-
-

Home
-
Job
-
Agents
-
Results
-
Insights
-
Pipeline
-
Home

Inspiration
High-performance computing has a paradox: the people who need massive parallel simulations the most often can't access HPC resources efficiently because of the steep technical barrier. They speak the language of their domain, not shell scripts and batch schedulers.
We wanted to build a system where you could just describe what you want to compute in plain English, and AI would handle everything else. No infrastructure knowledge required.
What it does
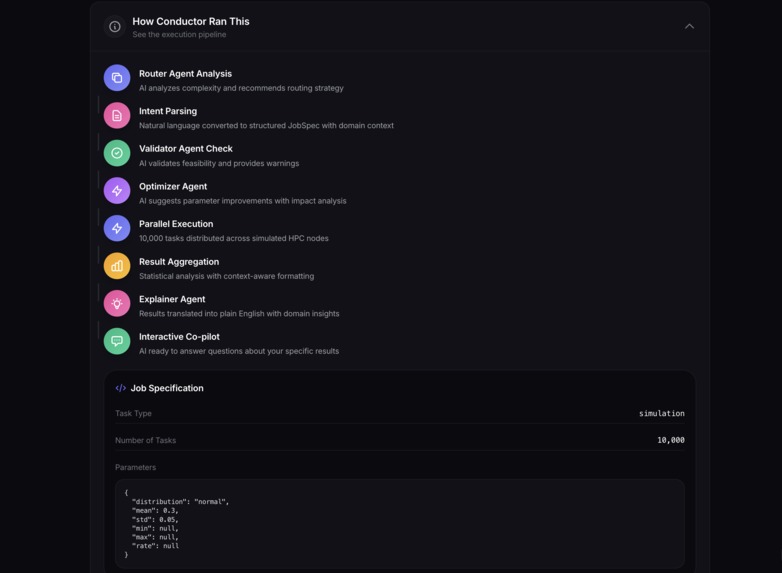
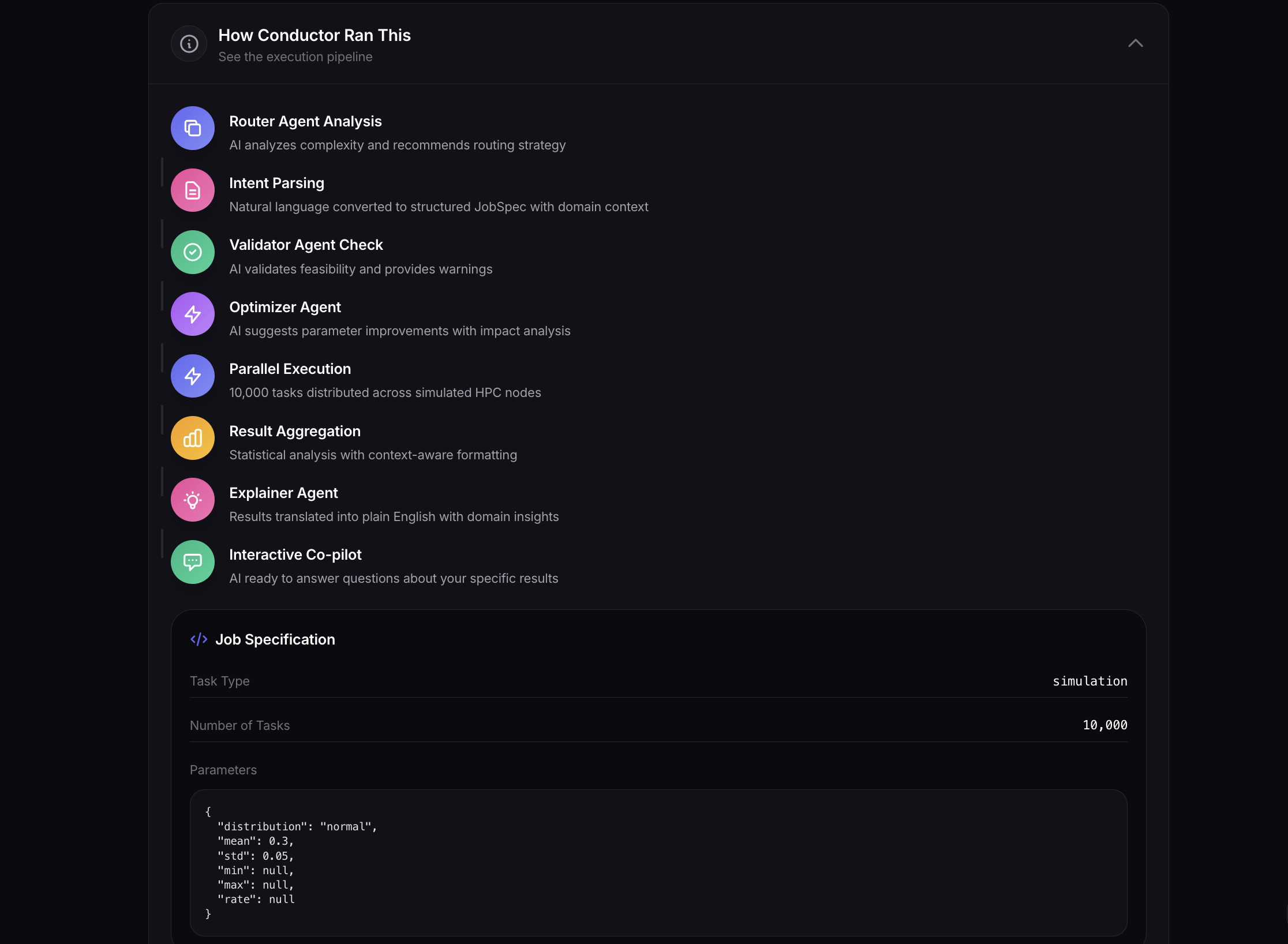
Conductor transforms natural language into optimized, parallel compute workloads through a multi-agent AI system:
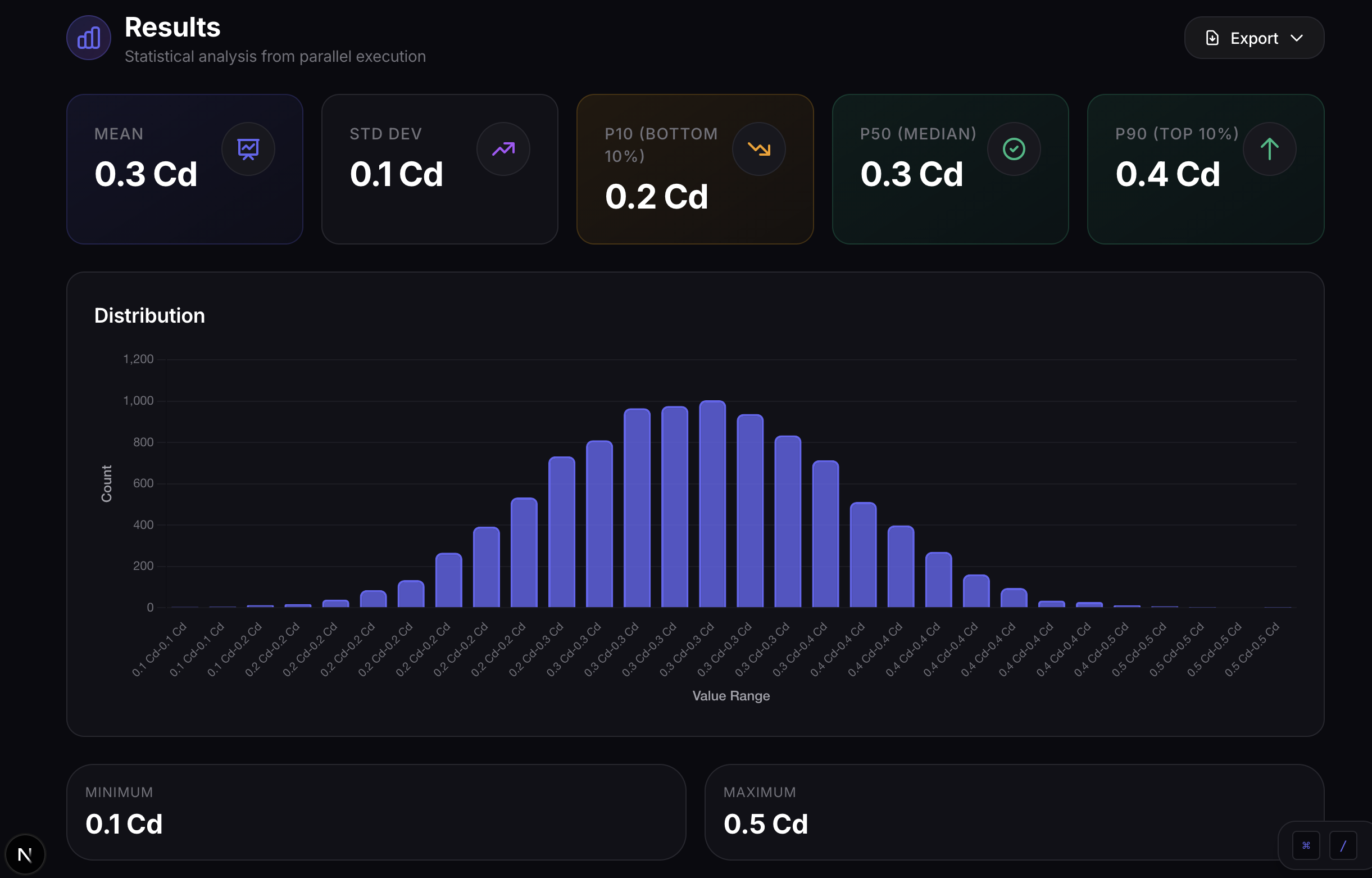
- You type what you want to compute: "Optimize aerodynamic drag across 10,000 wing configurations"
- A Router Agent analyzes your intent and determines the best execution strategy
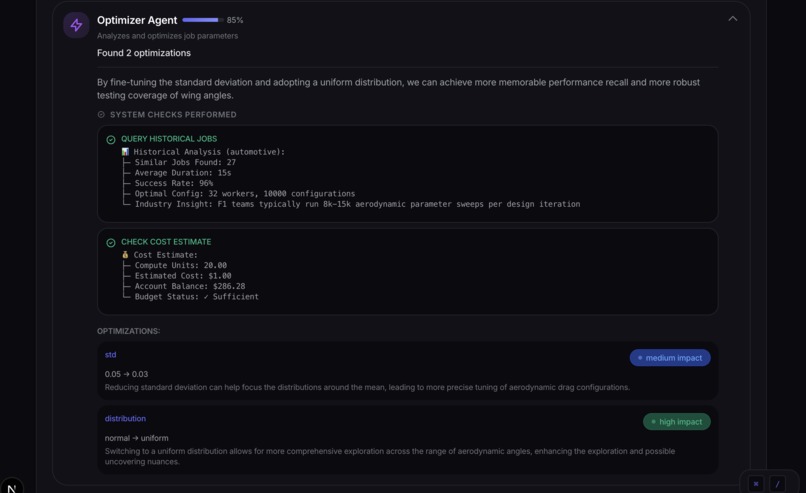
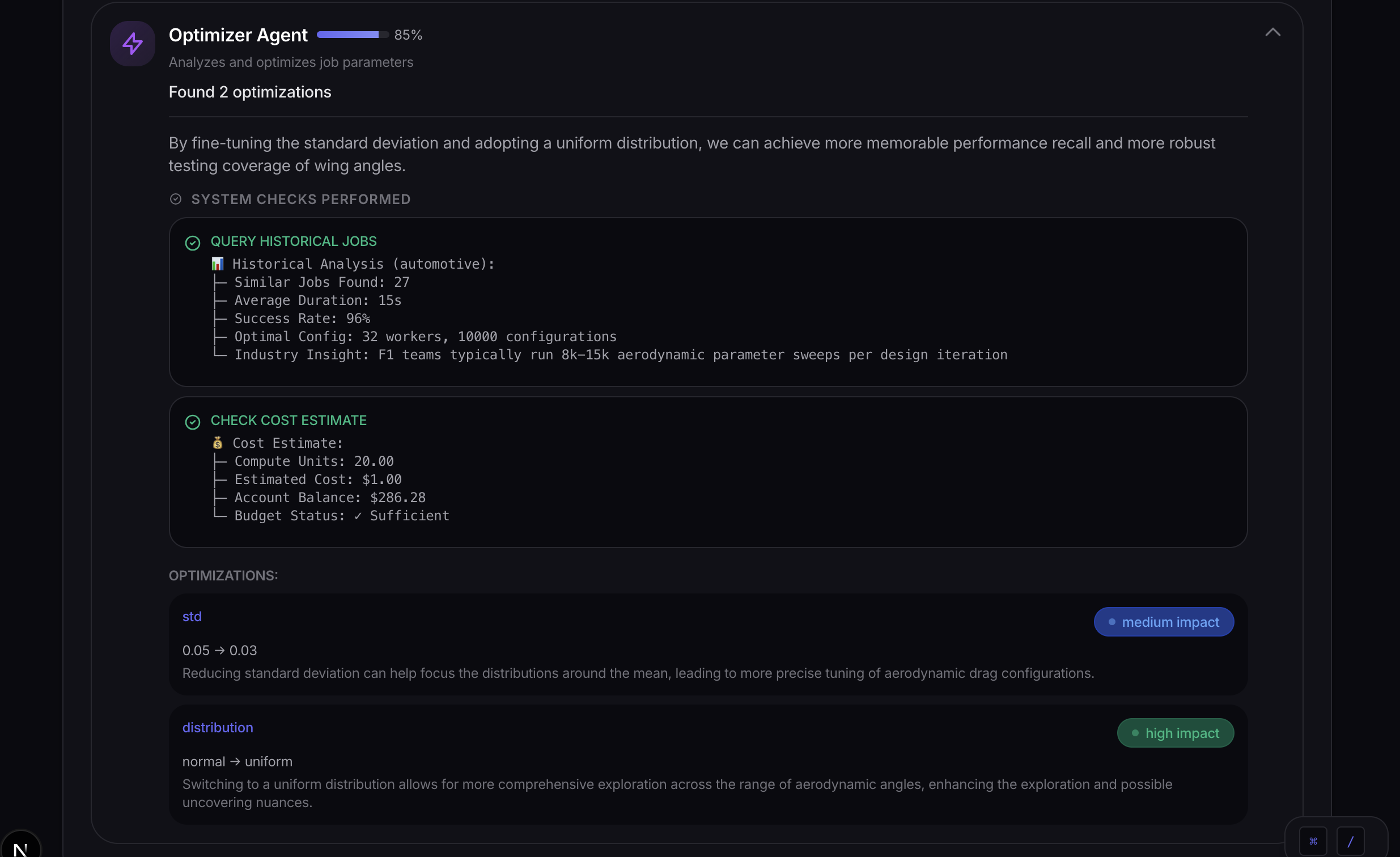
- An Optimizer Agent refines parameters based on domain knowledge and historical data
- A Validator Agent performs pre-flight checks on feasibility and data sources
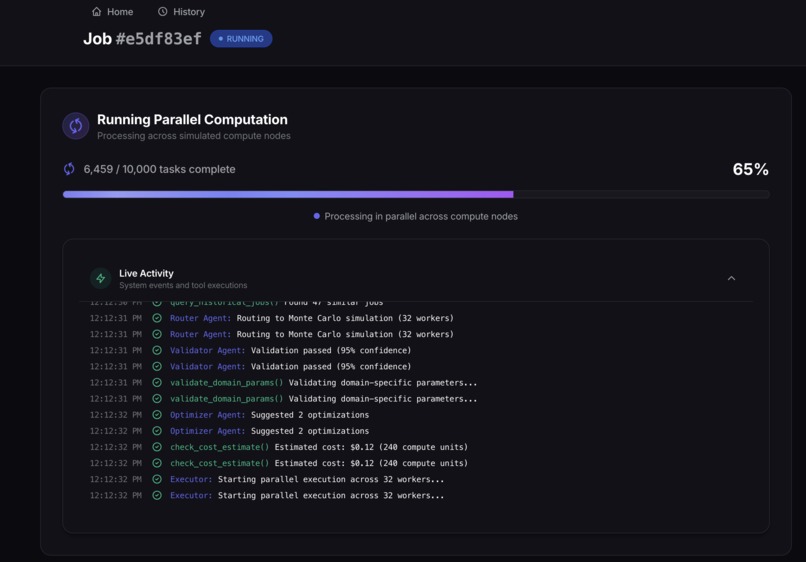
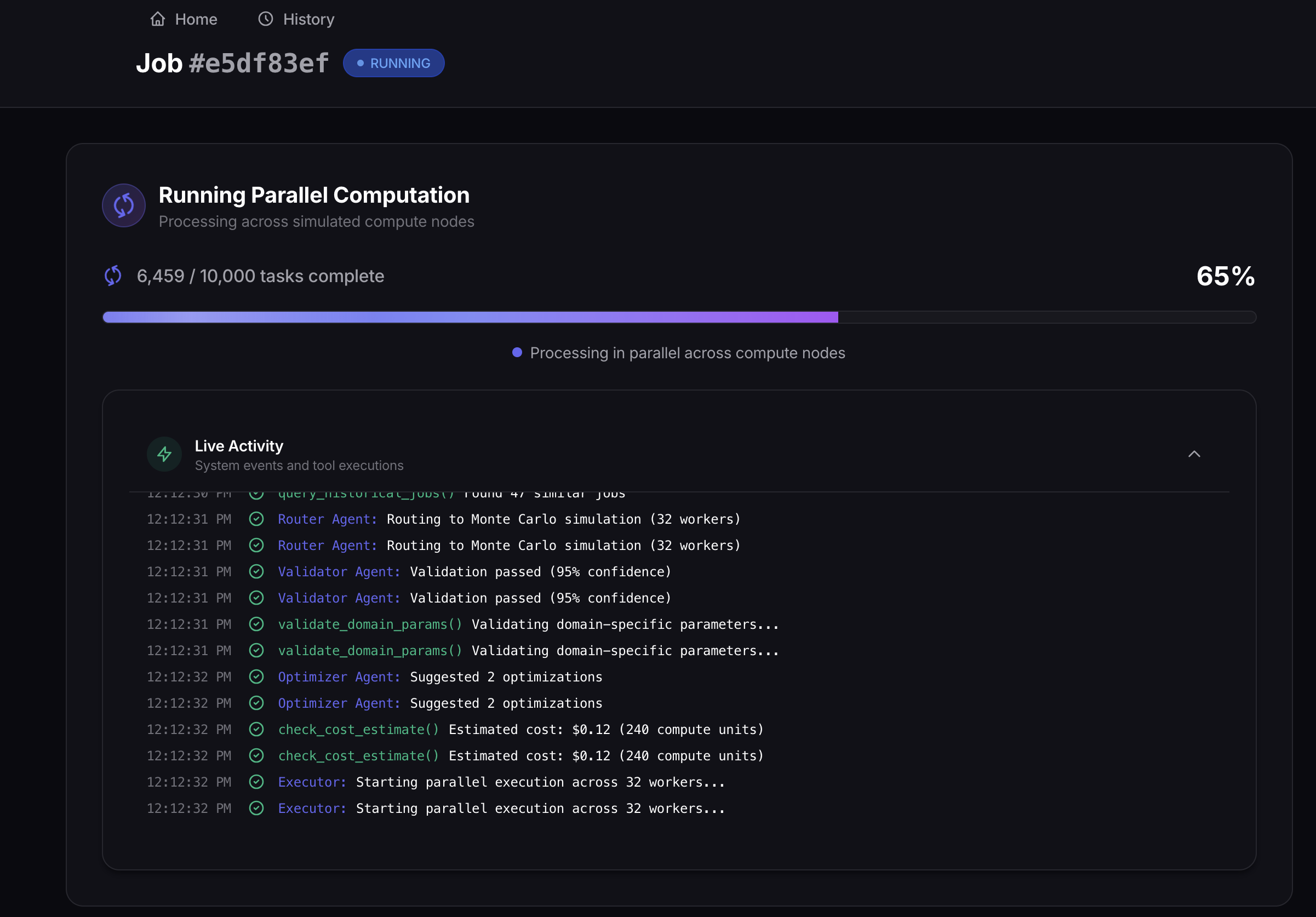
- The system executes thousands of parallel tasks with real-time progress tracking
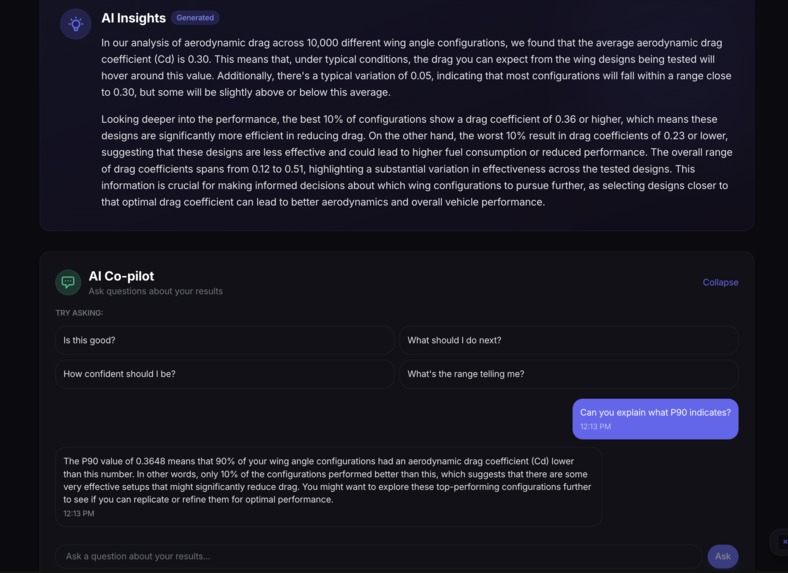
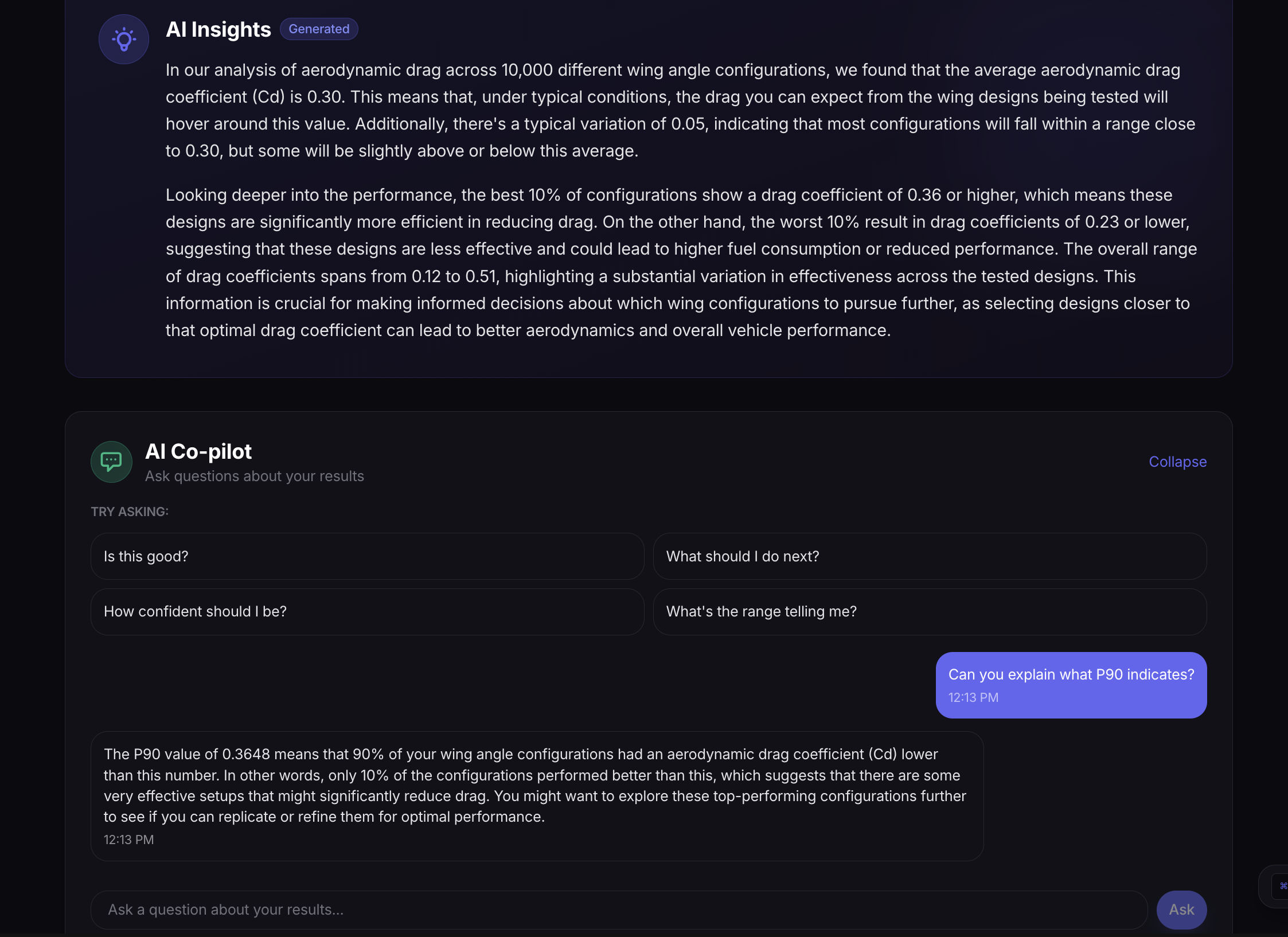
- An Explainer Agent translates statistical results into plain-English insights
- An Interactive Co-pilot lets you explore results conversationally
The entire workflow from intent to insights happens without writing a single line of code or configuring any infrastructure.
How we built it
Frontend: Next.js with TypeScript and Chart.js for visualizations
Backend: Python FastAPI with OpenAI's GPT-4o-mini
Agent Architecture: Each agent has a specialized role with its own system prompt and decision-making logic. We implemented a mock Model Context Protocol (MCP) where agents can call "tools" like check_cluster_status() and validate_data_source() to simulate real HPC interactions.
Challenges we ran into
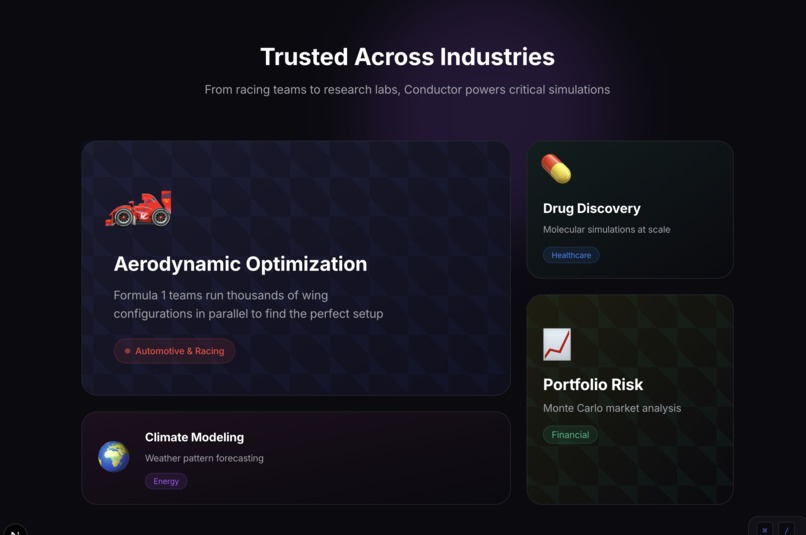
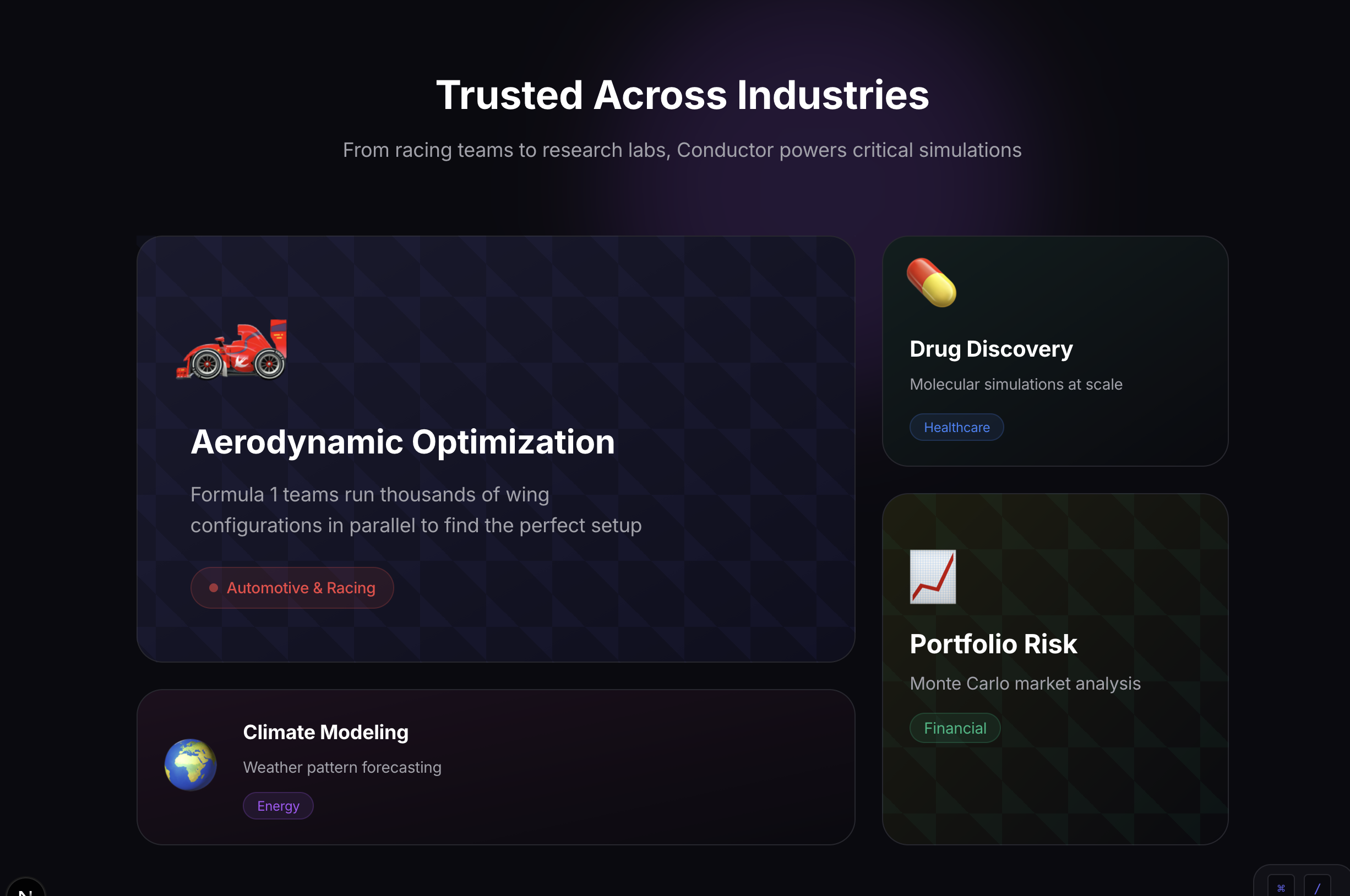
Context-aware defaults: When users typed "weather analysis," they expected temperatures in Fahrenheit, not arbitrary units. We built a domain inference system that detects keywords and applies realistic defaults. Getting this right required understanding what "realistic" meant for each domain such as drag coefficients for automotive, efficacy percentages for healthcare, etc.
Getting agents to feel dynamic: AI agents initially produced identical outputs every time always suggesting the same optimizations, always 90% confident. We learned that just increasing temperature wasn't enough. We had to explicitly prompt the agents to vary their behavior.
Accomplishments that we're proud of
The multi-agent system actually works. Getting five AI agents to collaborate where the Router's output feeds into the Optimizer, which feeds into the Validator was complex, but the system feels cohesive and intelligent.
Real-time transparency. We built a collapsible AI reasoning panel that shows each agent's thought process, confidence scores, and tool calls. Users can see exactly why the system made each decision. Transparency builds trust.
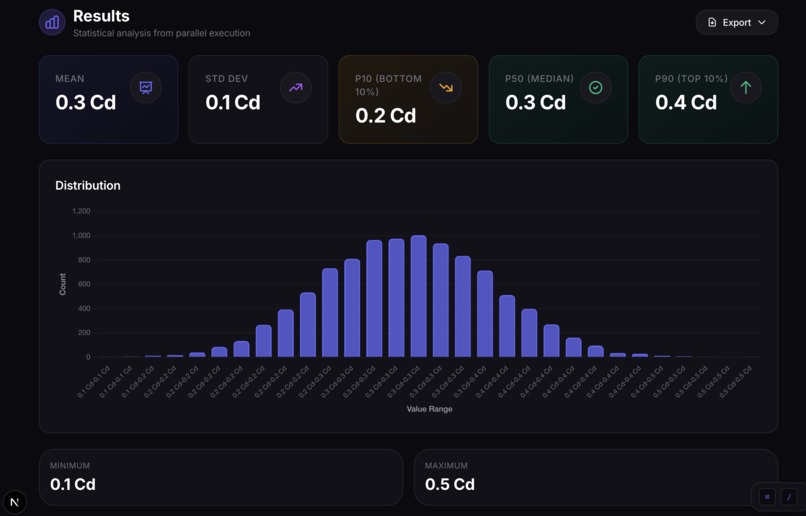
It feels real. Even though we're simulating HPC workloads, the system produces domain-appropriate results with proper units and realistic distributions. An automotive engineer would recognize drag coefficients; a financial analyst would recognize portfolio values.
What we learned
Prompt engineering matters more than model parameters. We spent time adjusting temperature and token limits before realizing that better prompts (explicit variance instructions, domain-specific examples) were far more effective for the LLM calls.
What's next for Conductor
Data source connectors: S3, Google Cloud Storage, institutional databases let users reference real datasets in their prompts.
Collaboration features: Share job templates, compare results across teams, build a library of common workflows.
Built With
- chart.js
- gpt-4o-mini
- next.js-16
- numpy
- pydantic
- python-fastapi
- react
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.