-
-

-

-

-

-

-

-

-
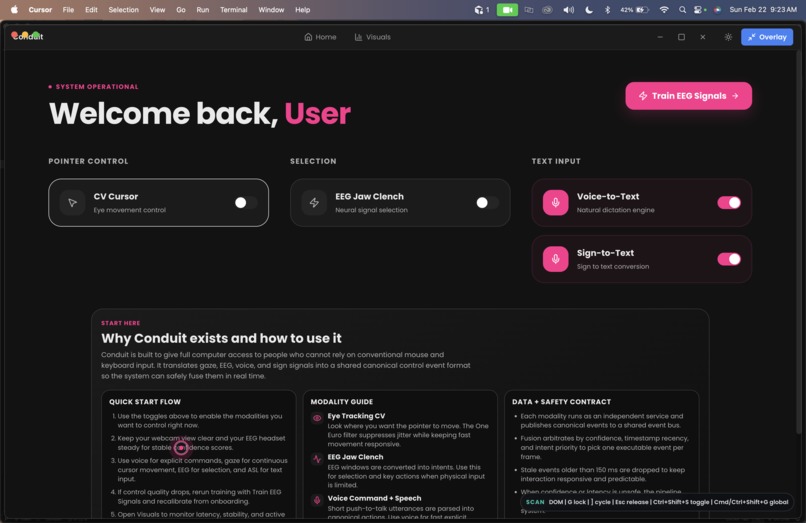
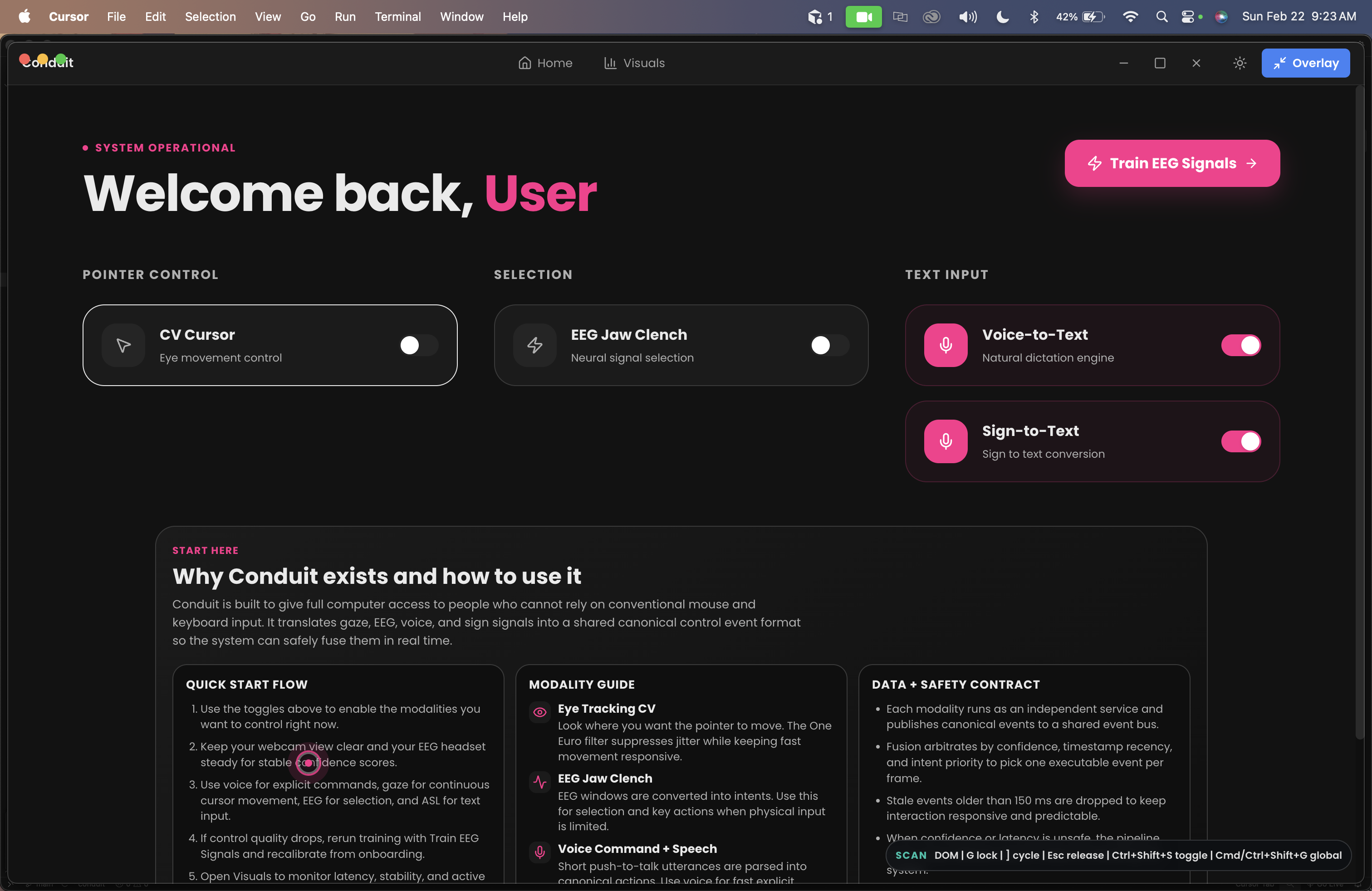
Home page
-
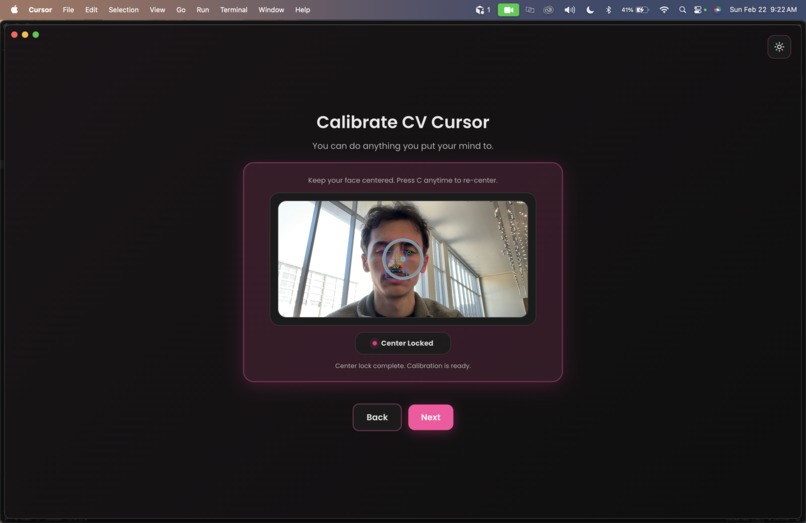
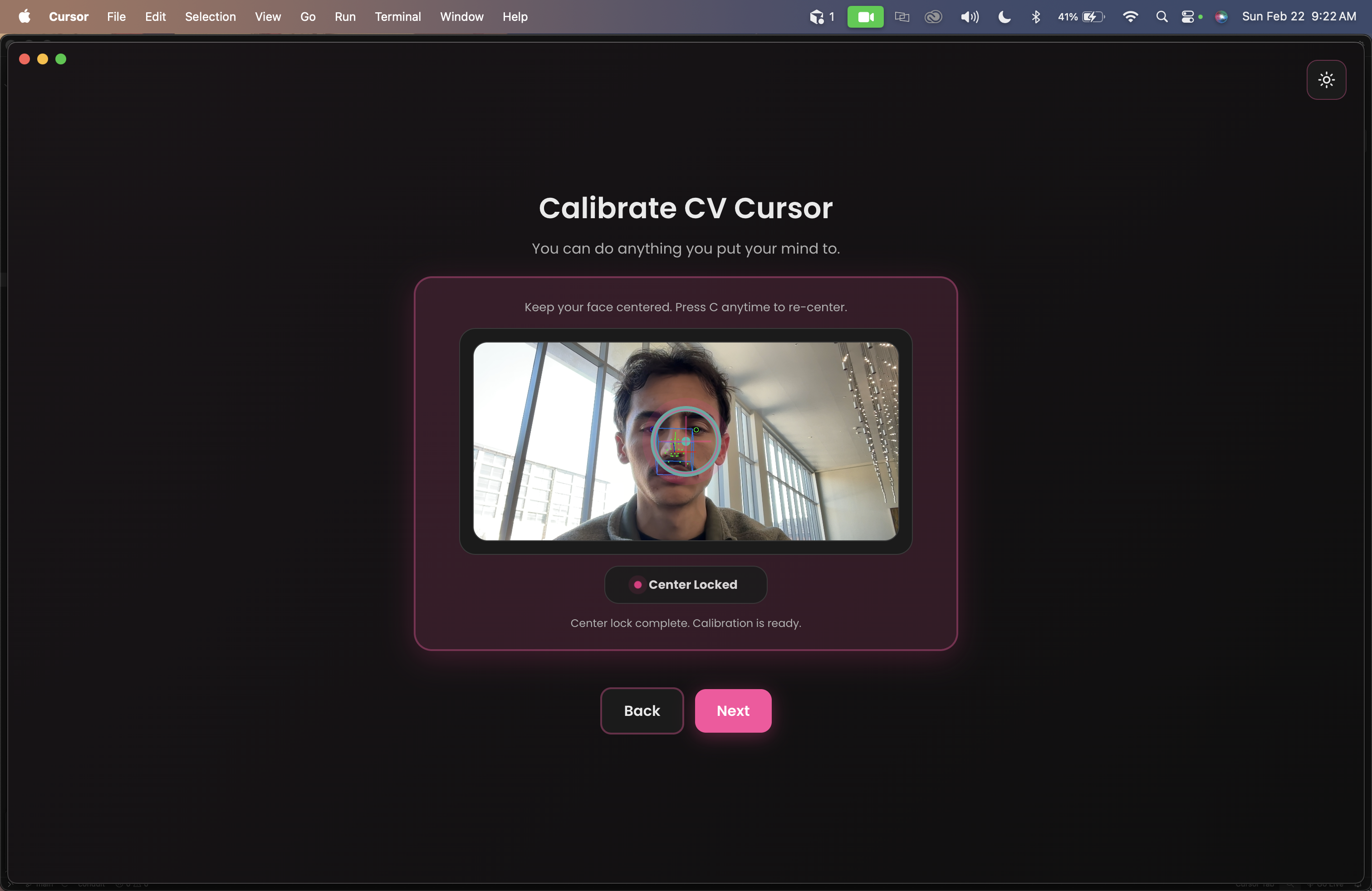
Initial calibration
-
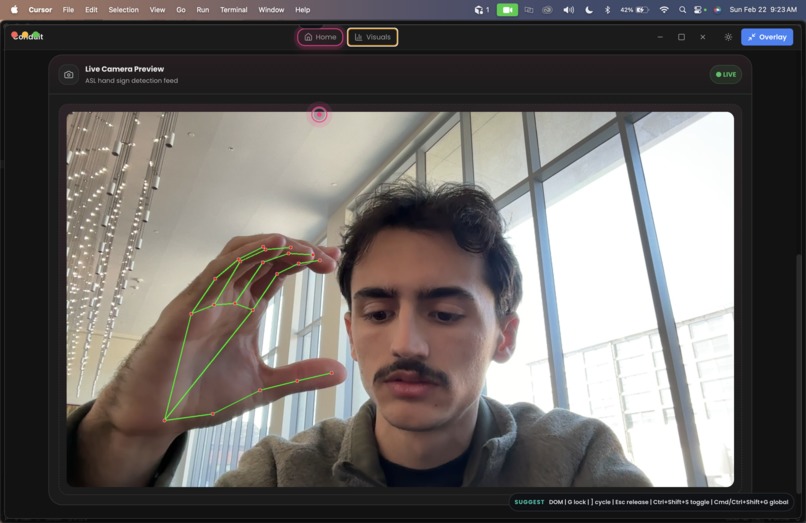
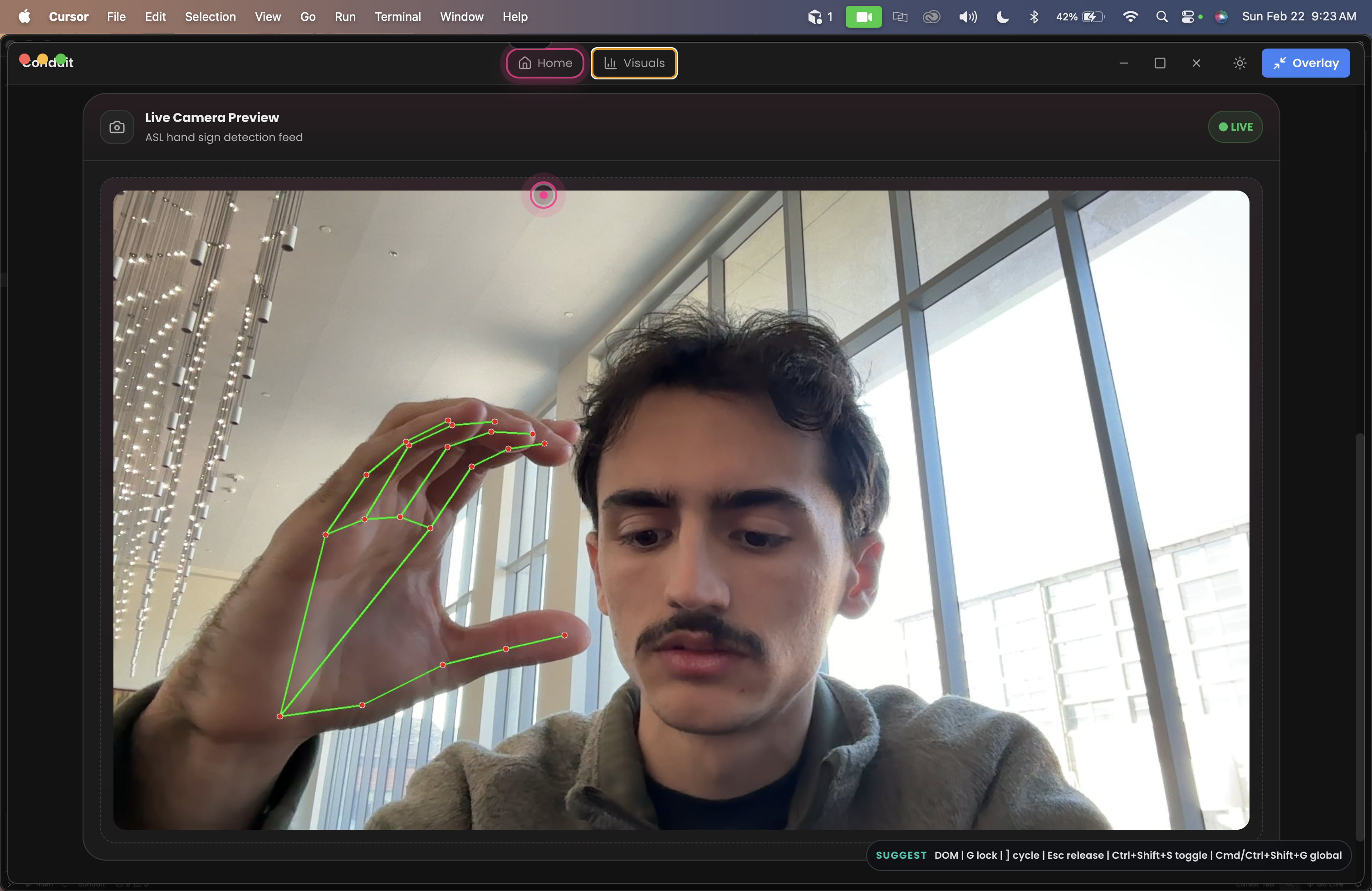
CV ASL Visualizer within our Visualization tab.
-
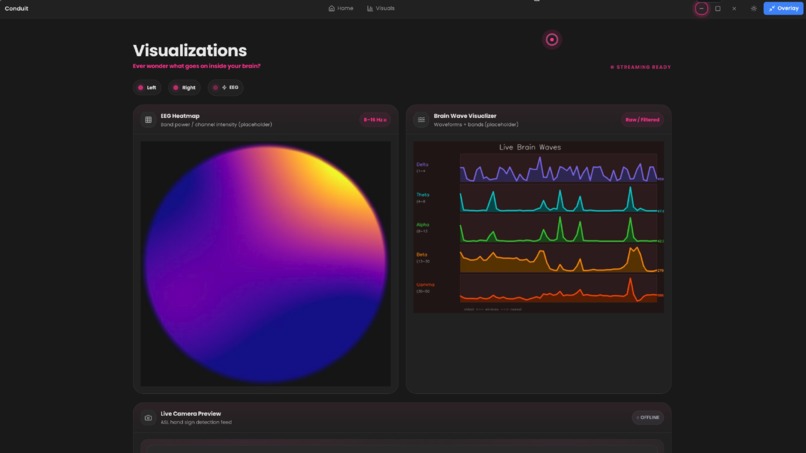
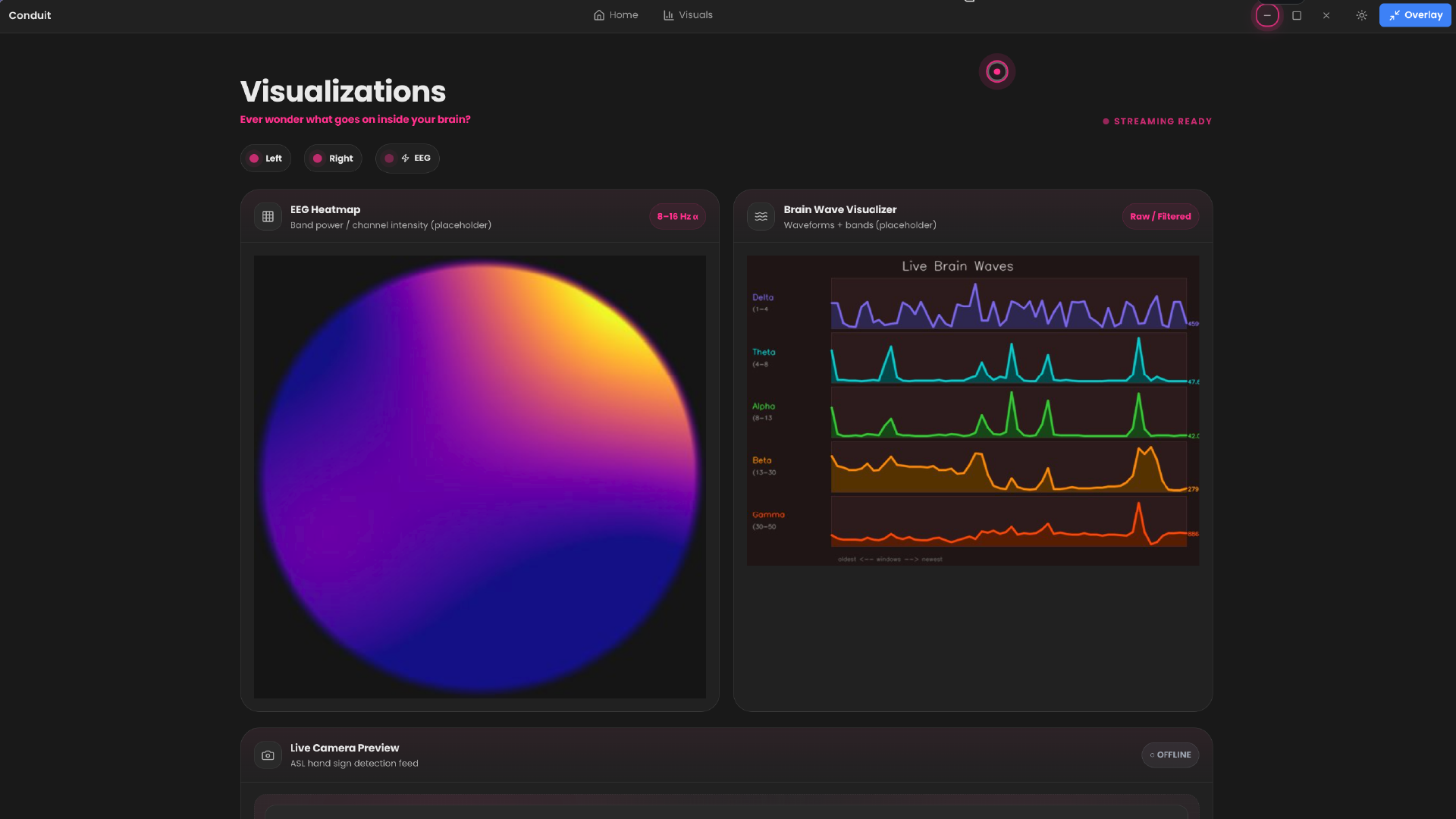
Visualization tab where we show realtime heatmap and EEG wave visualizers







Inspiration
Currently, 1.3 billion humans suffer from disability, over 30% of the people living with disability are unable to use conventional computer controls. Every interface we interact with daily assumes you can move a hand, speak clearly, or see a screen.
For hundreds of millions of people, that assumption is an exclusion.
We built Conduit because we believe full computer access is not a privilege, but a right. No one should be locked out of it because the tools only work in one way.
What it does
Conduit provides a data driven solution to computer accessibility. Conduit does this by treating each input method as a data stream, we aggregated alternative biological and behavioral signals and transformed them into canonical computer events
We currently support four independent modalities:
- Voice Command and Speech to Text: Audio input is transcribed and passed through using Eleven Labs into Gemini to support commands and Speech to Text. Where any user can speak to access the keyboard, or have easy access to just about any computer operation.
- EEG Mouse Control: We extracted frequency domain features from raw EEG data and classified user intent. A sliding window feature extractor converts brainwave signals into actionable events
- Eye Tracking CV: takes each webcam frame, runs face/iris landmark detection, and converts gaze geometry into screen space coordinates, then uses quality gating plus a One Euro filter to keep micro jitter out while preserving fast eye movements, with gain/ramp, bounds, and max-speed logic shaping final cursor movement. Those stabilized targets are published as canonical gaze_target events for fusion/control, with low-confidence/invalid frames safely held or suppressed so the system can stay stable and responsive.
- ASL CV: A custom trained MobileNetV2 model with channel attention modules classifies ASL hand signs in real time. Predictions are smoothed across frames before emitting keyboard events.
- * Data driven? ** Conduit is data-driven at every layer from deep learning models powering gesture recognition to real-time signal processing for cursor control. Each modality follows a structured pipeline: ingest → preprocess → model → filter → structured event.
We also implemented error prediction over time in the EEG system where the data becomes a closed loop cycle of continuous learning to improve the users experience overtime.
How we built it
We built Conduit with the scope in mind. We made architecture conscious decisions in order to avoid as many issues as possible and to make it seamless. Each modal runs individual to itself.
Eye Tracking: 478 facial landmarks extracted per frame. 3D iris vectors projected onto a calibrated monitor plane, One euro filter for adaptive smoothing.
STT Audio captured and sent to ElevenLabs, intent classification via Gemini, events are then emitted asynchronously to prevent blocking.
ASL Vision Model: Custom channel attention modules Balanced augmented dataset prediction smoothing to avoid false positives
EEG Muse headset streaming, 256 sample sliding windows 10 engineered features per channel 1-45hz bandpass filtering majority vote stabilization buffer.
Challenges we ran into
- Head movement introduced geometric instability. We decided to implement 3D sphere calibration to anchor iris vectors to head pose.
- Gaze required <50ms responsiveness while STT ranged 300-800ms. We integrated fully asynchronous pipelines which ensured no modality blocked another.
Accomplishments
- Four modality system running simultaneously in real time
- Custom ASL classifier recognizing all 26 letters
- Stable 3D gaze tracking robust to head movement
- EEG based binary intent detection using consumer hardware
- Unified canonical event schema across all agents
What we learned
- Multimodal systems are constrained more by latency and concurrency than model accuracy
- Filtering and signal stabilization matter
- Early architectural decisions reduce integration complexity
Whats next
- Integrate more features to provide more for disabled people
Figma Make Challenge Consideration
Please refer to Figma Make Challenge Google Form Submission by Elizabeth Pretto-Sotelo
Built With
- electron
- elevanlabs
- fastapi
- gemini
- opencv
- python
- typescript











Log in or sign up for Devpost to join the conversation.