
Inspiration
Every data team has lived some version of this story. It's Friday afternoon. Someone in marketing, well intentioned and in a hurry, connects a new data source to the company's Fivetran account. It works perfectly, that's the point of Fivetran, and by Monday millions of rows have landed in the warehouse. But nobody reviewed it. Nobody knew it existed. A schema change from that source has quietly propagated downstream: three executive dashboards show wrong numbers, a dbt model is broken, and the on call data engineer spends the day doing archaeology instead of engineering. The postmortem ends with the same sentence as the last one: "nobody was watching."
Here's what struck us: software engineering solved this exact problem decades ago. No code reaches production without a pull request. No deploy happens without CI gates. No infrastructure changes without review. We take these guardrails so much for granted that working without them feels reckless.
Data teams haven't built that layer for their pipelines yet, and it's not for lack of raw material. Fivetran already exposes everything a control plane needs: per table usage metering through the Platform Connector, real time webhooks for every connector event, and a REST API that can act on the fleet. What's missing is something that uses all of it continuously: reviewing every new connector against policy, watching schema changes before they surprise downstream consumers, reading the sync logs nobody has time to read, and answering the CFO's question of "who is consuming what, and why?" with evidence instead of a shrug.
That gap has predictable, expensive symptoms: broken models, silent data quality incidents, and waste like cold tables syncing millions of rows that nobody has queried in months. But we want to be precise about something. The money is not the problem. The money is the symptom. The problem is that nobody, and realistically no human team at this scale, is watching continuously. Fix that, and the waste, the breakage and the chaos fix themselves.
When this hackathon asked us to build agents that "don't just provide answers, but help you take action," we knew exactly what to build. Continuous pipeline governance is the perfect agentic problem: it requires constant vigilance (humans get bored), evidence based judgment (LLMs are great at synthesis), real execution (Fivetran's APIs make it possible), and, critically, human accountability for consequential decisions. That last part is what most agent demos get wrong, and what we obsessed over.
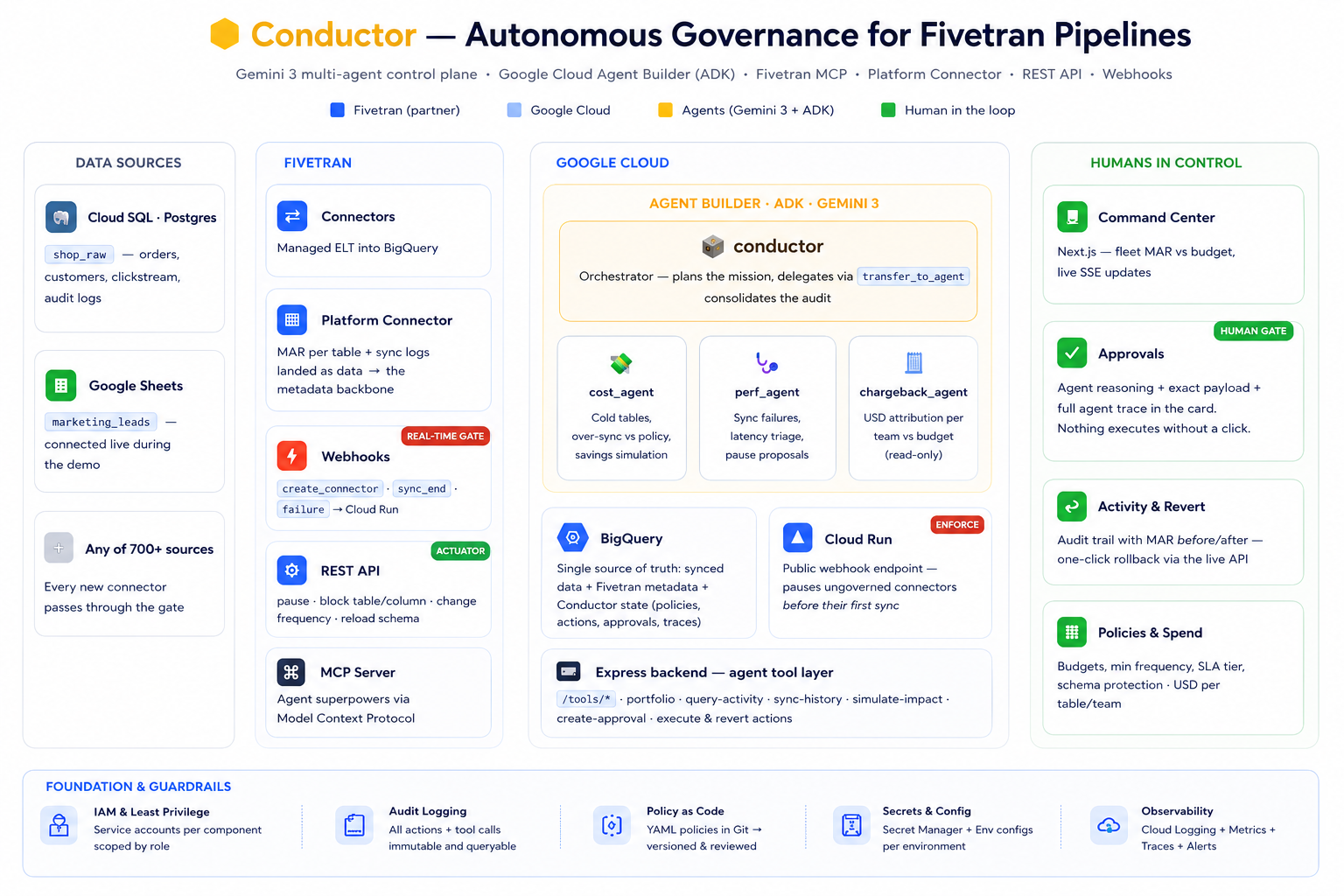
We built Conductor: a governance control plane on top of Fivetran's own platform primitives, run by a team of Gemini agents, with a human holding the keys.
What it does
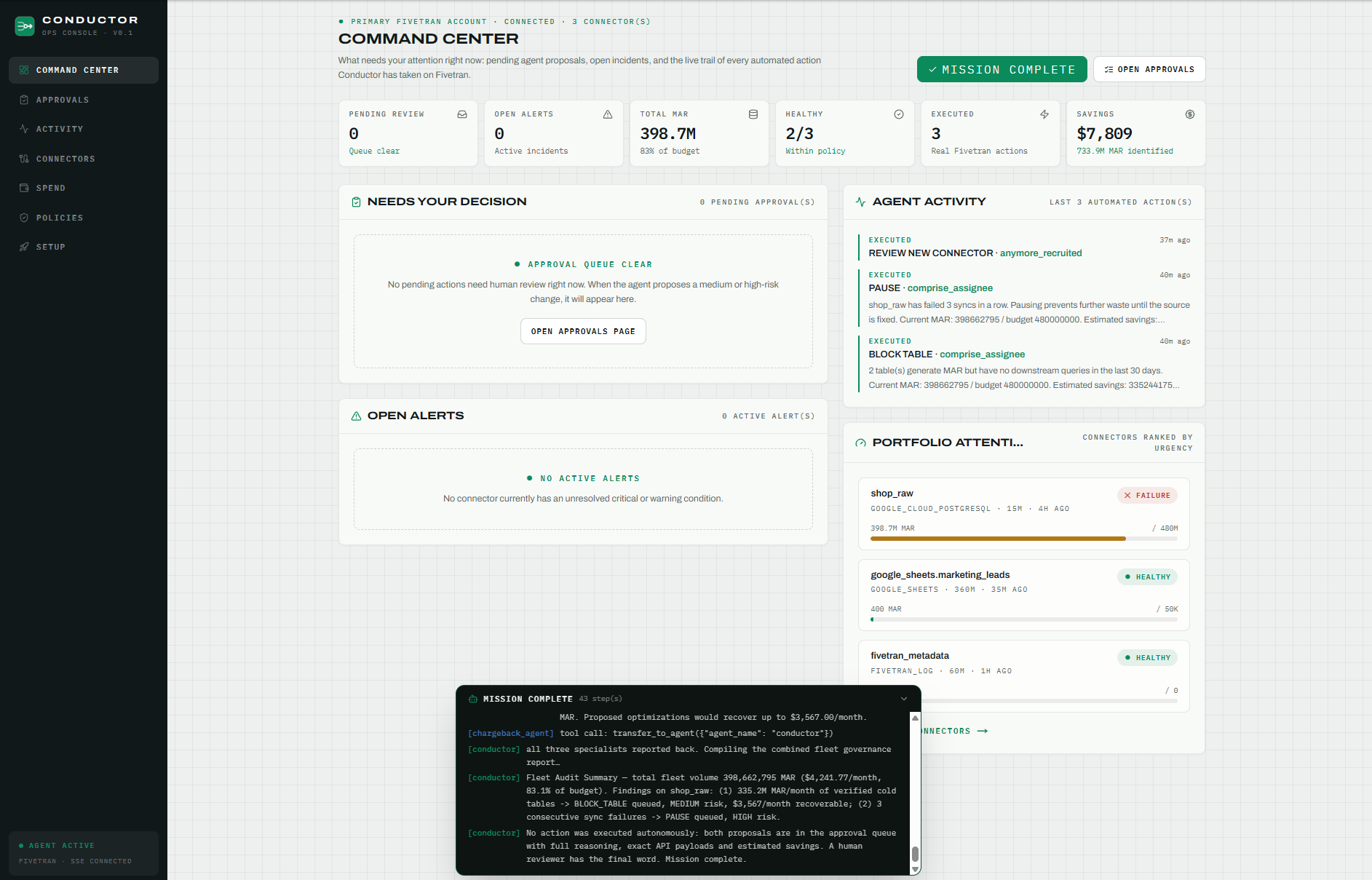
Conductor sits on top of a real Fivetran fleet syncing into BigQuery and does four things: it watches, it reasons, it proposes, and, only after a human approves, it acts.
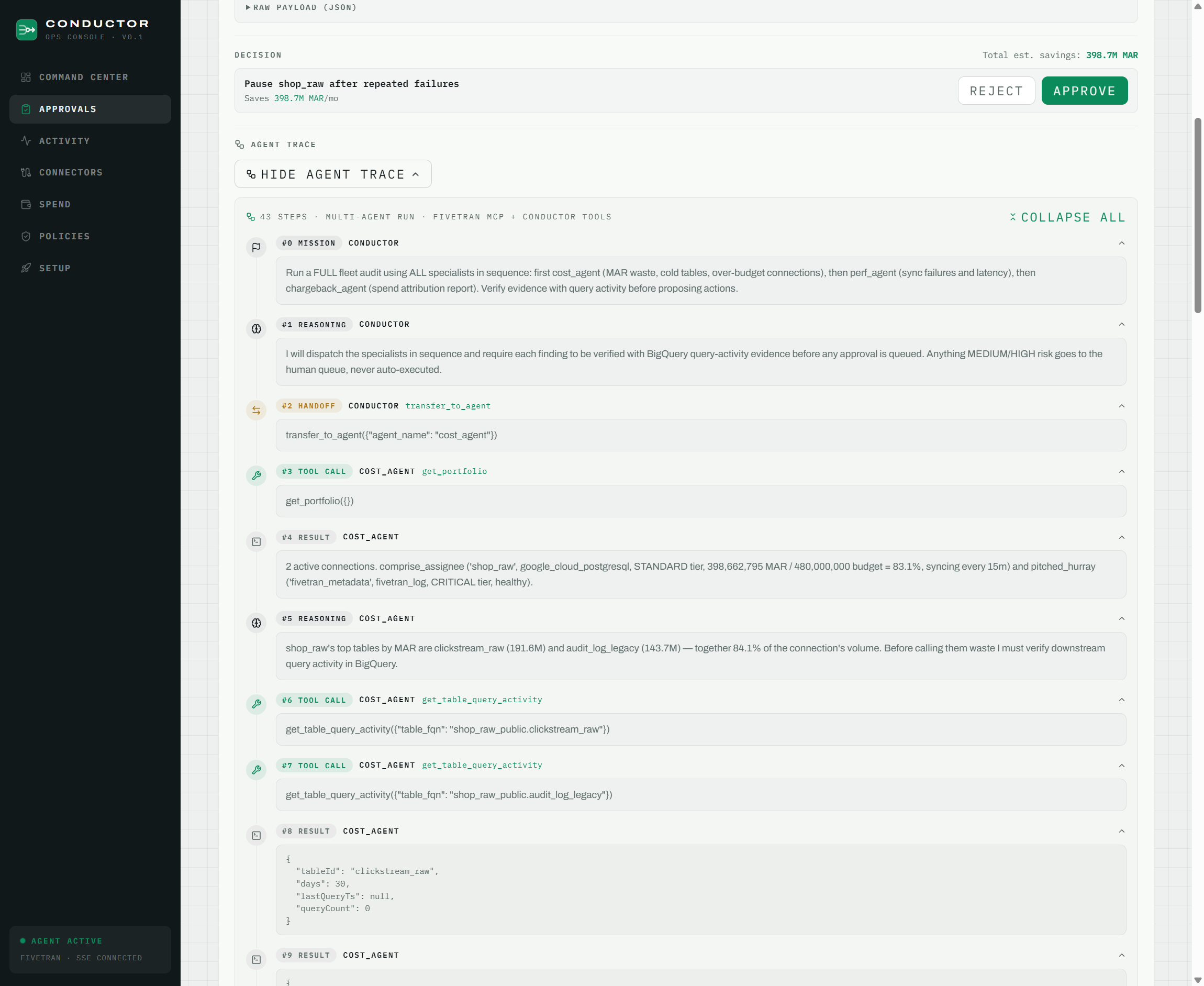
1. The multi agent fleet audit. A conductor orchestrator agent (Gemini 3, built on Google Cloud Agent Builder / ADK) receives a mission, such as "run a full fleet audit", plans it, and delegates to three specialists via agent to agent handoffs:
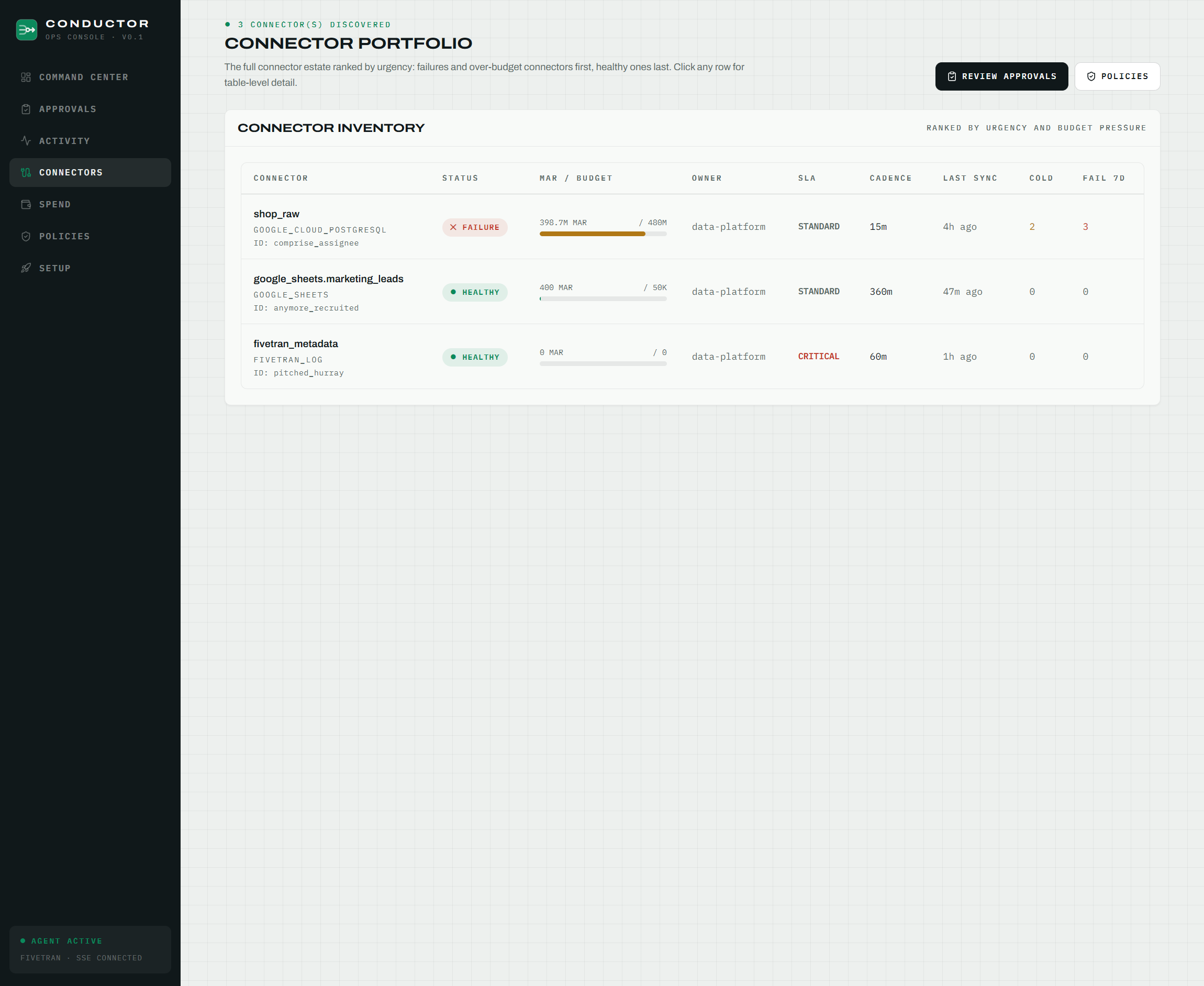
cost_agenthunts waste. Its signature move is detecting cold tables: it reads Fivetran's own per table MAR metering (landed in BigQuery by the Fivetran Platform Connector) and cross references it against BigQuery'sINFORMATION_SCHEMAquery logs. A cold table isn't a hallucination or a heuristic. It's a table where the company paid to sync 191 million rows this month, and the query logs show zero reads in 30 days. It also catches policy violations, like a connector syncing every 15 minutes when its policy mandates a 60 minute minimum. Before proposing anything, it simulates the optimization impact and prices it in dollars.perf_agenttriages health. It reads the Fivetran sync log, detects patterns like three consecutive failures with the same JDBC timeout, and autonomously proposes pausing the connector, citing the actual timestamps, durations and failure reasons as evidence.chargeback_agentanswers the CFO question. It attributes MAR and dollars to each connection and team, compares against budgets, and produces a finance ready spend attribution report. By design, it's read only, because reporting shouldn't have side effects.
One mission produces roughly 60 tool calls across four agents, every one of them traced and persisted.
2. Human in the loop approvals, with the receipts. Nothing the agents propose executes on its own. Every action lands in an approval queue, and each decision card contains three things: the agent's reasoning in plain language with the numbers it found, the exact API payload that will execute on approve, and the complete agent trace embedded in the card: every handoff, every tool call, every intermediate thought that led to this proposal. The human doesn't just judge the verdict; they judge the argument. Approve, and the action executes against the live Fivetran API. Made a mistake? Every executed action has a one click revert that also runs against the real API, with MAR before and after recorded in a permanent audit trail.
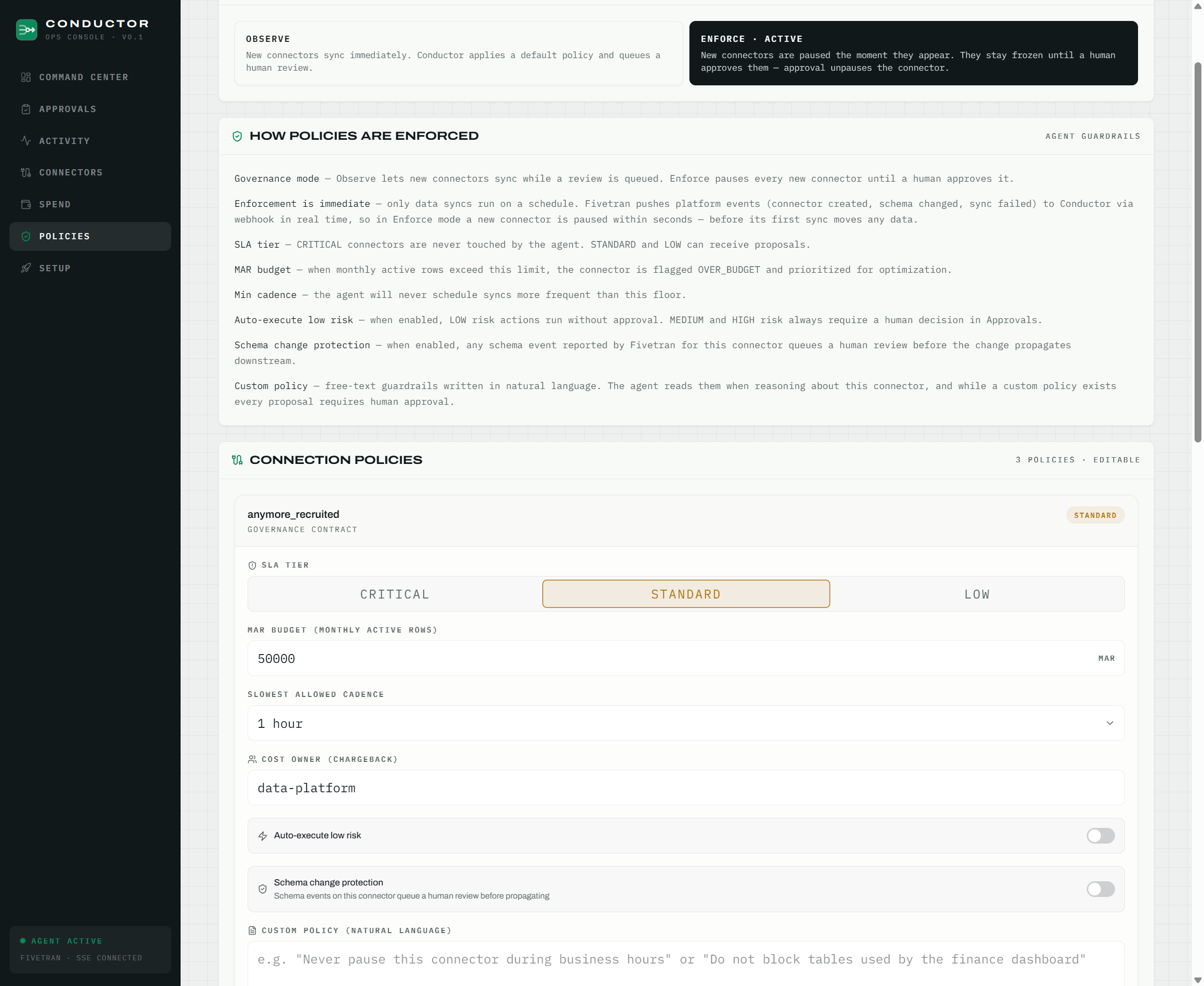
3. The real time gate. This is the heartbeat of the product. Register a Fivetran account webhook, flip Conductor to ENFORCE mode, and watch: someone creates a new connector in Fivetran's UI, any source, any time. The create_connector event hits our Cloud Run endpoint, and within seconds Conductor pauses the connector before its first sync, applies a default STANDARD policy (MAR budget, minimum frequency), and queues a review approval, complete with its own gate trace. Not one row reaches the warehouse until a human says so. Approve it, and Conductor unpauses the connector via the API and the sync begins. We demo this live, end to end, against the real Fivetran UI. Schema changes get the same treatment: connections with schema change protection enabled raise a review approval whenever Fivetran reports a structural change, so downstream consumers are never surprised again.
4. The governance surface. A Next.js Command Center gives humans the cockpit: fleet wide MAR vs budget, per connection detail with a policy editor (budget, minimum frequency, SLA tier, team owner, schema protection), a spend explorer with USD per table and connection, acknowledgeable alerts for budget breaches and failures (with optional Slack notifications to the owning team), live SSE updates, and an OBSERVE / ENFORCE toggle that sets the governance posture for the whole workspace: observe and review, or actively block ungoverned changes.
How we built it
The architecture is a deliberate separation of powers. Agents propose, policies constrain, humans decide, and everything is auditable:
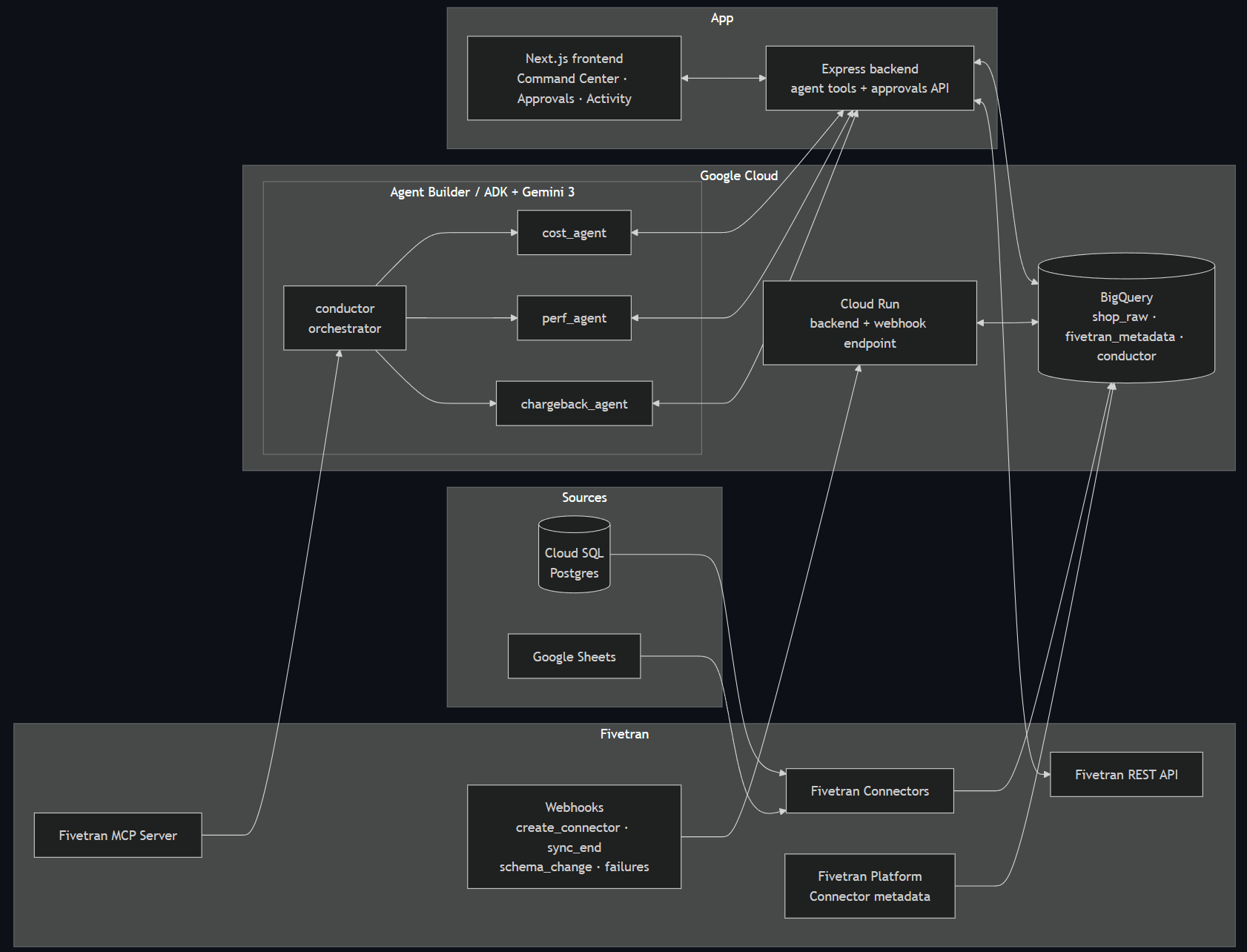
- Gemini 3 + ADK (Python). The agent system is an
LlmAgenthierarchy: a root orchestrator with three specialist sub agents connected bytransfer_to_agenthandoffs. Each specialist has its own toolset and a strict prompt contract: every claim must come from a tool call, and every proposal must carry its evidence and a simulated impact. The trace of each run, every step from mission to final report, is published to BigQuery so the UI can replay it. - Fivetran, integrated four ways. The MCP server gives agents their partner superpowers. The Platform Connector is our metadata backbone: Fivetran metering its own MAR per table directly into BigQuery, which means our cost math runs on ground truth, not estimates. The REST API is the actuator: pause and unpause, block table or column, change sync frequency, reload schema. And account webhooks (
create_connector,sync_end, failures) close the real time loop. - BigQuery as the single source of truth. Synced operational data, Fivetran's metadata, and Conductor's entire state (policies, actions, approvals, agent traces, workspace settings) live in one place. The local backend and the Cloud Run deployment share it, so a webhook landing in the cloud shows up instantly in the operator's UI.
- Cloud Run hosts the public webhook endpoint and the deployed backend. The Express backend exposes the agent tool layer (
/tools/*: portfolio, query activity, sync history, impact simulation, approval creation, action execution and revert) and the operator API. The Next.js frontend is the human cockpit.
Challenges we ran into
- Race conditions against a live SaaS. Our gate pauses a new connector the moment the webhook fires, but we discovered Fivetran flips the connector back to active when its setup test completes, after our pause. Real product moment: we built a re assertion loop that re checks the connector's state and re pauses it while the review is still pending. Demoing against live infrastructure means engineering for its quirks, not around them.
- Making agents trustworthy enough to touch production. Early prompts produced confident, plausible nonsense: invented table names, fabricated savings. The fix wasn't prompt tweaking; it was architectural. Tools became the only source of truth, proposals must embed their evidence, and the full reasoning trace ships with every approval. When a human can audit the argument, hallucinations have nowhere to hide.
- Calibrating every dollar to reality. It's easy to demo impressive fake numbers. We refused. We calibrated the entire fleet against Fivetran's official pricing simulator: our demo fleet's 398.6M MAR corresponds to a real $4,241.95/month quote, which gives a true effective rate of $10.64 per million MAR. The $3,567/month of waste the agents find is what this would actually cost.
- Multi location BigQuery, streaming buffers, webhook signatures. The unglamorous plumbing that separates a slideware demo from a system that runs.
Accomplishments that we're proud of
The single proudest moment: a judge can open Fivetran's real UI, create a real connector, and watch Conductor freeze it before one row syncs, then approve it in Conductor and watch the sync start. That five second moment is the product thesis, live, with no mocks and no video cuts. Beyond that: four agents collaborating in a single traced mission, an approvals UX where the agent's full reasoning chain lives inside the decision card, dollar accurate findings calibrated to the partner's own pricing, and rollback for every action, because governance without undo is just bureaucracy.
What we learned
Agents earn trust the same way junior engineers do: by showing their work and asking before acting. The breakthrough in this project wasn't a smarter model or a cleverer prompt. It was the governance architecture around the model. Agents propose with evidence. Policies set the boundaries. Humans make the consequential calls. Every decision is recorded forever. Once that structure existed, Gemini's reasoning became something we could deploy, not just admire. We also learned that the most convincing agent demos are the ones with the least theater: real APIs, real metadata, real money, real pauses.
What's next for Conductor
- Graduated autonomy: low risk actions (like blocking a table that has been cold for 90+ days) auto approve after a track record, with humans reviewing summaries instead of every action. Earned trust, encoded.
- Anomaly detection on MAR trends: catch the connector that doubled its volume this week, before the invoice does.
- Slack native approvals: decide where the team already lives.
- Multi destination and multi workspace support for real enterprise fleets.
- Policy as code: versioned, reviewable governance policies, so data governance finally gets its
git diff.
Built With
- adk
- express.js
- gemini
- next.js

Log in or sign up for Devpost to join the conversation.