
Inspiration
We've all been there — staring at a grade on an exam and having no idea what went wrong. A student scores 62% on a data structures exam, but that number says nothing about whether they struggled with recursion, graph traversal, or just the one question on hash tables that tripped everyone up. Instructors face the inverse problem: a gradebook full of numbers with no way to trace why students are failing, or which foundational gap, if fixed, would unlock the most downstream improvement.
We were inspired by the idea that exam scores contain far more signal than a single number. If you know which questions map to which concepts, and which concepts depend on which prerequisites, you can propagate weakness backward through a dependency graph and surface the root cause — not just the symptom. The second inspiration came from frustration with linear AI chat. When studying a topic like photosynthesis, you inevitably want to branch: explore light reactions in one direction, the Calvin cycle in another. A single chat thread forces you to choose one path and lose the other. We wanted a spatial, visual interface where every tangent gets its own thread — connected, not competing.
What it does
ConceptPilot is two systems in one:
1. The Readiness Engine — a deterministic analytics pipeline that takes three inputs (exam scores, question-to-concept mappings, and a concept prerequisite graph) and computes per-student, per-concept readiness scores. The core formula:
$$R_{\text{final}}(s, c) = \text{clamp}\Big[\alpha \cdot R_{\text{direct}}(s, c) \;-\; \beta \cdot P(s, c) \;+\; \gamma \cdot B(s, c),\;\; 0,\; 1\Big]$$
where:
- $R_{\text{direct}}(s, c)$ is the weighted normalized score for student $s$ on concept $c$
- $P(s, c) = \sum_{p \in \text{prereqs}(c)} w_{p \to c} \cdot \max\big(0,\; \tau - R_{\text{direct}}(s, p)\big)$ is the prerequisite penalty — how much upstream weakness drags down the current concept
- $B(s, c) = \min\Big(0.2,\; \sum_{d \in \text{children}(c)} 0.4 \cdot w_{c \to d} \cdot R_{\text{direct}}(s, d)\Big)$ is the downstream boost — bounded validation from strong performance on dependent concepts
- $\alpha, \beta, \gamma$ are tunable weights (defaults: 0.5, 0.3, 0.2) and $\tau$ is the weakness threshold
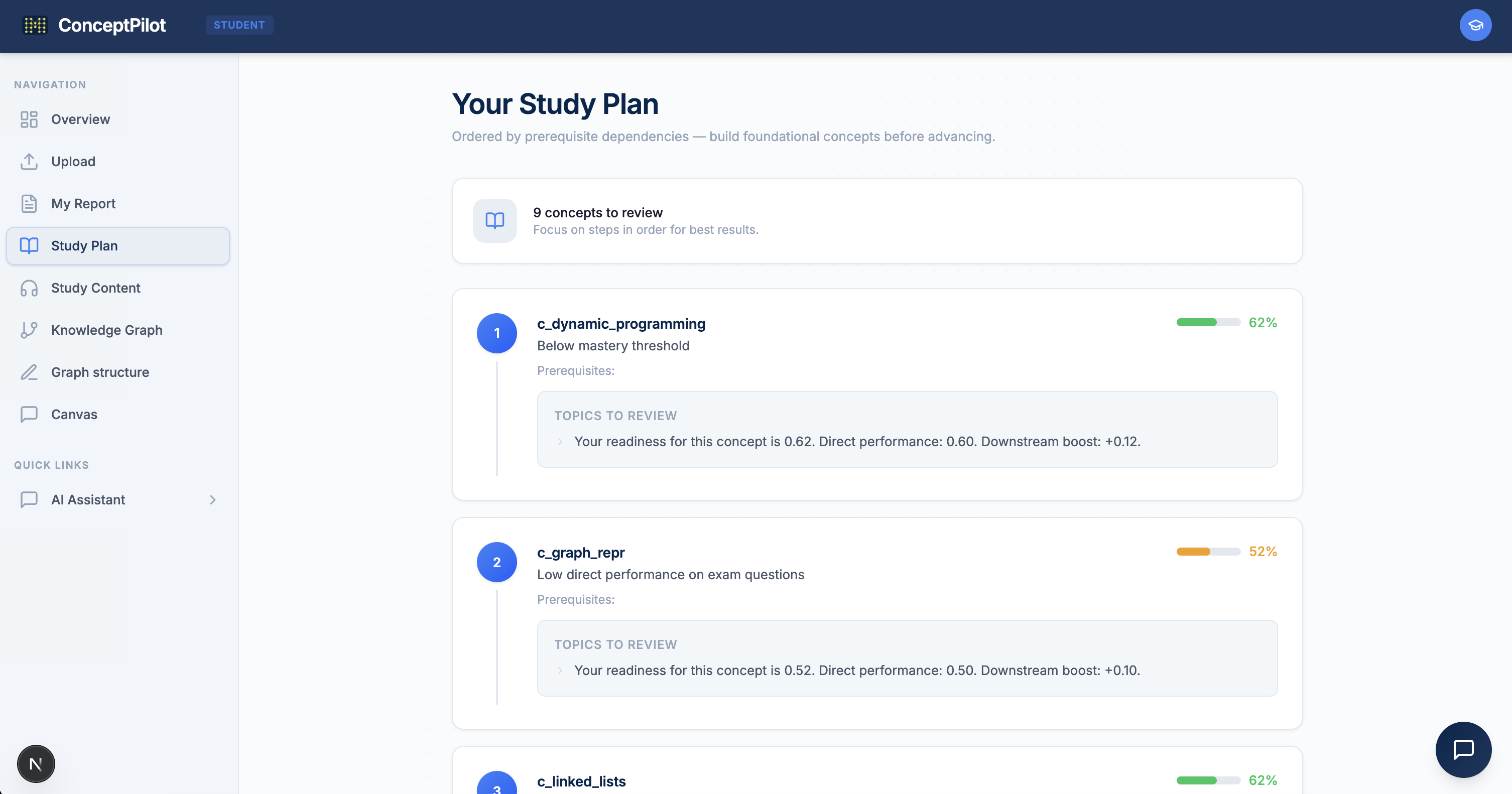
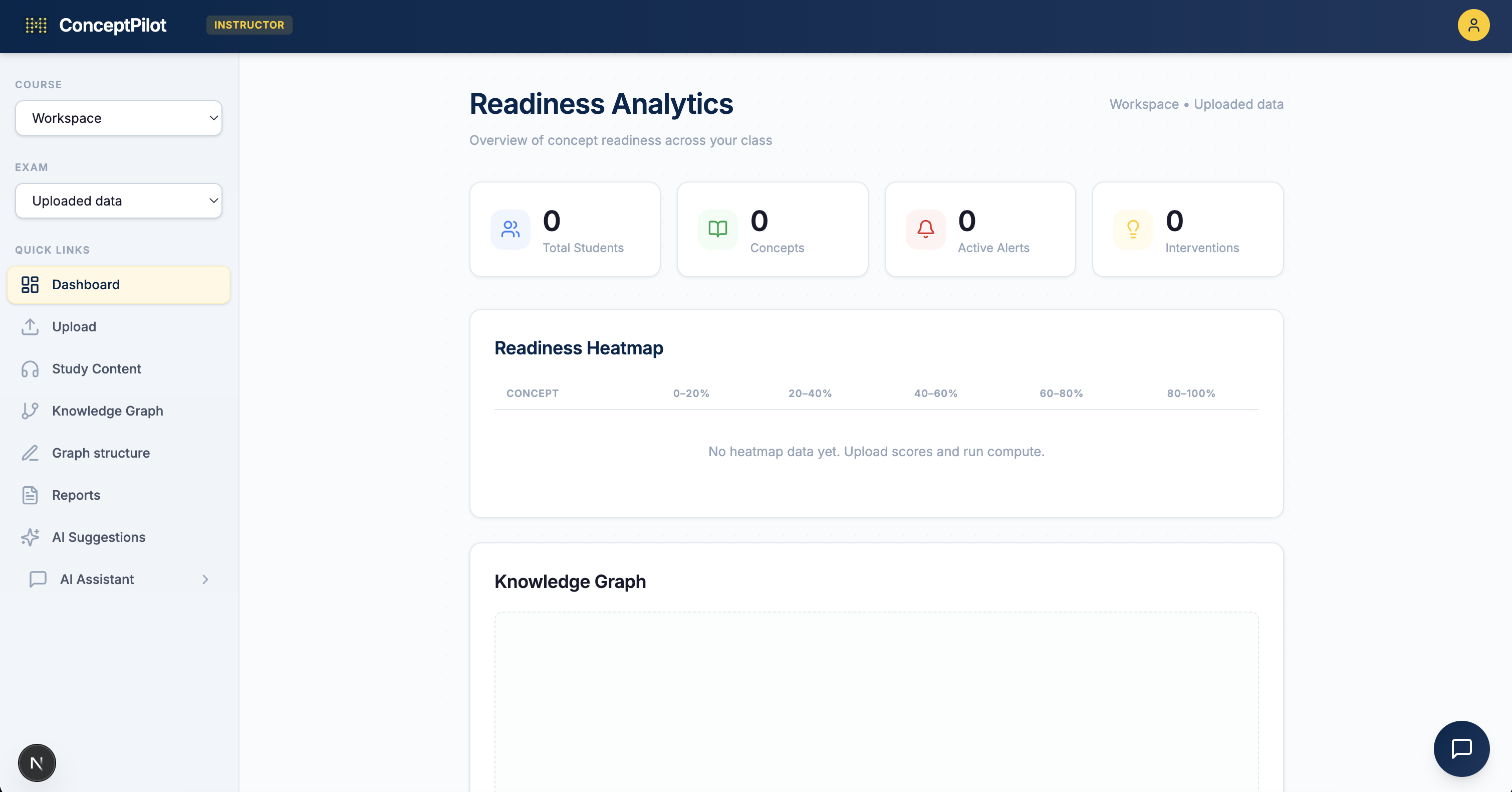
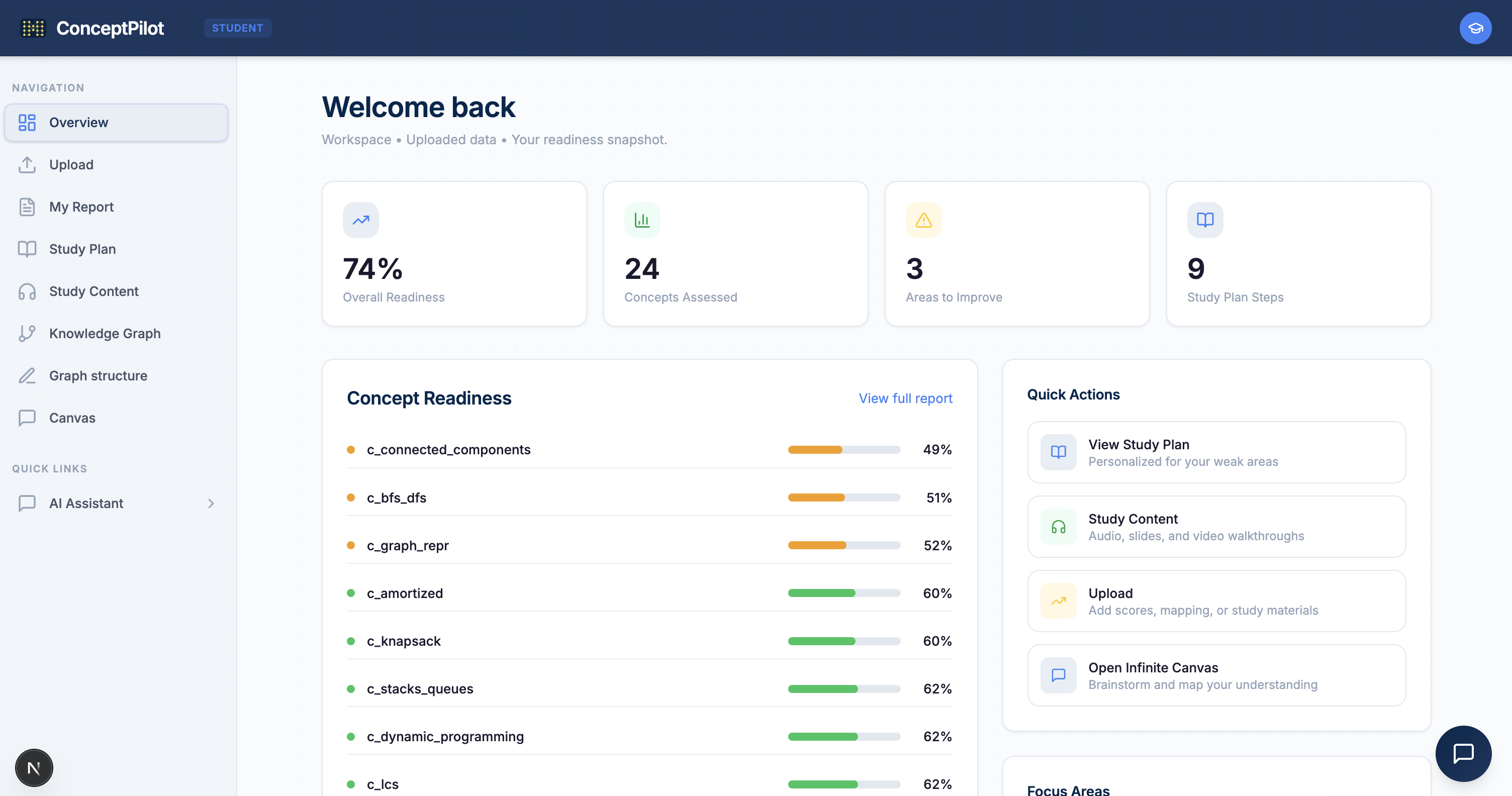
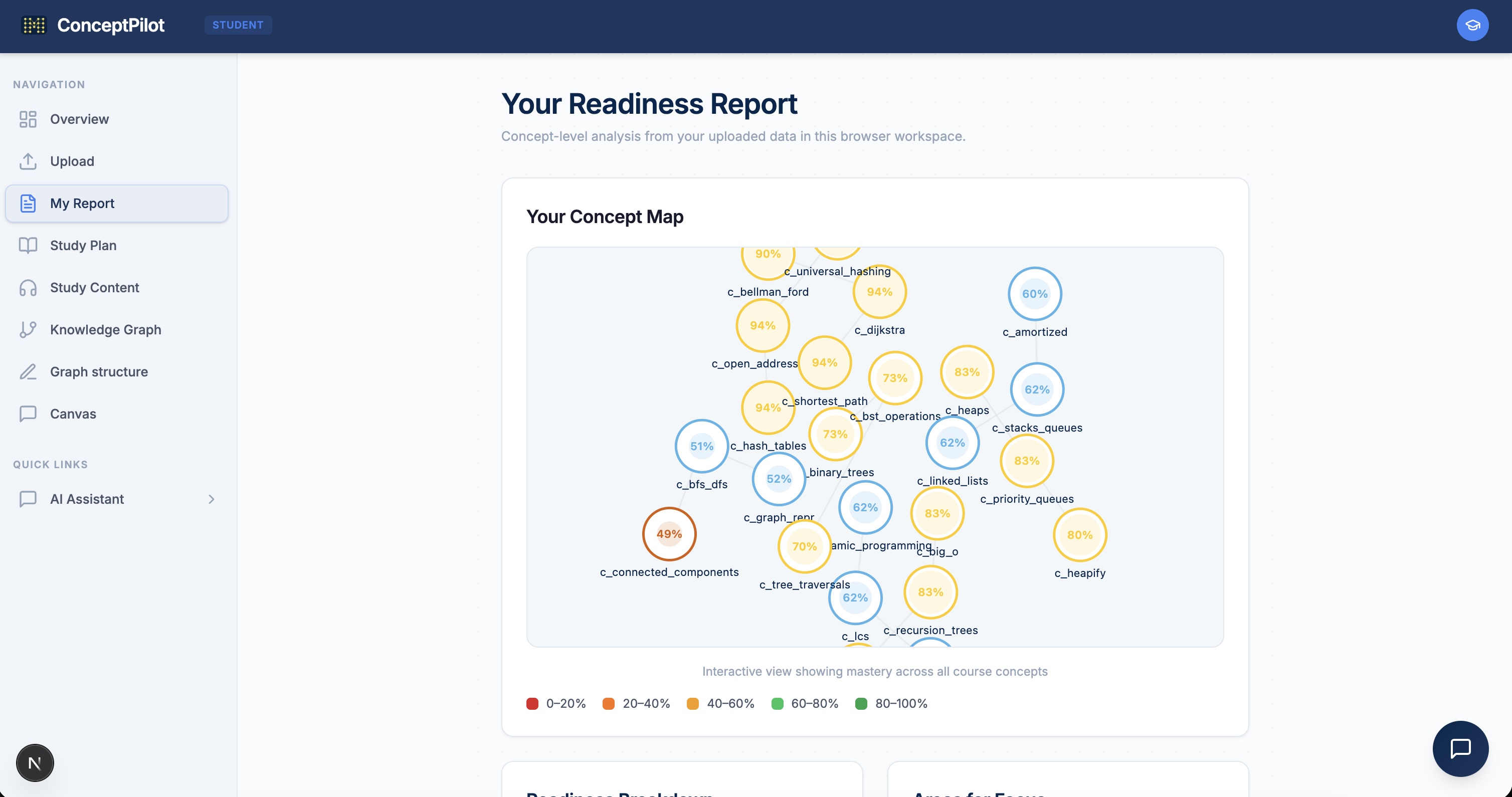
The engine produces readiness heatmaps, confidence labels, k-means student clusters, ranked intervention recommendations (which concept to teach next for maximum impact), and root-cause traces that decompose every readiness score into its contributing factors.
2. The Infinite Canvas — a spatial workspace powered by React Flow where Claude-powered chat nodes, uploaded documents, images, and AI-generated artifacts live on a zoomable, pannable surface. Students can:
- Branch conversations to explore subtopics without losing context
- Link document and image nodes to chat nodes so Claude can reference them
- Choose interaction skills (Tutor, Socratic, Devil's Advocate, Code Coach)
- Generate study content: audio summaries via ElevenLabs, slide presentations, and synchronized video walkthroughs
- Collaborate in real time with other students via WebSocket multiplayer
Student reports are non-punitive and non-comparative — no class rank, no percentiles, just "here's what to study next and in what order."
How we built it
Frontend: Next.js 15 with TypeScript and Tailwind CSS. The canvas is built on React Flow (@xyflow/react) with custom node types for chat, documents, images, and artifacts. D3.js powers the concept DAG visualizations. shadcn/ui and Radix provide the component system. MUI handles the instructor dashboard (heatmaps, data tables). Drag-and-drop file upload uses react-dnd.
Backend: FastAPI (Python 3.11+) with async SQLAlchemy and asyncpg for non-blocking database access. The readiness computation is built on NumPy, with NetworkX for graph operations (topological sort, DAG validation, cycle detection) and scikit-learn for student clustering. All Claude interactions go through the Anthropic Python SDK. ElevenLabs handles text-to-speech for generated audio content. Alembic manages 13 migration versions across the schema.
Database: PostgreSQL on Neon Serverless — 20+ tables spanning the readiness engine (courses, exams, scores, concept graphs, parameters, compute runs, readiness results, clusters, interventions) and the canvas system (projects, nodes, edges, messages, branches, files).
Object Storage: Vultr Object Storage (S3-compatible via boto3) for uploaded files, exported artifacts, and generated media.
Real-time: FastAPI WebSockets for canvas multiplayer — node creation, movement, edge linking, and branch locking broadcast to all connected clients.
AI: Every AI call goes through Claude (Anthropic API). Suggestions for concept tags, prerequisite edges, graph expansion, and intervention drafts all require human review before application. The deterministic engine owns numeric correctness — Claude assists with interpretation, never overrides computation.
Challenges we faced
Keeping computation deterministic. When you're propagating penalties through a DAG and computing cluster centroids, floating-point non-determinism is a real enemy. We enforce sorted traversal order everywhere, use stable seeds for k-means, sanitize NaN/Inf at every stage, and assert that the final readiness matrix contains no NaN values. Same inputs, same parameters, same outputs — always.
CORS and environment configuration across three deployment targets. The backend runs on Vultr, the database on Neon, the frontend on Vercel. Each has its own SSL requirements, connection string format, and origin policy. The app auto-normalizes postgresql:// to postgresql+asyncpg://, but getting CORS, SSL mode, and WebSocket upgrades to work correctly across local dev and production required careful middleware ordering and environment validation. We built a standalone validation script (validate_env.py) that tests database connectivity, API key configuration, object storage reachability, and production CORS rules before the app ever starts.
Designing non-punitive student reports. It's surprisingly hard to surface "you're weak at recursion because you're missing loop fundamentals" without making it feel like a judgment. Every student-facing surface avoids class rank, percentiles, and peer comparisons. The language is always "here's what to study next" rather than "here's what you got wrong." This constraint shaped the entire frontend design — from color choices (no red/green pass/fail) to the ordering of information (study plan first, scores second).
Scaling the canvas without losing context quality. The key insight behind the Infinite Canvas is that long, monolithic chat threads degrade AI response quality because irrelevant context fills the window. Branching solves this — each child node carries only selected context from its parent. But implementing branch locking for multiplayer (only one user can prompt in a given chat node at a time), context assembly across linked nodes, and real-time synchronization of node state across clients added significant complexity to what started as "just put chat in boxes on a canvas."
What we learned
Building ConceptPilot taught us that the most valuable AI applications aren't the ones where the model does everything — they're the ones that draw a clear line between what the model should do and what it shouldn't. The readiness engine is deliberately not AI. It's linear algebra on a graph. Claude helps instructors interpret the results, draft interventions, and explore data — but it never touches the computation. That separation made the system trustworthy in a way that a pure AI approach never could have been.
We also learned that spatial interfaces change how people think about problems. When a student can see their conversation branches laid out on a canvas, with prerequisite concepts linked to study nodes, the learning process becomes navigable rather than linear. The canvas isn't just a UI choice — it's a pedagogical one.
What we learned
What's next for Concept Pilot
Built With
- claude
- elevenlabs
- fastapi
- figma
- javascript
- next.js
- python
- typescript
- vercel
- vultr

Log in or sign up for Devpost to join the conversation.