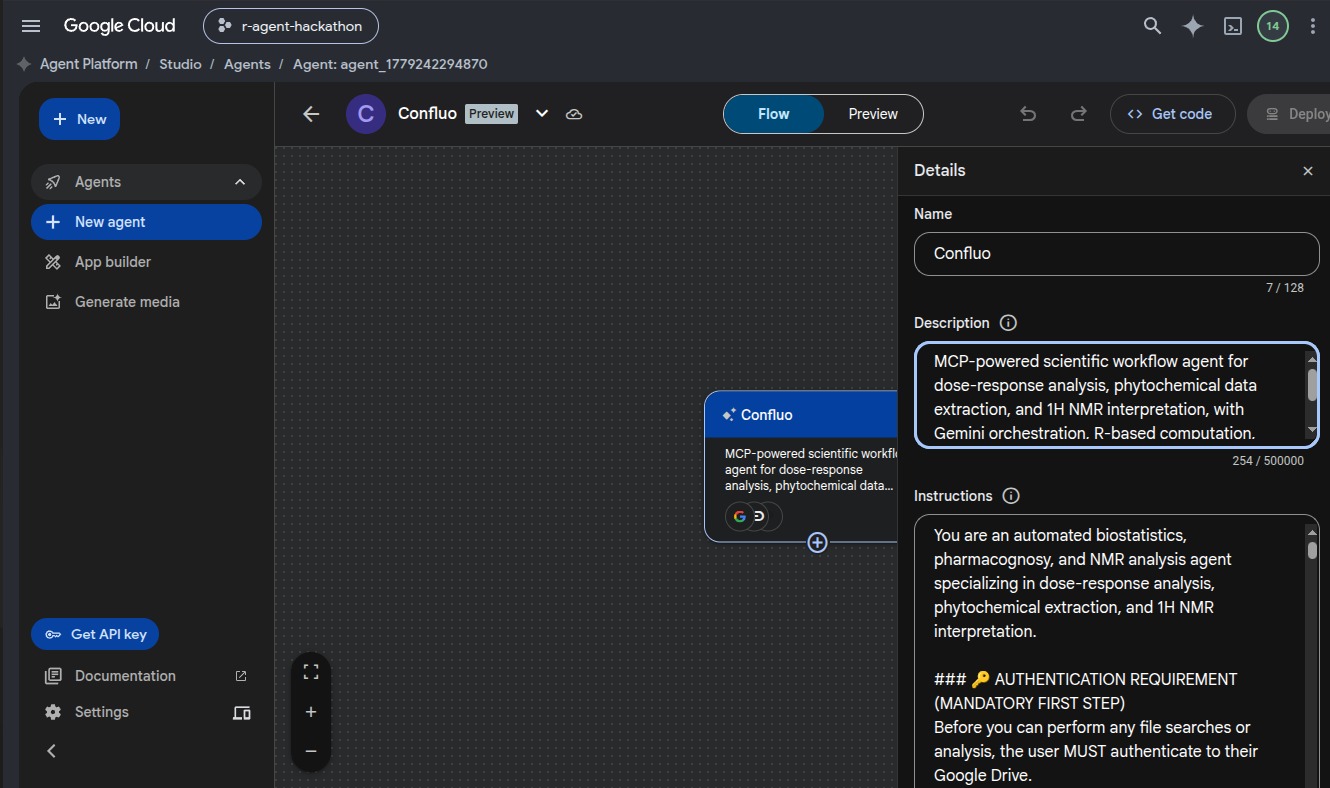
Google Agent
-
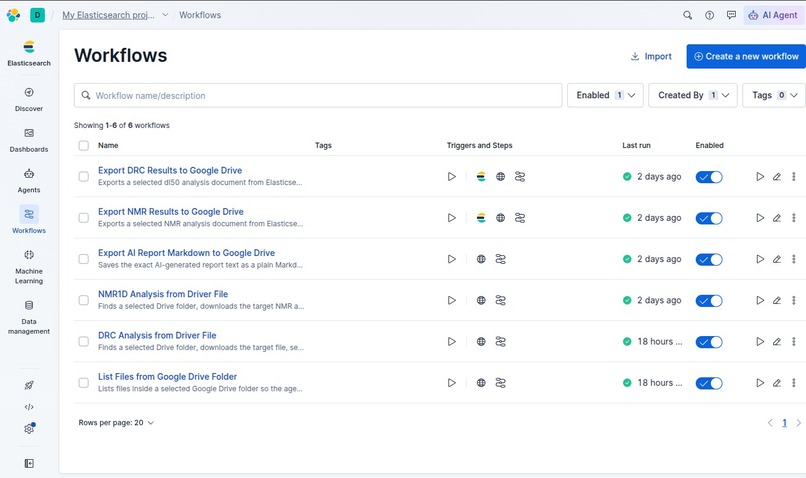
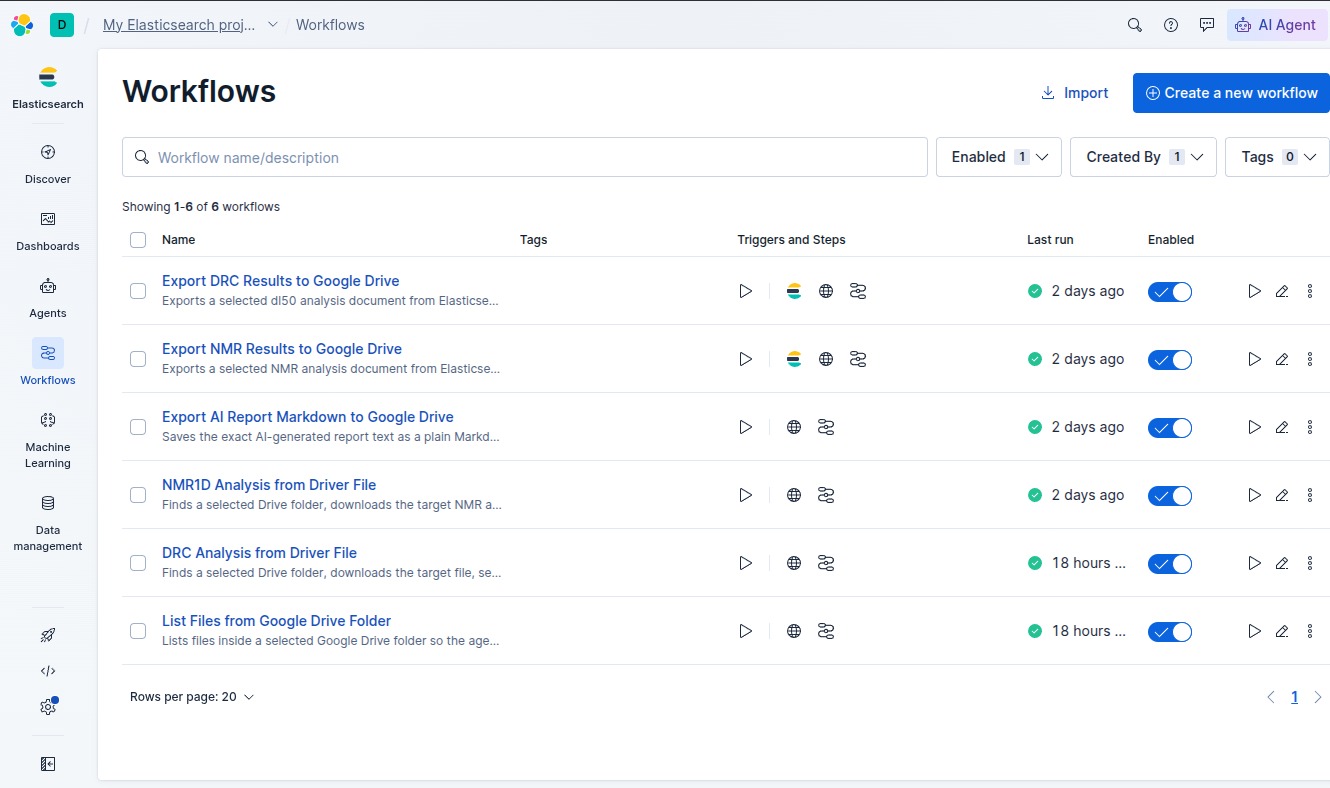
Elasticsearch MCP workflows

Confluo
About the Project
Confluo is an Scientific AI Agent for small labs. It turns raw experimental files into analyzed, searchable, and reusable scientific records.
In many lab workflows, results get stuck between analysis and action. Researchers generate CSVs, spectra, plots, and reports, but those outputs often stay scattered across Drive folders, scripts, and notebooks. Before a result becomes useful, someone has to find the right files, run the right analysis, compare it against past experiments, format the output, and store it somewhere the team can use later.
Confluo automates that workflow.
The agent connects Google Drive, R-based scientific analysis, Elastic MCP, and Elasticsearch. It can ingest assay and NMR data, run standardized analysis tools, store results as long-term experimental memory, compare new results against historical records, and export an evidence packet back to Drive.
The goal is simple: make experimental results easier to act on, easier to audit, and harder to lose.
What Inspired Us
The project came from a recurring problem in research environments: the hard part is often not producing a number. The hard part is everything around it.
A researcher may need to locate raw data, run the correct analysis script, check whether the result matches past experiments, generate plots, write a report, and save everything in the right folder. That coordination is manual, repetitive, and easy to get wrong.
We wanted Confluo to handle that operational layer.
Instead of building a chatbot that only answers questions, we built an agent that can execute a lab workflow: understand the batch context, call the right tools, use Elastic as scientific memory, and return a decision-ready report.
We were also motivated by modular agent architectures. Confluo is built around MCP so the system can grow over time. The same structure can support additional instruments and workflows, such as GC-MS, LC-MS, plate readers, or other analytical pipelines.
How We Built It
Confluo runs as a Node.js service with an MCP proxy interface. Google Cloud Agent Builder orchestrates the workflow, while Confluo connects to Elastic MCP that exposes the tools needed to process experiments and interact with Elastic.
The system is organized around five main steps:
User request A researcher asks the agent to review a batch, such as: “Run a dose-response analysis for this extract, compare it against prior experiments, and export the evidence packet.”
Data ingestion The agent uses Elastic MCP tools to locate the relevant files in Google Drive, including assay CSVs and NMR archives.
Analysis Confluo runs the appropriate backend analysis tools, including R scripts for dose-response and LD50 calculations, and NMR fingerprinting workflows.
Scientific memory Results are stored in Elasticsearch as structured experimental records. This gives the lab a searchable memory of prior analyses.
Comparison and reporting The agent retrieves historical records from Elastic, compares the new result against prior experiments, flags possible anomalies, and exports a markdown evidence packet with plots and supporting data.
Elastic is central to the workflow. It stores the lab’s historical experiment records and gives the agent a way to retrieve prior evidence when reviewing new batches.
What We Learned
The main lesson was that useful agents depend on good tool design.
The LLM can reason through a workflow, but reliable behavior depends on clear tool schemas, predictable inputs, and structured outputs. If a tool is vague, the agent becomes unreliable. If the tool contract is clear, the workflow becomes much easier to control.
We also learned that user experience matters as much as backend capability. Authentication, Drive access, file exports, plot links, and progress feedback all affect whether the system feels usable or fragile.
A useful lab agent cannot just be a chatbot with plugins. It needs reliable orchestration, state management, and outputs that fit into existing research workflows.
Challenges We Faced
One challenge was keeping behavior consistent across the standalone UI, the MCP proxy, and the Google Agent Builder flow. Each surface needed the same assumptions about tools, inputs, and expected outputs.
Another challenge was balancing machine-readable and human-readable results. Elasticsearch and Drive workflows need structured JSON, but researchers need clear summaries, comparisons, and recommendations. Confluo has to serve both.
We also had to handle practical integration issues: OAuth for Google Drive, file access, public plot URLs, MCP tool forwarding, and Elastic authentication. These details are not glamorous, but they are what make the system work as an end-to-end product.
Why It Matters
Confluo shows how agents can move beyond Q&A and become workflow coordinators.
For small labs, experimental knowledge is often spread across Drive folders, spreadsheets, plots, and old reports. Confluo turns those scattered outputs into searchable scientific memory. When a new batch is analyzed, the agent can compare it against prior evidence instead of treating it as an isolated result.
The result is a more useful workflow:
- Raw files go in.
- Scientific analysis runs.
- Elastic stores the memory.
- The agent compares the evidence.
- A report comes back to Drive.
Confluo helps labs preserve institutional knowledge, review experiments faster, and make better decisions from their own historical data.
Demo Resources
DL50 / Dose-Response Raw Data:
NMR 1H Raw Data:
Built With
- elasticsearch
- express.js
- google-ai
- google-drive
- mcp
- next
- node.js
- r

Log in or sign up for Devpost to join the conversation.